垃圾回收
1、垃圾回收前需要先了解的知识:
public static void main(String[] args) {
int i = 0;
try {
} catch (Throwable e){
e.printStackTrace();
}finally {
System.out.println(i);
}
}1、增加-XX:+PrintStringTableStatistics 展示字符串池中的个数 以及大小信息
2、增加-XX:+PrintGCDetails -verbose:gc 打印垃圾回收的详细信息
3、 heap:内存占用情况
1、PSYoungGen新生代:总大小:2560K 使用了:1566k
2、ParOldGen老年代:总大小7168k,使用正常

3、SymbolTable statistics:符号表,类的字节码中有哪些类名,方法名等

4、StringTable statistics:字符串池的统计信息(重点)
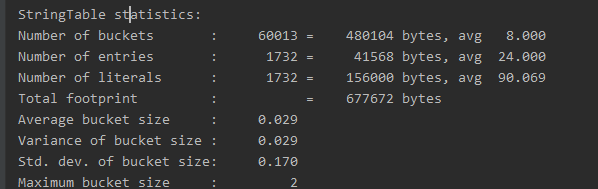
字符串池在底层是hashTable的格式,hashTable是数组加链表的格式,数组的个数,称之为筒
Number of buckets(初始化数组 ): 60013个
Number of entries(当前数组的个数):1732个
Number of literals(字符串个数):1732个
Total footprint(总占用):676240 bytes
当此时新增100个对象intern()后,就会变成1832个,很明显看出区别。如果不intern()则不会进入常量池也就没有区别
public static void main(String[] args) {
int i = 0;
try {
for (int j = 0; j < 100; j++) {
String.valueOf(j).intern();
}
} catch (Throwable e){
e.printStackTrace();
}finally {
System.out.println(i);
}
}2、查看垃圾回收效果
1、将堆内存调整为10m:-Xmx10m
2、尝试往字符串常量池中存入10000个对象
public static void main(String[] args) {
int i = 0;
try {
for (int j = 0; j < 10000; j++) {
String.valueOf(j).intern();
}
} catch (Throwable e){
e.printStackTrace();
}finally {
System.out.println(i);
}
}3、正常字串符个数应该增加10000个,可结果为以下2520个,结果不对,所以,是出发了垃圾回收,查看最上方
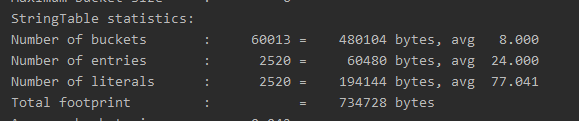
4、最上方发现GC为垃圾回收,下方解释为:新生代垃圾回收,从2048回收到了488k,times为时间![]()
3、StringTable性能调优
1、数组数量越少,hash碰撞的可能性就越大,hash碰撞后,形成了链表,链表越长,查询速度就会收到影响
增加数组的容量 -XX:StringTableSize=200000 之前默认为60000个
2、如果可能会有重复,内存占用优化,减少堆占用,存入StringTable中
如果有10万条数据,如果是存入堆,那就是30万数据。由于字符串池中是不重复的,所以将数据存入字符串池中,
重复数据过滤,也就实现了内存占用优化。调用intern()
4、直接内存调优
1、什么是直接内存
直接内存是操作系统内存,不受JVM内存回收管理,分配回收需要自己来实现,读写性能高,复制以下代码测试直接内存和io的速度
private static String FROM = "文件位置";
private static String TO = "赋值到哪";
private static int _1MB = 1024 * 1024;
public static void main(String[] args) {
byteBuffer(); //196.8509
io(); //520.2458
}
private static void byteBuffer() {
long startTime = System.nanoTime();
try (
FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1MB);
while (true) {
int len = from.read(byteBuffer);
if (len == -1) {
break;
}
byteBuffer.flip();
to.write(byteBuffer);
byteBuffer.clear();
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("直接内存用时:" + (System.nanoTime() - startTime) / 1000_000.0);
}
private static void io() {
long startTime = System.nanoTime();
try (FileInputStream from = new FileInputStream(FROM);
FileOutputStream to = new FileOutputStream(TO)) {
byte[] buf = new byte[_1MB];
while (true) {
int len = from.read(buf);
if (len == -1) {
break;
}
to.write(buf, 0, len);
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("io用时:" + (System.nanoTime() - startTime) / 1000_000.0);
}2、为什么直接内存会比io读取会快
io:下图为例,java读取文件时,会首先调用操作系统提供的方法,也就是本地方法区的方法,之后将磁盘文件分次读取到系统缓冲区中,然后将系统缓冲区的文件读取到java的缓冲区中,由于是两块缓冲区,也就导致了慢

