摘自书籍:Greenplum企业应用实战 完整版[何勇,陈晓峰著]
1.数据扫描方式
-
Seq Scan:顺序扫描
顺序扫描将一个数据文件从头到尾读取一次,这种方式非常符合磁盘的读写特性,顺序读写,吞吐很高。对于分析性的语言,顺序扫描基本上是对全表的所有数据进行分析计算,在是数据仓库中,大都为这种扫描,结合压缩表使用,可以减少磁盘IO的损耗。
-
Index Scan:索引扫描
索引扫描是通过索引来定位数据的,一般对数据进行特定的筛选,筛选后的数据量比较小(对于整个表而言)。使用索引进行筛选,必须先在筛选字段上建立索引,查询时先通过索引文件定位到实际数据在数据文件中的位置,再返回数据。
-
Bitmap Heap Scan:位图堆表扫描
当索引定位到的数据在整表中占比较大的时候,通过索引定位到的数据会使用位图的方式对索引字段进行位图堆表扫描,以确定结果数据的准确。数据仓库很少用这种扫描方式。
-
Tid Scan:通过隐藏字段ctid扫描
ctid是PostgreSQL中标记数据位置的字段,通过这个字段来查找数据,速度非常快,类似于Oracle的rowid。Greenplum是一个分布式数据库,每一个子节点都是一个PostgreSQL数据库,每一个子节点都单独维护自己的一套ctid字段。
因此,如果在Greenplum中通过ctid来找数据,会有如下的提示:

如果要确定到具体一行数据,还必须通过制定另外一个隐藏字段(gp_segment_id)来确定取哪一个数据库的ctid值。
select * from test1 where ctid='(1,1)' and gp_segment_id=1;-
Subquery Scan '*SELECT*':子查询扫描
只要SQL中有子查询,需要对子查询的结果做顺序扫描,就会进行子查询扫描。
-
Function Scan:函数扫描
数据库中有一些函数的返回值是一个结果值,当数据库从这个结果集中取出数据的时候,就会用到这个function Scan,顺序获取函数返回的结果集(这是函数扫描方式,不属于扫描方式),如:
explain select * from generate_series(1,10);2.分布式执行
-
Gather Motion(N:1)
聚合操作,在Master上将子节点所有的数据聚合起来。一般的聚合规则是:哪一个子节点的数据先返回到Master上就将该节点的数据先放到MASTER上。
-
Broadcast Motion(N:N)
广播,将每个Segment上某一个表的数据全部发送给所有Segment。这样每一个Segment都相当于有一份全量数据,广播基本只会出现在两边关联的时候,相关内容再选择广播或者重分布。
-
Redistribute Motion(N:N)
重新分布数据,当需要做跨库关联或者聚合的时候,当数据不能满足广播的条件,或者广播的消耗过大时,Greenplum就会选择重分布数据,即数据按照新的分布键(关联键)重新打散到每个Segment上,重分布一般在以下三种情况发生:
(1)关联:将每个Segment的数据根据关联键重新计算hash值,并根据greenplum的路由算法路由到目标子节点中,使关联时属于同一个关联键的数据都在同一个Segment上。
(2)Group By:当表需要Group By,但是Group By的字段不是分布键时,为了使Group By的字段在同一个库中,Greenplum会分两个Group By操作来执行,首先,在单库上执行一个Group By会分两个Group By操作来执行,首先,在单库上执行一个Group By操作,从而减少需要重分布的数据量;然后将结果数据按照Group By字段重分布,之后再做聚合获得最终结果。
(3)开窗函数:跟Group By类似,开窗函数的实现也需要将数据重分布到每个节点上进行计算,不过其实比Group By更复杂一些。
(4)切片(Slice)
Greenplum在实现分布式执行计划的时候,需要将SQL拆分成多个切片(Slice),每一个Slice其实是单库执行的一部分SQL,上面描述的每一个motion都会导致Greenplum多一个Slice操作,而每一个Slice操作节点都会发起一个进程来处理数据。
3.SQL消耗
在每个SQL的执行计划中,每一步都会有(cost=0.01..0.05 rows=3 width=150)这3项表示SQL的消耗,后面会介绍消耗具体的计算方法。
(1)Cost
以数据库自定义的消耗单位,通过统计信息来估计SQL的消耗。
(2)Rows
根据统计信息估计SQL返回结果集的行数。
(3)Width
返回结果集每一行的长度,这个长度值是根据pg_statistic表中的统计信息来计算的。
4.其他术语
(1)Filter过滤
Where条件中的筛选条件,在执行计划中就是Filter关键字。
Filter:relfilenoe = 1249::oid
(2)Index Cond
如果在查询的表中where筛选的字段中有索引,那么执行计划会通过索引定位,提高查询的效率。Index Cond就是定位索引的条件。
(3)Recheck Cond
在使用位图扫描索引的时候,由于PostgreSQL里面使用的是MVCC协议,为了保证结果的正确性,要重新检查一下过滤条件。

(4)Hash Cond
执行Hash join的时候的关联条件:
(5)Merge
在执行排序操作时数据会在子节点各自排好序,然后在Master上做一个归并操作。
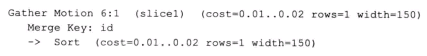
(6)Hash Key
在数据重分布时候指定的重算hash值的分布键:

(7)Materialize
将数据保存在内存中,避免多次扫描磁盘带来的开销。