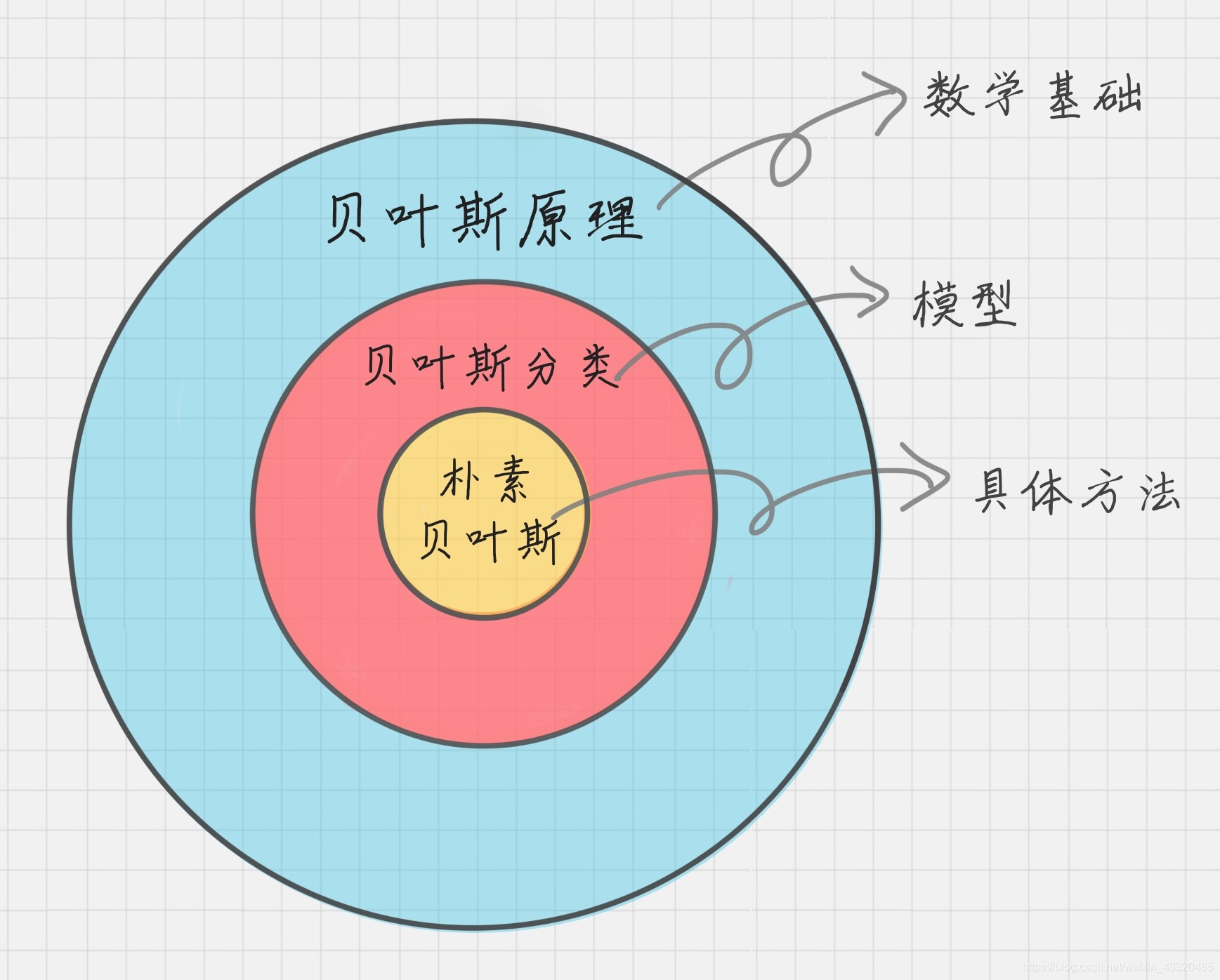
知识框架来源:人工智能之数据挖掘
其他补充来源:拿下Offer-数据分析师求职面试指南、数据分析实战45讲
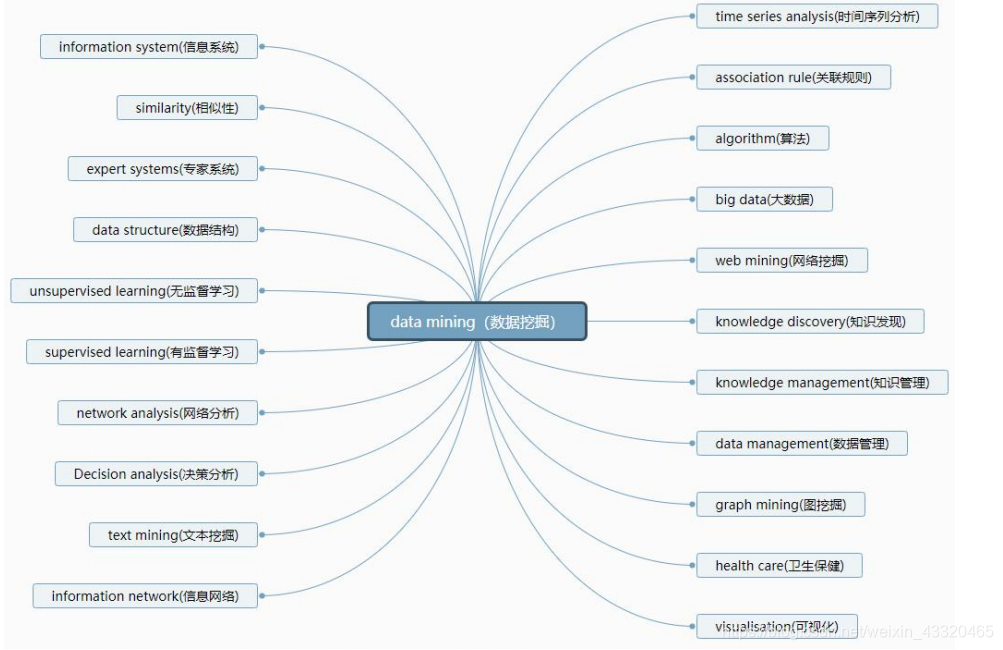
Data Mining
概述篇
基础认知
-
广义:
一类深层次的数据分析方法 -
目的:
自动抽取隐含的、以前未知的、具有潜在应用价值的模式或规则等有用知识 -
涉及学科
使用人工智能、机器学习、统计学和数据库等交叉学科领域方法 -
对象
大规模、不完全、有噪声、模糊随机的数据集。 -
核心过程:
(1) 数据清理:消除噪声和删除不一致数据。
(2) 数据集成:将多种数据源组合在数据仓库。
(3) 数据选择:定义问题,从数据库中提取与分析任务相关的数据。
(4) 数据变换:分析整理数据。通过汇总或聚集操作把数据变换、统一成适合挖掘的形式。
(5) 数据挖掘:使用智能方法提取数据模式。
(6) 模式评估:根据某种度量,识别代表知识的模式。
(7) 知识表示:使用可视化与知识表示技术,向用户提供挖掘的知识。 -
挖掘的核心
建模:另利用用模型学习已知数据集中的变量特征,并通过一系列方法提高模型的学习能力,最终对一些结果位置的数据及输出相映的结果。 -
数据集
- 训练集
训练模型 ,用于模型训练拟合的样本,占总体样本的百分之七十到百分之八十 - 验证集
模型调试 ,结果已知不参与模型训练拟合,用于验证训练后模型的拟合效果。对模型中的超参数进行选择。在实际工作中 - 测试集
验证结果,利用模型输出结果的数据集模型上线后,输出测试集的结果与最终结果进行对比。测试及后续可以转换为训练集或验证及实现模型的循环迭代。
- 训练集
-
模型评估
- 过拟合Overfitting
样本量相对于模型复杂度较小,样本噪声导致复杂模型的泛化能力较差 。训练集只是全部数据的抽样,而且存在噪声,该噪音不具有通用性并不能体现全部数据的特点,当模型过于复杂时,会太依赖于训练集,也会大量学习训练其中的噪音,并当成所有数据的特点。结果过于精准,容错率就会比较低,导致分化能力变差。
泛化能力是指:分类器是通过训练集抽象出来的分类能力。模型的“泛化能力”差,模型的训练结果过分精准,以至于存在“死板”的情况,在实际应用的过程中,会导致分类错误。 - 欠拟合
表明模型过于简单,没有很好的拟合训练集变量之间的特征。需要进一步提高复杂度。
- 过拟合Overfitting
-
参数
- 参数
通过模型对训练集的拟合获得,比如线性回归模型中斜率和截距。 - 超参数
无法通过模型获得在模型训练前仍为给定的超参数,只能通过验证及进行验证并最终决定:决策树的深度、随机森林模型中树的数量的。
- 参数
-
参数调整
- 工作量大 :
模型调整参数,是一个非常耗时的工作,需要综合考虑模型效果,实现复杂度以及工作量。 - 复杂度
模型属性数相对于训练集数,复杂的模型未必能带来好的结果,也可能使得模型出现过拟合现象。导致误差增加 - 平衡
需要平衡过拟合和欠拟合,降低整体的误差。
- 工作量大 :
-
误差
- 偏差bias
模型的精准度。偏差高代表着:模型存在欠拟合的现象反应模型在训练集上。期望输出于真实输出之间的差距。 - 方差variance
模型的稳定性。 方差高代表着模型过拟合。反映了模型在不同情况下得到的结果与真实结果之间的误差。
- 偏差bias
-
算法的强弱
学习器的强弱。强学习器和弱学仪器是一个相对的概念,没有很明确的划分。体现在学习区对复杂场景的处理能力上。相对于决策树模型,随机森林是强学习器。但和其他更加复杂的模型相比,他就是弱学习器。 -
模型集成
- 将多个弱学习器(基模型)构造成一个强学习器。
能够实现更好的效果的原因:模型的误差包括偏差和方差,集成能够降低方差。假设决策树模型有相同的偏差和方差:将通过通过多个决策树模型得到的结果进行平均或投票,可以保证随机森林的偏差于单个决策树模型的偏差基本相同,但是由于各个决策树模型之间的相互独立,对结果进行平均或加强之后,能够大幅度减小随机森林模型的方差,最终将误差减小。 - 类型
