jvm
1、什么是jvm
java程序的运行环境(二进制字节码的运行环境)
2、jvm特点
1、一次编写,导出运行
2、自动管理内存,垃圾回收功能,刚开始java竞标的是c语言,c语言需要自己管理内存,不慎就会内存泄漏,java减少了程序员出错的机会
3、数组下标越界检查,c语言如果下标越界,可能覆盖其他代码的内存,非常严重。
4、多态,更多的展现了代码的可能性
3、java环境以及工具
1、jvm:是运行java程序的运行环境
2、jre:jvm所需要的核心类库
3、jdk:java开发工具包,将java编译成class文件就是jdk来处理的,jdk包含了jre,如果安装了jdk,就不需要安装再安装jre了
4、javase:配合一些像eclipse,idea等代码编写工具,就可以编写代码,但此时,仅只能在本地运行
5、javaee:配合服务器,例如Tomcat等,就可以让代码在线上执行

4、java内存结构

1、程序计数器

1、程序计数器作用
记住下一条jvm指令的执行地址,就比如上图中第一列绿色的数字,就可以理解为指令对应的内存地址,根据地址信息就可以找到命令,然后进行执行
2、代码执行流程
java源代码会被java编译成二进制字节码和jvm指令,然后将二进制字节码和jvm指令交给解释器,解释器作用是将二进制翻译成机器码,然后交给cpu来执行。
示例:如上图,比如拿到第一条getstatic指令交给解释器,解释器会把getstatic指令编译成机器码,再由cpu来执行机器码。于此同时,会将下一条指令的地址交给程序计数器,
例如,getstatic的下一条是asstore_1 asstore_1的对应地址是3,这时就会将3放入程序计数器,第一条指令结束之后,这时候解释器,就会到程序计数器中拿到下一条指令,然后再重复执行流程
3、程序计数器的实现:寄存器
寄存器是cpu中读取速度最快的单元,因为读取指令的操作是非常频繁的,java设计的时候就把寄存器当做程序计数器,用寄存器来存储地址
4、程序计数器的特点
1、线程私有的,每个线程都有自己的程序计数器
java是支持多线程运行的,当多线程执行的时候,cpu是由一个调度器组件分配时间片的,例如,
给线程1分配一个时间片,如果此时,线程1在时间片内代码没有执行完,就会把线程1的代码实现一个暂存,且狂欢到线程2执行,线程2代码执行完成了,再切换到线程1来继续执行剩余没有执行完的代码,这就是 时间片的概念,如果在线程切换的过程中,要记住下一条指令执行到哪里了,还是会用到程序计数器
例如:当线程1执行完第9条指令的时候,cpu要切换线程了,那就会把第10条指令存在程序计数器中,等待线程2执行完之后,线程1再次抢到时间片,此时线程1就会继续从第10条指令开始执行
2、程序计数器不会出现内存溢出
2、栈
1、栈的特点
1、先进后出,比如像羽毛球筒
2、垃圾回收不涉及栈内存,因为栈帧使用完后会自动释放内存
3、windows系统的栈内存大小是根据虚拟内存来定的,其他的比如linux是分配的1m为虚拟内存,栈内存划分越大不代表运行速度越快,栈内存越大,会让线程数变少。比如一共500m虚拟内存,给每个栈分1m,可以分500个线程,改成每个栈2m后,只能有250个线程了,栈内存大了,只能更多次的方法递归调用
4、看一个变量是否为安全的,只需要判断是否有多个线程可以访问同一个变量,所以在访问方法时的局部变量(不包含传参和返回的参数)是线程安全的,因为不会有多个线程能访问到同一个局部变量,但如果变量增加了static,则在线程中是共享的,static修饰的变量就是不安全的
2、栈的作用
线程运行需要的内存空间,栈会给每个线程都创建一块自己的内存空间
3、栈内的组成
一个栈内可以看成是多个栈帧组成的
4、栈帧是什么
一个栈帧就代表着一次方法的调用。线程是要执行代码的,代码又是一个一个的方法组成的,那么一个方法的执行就可以称之为栈帧
5、栈帧的执行顺序
比如调用第一个方法时,就会在栈中划分出一个栈帧空间,将栈帧压入栈中,如果此时,方法内又调用了方法二,那么就会为方法二再次创建一个栈帧,压入到方法一上,此时,等待方法二执行完,出栈,释放内存,然后会继续执行栈帧1,栈帧1执行完成,释放内存
此时需要注意的是,每个线程只能有一个活动栈帧,只会执行最后一个进入的栈帧
6、栈帧的结构
1、局部变量表
用来存放方法的参数和方法定义的局部变量
2、操作数栈
3、动态链接
4、方法返回地址
7、栈内存溢出
什么情况下会造成栈内存溢出,
1、递归没有正确结束条件,每次递归都会有一个栈帧,就会出现栈内存溢出
2、栈帧过大,可能会出现内存溢出,不容易出现
8、修改栈大小
1、在idea中可以在Application中找到VM options,然后输入 “-Xss256k”修改为你想要的数值