直接内存:当调用ByteBuffer.allocateDirect方法时,也就意味着在系统内存这边划分一块直接内存区域,这块区域的 特点是可以在java代码可以直接访问,磁盘文件可以直接将文件读取到直接内存中,java可以直接从直接内存中获取到,少了一步读取到java缓冲期中,也就更快了

3、不受jvm垃圾回收管理
static int _1G = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1G);
System.out.println("分配了直接内存1G");
System.in.read();
byteBuffer = null;
System.out.println("开始释放内存");
System.gc();
System.in.read();
}1、上方代码分配了直接内存之后,发现idea新增了1g的内存,执行了垃圾回收之后,发现就会释放了

2、执行完垃圾回收后,直接内存释放的原因
1、实际上ByteBuffer内部是调用Unsafe类来执行的对直接内存的操作,而unsafe必须调用freeMemory方法才可以释 放内存那接下来就看下ByteBuffer.allocateDirect内部是如何操作的
static int _1GB = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
//获取操作直接内存的类
Unsafe unsafe = getUnsafe();
//分配1g直接内存 返回分配的地址
long base = unsafe.allocateMemory(_1GB);
unsafe.setMemory(base,_1GB,(byte) 0);
System.in.read();
//根据地址释放内存 直接内存必须调用释放内存的方法才可以释放
unsafe.freeMemory(base);
System.in.read();
}
public static Unsafe getUnsafe() {
try {
//获取到theUnsafe字段
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
Unsafe o = (Unsafe)theUnsafe.get(null);
return o;
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
return null;
}2、allocateDirect 只new了一个DirectByteBuffer

可以看到这里面直接调用了unsafe方法,写的和上面的unsafe调用类一模一样,下方还调用了一个叫Cleaner类,
这个类为虚引用对象,虚引用的特点为,当虚引用对象被垃圾回收时,会执行类中的run方法