- 同质集成模型:类似于随机森林将,多个决策树模型 、相同种类模型集成
- 异质集成模型:将不同种类的模型进行集成
- 集成方法
- Bagging 随机对样本进行随机采样,得到n个样板间。对每一个样本独立训练决策树模型。通过集合策略输出最终结果
- Boosting 新决策树模型基于旧策树模型的结果,方法
- AdaBoot :加大此前决策树模型中分类错误数据的权重,使得下一个生成决策树模型能够尽量将这些模型分类训练正确。
- GBDT:通过计算损失函数梯度下降方向,定位模型的不足而建立新的决策树模型。应用更广泛。以Cart树作为基模型
- 将多个弱学习器(基模型)构造成一个强学习器。
-
模型融合
在模型集成中将各个基模型的结果进行组合,得到最终的结果的过程称为模型融合。- 方法
平均法 :在预测问题中,将各个基模型的结果进行平均作为最终结果。
投票法 :在分类问题中,选择基模型中预测比较多的类别作为最终结果。
- 方法
-
与大数据的关系
- 大数据包含数据挖掘的各个阶段,即数据收集、预处理、特征选择、模式挖掘、知识表示等
- 大数据的基础架构又为数据挖掘提供数据处理的硬件设施;
- 最后大数据的迅速发展也使得数据挖掘对象变得更为复杂不仅包括人类社会与物理世界的复杂联系,还愈加明显地呈现出高度动态化。要从大量无序数据中获取真正价值,数据挖掘算法必须满足对真实数据和实时数据的处理能力,这使得很多传统算法不再适用
- 大数据的 5V 特性
目前比较公认的定义是麦肯锡全球研究机构(McKinsey Global Institute)也给出的,综合了“现有技术无法处理”和“数据特征定义”,即规模庞大Volume)、种类繁多(Variety)、数据时效高(Velocity)和价值密度低(Value)。
-
发展历程

-
研究进展
近期的主要发展归为两大类:复杂数据挖掘与分布式数据挖掘。- 复杂数据包括序列数据、图数据等。
- 分布式数据挖掘遵循“全局分布、局部集中”的挖掘原则,数据挖掘领域非常有前途的方向。
-
十大问题与挑战
1 数据挖掘的统一理论框架的构建(Developing a Unifying Theory of DataMining)
2 高维数据和高速数据流的挖掘(Scaling Up for High DimensionalData/High Speed Streams)
3 序列和时序数据的挖掘(Mining Sequence Data and Time Series Data)
4 复杂数据中复杂知识的挖掘(Mining Complex Knowledge from ComplexData)
5 网络环境中的数据挖掘(Data Mining in a Network Setting)
6 分布式数据和多代理数据的挖掘(Distributed Data Mining and MiningMulti-agent Data)
7生物和环境数据的挖掘(Data Mining for Biological and EnvironmentalProblems)
8 数据挖掘过程中的相关问题处理(Data-Mining-Process Related Problems)
9 数据挖掘中数据安全、数据所涉及到的隐私和数据完整性的维护(Security,Privacy and Data Integrity)
10 非静态、非平衡及成本敏感数据的挖掘(Dealing with Non-static,Unbalanced and Cost-sensitive Data)
挖掘对象
大规模、不完全、有噪声、模糊随机的数据集。可以是任何类型的数据源,包括数据库数据、数据仓库、事物数据,以及文本、多媒体数据、空间数据、时序数据、web 数据、数据流、图或网络数据等。
- 数据库数据
- 一种结构化数据,比如关系数据库、图数据库中的数据。
- 数据仓库(Data Warehouse)
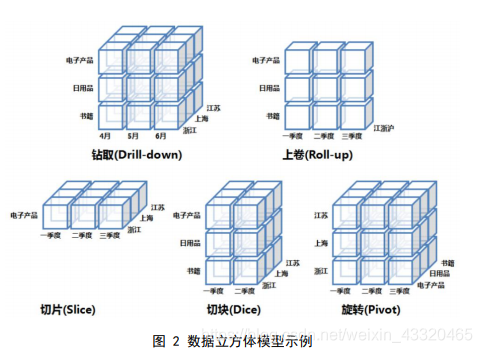