2、在linux中修改栈内存大小,可以找到tomcat/bin/catalina.sh,找到JAVA_OPTS修改参数

9、查看线程占用过高
比如现在执行的代码,将java代码放入linux中
1、第一步编译代码: javac Main.java
2、第二步后台运行代码:nohup java Main &
1、使用top命令可以查看到pid(进程id)

2、使用ps H -eo pid,tid,command,%cpu | grep pid 就可以获取到想要看到的线程id,tid就是线程id

3、使用jdk中提供的命令 jstack pid(进程id) 查询到所有的线程id ,不过查询到的线程id是16进制的,将第二步查询到的10进制的线程用计算器转换为16进制,就可以查到想查到的进程


10、排查线程死锁的问题
1、创建一个会产生死锁的代码,下方代码主要体现为:线程一和线程二分别拿到了自己的锁后又去锁对方的锁,此时就会出现死锁,如果看不懂,可以去看我写的关于线程和锁的两篇文章,写的比较详细
public class MainTest {
public static final String lock1 = "lock1";
public static final String lock2 = "lock2";
public static void main(String[] ars) {
Thread thread1 = new Thread(() -> {method1();}, "thread111111111");
Thread thread2 = new Thread(() -> {method2();}, "thread222222222");
//两个线程已经在外层获取到了各自的锁,再去内层获取对方锁的时候,发现被对方占用,也就造成了死锁
thread1.start();
thread2.start();
}
private static void method1() {
try{
while(true){
synchronized(lock1){
//等待时间让线程锁住
Thread.sleep(100);
synchronized(lock2){
}
}
}
}catch(Exception e){
e.printStackTrace();
}
}
private static void method2() {
try{
while(true){
synchronized(MainTest.lock2){
//等待时间让线程锁住
Thread.sleep(100);
synchronized(MainTest.lock1){
}
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}2、运行代码完成之后,发生了死锁,使用jstack 进程号id命令,查询出的结果,第一张图为查询出的线程状态,第二张图为jstack会在最后展示出所有死锁的线程


3、使用jconsole工具可以更直观的看到死锁的情况

3、本地方法栈
1、什么是本地方法栈
1、就是jvm调用一些本地方法的时候,需要给本地方法提供的内存空间。
2、本地方法的特点就是在方法前缀会有native

2、什么是本地方法
1、不是由java代码编写的代码,称为本地方法。比如像c或者c++这种语言编写的方法就是本地方法,这种代码是为了能让java能够跟更底层的功能来打交道
2、例如在基础类库中或者java引擎中都会有这些本地方法,比如最常见的Object类中clone就是调用c来实现的,还有hashCode都是本地方法
4、堆
1、什么是堆
1、堆是线程共享的,堆中的对象可能会有线程安全问题
2、通过new关键字创建的对象都会在堆中储存
3、有垃圾回收机制,对象如果不再被使用,就会被垃圾回收掉
2、堆内存溢出
1、在堆内存中,一直创建对象,但由于被其他对象引用,导致不会被垃圾回收,堆内存中对象越来越多,也就导致了堆内存溢出
例如以下代码:a + a的意思就是一直在创建a对象, a对象一直被list引用,导致不会被垃圾回收,也就会堆内存溢出了
public static void main(String[] args) {
int i = 0;
try {
List<String> list = new ArrayList<>();
//在堆内存中创建了一个hello对象
String a = "hello";
while (true){
//在list中引用了a对象
list.add(a);
//此时相当于在堆内存中创建了多个a对象,但是由于list一直在引用a对象,
//所以a对象不会被垃圾回收,随着a对象越来越多,也就内存溢出了
a = a + a;
i++;
}
}catch (Throwable e){
e.printStackTrace();
System.out.println(i);
}
}3、堆内存修改大小
idea中在VM options中增加-Xmx8m 也就相当于将堆内存修改为了8m