此时看到run方法就恍然大悟了,就是调用了freeMemory方法来回收的直接内存,而不是用的jvm的垃圾回收

2、垃圾回收
1、判断对象是否可以回收的算法
1、引用计数法
只要一个对象被其他对象所引用,就让这个对象计数+1,如果其他对象不再引用,这个对象计数-1,当计数 为0时,就代表可以回收了
弊端:
当a对象引用b,b对象引用a,这样就会导致两个对象引用计数都是1,也就造成了a,b对象内存不会被回收
2、可达性分析算法
1、首先要确定根对象,在垃圾回收前,会对堆中所有的对象进行扫描,查看每个对象是否被根对象直接或 者间接的引用,如果是,不能被回收,否则,就可以被回收
2、哪些对象可以被认定为根对象
1,栈帧中的引用对象
2,方法区中的类引用的对象
3,本地方法栈中引用的对象。
2、四种引用对象的方式
1、强引用
String a = "a"; 这种就是强引用
特点:是当根对象正在关联该对象,则不会被垃圾回收
2、软引用
1、当第一次垃圾回收后,发现内存还是不够,还会再次进行垃圾回收,此时会把软引用的对象回收。
2、可以配合引用队列进行操作,当引用的对象回收后, 自己本身虽然为null,但也是一个对象,配合引用队列后,可以将自身清理
3、举例:从下图中可以看出第四次存入软引用对象时发现内存不足了,也就导致了第一次垃圾回收,新生代从4774K 清理成了 4558K,老年代从12476K清理成了12444K,发现还不足,也就导致了第二次的垃圾回收,这次回收就将软引用对象清理了,可以看出新生代直接清理为了0,老年代也直接清理为了601k。二次调用查看对象时可以发现也只有第5个存成功了
static int _4M = 1024 * 1024 * 4;
public static void main(String[] args) throws IOException {
List<SoftReference<byte[]>> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
//SoftReference 弱引用对象 当内存不足时 会释放该对象
SoftReference softReference = new SoftReference<>(new byte[_4M]);
list.add(softReference);
System.out.println("添加【"+(list.size())+"】时 : " + softReference.get());
}
System.out.println("===============");
for (SoftReference<byte[]> softReference : list) {
System.out.println("调用时:" + softReference.get());
}
}
4、配合引用队列,将为null的也就是已经被垃圾回收的引用队列从list中清除
static int _4M = 1024 * 1024 * 4;
public static void main(String[] args) {
//引用队列
ReferenceQueue<byte[]> queue = new ReferenceQueue<>();
List<SoftReference<byte[]>> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
//当软引用所关联的byte数组被回收时,软引用本身会加到ReferenceQueue中
SoftReference softReference = new SoftReference<>(new byte[_4M],queue);
list.add(softReference);
System.out.println("添加【"+(list.size())+"】时 : " + softReference.get());
}
//会返回第一个传入的引用对象
Reference<? extends byte[]> poll = queue.poll();
//当引用对象不为null时,也就证明引用对象已经被清理而且加入到了引用队列中
while (poll != null){
//删除被清理的引用对象
list.remove(poll);
//返回下一个引用对象
poll = queue.poll();
}
System.out.println("===============");
for (SoftReference<byte[]> softReference : list) {
System.out.println("调用时:" + softReference.get());
}
}3、弱引用
当垃圾回收时,不管内存是否充足,都会把弱引用垃圾回收,也可以和引用队列配合使用
举例:发现第四次内存不足时,直接调用了垃圾回收,但这次没有像软引用一样,第二次才将对象清理,而是第一次就将对象直接垃圾回收了
static int _4M = 1024 * 1024 * 4;
public static void main(String[] args) {
//引用队列
ReferenceQueue<byte[]> queue = new ReferenceQueue<>();
List<WeakReference<byte[]>> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
//当弱引用所关联的byte数组被回收时,弱引用本身会加到ReferenceQueue中
WeakReference softReference = new WeakReference<>(new byte[_4M],queue);
list.add(softReference);
System.out.println("添加【"+(list.size())+"】时 : " + softReference.get());
}
//会返回第一个传入的引用对象
Reference<? extends byte[]> poll = queue.poll();
//当引用对象不为null时,也就证明引用对象已经被清理而且加入到了引用队列中
while (poll != null){
//删除被清理的引用对象
list.remove(poll);
//返回下一个引用对象
poll = queue.poll();
}
System.out.println("===============");
for (WeakReference<byte[]> softReference : list) {
System.out.println("调用时:" + softReference.get());
}
}
4、虚引用
必须配合引用队列来使用,例如之前说的直接内存调用,ByteBuffer.allocateDirect中使用的Cleaner,就是虚 引用对象,当虚引用对象被清理时,虚引用本身会进入引用队列中,随后会被一个专门的线程去查找引用队列中新添加的虚引用,调用虚引用对象的clean方法
3、垃圾回收算法
1、标记清除算法
先标记出没有引用的对象标记出来,之后再清除
优点:清除速度快,因为只需要标记后清除
弊端:清除后会有多个内存碎片,清除后不会整理,再想放进去只能寻找足够的空闲位置

2、标记整理
先标记出没有引用的对象标记出来,再整理有用的对象,将对象按顺序排列,最后清除没有引用的对象
优点:不会有内存碎片
缺点:有了整理这一步,会将对象地址改变,效率就会慢

3、复制
会将内存区域分为两部分,一个是from,一个是to,首先将不被引用的对象标记为垃圾,然后将from存活的对象 复制到to中,复制到to中的会整理,然后清除from中的对象,最后将to和from交换
优点:不会产生碎片
缺点:会占用双倍的内存空间

4、JVM分代垃圾回收
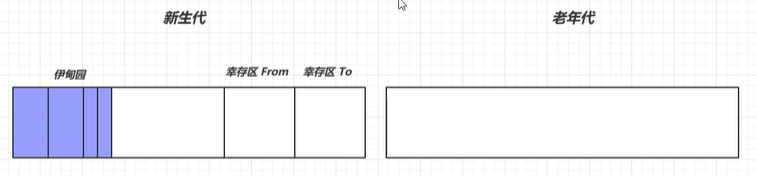
1、伊甸园
刚创建好的对象就会进入到伊甸园中,当执行新生代(Minor GC)垃圾回收时,没有引用的对象就会被清理
2、幸存区
当执行完一次新生代垃圾(Minor GC)回收后,还有引用存活的对象会进入到FROM中,然后标记FROM中没有引用的对象,之后将有引用的放入到TO中,会将有引用的对象寿命+1,清除from中的对象,然后将TO的内存和From进行交换
3、老年代
1、当幸存区中的对象寿命超过了预值(默认为15)后,会将幸存区对象晋升到l老年代中,当老年代对象也满了,此时会执行老年代垃圾回收(Full GC),老年代垃圾回收会将所有的内存进行回收
2、大对象直接进入老年代
4、特点
当执行垃圾回收时,所有线程都会停止,等垃圾线程执行完其他线程才能恢复运行
5、垃圾回收参数