从多个数据源收集的信息存储库,存放在一致的模式下,并且通常驻留在单个站点上,是决策支持系统和联机分析应用数据源的结构化数据环境。数据仓库通常使用数据立方体(Data Cube)的多维数据结构建模。通过钻取、上卷、切片、切块、旋转等联机分析处理(Online Analytical Processing, OLAP)操作,允许用户在不同汇总级别观察数据。
- 事物数据
通常表示人类一次活动记录,比如一次购物、一个航班订票等。一个事物数据包含一个唯一的事物标识号,以及一个组成事物的项列表(购买的商品)。从图 2 可以看出,事物数据包含嵌套关系,难以放在关系数据库中,通常存放在表 1 所示的表格式的文件中

常见任务:
- 数据表征
是对目标类数据的一般特征或指定特征的总结。对应于用户指定类的数据通常通过数据库查询收集。例如,要研究上一年销售额增长 10%的软件产品的特征,可以通过执行 SQL 查询来收集与此类产品相关的数据。 - 异常检测
数据库可能包含不符合数据一般行为或模型的数据对象,这些数据对象即为异常值。大多数数据挖掘方法将异常值视为噪声或异常但是在诸如欺诈检测等应用中,罕见事件可能比常见的更有价值。异常值数据的分析通常被称为异常值挖掘。 - 关联规则学习
搜索变量之间的关系。例如,一个超市可能会收集顾客购买习惯的资料。运用关联规则学习,超市可以确定哪些产品经常一起买,并利用这些信息促进销售,这种学习也被称为市场购物篮分析。 - 聚类
发现数据的类别与结构。聚类算法基于最大化类内相似性和最小化类间相似性的原则,将对象进行聚类或分组。也就是说,形成对象集群,使得集群内的对象彼此之间具有较高的相似性,但与其他集群中的对象非常不相似。每个集群都可以被视为一类对象,从中可以派生出规则。 - 分类
分类是查找描述和区分数据类别或概念的模型(或函数)的过程,目的是为了能够使用模型来预测未知对象的类别。例如,一个电子邮件程序可能试图将一个电子邮件分类为“合法的”或“垃圾邮件”。 - 回归
试图找到能够以最小误差对该数据建模的函数。回归分析是最常用于数字预测的统计方法,还可以根据现有数据预测趋势。 - 演化分析
描述并建模对象行为随时间变化的规则或趋势。这种分析具有时间序列数据分析、序列或周期性模式匹配以及基于相似性的数据分析的特征
模型分类
-
监督学习和非监督学习
- 区别:训练数据中是否有标签,这是二者最根本的区别。监督学习的数据既有特征又有标签,而非监督学习的数据中只有特征而没有标签。
- 监督学习supervised learning
让机器自己找到特征和标签之间的联系,在以后面对只有特征而没有标签的数据时可以自己判别出标签,监督学习可以分为两大类:回归(Regression)、分类(Classification) ,二者之间的区别在于回归分析针对的是连续数据,而分类针对的是离散数据。
问题 模型 预测问题。 线性回归模型 、时间序列模型 、神经网络 分类问题 逻辑回归模型 、svm模型 、决策树模型、 随机森林模型 Boosting模型。 - 非监督学习unsupervised learning
挖掘数据之间的内在联系,将样本分成若干类。训练数据只有特征没有分类标签,这可能是因为我们不具备先验的知识,或者打标签的成本很高。所以我们需要机器对数据进行聚类分析,然后就可以通过聚类的方式从数据中提取一个特殊的结构。
问题 模型 聚类问题 K-means聚类模型、 DBSCAN聚类模型、 E_m聚类模型。 降维问题 PCA主要成分分析 - 半监督学习
半监督学习的训练数据中有一部分是有标签的,另一部分是没有标签的,而没标签的数据量远远大于有标签的数据量。隐藏在半监督学习下的基本规律在于数据的分布必然不是完全随机的,通过一些有标签数据的局部特征,以及更多没标签数据的整体分布,就可以得到可以接受甚至是非常好的分类结果
-
参数和非参数模型
| 类别 | 特征 | 模型 | 缺点 | 优点 |
|---|---|---|---|---|
| 参数模型 | 限定了目标函数的形式 | 线性回归模型、逻辑回归模型、朴素贝叶斯模型 | 1.提前对目标函数作出假设。现实问题很难应用某一目标函数,特别是复杂问题很难得到拟合效果好的模型。2.复杂度偏低,容易出现欠拟合现象 | 1.可解释性强冲 2.学习和训练速度较快 3.数据量小 |
