-
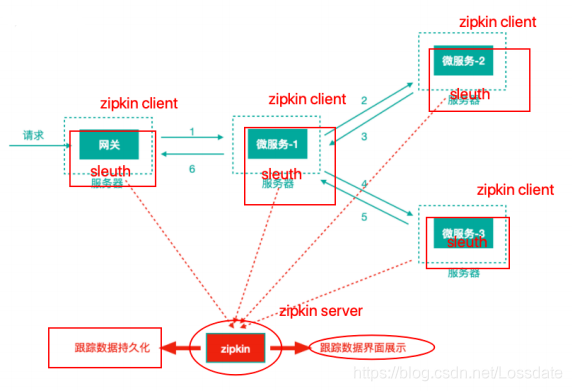
Sleuth 每⼀个需要被追踪踪迹的微服务⼯程都引⼊依赖坐标
1)pom<!--链路追踪--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>2)ym
#分布式链路追踪 logging: level: org.springframework.web.servlet.DispatcherServlet: debug org.springframework.cloud.sleuth: debug -
Zipkin Server 构建
1)pom<!--zipkin-server的依赖坐标--> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-server</artifactId> <version>2.12.3</version> <exclusions> <!--排除掉log4j2的传递依赖,避免和springboot依赖的⽇ 志组件冲突--> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-log4j2</artifactId> </exclusion> </exclusions> </dependency> <!--zipkin-server ui界⾯依赖坐标--> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <version>2.12.3</version> </dependency>2)yml
server: port: 9411 management: metrics: web: server: # 关闭⾃动检测请求 auto-time-requests: false3)启动类

-
Zipkin Client 构建(在具体微服务中修改,即需要被追踪踪迹的微服务)
1)pom<!-- zipkin client --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>2)yml
spring: application: name: service-resume # zipkin client zipkin: base-url: http://127.0.0.1:9411 # zipkin server的请求地址 sender: # web 客户端将踪迹⽇志数据通过⽹络请求的⽅式传送到服务端,另外还有配置 # kafka/rabbit 客户端将踪迹⽇志数据传递到mq进⾏中转 type: web sleuth: sampler: # 采样率 1 代表100%全部采集 ,默认0.1 代表10% 的请求踪迹数据会被采集 # ⽣产环境下,请求量⾮常⼤,没有必要所有请求的踪迹数据都采集分析, # 对于⽹络包括server端压⼒都是⽐较⼤的, # 可以配置采样率采集⼀定⽐例的请求的踪迹数据进⾏分析即可 probability: 1 -
server 界面
1)启动后访问地址:http://localhost:9411 -
Zipkin Server服务区 -> 追踪数据Zipkin持久化到mysql
1)创建数据库
数据库名 -> zipkin
2)表-- -- Copyright 2015-2019 The OpenZipkin Authors -- -- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except -- in compliance with the License. You may obtain a copy of the License at -- -- http://www.apache.org/licenses/LICENSE-2.0 -- -- Unless required by applicable law or agreed to in writing, software distributed under the License -- is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express -- or implied. See the License for the specific language governing permissions and limitations under -- the License. -- CREATE TABLE IF NOT EXISTS zipkin_spans ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL, `id` BIGINT NOT NULL, `name` VARCHAR(255) NOT NULL, `remote_service_name` VARCHAR(255), `parent_id` BIGINT, `debug` BIT(1), `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query', PRIMARY KEY (`trace_id_high`, `trace_id`, `id`) ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds'; ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames'; ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames'; ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range'; CREATE TABLE IF NOT EXISTS zipkin_annotations ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds'; ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames'; ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values'; ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job'; CREATE TABLE IF NOT EXISTS zipkin_dependencies ( `day` DATE NOT NULL, `parent` VARCHAR(255) NOT NULL, `child` VARCHAR(255) NOT NULL, `call_count` BIGINT, `error_count` BIGINT, PRIMARY KEY (`day`, `parent`, `child`) ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;3)zipkin server 9411 -> pom加入mysql依赖
扫描二维码关注公众号,回复: 12723257 查看本文章
<!-- zipkin针对mysql持久化的依赖 --> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-storage-mysql</artifactId> <version>2.12.3</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency> <!-- 事务控制 --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-tx</artifactId> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-jdbc</artifactId> </dependency>4)yml添加
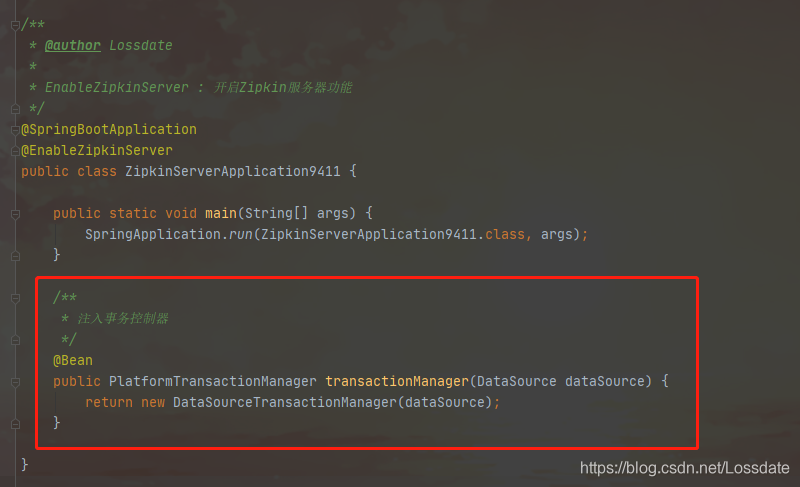
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/zipkin?useUnicode=true&characterEncoding=utf8&useSSL=false&allowMultiQueries=true&serverTimezone=UTC username: root password: 123456 druid: initialSize: 10 minIdle: 10 maxActive: 30 maxWait: 50000 # 指定zipkin持久化介质为mysql zipkin: storage: type: mysql5)启动类注⼊事务管理器