5、垃圾回收器
1、串行(标记+整理)
1、是单线程的
2、堆内存小,适合个人电脑
3、由于是单线程的,当执行垃圾回收时,其他线程都会到阻塞状态
4、-XX:+UseSerialGC 新生代为复制算法,老年代为标记整理算法

2、吞吐量优先(1.8默认回收器)(标记+整理)
1、多线程并行执行,执行时垃圾回收器一拥而上,一起处理垃圾,可能会出现cpu突然增高的情况
2、堆内存大,适合服务器
3、每次工作时间比较长,然后一次休息够,就好像一次充满,用完再充电
4、-XX:+UseParallelGC 或者 -XX:+UseParallelOldGC,开启其中一个就可以 新生代为复制算法,老年代为标记整理算法
5、-XX:+UseAdaptiveSizePolicy 动态调整新生代的内存大小,还有晋升阈值等
6、-XX:GCTimeRatio=1 调整垃圾回收时间和总时间的占比 1/(1+ratio)公式,ratio的默认值为99, 1/(1+99) = 0.01 也就是垃圾回收时间不能超过总时间的百分之1,
100分钟只能有1分钟在垃圾回收,如果超过这个比例,垃圾回收器就会自动调整堆的大小已达到目的,一般是将堆增大 一般可以设置为19
7、-XX:MaxGCPauseMillis=100 每次最大垃圾回收时间
8、-XX:ParallelGCThreads 同时执行垃圾回收器的线程数

3、响应时间优先(cms)(标记+清除)
1、由于是标记清除算法,会产生内存碎片,在内存碎片比较多的情况下,造成将来分配对象时,新生代内存和老年代内存都不足,会造成并发失败,采取补救措施.让cms进行一次串行的垃圾回收(标记+整理),然后再进行cms清理,调用串行垃圾回收叫fullGC
2、运行流程
1、初始标记,只初始化一些根对象,其他线程都是阻塞的,速度比较快,基本不会影响用户使用
2、并发标记,用户线程恢复运行,不影响用户使用,垃圾回收线程还可以继续标记那些剩余的没有标记的垃圾
3、重新标记,所有线程都会重新标记,重新标记的意义在于并发标记时其他线程也在运行,其他线程工作时也可能有产生一些垃圾,此时把那些产生的垃圾标记
4、并发清理,用户线程可以正常运作,垃圾回收线程把标记好的垃圾回收。由于其他用户线程还在继续运行,用户线程运行时可能会出现新的垃圾,此时创建的新的垃圾只能下次垃圾回收再清理
3、-XX:+UseConcMarkSweepGC(标记清除) ~ -XX:UseParNewGC(复制) 垃圾回收时其他用户线程某些时间也可同时运行
-XX:ParallelGCThreads=n 同时执行垃圾回收器的线程数
-XX:ConcGCThreads=threads 同时执行垃圾回收的线程数 建议设置1 比 4的比例 1个垃圾回收服务4个线程
-XX:CMSInitatingOccupancyFraction=percent 执行垃圾回收的内存占比 只要老年代的垃圾到达一定程度 就会执行垃圾回收
-XX:CMSScavengeBeforeRemark 初始标记前,先执行一次新生代垃圾回收