| 非参数模型 | 没有对目标形式进行限定,通过训练自由的从训练数据集中学习任意的函数。 | 1.svm模型 2.决策树模型3.随机森林模 型 | 1.计算量大-数据量大2.可解释性弱-么 | 1.适用于大数据量逻辑复杂的问题。效果好于参数模型,由于不存在错误前提假设,在数据量趋于无穷大的时候,可以无限逼近于真实模型。2.存在超参数选择 |
| 半参数模型 | 固定了隐藏的数目和每一层神经元的个数,属于参数模型。隐层数目和每一层神经元个数在模型中通常是不固定的。 | 神经网络模型 |
- 生成和判别
| 类别 | 定义 | 特征 | 模型 |
|---|---|---|---|
| 生成模型 | 能够学习数据生成机制,得到联合分布p (x,y),特征x和y共同出现的概率,然后求条件概率分布, | 数据量需求大,能够很好的估计概率密度。数据充足的情况下,生成模型的收敛速度较快。能够处理隐变量。相对于判别模型生产模型准确率以及适用范围弱 | 朴素贝叶斯模型、混合高斯模型、隐马尔可夫模型。 |
| 判别模型。 | 学习得到条件概率分布p(y | x),在特征x的调情况下标签y出现的概率 | 计算量小。准确率和适用范围大切。较为常用 |
问题与挑战
- 数据挖掘过程中的相关问题处理
大数据的规模大、来源种类多样、价值密度低、增长速度快、准确性低等特征,给数据挖掘过程中每个阶段造成不同的问题挑战
(1) 数据采集和入库:不同类型的数据存储在一个地方、相同数据在不同的数据源中命名形式不一样、不同数据源中的数据性质不同等会给数据采集和存储带来很大挑战。
(2) 数据清洗:定义和确定错误类型,搜索和识别错误,更正错误,记录错误以及修改数据输入程序以减少结构化、非结构化和半结构化数据会带来数据清理方面的挑战。当数据没有存在噪音、不完整、不一致等问题时,数据挖掘和分析过程会提供正确的信息。
(3) 数据分析与挖掘:数据分析与挖掘是大数据的核心挑战。如果在采集、存储、清理、集成、转换等流程中出现任何问题,会导致容易挖掘到无用的数据。如果想在大数据中获取有价值的信息,有必要研究适用于所有类型数据的挖掘技术。
(4) 数据集成与融合:在大数据挖掘中,不同类型的数据模式集成和融合是最大的挑战。例如,集成的数据模式通常是在不同数据源中获取,而不同数据源中的同一对象通常具有不同的名称表示形式。如何正确将指向同一对象的不同数据融合到一起,是数据集成和融合技术的巨大挑战。
- 数据完整性(Data Integrity)
数据挖掘所使用的数据常常是为其他 用途收集的,原始数据中出现的问题会对下一阶段的分析过程产生重大的影响, 因此在数据清洗阶段需要检验数据完整性。数据对象遗漏一个或多个属性值的 情况在数据挖掘任务中屡见不鲜,例如有的人拒绝透露年龄和体重,这时信息 收集不全的现象变得十分常见。
指数据的准确性和可靠性,用于描述存 储的所有数据值均处于客观真实的状态。
完整性检验5 个基本原则:可溯源、清晰、同步、原始或真实复制、准确
策略,包括删除数据对象或属性、估计遗漏值、在分析时忽略遗漏值、使用默认值、使用属性平均值、使用同类样本平均值、预测最可能的值 等。
-
传统数据挖掘技术与网络动态数据挖掘
传统数据挖掘技术主要针对静态数据集、数据仓库问题定义、数据采集、数据预处理、数据清理/集成、数据选择/变换/归约、 数据挖掘、模式评估、解释和应用
网络动态数据挖掘需要面对不断变化的网络环境及各种动态变化的实时数据之外, 还需要对整个数据挖掘过程、数据集与关联规则集的更新过程等进行实时分析 和处理。
-
非平衡样本数据挖掘
在不平衡数据中,人们将拥有较多实例的那一类称为多数类(有时也称为 负样本),将拥有相对较少实例的那一类称为少数类(有时也称为正样本)。现有分类算法(如决策树和神经网络等)大多假定每个样本的误分类具有同样的代价而致力于提高分类器的泛化精度,分类的结果偏向于大类别样本,即大类别样本的分类精度高于小类别样本。但对很多现实的应用,如医疗诊断、信用卡欺诈检测、网络入侵、故障识别等,不同类别的样本数相差较大,不同样本的误分类代价通常不相等,仅凭全局精度评价分类器的性能优劣是不够的。此时需要引入代价敏感数据挖掘技术(Cost Sensitive Data Mining, CSDM)
