1.什么是序列化
我们知道内存中的数据对象只有转化成二级制的流才可以进行数据的持久化和网络传输,序列化是将数据对象转换为字节序列的过程,而反序列化是指把字节序列恢复为数据对象的过程。
序列化需要保留充分的信息以恢复数据对象,但是为了节约存储空间和网络带宽,序列化后的二进制流又要尽可能小。 如果使用序列化技术,在执行序列化操作的时候很慢或者是序列化之后的数据量还是很大,那么会让分布式应用程序性能下降很多。
2.Spark的序列化
2.1 在Java中常见的序列化方法有:
1).实现序列化接口Serializable,这个使用的比较多,对于序列化接口Serializable接口是一个空的接口,它的主要作用就是标识这个对象时可序列化的,jre对象在传输对象的时候会进行相关的封装。

2).使用Externalizable接口实现序列化,它继承自Serializable接口,需要我们重写writeExternal()与readExternal()方法,但是这里必须要提供一个public的无参的构造器。
3).还有一些基于Json、基于Protobuf的序列化方法,有兴趣自己去了解一下。
2.2 Spark两种序列化方法:
Spark 是一个高性能、分布式的、基于内存计算的计算引擎,Spark 集群中包含多个节点,各节点之间要进行通信(比如数据传输,Spark 通过 RPC 进行节点间的通信),因而必定存在序列化(对象转字节数组)和反序列化(字节数组转对象),Spark旨在在便利(允许您使用您的操作中的任何Java类型)和性能之间实现平衡。它默认提供了下面两种序列化库:
1).java native serialization
Spark默认使用Java的ObjectOutputStream框架来序列化对象,可以对任何实现了java.io.Serializable的任何类进行序列化,而且还提供了Externalizable接口,可实现自己更高性能序列化算法;这种序列化方式速度比较慢,且序列化后的数据占用内存空间大。
2).kryo serialization
Spark也可以使用Kryo库(version 2)来实现更快的对象序列化。Kryo比Java序列化更快、序列化后数据占用内存空间更小,通常比Java序列化后的数据占用空间小10倍,但不支持所有的Serializable类型。用户如果希望使用Kryo来获取更好的性能,需要对序列化使用的类型进行注册。
3.Kryo serialization实例和性能测试
测试数据生成
我这里在我的本地生成一份测试数据kryoTest2.txt,共600万行,大小是461MB,每一行保存了4个字段用逗号隔开,分别是name,age,score,address信息,文件大小是464MB,数据生成代码如下:
package com.hadoop.ljs.hdfs273;import java.io.File;import java.io.FileWriter;import java.io.IOException;import java.io.Writer;public class KryoSourceDataGenernate { public static void main(String[] args) throws IOException { File file = new File("D:\\kryoTest2.txt"); Writer out = new FileWriter(file,true); for(int i=1;i<6000000;i++){ String name="student_"+i; int age = (int)(Math.random()*100); double score=i*100+(int)(Math.random()*100); String address="chian_shandong_jinan_lixiaqu_erhuandonglu_"+i; out.write(name+","+age+","+score+","+address +"\n"); } out.close(); }}
这里先给你贴出来前10行数据格式:
student_1,19,145.0,chian_shandong_jinan_lixiaqu_erhuandonglu_1student_2,1,281.0,chian_shandong_jinan_lixiaqu_erhuandonglu_2student_3,49,306.0,chian_shandong_jinan_lixiaqu_erhuandonglu_3student_4,63,424.0,chian_shandong_jinan_lixiaqu_erhuandonglu_4student_5,39,570.0,chian_shandong_jinan_lixiaqu_erhuandonglu_5student_6,88,675.0,chian_shandong_jinan_lixiaqu_erhuandonglu_6student_7,35,717.0,chian_shandong_jinan_lixiaqu_erhuandonglu_7student_8,23,805.0,chian_shandong_jinan_lixiaqu_erhuandonglu_8student_9,27,963.0,chian_shandong_jinan_lixiaqu_erhuandonglu_9student_10,48,1008.0,chian_shandong_jinan_lixiaqu_erhuandonglu_10