4、堆内存诊断
代码示例:进程启动后30秒后创建10m的byte数组,再过30秒后执行垃圾回收,用以下工具查看创建前,创建后,垃圾回收后三种状态的堆内存情况
public static void main(String[] args) throws InterruptedException {
System.out.println("第一次休眠30秒");
Thread.sleep(30000);;
System.out.println("创建一个10M的byte数组");
//在堆出现10m的内存空间 一个byte一个字节 1024字节是1k,1024 * 1024是1m, * 10就是10m
byte[] byteArr = new byte[1024 * 1024 * 10];
System.out.println("第二次休眠30秒");
Thread.sleep(30000);;
System.out.println("变量不再引用");
byteArr = null;
//垃圾回收 10m数组
System.gc();
System.out.println("执行了gc");
Thread.sleep(10000000);
}
1、jps工具
查看当前系统中所有的当前进程id

2、jmap工具
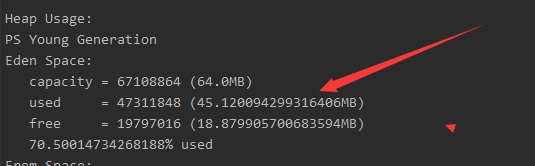
是用命令jmap -heap pid 根据进程id查看堆内存的占用情况,
![]()
maxHeapSize就是最大的堆内存量

used 箭头指的位置就是当前使用了多少堆空间
3、jconsole 工具
图形界面的监控工具
1、进程启动后 window + r 输入jconsole,打开链接的线程列表,找到想链接的进程

2、打开内存,会发现刚开始使用堆内存20多吗,30秒之后堆内存到了60多m,又过了30秒,执行了垃圾回收,降到了不到10m,这就是jconsole能看到的比较详细的使用了

4、垃圾回收之后,内存占用还是很高的处理方法
1、jvisualvm图形界面工具
堆Dump :可以查看当前时刻堆内存中的具体对象信息

找到new出来的10m的nyte数组对象


5、方法区
1、什么是方法区
1、是线程共享的
2、存储了类以及类的结构相关的信息。例如 成员变量 ,方法,成员方法以及构造方法
3、方法区在虚拟机启动时被创建,1.8之前是在堆中,1.8之后移除到了本地内存中,也就是操作系统中
2、方法区的内存溢出现象
重复生成类就会出现方法区的内存溢出,例如spring框架,mybatis框架都会用到动态产生class并加载这些类的情况
3、修改方法区内存溢出的容量
VM option中传入 -XX:MaxMetaspaceSize=8m
4、运行时常量池
1、什么是常量池
1、常量池:常量池就是一张表,虚拟机根据这张常量表找到对应的类名,方法名,参数类型等信息,就类似于数据一样
2、运行时常量池:运行时常量池就是当类被加载时,常量池中的值就会加载到内存中,此时,加载到内存中执行的常量池,称之为运行时常量池
2、以下拿helloworld代码举例,来让我们能够清晰的看到什么是常量池,常量池的作用是什么
public class MainTest{
public static void main(String[] args){
System.out.println("hello world");
}
}第一步,将java代码编译成class代码 执行: javac 类.java

第二步,反编译class代码中的字节码,获取class文件的详细信息 ,执行:javap -v 类.class
编译后的代码主要分为三部分
1、类的基本信息,主要包含了类的位置,类的版本,最后一次修改时间

2、常量池,常量池中存放的都是一些地址
第一列: #1 #2 这些都是地址,字节码要找的就是这个地址
第二列: Methodref、 Filedref等等这些都是类型,比如Class 就是类。utf8就是字符串
第三列:#6.#15这个也是地址,是前面#1引用到的地址
第四列: 双斜杠后面的是javap提供的注释,cpu不会去读取,是提供用来看的,也就是是第三列的注释。当运行到运行时常量池中,就会将这些符号编译成真正的代码,也就是注释中这些

3、类方法定义,例如构造方法,引用等,下图举例:

1、例如上方public template.MainTest(); 默认的构造方法
2、下图就是方法的指令了
第一列的0,1,4,就是程序计数器要读取的地址,上方提到的程序计数器要读的就是这个
第二列的一步一步解释:
getstatic:就是指获取一个静态变量,就像第四列注释的,其实就是获取System.out静态变量
ldc:是加载一个参数,就像后方注释的 加载的就是helloworld字符串
invokevirtual:是执行一次方法调用,就是调用的System.out静态方法中的println方法
return:主方法也就表示结束了