4、G1(jdk9默认)(整体是标记+整理算法,两个区域之间是标记+复制算法)
1、同时注重吞吐量和响应时间
2、-XX:MaxGCPauseMillis=ms设置最大暂停时间
3、-XX:UseG1GC 开启g1
4、-XX:G1HeapRegionSize=size 每个区域的大小
5、当垃圾回收速度比创建垃圾速度慢时,会调用串行垃圾回收,此时,才会产生fullGC,否则不会产生fullGC
6、会将堆划分为三个阶段,三个阶段是一个循环的过程,每个阶段都可以划分为伊甸园 幸存区 老年代
1、新生代垃圾回收阶段(Young Collection)(新生代对象占满会产生)
1、白色代表空闲区域,E为伊甸园,当E占满后,会触发新生代垃圾回收。
2、S为幸存区,清理时会将未清理对象以复制的算法复制到幸存区中。
3、O为老年代,当幸存区也不足时,幸存区到达阈值的会进入老年代,大对象也会直接进入老年代

2、新生代垃圾回收 同时 并发标记阶段(Young Collection + Concurrent Mark)(老年代对象内存占到一定阈值)
1、垃圾回收过程中,会对对象进行初始标记和并发标记
2、初始标记
标记根对象,会在新生代垃圾回收时
3、并发标记
根对象下的关联的对象,当老年代内存比例到达阈值,才会发生。标记时不会产生线程暂停
4、-XX:InitiatingHeapOccupancyPercent=percent (默认45%)
老年代占用到百分之45时就会并发标记

3、混合回收 (Mixed Collection )(伊甸园,幸存区,老年代全面垃圾回收)
1、重新标记,和cms一样,并发标记时用户线程也会产生新的对象,将并发标记过程中,可能会漏的垃圾对象,进行最终标记,会STW
2、拷贝存活,伊甸园会用复制算法复制到新的幸存区,幸存区中没有到达年龄的也会复制到新的幸存区,老年代也会复制到新的老年代。优先会根据最大暂停时间将老年代垃圾最多的的进行复制,复制的区域少,也就能达到最大暂停时间,此段时间会STW
3、当垃圾回收速度比创建垃圾速度慢时,才可以理解为full GC

7、新生代回收跨代引用(cart表)
1、要想查找对象,首先要找根对象,跟对象可能会来自于老年代,老年代存活对象可能会比较多,也就导致效率查找老年代对象效率低
解决方案:使用了一个cart表的技术,将老年代继续细分,分成一个个的cat如果老年代引用了新生代对象,将老年代的cart标记为脏cart,下次直接找根对象就可以直接找脏cart区域就可以了,减少了查找的范围
2、如何标记脏cart
每次对象的引用发生变更,异步更新脏cart

6、类加载器
类加载器会有层级的关系,会优先上级加载,如果上级加载过该类,则由上级加载类
双亲委派就是上下级的关系,上级加载了类就不会加载下级的类
双亲委派好处:保证加载了上级就不会再加载下级。 也防止了 如果下级写了同样的类,绝对会加载的是上级的类
1、Bootstrap ClassLoader 启动类加载器 (jre/lib下的类) 无上级
打印为null,这就是启动类加载器加载的
public static void main(String[] args) throws ClassNotFoundException {
Class<?> aClass = Class.forName("java.lang.Integer");
//打印 null
System.out.println(aClass.getClassLoader());
}2、Extension ClassLoader 拓展类记载器(jre/lib/ext下的类) 上级为Bootstrap ClassLoader
将类达成jar包放入ext包中,测试拓展类加载器
打包:jar -cvf my.jar 文件class 并放入 ext文件夹下,注意打包后的类包名要一致