3.1 不设置序列化方式,默认用Java序列化
测试代码很简单就是读取测试文件,将RDD转换成自定义类型为student类的RDD,并持久化到内存中,然后观察RDD占用的内存大小,最后将RDD输出到本地文件,主函数代码如下:
ackage com.hadoop.ljs.spark.serializeimport java.io.Fileimport org.apache.spark.storage.StorageLevelimport org.apache.spark.{SparkConf, SparkContext}/** * @author: Created By lujisen * @company ChinaUnicom Software JiNan * @date: 2020-03-30 11:15 * @version: v1.0 * @description: com.hadoop.ljs.spark.serialize */case class Student(name:String,age:Int,score:Double,address:String)object KryoTest { def main(args: Array[String]) { val output=new File("D:\\kryoTestDir") deleteDir(output) val sparkConf = new SparkConf().setMaster("local[2]").setAppName("KryoTest") sparkConf.set("spark.driver.memory","2048m") sparkConf.set("spark.executor.memory","2048m") val sc = new SparkContext(sparkConf) val sourceDatat = sc.textFile("D:\\kryoTest2.txt") val logsCache=sourceDatat.map(x=>{ val fields=x.split(",") Student(fields(0),fields(1).toInt,fields(2).toDouble,fields(3)) }).persist(StorageLevel.MEMORY_ONLY) logsCache.map(x=>{ x.name+"\t"+x.age+"\t"+x.score+"\t"+x.address }).repartition(1).saveAsTextFile("D:\\kryoTestDir") //为了方便我们从spark ui查看内存占用 这里让程序阻塞100秒 Thread.sleep(100000) } def deleteDir(dir: File): Unit = { val files = dir.listFiles() files.foreach(f => { if (f.isDirectory) { deleteDir(f) } else { f.delete() println("delete file " + f.getAbsolutePath) } }) dir.delete() println("delete dir " + dir.getAbsolutePath) }}
我们看下RDD内存占用,如下图所示,Input size是465.6MB,而RDD持久化后内存占用1434.1MB,比我们的输入大了好几倍,耗时10秒。
3.2 修改RDD持久化级别修改为MEMORY_ONLY_SER:
val logsCache=sourceDatat.map(x=>{ val fields=x.split(",") Student(fields(0),fields(1).toInt,fields(2).toDouble,fields(3)) //修改了持久化级别,从MEMORY_ONLY变为MEMORY_ONLY_SER }).persist(StorageLevel.MEMORY_ONLY_SER)
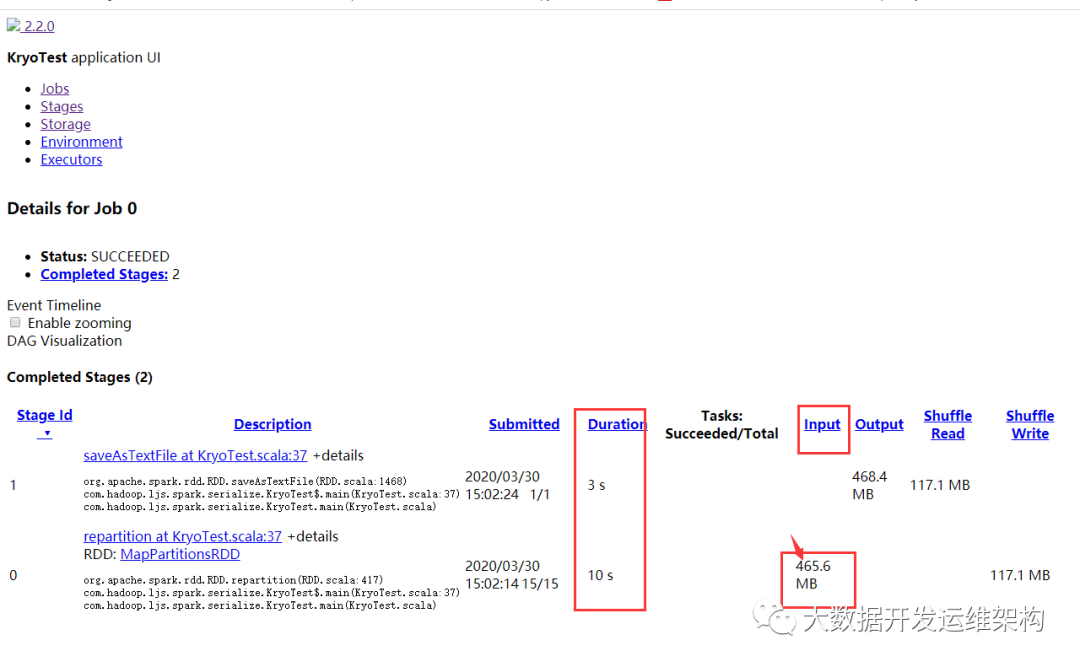
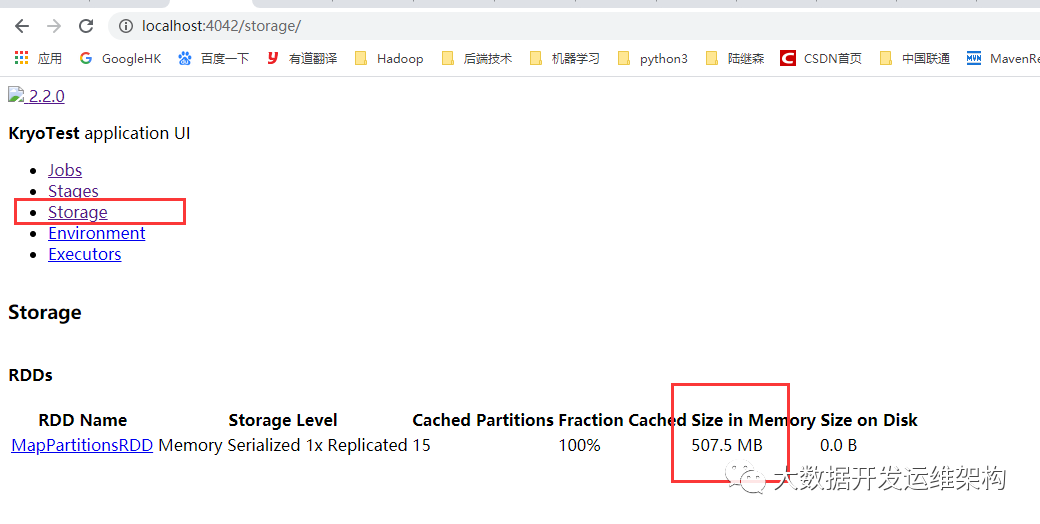
我们看下RDD内存占用,如下图所示,Input size是465.6MB,而RDD持久化后内存占用507.5MB,比之前小了很多,耗时13秒。
3.3 继续修改序列化方式为Kryo,但是没有对sudent进行注册:
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("KryoTest") sparkConf.set("spark.driver.memory","2048m") sparkConf.set("spark.executor.memory","2048m") //这里修改序列化类为KryoSerializer sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