3、接下来就要看第三列了,这个是解释上方的常量池最重要的一个点,我们拿第三列的第一个#2来举例,其实这里的#2也就是调用的上方常量池中的#2,作比较之后,会发现后方注释中的代码也就是#2引用的代码,下图解释:
#2引用了#16和#17,第一个#16引用了#23,#23是java/lang.System,第二个#17引用了#24和#25,以此类推,
最终拼起来就是Field java/lang/System.out:Ljava/io/PrintStream;这样也就拼成了第一句字节码,然后就可以进行接下来的交给cpu执行了

5、StringTable(字符串池)
1、StringTable是在运行时常量池中,这里存放的是字符串。需要注意的是:比如String s = "a"; 此时"a"就会在StringTable中存放,而不会在堆中存放,new String("a")会在堆中存放,不会在StringTable中存放。
public static void main(String[] args) {
String a = "a"; //StringTable中
String b = new String("a" ); //堆中
System.out.println(a == b); //false
}2、StringTable中的字符串是不会重复的,比如StringTable中已经存放了一个["a"],那此时如果再次调用String b = "a",这个b会直接拿池中的"a",而不会再次创建
public static void main(String[] args) {
String a = "a"; //StringTable中
String b = "a"; //直接拿StringTable中的"a"
System.out.println(a == b); //true
}3、StringTable是懒汉式的,执行时才会向StringTable中存放数据,不是初始化就存放数据的
public static void main(String[] args) {
String a = "a"; //运行到该行,StringTable中存入"a"
String b = "b"; //运行到该行,StringTable中存入"b"
}4、jdk会在代码编译时对常量进行优化,例如 String a = "a" + "b";那么代码编译时就会直接编译为了String a = "ab";
public static void main(String[] args) {
String a = "a" + "b"; //此时编译后为ab
} ![]()
5、字符串有一个intern()方法,该方法执行的效果为,如果StringTable里面有相同的值,则返回StringTable的该值,不再去创建。 如果StringTable里面没有该值,则在StringTable中创建该值,然后返回添加后的StringTable中的值
6、面试题1
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s3 == s6);
}分析: s3 == s4?
s3创建后,编译器优化为了 ab 存入了字符串常量池。s4相当于拼接s1和s2两个变量,在常量池中会编译为new StringBuilder().append("a").append("b").toString(),toString()方法其实就是new String(),也就是在堆中创建了"ab"这个对象。
以此证明,s3是在字符串常量池中,s4是在堆中,也就为false
分析:s3 == s5?
s5此时会在字符串常量池中寻找是否有ab这个字符串的,如果有就直接拿。此时,s3正好被编译器编译为了 ab 存入了字符串常量池中,拿的是相同的对象,也就为true
分析:s3 == s6?
s6是执行堆中的s4的intern()方法返回的,intern()会寻找常量池中是否有ab字符串,如果有,则直接返回,没有,则创建ab后返回,由于s3已经在字符串常量池创建了ab,也就直接返回了字符串常量池的ab,也就和s3的ab相等,为true
7、面试题2
public static void main(String[] args) {
String x2 = new String("c") + new String("d");
x2.intern();
String x1 = "cd";
System.out.println(x1 == x2 );
}分析:x1 == x2?
x2是堆中的 cd 。但由于x2执行了intern()方法,就将cd,传入到了字符串常量池中。 x1在创建字符串常量池中的时候,发现常量池中有cd,也就直接拿了常量池中的cd,由于都是同一个cd,也就为true
分析如果调换了位置
public static void main(String[] args) {
String x1 = "cd";
String x2 = new String("c") + new String("d");
x2.intern();
System.out.println(x1 == x2 );
}分析:x1 == x2?
x1首先在字符串常量池中创建了cd,x2是堆中的cd,x2执行intern()发现字符串常量池中有,也就没有放入成功, x1是字符串池中的,x2是堆中的,结果也就为false
8、面试题3
public static void main(String[] args) {
str();
builder();
}
private static void str() {
long start = System.nanoTime();
String str = "";
for (Integer i = 0; i < 100000; i++) {
str += i.toString();
}
System.out.println("str:" + (System.nanoTime() - start));
}
private static void builder() {
long start = System.nanoTime();
StringBuilder str = new StringBuilder();
for (Integer i = 0; i < 100000; i++) {
str .append(i.toString()) ;
}
System.out.println("builder:" + (System.nanoTime() - start) );
}分析:既然String底层优化成了拼接,那是否直接+就会很快不需要用StringBuilder.
解答:javap -v后查看到的代码如下,发现原来string的拼接虽然编译器编译成了StringBuilder.append,但是是在内部进行的拼接,每次都要创建两个对象,一个对象是StringBuilder,另一个是StringBuilder.toString的内部会newString。这也就导致了速度很慢