十大经典算法
- C4.5
- KNN(K-Nearest Neighbor)
- K-Means
- CART(Classification and Regression Trees
- SVM(Support Vector Machine Apriori )
- EM(Expectation Maximization
- Page Rank.
- AdaBoost.
- Naive Bayes
- Apriori
C4.5
C4.5 算法是由 Ross Quinlan 在 ID3 算法的基础上,开发的用于产生决策树的算法,通常用于统计分类。C4.5 算法与 ID3 算法一样使用了信息熵的概念,并和 ID3 一样通过学习数据来建立决策树。把哪个属性作为根节点,是 C4.5 算法研究的重点,它采用信息增益率来选择属性。信息增益率使用“分裂信息”值将信息增益规范化,选择具有最大增益率的属性作为分裂属性。信息增益率的计算公式如下所示
1. 决策树
-
作用
给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5 、ID3 的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类 -
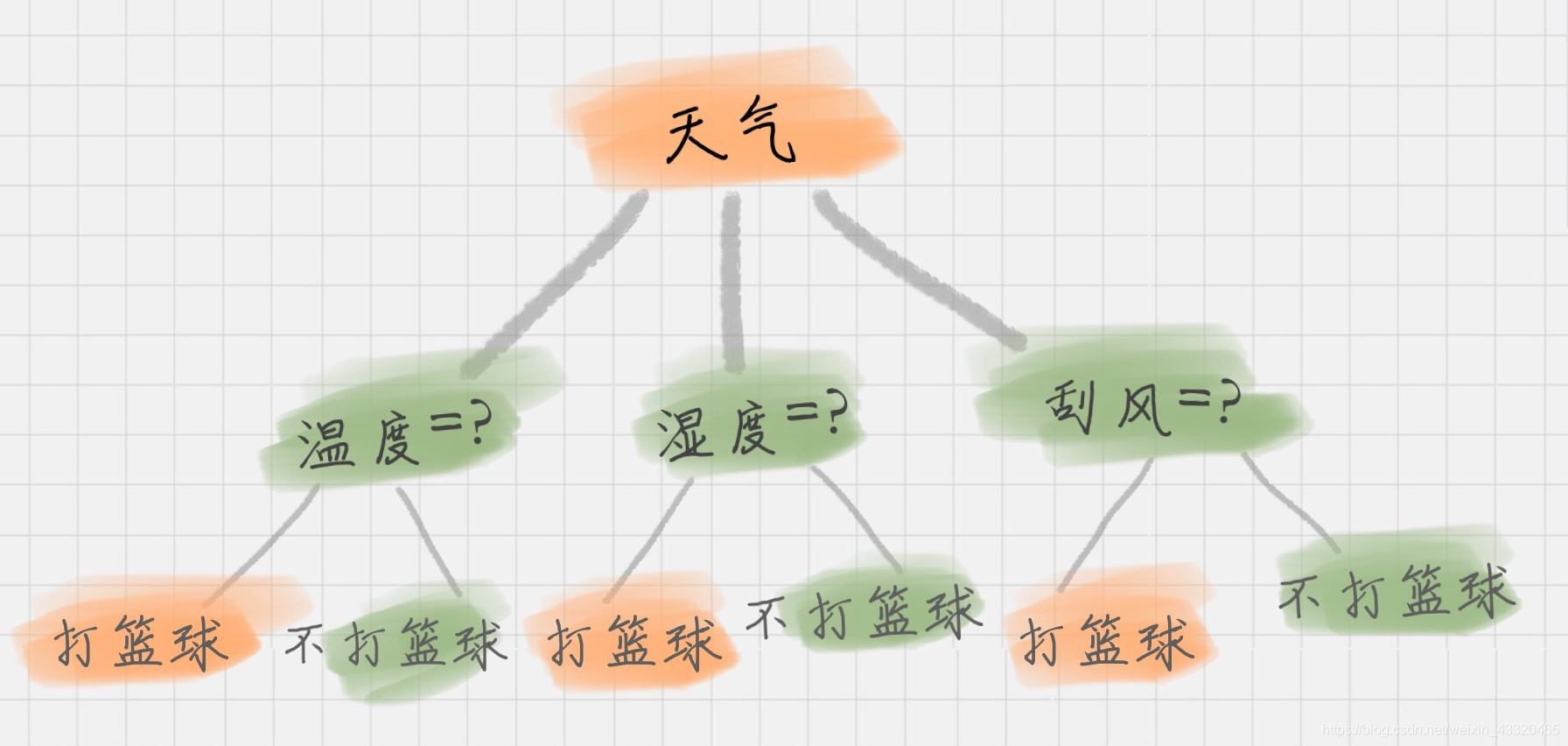
工作原理
类似于流程图的树形结构,每一个节点代表对一个特征的测试。树的分支代表着该特征的一个测试结果。每一个节点代表一个类别。决策树的核心就是寻找纯净的划分
-
类别
- 分类树 ,处理离散数据,也就是数据种类有限的数据,它输出的是样本的类别 cart
- 回归树 ,对连续型的数值进行预测,也就是数据在某个区间内都有取值的可能,输出的是一个数值。
-
构造
选择什么属性作为节点,三种节点- 根节点 :树的最顶端 - 天气
- 内部节点 :树中间的那些节点 - 温度”、“湿度”、“刮风
- 叶节点 :决策结果,停止并得到目标状态 -树最底部的节点,叶节点不存在子节点
-
节点选择指标
- 纯度 :让目标变量的分歧最小 - 不纯度指标 集合 1:6 次都去打篮球;集合 2:4 次去打篮球,2 次不去打篮球;集合 3:3 次去打篮球,3 次不去打篮球。按照纯度指标来说,集合 1> 集合 2> 集合 3。因为集合 1 的分歧最小,集合 3 的分歧最大。
- 信息熵 entropy : 信息的不确定度 - 度量信息量 ,信息熵越大,纯度越低。当集合中的所有样本均匀混合时,信息熵最大,纯度最低。
- 计算模型 :ID3 算法 C4.5 算法 cart算法
-
优缺点
-
优点 :
1.不需要对样本进行预先假设,更快地处理复杂样本。可以处理多维度输出的分类问题。
2.非参数模型 计算速度快。使用决策树预测的代价是O(log2m)。m为样本数。
3.简单直观,生成的决策树很直观。能够通过绘制分支清晰的剖析模型的选择流程,快速发现影响结果的因素,能及时指导业务进行调整修改。
4.可以同时处理分类问题和预测问题 .
5.能够处理离散型和连续型变量同时存在的场景。 很多算法只是专注于离散值或者连续值。
6.对缺失值不敏感。 基本不需要预处理,不需要提前归一化和处理缺失值。对于异常点的容错能力好,健壮性高。
7.可解释性强 。相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以很好解释。可以交叉验证的剪枝来选择模型,从而提高泛化能力。 -
缺点 :
1.弱学习器。有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
2.即使通过调优方法进行优化。也容易产生过拟合现象,造成结果误差大。 可以通过设置节点最少样本数量和限制决策树深度来改进。
3.在处理特征关联性较强的数据时表现不好。
4.受样本影响大。决策树会因为样本发生一点的改动,导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。 如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