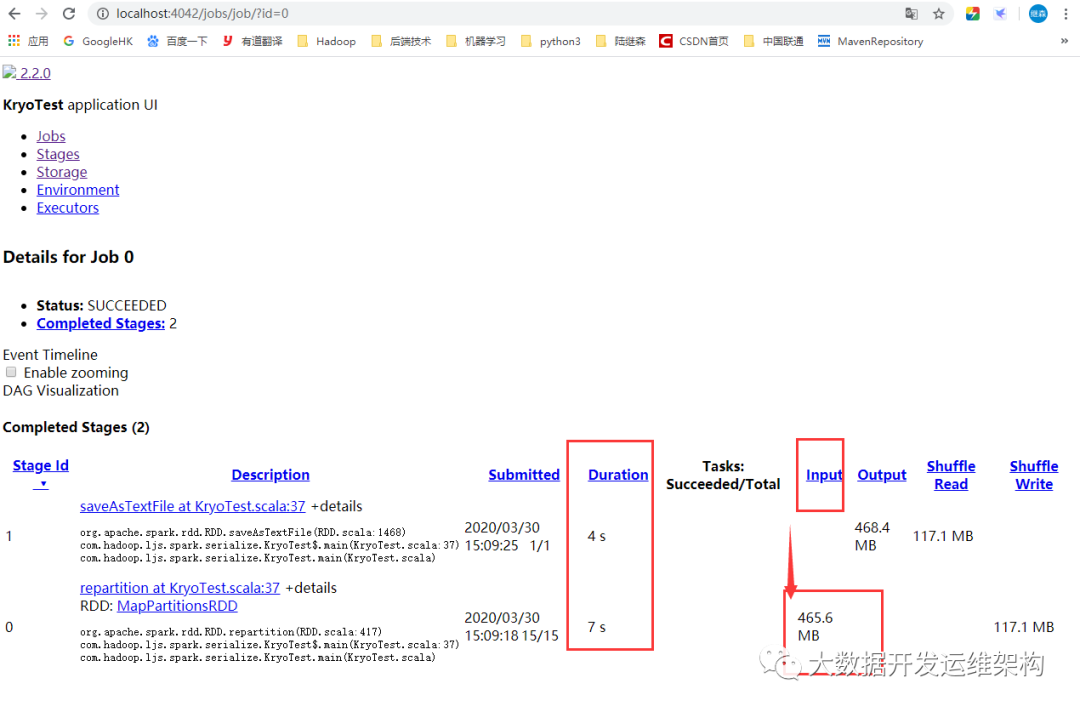
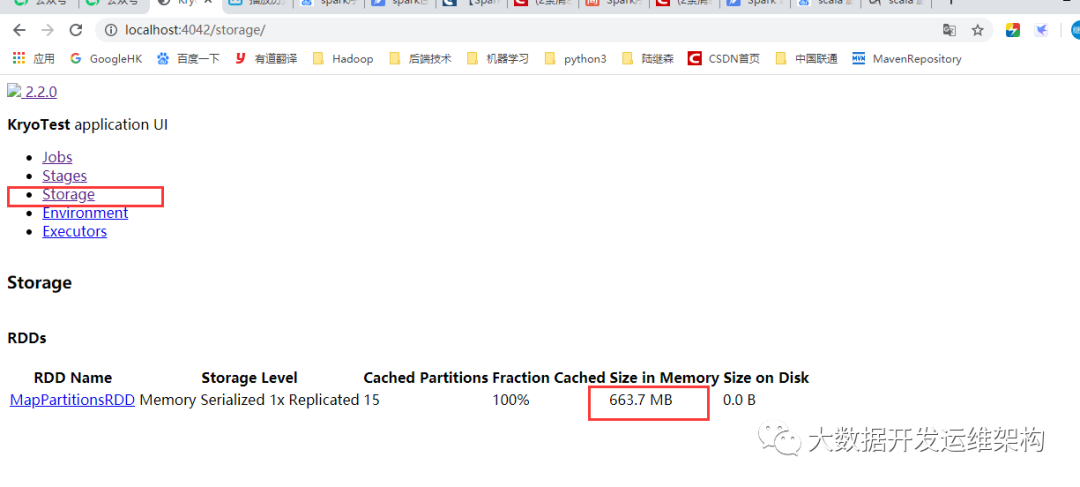
我们看下RDD内存占用,如下图所示,Input size是465.6MB,而RDD持久化后内存占用663.7MB,比3.2中的Java序列化占用内存还大了,这里我们没有对Kryo使用的序列化类student进行注册,如果不进行注册,那么Kryo必须要时刻保存类型的全限定名,反而占用更多的字符,这里一定要记住。耗时11秒。
3.4 继续修改序列化方式为Kryo,并对sudent进行注册:
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("KryoTest") sparkConf.set("spark.driver.memory","2048m") sparkConf.set("spark.executor.memory","2048m") //指定Kryo序列化方式,并对student类进行了注册 sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") sparkConf.registerKryoClasses(Array(classOf[Student], classOf[String]))
我们看下RDD内存占用,如下图所示,Input size是465.6MB,而RDD持久化后内存占用440.5MB,比之前小了很多,耗时8秒,这里可以看出比3.2中的内存占用小了,处理速度也快了。
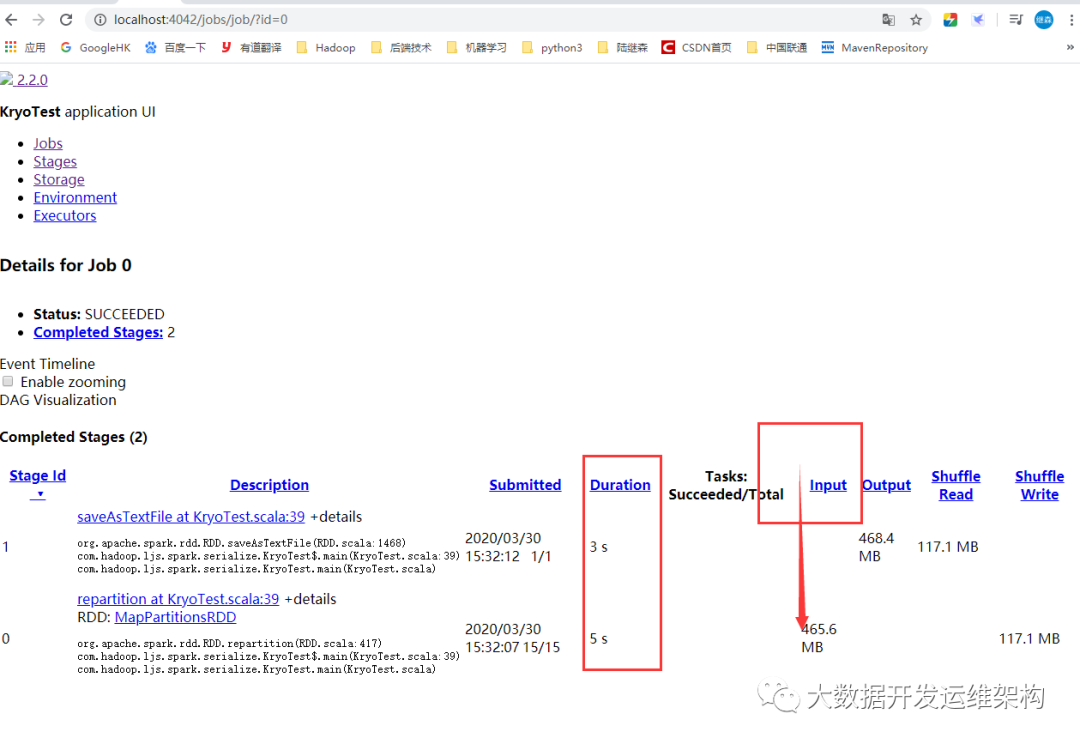
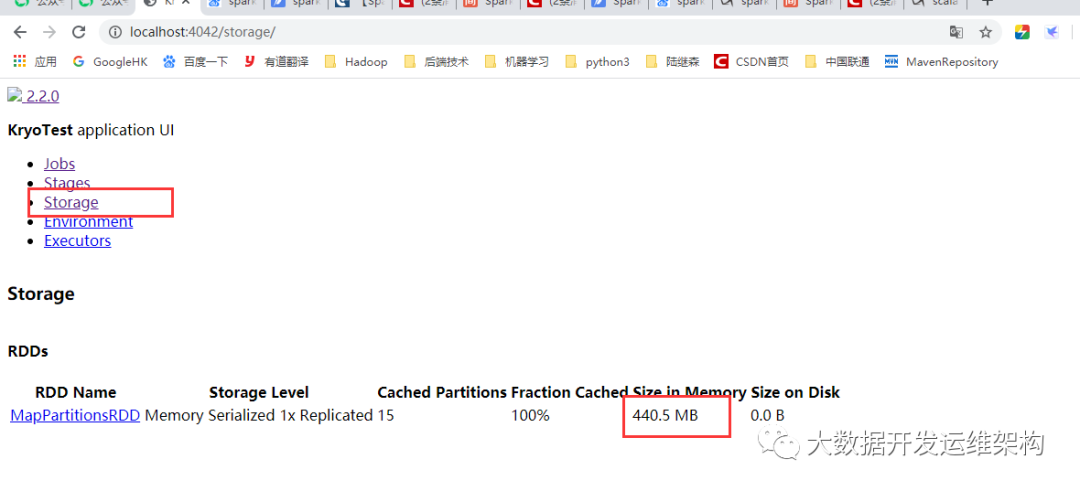
为让你看的更清晰,我这里列了一个图标对别下性能,数据量如果比较大,效果会更明显:
| 配置 |
内存占用 |
耗时 |
使用Java序列化,RDD持久化级别MEMORY_ONLY |
1434.1MB | 10秒 |
| 使用Java序列化,RDD持久化级别MEMORY_ONLY_SER | 507.5MB | 13秒 |
| 使用Kryo序列化,未注册序列化类student | 663.7MB | 11秒 |
| 使用Kryo序列化,注册序列化类student | 440.5MB | 8秒 |
由此,我们看出Kryo序列化后数据占用内存较小,且速度比较快,但是使用时一定要对需要序列化的自定义类进行注册,否则序列化后的数据可能占用更多的内存。