Spring1.x里Zipkin可以自己定制编译部署,Spring2.x里Zipkin是一个独立的jar包服务,不能自己定义
一、服务端
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar

二、客户端(包括zuul 和 微服务)
- POM
<!--zipkin客户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.3.RELEASE</version>
</dependency>
- 配置
#项目添加zipkin支持
spring.zipkin.base-url=http://localhost:9411
# 将采样比例设置为 1.0,也就是全部都需要。默认是 0.1
spring.sleuth.sampler.probability=1.0
- 测试
启动服务(eureka, zuul, 具体服务),调用接口,并查看zipkin服务端UI页面
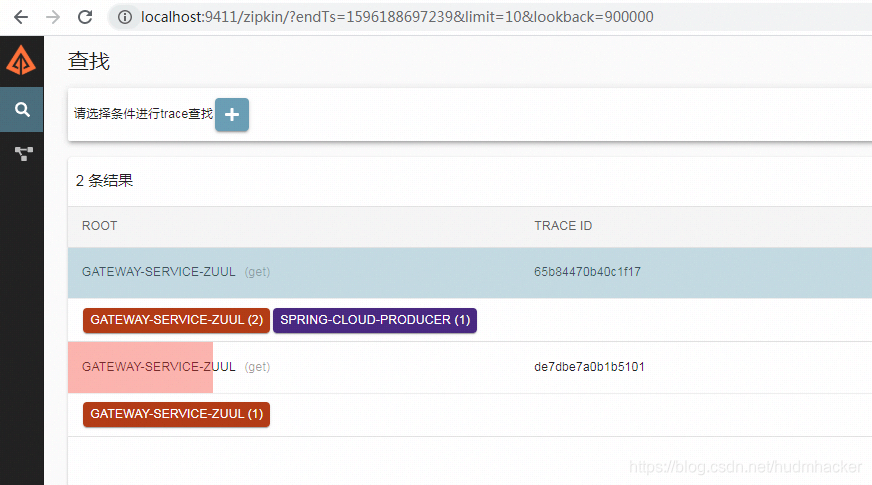
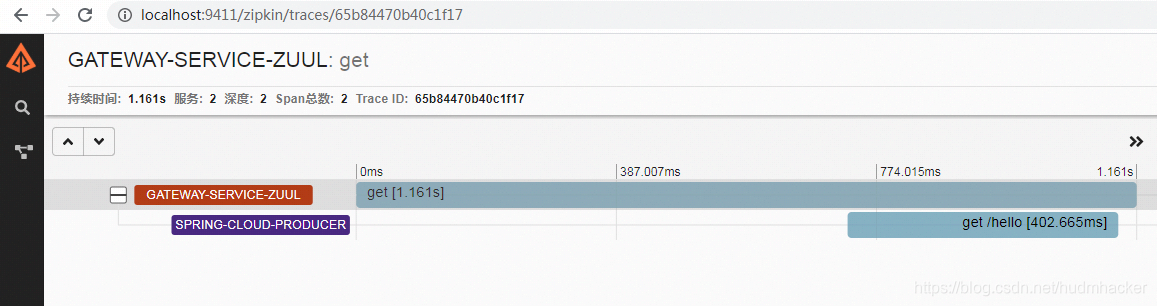
三、通过rabbbitmq方式进行消息传递(前面是通过http接口方式)
zipkin服务和各个微服务/zuul网关解耦,大家只依赖于消息总线rabbitmq,而不依赖某一个服务
- 改造服务端zipkin
java -jar zipkin.jar --zipkin.collector.rabbitmq.addresses=49.235.66.205
- 改造zuul网关和微服务
POM
<!--trace数据通过rabbitmq而不是直接传递给zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
<version>3.0.6.RELEASE</version>
</dependency>
配置
spring.sleuth.sampler.probability=1.0
spring.zipkin.rabbitmq.queue=zipkin
spring.zipkin.rabbitmq.addresses=49.235.66.205
- 测试

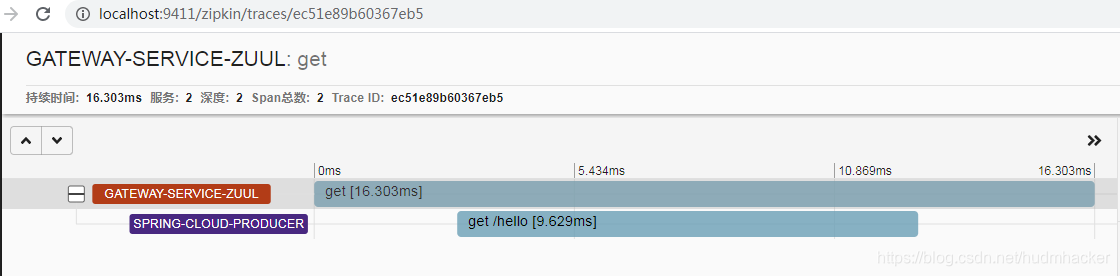
四、怎么把trace和span持久化呢?
zipkin支持多种数据持久化策略,比如ES,Mysql等
比如持久化到MYSQL:
- 创建数据库zipkin
- 导入数据表:https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/mysql-v1#applying-the-schema
- zipkin运行的时候配置mysql支持即可
java -jar zipkin.jar --zipkin.collector.rabbitmq.addresses=xx.xx.xx.xx --STORAGE_TYPE=mysql --MYSQL_HOST=xx.xx.xx.xx --MYSQL_DB=zipkin --MYSQL_USER=xxx --MYSQL_PASS=xxx
Refer:https://github.com/openzipkin/zipkin/tree/master/zipkin-server#mysql-storage