5.寻找最优的决策树是一个NP难题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习的方法来改善。
-
-
调优方法
- 剪枝 ,控制数的深度及节点个数等参数,避免过拟合。
给决策树瘦身,防止“过拟合”,目标是,不需要太多的判断
- 预剪枝Pre-Pruning
在决策树构造时就进行剪枝。 方法是在构造的过程中对节点进行评估, 如果对某个节点进行划分, 在验证集中不能带来准确性的提升,那么对这个节点进行划分就没有意义,这时就会把当前节点作为叶节点,不对其进行划分 - 后剪枝Post-Pruning
在生成决策树之后再进行剪枝, 通常会从决策树的叶节点开始,逐层向上对每个节点进行评估。 如果剪掉这个节点子树,与保留该节点子树在分类准确性上差别不大,或者剪掉该节点子树,能在验证集中带来准确性的提升,那么就可以把该节点子树进行剪枝。方法是:用这个节点子树的叶子节点来替代该节点,类标记为这个节点子树中最频繁的那个类。 CCP 方法:cost-complexity prune,中文叫做代价复杂度
- 要用交叉验证法,选择合适的参数。
- 通过模型及集成的方法,基于决策树形成更加复杂的模型。
- 剪枝 ,控制数的深度及节点个数等参数,避免过拟合。
2.信息增益(ID3 算法)
ID3 算法计算的是信息增益,信息增益指的就是划分可以带来纯度的提高,信息熵的下降
-
公式

定义:父亲节点的信息熵减去所有子节点的信息熵
D 是父亲节点,
Di 是子节点,计算每个子节点的归一化信息熵,即按照每个子节点在父节点中出现的概率
Gain(D,a) 中的 a 作为 D 节点的属性选择 -
缺陷:
ID3 算法倾向于选择取值比较多的属性,有些属性可能对分类任务没有太大作用,但是他们仍然可能会被选为最优属性 比如我们会发现 这样,如果我们把“编号”作为一个属性(一般情况下不会这么做,这里只是举个例子),那么“编号”将会被选为最优属性 -
案例

1.将天气属性作为根节点,信息增益计算
根节点的信息熵: 练集中一共有 7 条数据,3 个打篮球,4 个不打篮球,所以根节点的信息熵是

2.三个叶子节点的信息熵,
D1(天气 = 晴天)={1-,2-,6+}D2(天气 = 阴天)={3+,7-}D3(天气 = 小雨)={4+,5-},+ 代表去打篮球,- 代表不去打篮球
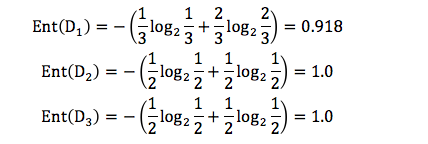
归一化信息熵 = 3/70.918+2/71.0+2/7*1.0=0.965。
3.天气作为属性节点的信息增益为
Gain(D , 天气)=0.985-0.965=0.020。
4.同理我们可以计算出其他属性作为根节点的信息增益, 它们分别为 :
Gain(D , 温度)=0.128
Gain(D , 湿度)=0.020
Gain(D , 刮风)=0.020
5.温度作为属性的信息增益最大。因为 ID3 就是要将信息增益最大的节点作为父节点,这样可以得到纯度高的决策树,
6.要将上图中第一个叶节点,也就是 D1={1-,2-,3+,4+}进一步进行分裂,往下划分,计算其不同属性(天气、湿度、刮风)作为节点的信息增益,可以得到:Gain(D , 湿度)=1Gain(D , 天气)=1Gain(D , 刮风)=0.3115,
7.我们能看到湿度,或者天气为 D1 的节点都可以得到最大的信息增益,这里我们选取湿度作为节点的属性划分。同理,我们可以按照上面的计算步骤得到完整的决策树,结果如下:
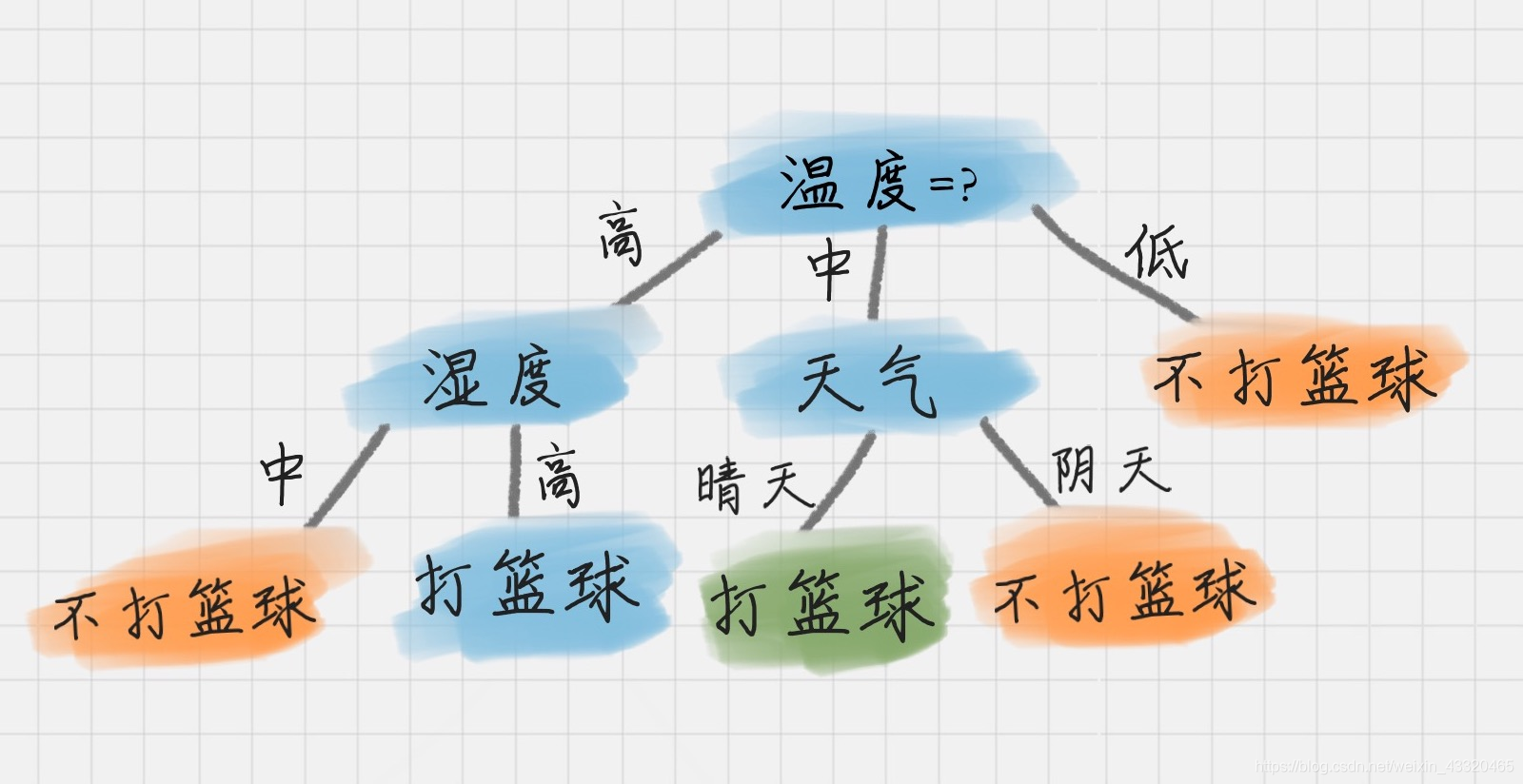
3.信息增益率(C4.5 算法)
- 公式
信息增益率 = 信息增益 / 属性熵,

属性熵 SpliIInfoA(D)

-
C4.5 算法对 ID3 算法的改进之处在于:
(1)克服多属性偏向
C4.5 算法用信息增益率来选择属性,克服了 ID3 算法用信息增益选择属性时偏向选择取值多的属性的不足;当属性有很多值的时候,相当于被划分成了许多份,虽然信息增益变大了,但是对于 C4.5 来说,属性熵也会变大,所以整体的信息增益率并不大
