当将数据写入文件、发送到网络、写入到存储时通常需要序列化(serialization)技术,从其读取时需要进行反序列化(deserialization),又称编码(encode)和解码(decode)。序列化作为传输数据的表示形式,与网络框架和通信协议是解耦的。如 Dubbo 支持 Hessian 和 JSON,HTTP 协议支持 XML、JSON 和流媒体传输等。
序列化的方式有很多,作为数据传输和存储的基础,如何选择合适的序列化方式显得尤其重要。
序列化分类
通常而言,序列化技术可以大致分为以下三种类型:
- 内置类型:指编程语言内置支持的类型,如 Java 里面的java.io.Serializable。这种类型由于与语言绑定,不具有通用性,而且一般性能不佳,一般只在局部范围内使用。
- 文本类型:一般是标准化的文本格式,如 XML、JSON。这种类型可读性较好,且支持跨平台,具有广泛的应用。主要缺点是比较臃肿,网络传输占用带宽大。
- 二进制类型:采用二进制编码,数据组织更加紧凑,支持多语言和多平台。常见的有 Protocol Buffer/Thrift/MessagePack/FlatBuffer 等。
序列化的性能指标
衡量序列化/反序列化主要有三个指标:
- 序列化之后的字节大小
- 序列化/反序列化的速度
- CPU和内存消耗 下图是一些常见的序列化框架性能对比:
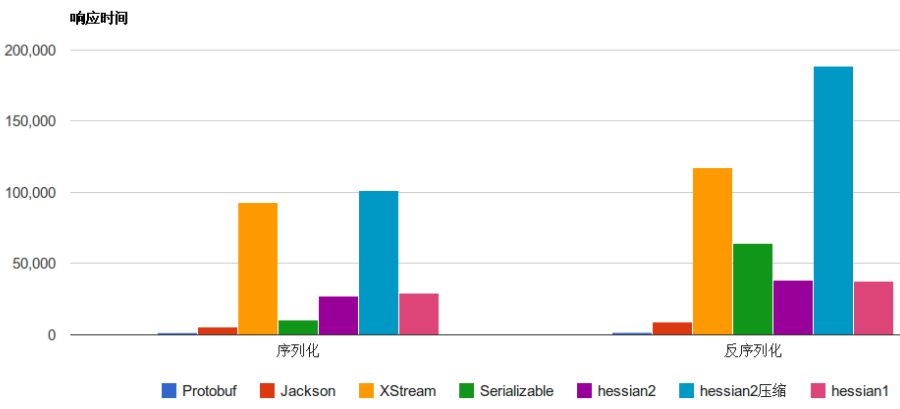
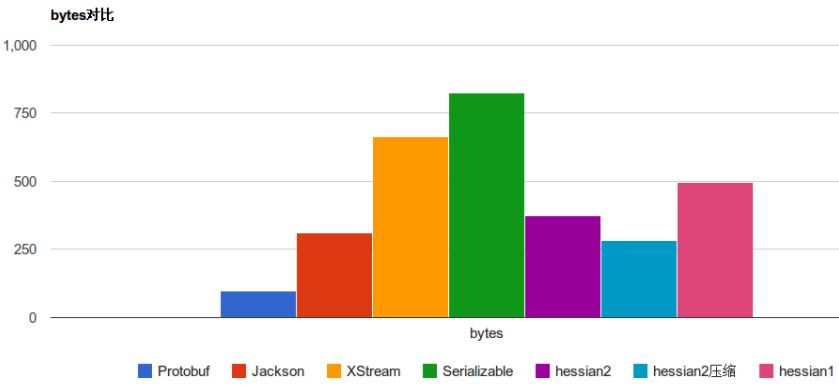
可以看出 Protobuf 无论是在序列化速度上还是字节占比上可以说是完爆同行。不过人外有人,天外有天,听说FlatBuffer 比 Protobuf 更加无敌,下图是来自谷歌的FlatBuffer 和其他序列化性能对比,光看图中数据 Facebook 貌似秒杀 PB 的存在。
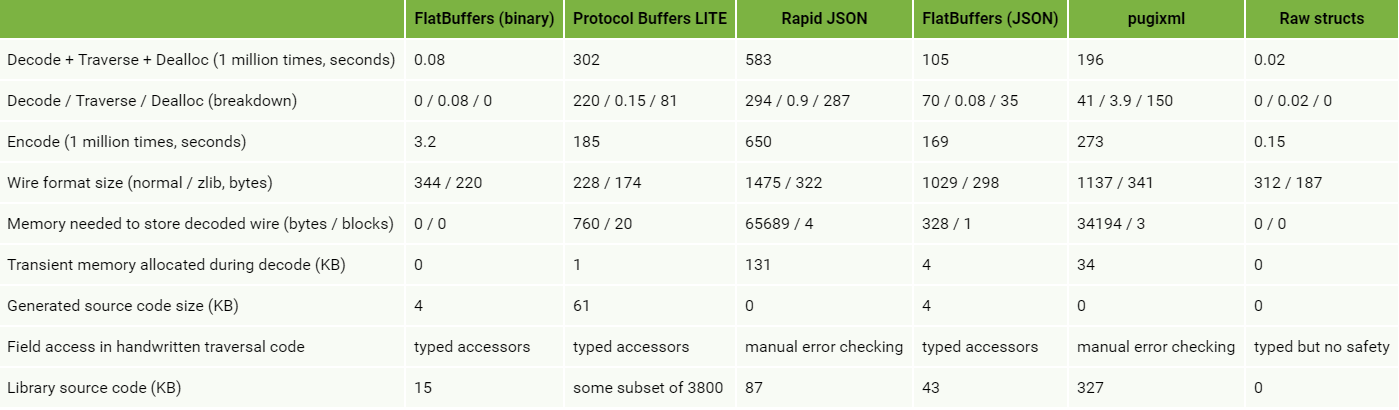
序列化选型考量
在对序列化技术进行选型的时候,我们需要从以下几个方面考虑:
- 性能:CPU 和字节占用大小是序列化的主要开销。在基础的 RPC 通信、存储系统和高并发业务上应该选择高性能高压缩的二进制序列化。一些内部服务、请求较少 Web 的应用可以采用文本的JSON,浏览器直接内置支持JSON。
- 易用性:丰富数据结构和辅助工具能提高易用性,减少业务代码的开发量。现在很多序列化框架都支持列表、哈希等多种结构和可读的打印。
- 通用性:现代的服务往往涉及多语言、多平台,能否支持跨平台跨语言的互通是序列化选型的基本条件。
- 兼容性:现代的服务都是快速迭代和升级,一个好的序列化框架应该有良好的向前兼容性,支持字段的增减和修改等。
- 扩展性:序列化框架能否低门槛的支持自定义的格式有时候也是一个比较重要的考虑因素。
本文亦通过 NoOne's Blog 发表。