打印结果为extClassLoader,也就测试出了如果拓展类加载器有,则不调用应用程序类加载器
public static void main(String[] args) throws ClassNotFoundException {
Class<?> aClass = Class.forName("template.P");
//sun.misc.Launcher$ExtClassLoader@7f31245a 也就是ExtClassLoader
System.out.println(aClass.getClassLoader());
}3、Application ClassLoader 应用程序类加载器 (类路径下的类) 上级为Extension ClassLoader
打印为AppClassLoader,是由应用程序类加载器加载的
public static void main(String[] args) throws ClassNotFoundException {
Class<?> aClass = Class.forName("template.P");
//sun.misc.Launcher$AppClassLoader@18b4aac2 也就是AppClassLoader
System.out.println(aClass.getClassLoader());
}4、自定义类加载器 上级为Application ClassLoader
1、什么情况下会使用自定义类加载器
1、加载任意路径下的类
2、希望可以实现解耦
3、可以隔离不同应用的同名类都可以加载,例如Tomcat
public class MainTest {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
MyClassLoader myClassLoader = new MyClassLoader();
Class<?> p = myClassLoader.loadClass("P");
P o = (P)p.newInstance();
System.out.println(o);
}
}
class MyClassLoader extends ClassLoader{
protected Class<?> findClass(String name) throws ClassNotFoundException {
//自己的类文件位置
String fileUrl = name = "d:\\" + name + ".class";
//获取Path类
Path path = Paths.get(fileUrl);
System.out.println("path : " + path);
//将路径下的文件复制到输出流中
ByteArrayOutputStream os = new ByteArrayOutputStream();
try {
Files.copy(path,os);
} catch (IOException e) {
e.printStackTrace();
}
//输出流获取到字节数组
byte[] bytes = os.toByteArray();
//父类的defineClass可以将流转换为class文件
Class<?> aClass = defineClass(name, bytes, 0, bytes.length);
return aClass;
}
}2、步骤
1、继承ClassLoader
2、重新findClass方法,不能重新loadClass 否则不走双亲委派
3、读取类文件字节码
4、调用父类defindClass加载类
5、调用该类的loadClass来加载类
5、类加载器源码
先看前半部分

1、第一遍加载P这个类,是使用的app类加载器
2、发现有上级ext,就执行了ext的loadClass
3、ext再执行到parent时,发现没有上级了,执行boot启动类加载器
后半部分

3、boot不会执行下半部分代码,因为是c代码。也就返回到了ext执行findClass代码,ext执行findClass发现没有找到P对象也就返回到了app加载器中
4、app加载器执行findClass对象时,找到了P,也就返回了
//加载类 第一次加载使用的是应用程序加载器
protected Class<?> loadClass(String name, boolean resolve){
synchronized (getClassLoadingLock(name)) {
// findLoadedClass是先从缓存中查找是否有个这个类,第一次肯定没有
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
//判断是否有上级,应用程序加载器上级为拓展类加载器
if (parent != null) {
c = parent.loadClass(name, false);
} else {
//如果没有了上级,那就找启动类加载器
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
//如果没有找到 不做处理
}
if (c == null) {
long t1 = System.nanoTime();
//以上都没有找到,到当前类加载器的findClass里找
c = findClass(name);
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}6、线程上下文类加载器
1、拿DriverManager类来举例,发现打印后是启动类加载器加载的DriverManager,因为mysql-connector-java包不在启动类加载器中,DriverManager是如何加载到一个应用类加载器中的com.mysql.jdbc.Driver的?
System.out.println(java.sql.DriverManager.class.getClassLoader()); // null 启动类加载器2、实际上使用的app应用程序类加载器加载的
ClassLoader.getSystemClassLoader():这个就是应用程序类加载器

3、ServiceLoader
创建 META-INF/service/java.sql.Driver 里面填写接口的实现类

遍历之后就可以拿到该接口下所有的实现类了,这里其实用的是线程类上下文类加载器,也不是启动类加载器,所以就可以实现了调用应用程序类
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
while(driversIterator.hasNext()) {
driversIterator.next();
}7、反射优化
1、调用invoke()方法时,内部会调用MethodAccessor方法访问器,该方法访问器16次内调用效率是比较低,原因是会调用本地方法 invoke0,当执行了大于15次后,会将本地方法付访问器替换成运行期间动态组成的新的方法访问器,替换了原来的方法访问器,原 因是生成的代码内部直接会执行方法,直接调用方法会速度快
2、15次是可以直接设置的,也是可以直接生成新的方法访问器,但是不建议修改,因为生成新的方法访问器需要时间,如果访问次 数少就没有必要