(2) 在树构造过程中进行悲观剪枝;
采用悲观剪枝ID3 构造决策树的时候,容易产生过拟合的情况。在 C4.5 中,会在决策树构造之后采用悲观剪枝(PEP),这样可以提升决策树的泛化能力。悲观剪枝是后剪枝技术中的一种,通过递归估算每个内部节点的分类错误率,比较剪枝前后这个节点的分类错误率来决定是否对其进行剪枝。这种剪枝方法不再需要一个单独的测试数据集。
(3) 能够完成对连续属性的离散化处理;
可以处理连续值 。C4.5 可以处理连续属性的情况,对连续的属性进行离散化的处理。比如打篮球存在的“湿度”属性,不按照“高、中”划分,而是按照湿度值进行计算,那么湿度取什么值都有可能。该怎么选择这个阈值呢,C4.5 选择具有最高信息增益的划分所对应的阈值。
(4) 能够对不完整数据进行处理。
基于比例,当数据集不完整的情况,C4.5 也可以进行处理。假如我们得到的是如下的数据,你会发现这个数据中存在两点问题。
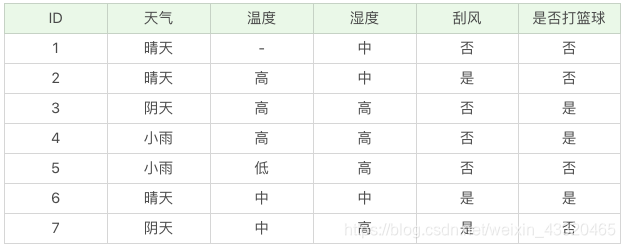
第一个问题是,数据集中存在数值缺失的情况,如何进行属性选择?第二个问题是,假设已经做了属性划分,但是样本在这个属性上有缺失值,该如何对样本进行划分?我们不考虑缺失的数值,可以得到温度 D={2-,3+,4+,5-,6+,7-}。温度 = 高:D1={2-,3+,4+} ;温度 = 中:D2={6+,7-};温度 = 低:D3={5-} 。针对将属性选择为温度的信息增为:Gain(D′, 温度)=Ent(D′)-0.792=1.0-0.792=0.208属性熵 =1.459, 信息增益率 Gain_ratio(D′, 温度)=0.208/1.459=0.1426。D′的样本个数为 6,而 D 的样本个数为 7,所以所占权重比例为 6/7,所以 Gain(D′,温度) 所占权重比例为 6/7,所以:Gain_ratio(D, 温度)=6/7*0.1426=0.122。这样即使在温度属性的数值有缺失的情况下,我们依然可以计算信息 -
案例
这里使用打篮球的案例来研究 C4.5 算法的执行流程。给定一些训练样本,具有
如下 4 个属性:Outlook(天气)、Temperature(温度)、Humidity(湿度)、Windy(是否刮风),来判断今天是否适合出去打篮球。图 12 展示了 C4.5 算法根据训练样本生成的决策树。根节点是 Outlook 属性,划分出了三个组合(Sunny、Overcast、Rainy)。
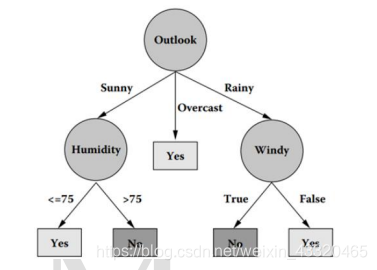
其中,Overcast 划分中的集合是“纯”的,故此子树就停止生长,表示 Outlook 的属性值为 Overcast 时,适合出去打篮球。
而 Sunny 和 Rainy 的属性值划分样例集合中包含 Humidity 和 Windy 的不同属性值,因此它们不“纯”,需要继续使用子树来表示子集,直到子集为“纯”的(即子集中的所有实例都属于同一个类别),树才停止生长。根据 Yes,得出只有符合以上属性值要求(比如 Outlook 为 Sunny,Humidity<=75;或者 Outlook为 Rainy,Windy 为 False),才能适合出去打篮球。
项目链接
- List item
CART(Classification and Regression Trees)
1.定义
-
简介
CART 算法,英文全称叫做 Classification And Regression Tree,中文叫做分类回归树。由 ID3,C4.5 演化而来,是许多基于树的 bagging、boosting 模型的基础。CART 是在给定输入随机变量 x 条件下输出随机变量 y 的条件概率分布。 -
特征
- 只支持二叉树 ,ID3 和 C4.5 算法可以生成二叉树或多叉
- 既可以作分类树,又可以作回归树。够处理连续值。python,sklearn默认决策树模型
- 用Gini系数也称Gini不纯度代替信息熵。选择特征:使Gini不纯度变小的特征作为节点。
-
