前言
随着分布式微服务部署的规模不断增长,服务之间依赖关系也变得更加复杂,那么,我们需要借助可视化工具实时分析线上应用健康状况,快速定位服务调用链上的故障点。下面将介绍,使用Spring Cloud Sleuth、Kafka、Zipkin实现微服务的链路跟踪。
版本说明
| 组件 | 版本 |
|---|---|
| Kafka | 2.2.2 |
| Zipkin | 2.20.2 |
| Spring Cloud | Greenwich.SR4 |
Kafka
Kafka作为消息队列,将接收来自Sleuth组件产生的链路日志,最终由Zipkin从队列中获取并展示。
我们可以在Kafka的官网进行下载:http://kafka.apache.org/downloads
下载完成后得到kafka_2.12-2.2.2.tgz压缩包并解压,接下来修改kafka服务端配置文件config/server.properties,将advertised.listeners配置项进行调整,这里需要修改为本机ip地址。
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners=PLAINTEXT://your.host.name:9092
由于Kafka已经内置了Zookeeper,并提供了启动脚本,无需单独下载安装。
下面我们来启动Zookeeper,首先切换到Kafka解压后的目录,然后执行启动脚本,并指定配置文件:
sh bin/zookeeper-server-start.sh config/zookeeper.properties
当然,我们也可以在执行命令时,添加-daemon参数,使其在后台运行。
接下来启动Kafka:
sh bin/kafka-server-start.sh -daemon config/server.properties
启动完成后,我们可以看到下列端口已经为LISTEN状态了。
tcp6 0 0 :::41179 :::* LISTEN 29862/java
tcp6 0 0 :::41183 :::* LISTEN 29165/java
tcp6 0 0 192.168.3.201:9092 :::* LISTEN 29862/java
tcp6 0 0 :::2181 :::* LISTEN 29165/java
Zipkin
Zipkin官网提供了docker和jar包两种方式来运行Zipkin服务。这里介绍docker方式,运行以下命令拉取镜像并创建容器。
docker run -d --name zipkin --restart always -p 9411:9411 -e KAFKA_BOOTSTRAP_SERVERS=192.168.3.201:9092 openzipkin/zipkin:2.20.2