public class MainTest {
public static void foo(){
System.out.println("foo........");
}
public static void main(String[] args) throws IllegalAccessException, InstantiationException, NoSuchMethodException, InvocationTargetException, IOException {
Method foo = MainTest.class.getMethod("foo");
for (int i = 0; i < 16; i++) {
foo.invoke(null);
}
System.in.read();
}
}
8、JMM java内存模型
定义了一套在多线程读写共享数据时,对数据的可见性,有序性,和原子性的规则和保障,和内存结构没有什么关系
1、 原子性
使用synchronize关键字,同一时间段只有一个线程可访问,既能保证可见性,也能保证原子性
2、可见性(volatile)
1、t1线程会频繁的去主内存中获取run的值,运行时编译就会做优化,将run放入了t1的高速缓存中,提高效率,之后主线程将主线程中的run改成了false,t1还是在拿高速缓存中的run,也就不会停止了
2、可以使用volatile修饰的变量是每次都读的主线程的run volatile是保证的可见性,一个线程对变量的修改对下一个线程是可见的,不能保证原子性
public class MainTest {
volatile static boolean run = true;
public static void main(String[] args) throws InterruptedException {
new Thread(() ->{
//正常主线程将run修改为false,这里会跳出循环,如果不加volatile关键词,就退不出
while (run){}
},"t1").start();
Thread.sleep(1000);
run = false;
}
}3、有序性
jvm可能会对比较耗时的操作往后排,例如num + num,出现这种情况称之为“指令重排”
1、举例下方代码,可能会出现num = 0,可能线程2执行了ready = true,又执行了num = num + num,结果就为0
解决方案:ready增加volatile关键字,就不会再出现指令重写的可能了
int num = 0;
boolean ready = false;
void run1(){
if (ready){
num = num + num;
}else{
num = -1;
}
}
void run2(){
num = 2;
ready = true;
}4、CAS
CAS(比较与交换),体现了乐观锁的思想,比如多个线程对一个变量执行+1的操作
1、每次修改会判断传入值+1是否等于结果值,如果是等于,那么返回false,如果为true,则会继续循环,直到结果正确
2、为了保证可见性,需要使用volatile修饰,结合CAS和volatile可以实现无锁并发,适用于竞争不激烈,多核cpu的情况,因为没有多核cpu,可能会导致其他线程在阻塞
3、因为对比sync少了切换锁的时间,所以效率是比sync效率高的
int params = 0;
while (true){
int result = params + 1;
//每次修改会判断传入值+1是否等于结果值,如果是等于,那么返回false,如果为true,则会继续循环,直到结果正确
if(compareAndSwap(params,result)){
break;
}
}5、乐观锁是悲观锁
1、乐观锁
CAS就是乐观锁,不怕别的人修改,哪怕你改了,我再重试一次就行
2、悲观锁
synchronize就是悲观锁,拒绝别的线程修改,只要自己拿到,你们都别动
6、原子操作类
java.util.concurrent提供了一系列安全的操作类,可以提供线程安全的操作,例如AtomicInteger,AtomicLong,底层都是用CAS +volatile实现的
7、synchronize优化
在JDK1.6以后,为了减少消耗,锁进行了很多的升级。并且有了四种状态,从低到高
1、无锁状态
锁标志头为01,是否偏移锁为0,也就是不属于偏移锁
2、偏向锁
研究发现,一些锁不仅不会被多线程竞争,并且每次都是被同一个线程锁使用,为了让这个线程获得这个锁的代价变低,而引入了偏向锁。
顾名思义,偏向就是偏心的意思,为这一个线程偏心的锁
过程:
1、当锁被这个线程获取到的时候,将线程id记录到偏向锁中,下次判断还是这个线程id,就直接进行同步。
2、如果有其他线程要访问时,也就发生了竞争,此时会将轻量锁升级为轻量锁
3、轻量锁
1、当偏向锁发生竞争升级为轻量锁,轻量锁每次退出都会释放锁,而偏向锁退出不会释放锁,退出才会释放
2、当有其他锁竞争时,会先进行自旋,多次判断锁是否为占用状态,此时线程不会阻塞,如果多次自旋还是没有拿到锁,才发生阻塞,此时会将轻量锁升级为重量锁
4、重量锁
没有自旋,当有其他线程竞争时,直接进入阻塞
9、逃逸分析
jvm执行分为解释器转换为字节码,和即使编译器(JIT)转换为字节码
解释器转换为字节码:每次遇到同样的代码,都会重复的解释
即使编译器转换字节码:下次遇到同样的代码,直接执行,不需要重复编译
代码举例: 打印结果 刚开始是327100,到最后只需要3500,证明后面根本没有执行new Object,因为即使编译器判断这段代码无用,就不再编译了
关闭逃逸分析:-XX:-DoEscapeAnalysis
public static void main(String[] args) {
for (int i = 0; i < 200; i++) {
long start = System.nanoTime();
for (int j = 0; j < 10000; j++) {
new Object();
}
System.out.println(System.nanoTime() - start);
}
}