其中-e KAFKA_BOOTSTRAP_SERVERS=192.168.3.201:9092参数,指定了Kafka的服务地址。
通过浏览器访问http://192.168.3.201:9411/zipkin/地址,我们就可以看到Zipkin的页面了。
示例项目
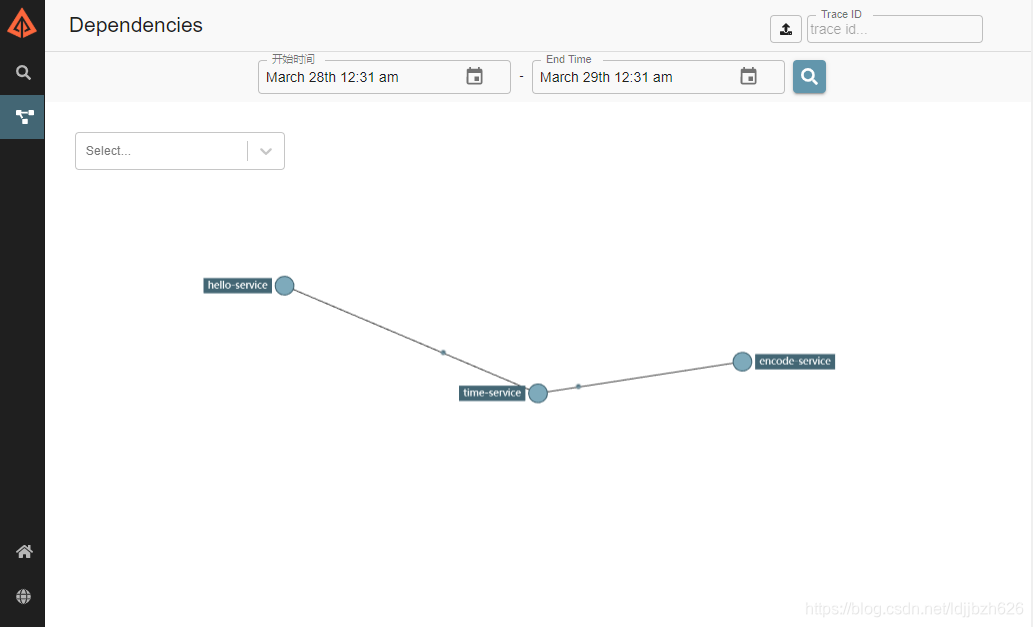
下面将创建三个服务,Service-1、Service-2和Service-3,它们分别提供一个接口,并依次调用。
Nacos将作为服务注册中心,完成服务治理。关于Nacos的部署和使用,可以参考Nacos入门指南系列文章。
依赖
项目中,与服务治理和链路跟踪相关的依赖如下:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置文件
应用配置文件中,需要指定服务注册中心的地址。
spring.sleuth.sampler.probability参数指定了链路跟踪数据的采样比例,当数值为1时,会对每一次请求进行采样,在生产环境会影响服务性能,可适当降低数值。
spring.zipkin.sender.type参数用来指定使用Kafka进行数据推送。
spring:
cloud:
nacos:
discovery:
server-addr: 192.168.3.201:8848
sleuth:
sampler:
probability: 0.5
zipkin:
sender:
type: kafka
kafka:
bootstrap-servers: 192.168.3.201:9092
链路日志
分别启动三个服务,并发起请求,查看后台日志,可以发现日志中已经添加了TraceID,SpanID等信息。
2020-03-29 00:22:58.692 INFO [hello-service,615270f0a2ce718d,615270f0a2ce718d,true] 6300 --- [io-30001-exec-3] s.s.c.sleuth.controller.HelloController : hello-service trace
2020-03-29 00:22:59.439 INFO [hello-service,f6894a35b3c948a5,f6894a35b3c948a5,true] 6300 --- [io-30001-exec-5] s.s.c.sleuth.controller.HelloController : hello-service trace
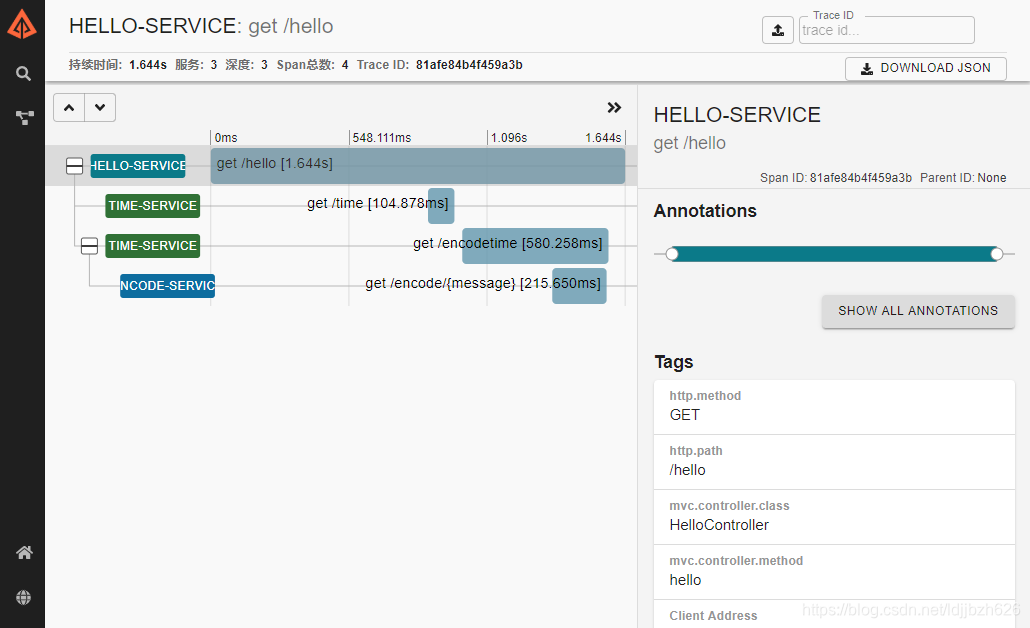
链路分析
通过Zipkin服务端界面,我们可以清晰的查看服务耗时及调用关系。