ID3、C4.5 和 CART 的一个比较总结
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 |
|---|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类、回归 | 二叉树 | 基尼系数、均方差 | 支持 | 支持 | 支持 |
- CART 算法优缺点:
- CART 算法的缺点在于:
(1) 在做特征选择的时候都是选择最优的一个特征来做分类决策,但是大多数,分类决策不应该是由某一个特征决定的,而是应该由一组特征决定的。
(2) 如果样本发生一点点的改动,就会导致树结构的剧烈改变。 - CART 算法的优点
可以对复杂和非线性的数据建模,缺点是结果不易理解。
- CART 算法的缺点在于:
2.基尼系数
-
简介
- 基尼系数本身反应了样本的不确定度。
当基尼系数越小的时候,说明样本之间的差异性小,不确定程度低。 - 用来衡量一个国家收入差距的常用指标。
当基尼系数大于 0.4 的时候,说明财富差异悬殊。基尼系数在 0.2-0.4 之间说明分配合理,财富差距不大。
- 基尼系数本身反应了样本的不确定度。
-
公式
假设 t 为节点,那么该节点的 GINI 系数的计算公式为:
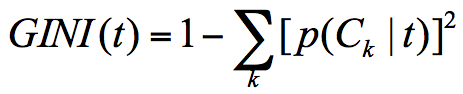
p(Ck|t) :节点 t 属于类别 Ck 的概率,节点 t 的基尼系数为 1 减去各类别 Ck 概率平方和。 -
计算基尼系数
两个集合的基尼系数分别为多少:集合 D1:6 个都去打篮球;集合 D2:3 个去打篮球,3 个不去打篮球。
针对集合D1:所有人都去打篮球,所以 p(Ck|t)=1,因此 GINI(t)=1-1=0。
集合 D2:有一半人去打篮球,而另一半不去打篮球,所以,p(C1|t)=0.5,p(C2|t)=0.5,GINI(t)=1-(0.5* 0.5+0.5* 0.5)=0.5。
通过两个基尼系数你可以看出,集合 1 的基尼系数最小,也证明样本最稳定,而集合 2 的样本不稳定性更大。 -
基于基尼系数 建立CART 算法
基尼系数对特征属性进行二元分裂,假设属性 A 将节点 D 划分成了 D1 和 D2,如下图所示:
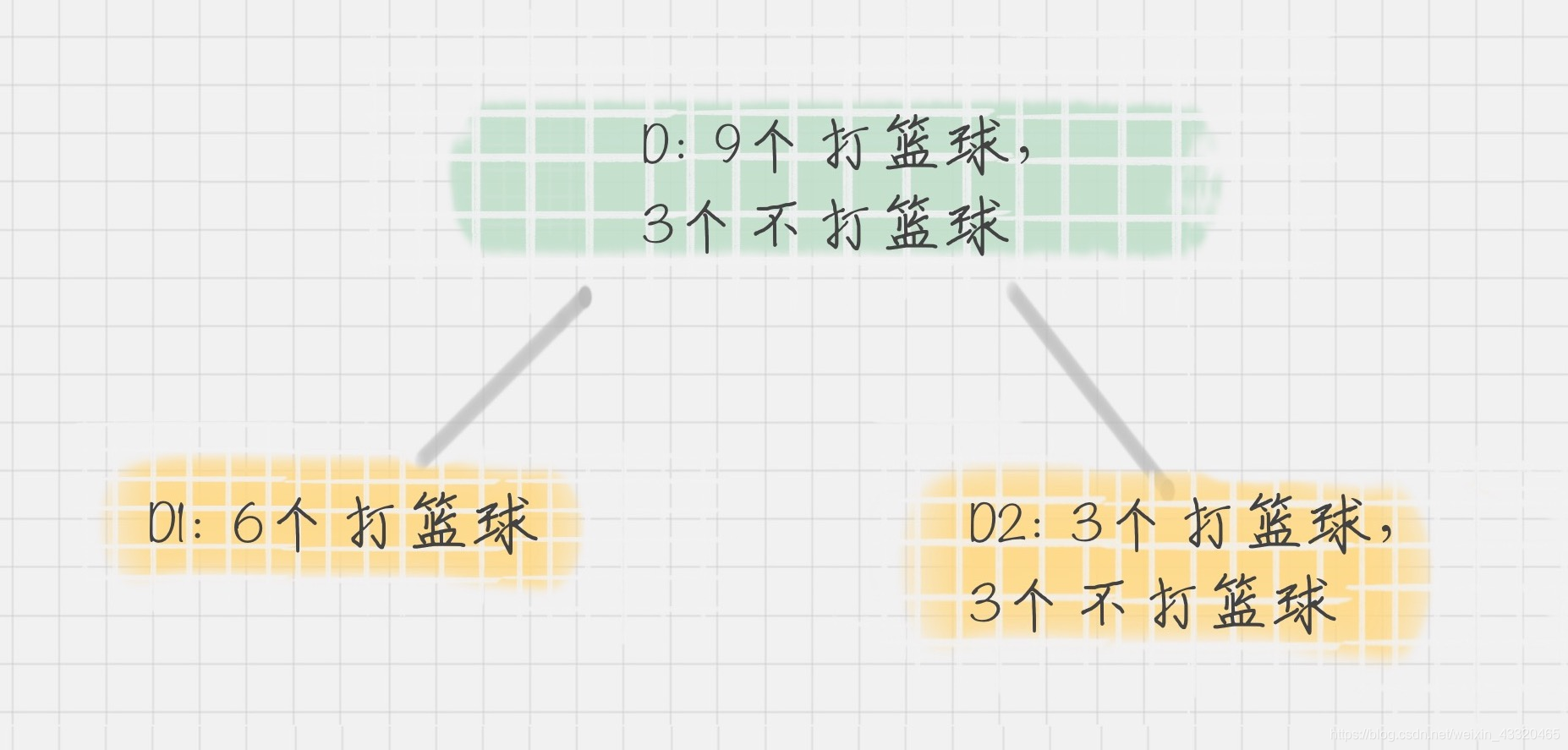
节点 D 的基尼系数等于子节点 D1 和 D2 的归一化基尼系数之和,用公式表示为:
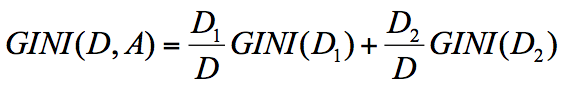
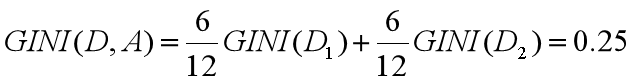
节点 D 被属性 A 划分后的基尼系数越大,样本集合的不确定性越大,也就是不纯度越高。
核心解读
- CART 算法由以下两步组成:
(1) 树的生成:基于训练数据集生成决策树,生成的决策树要尽量大;
(2) 树的剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树这时损失函数最小作为剪枝的标准。
-
CART 分类树的工作流程
分类的过程本身是一个不确定度降低的过程。决策树的生成就是基于训练数据集,通过递归地构建二叉决策树的过程,选择基尼系数最小的属性作为属性的划分。树内部结点特征取值为“是”和“否”,左分支取值为“是”,右分支取值为“否”。这样的判定树等价于递归地二分每一个特征,将输入空间划分为有限个单元,并在这些单元上预测概率分布,也就是在输入给定的条件下输出条件概率分布。 -
- 算法输入训练集D,基尼系数的阈值,样本个数阈值。
- 算法从根节点开始,用训练集递归建立CART分类树。
(1)对于当前节点的数据集为D,如果样本个数小于阈值或没有特征,则返回决策子树,当前节点停止递归。
(2)计算样本集D的基尼系数,如果基尼系数小于阈值,则返回决策树子树,当前节点停止递归。
(3)计算当前节点现有的各个特征的各个特征值对数据集D的基尼系数。
(4)在计算出来的各个特征的各个特征值对数据集D的基尼系数中,选择基尼系数最小的特征A和对应的特征值a。根据这个最优特征和最优特征值,把数据集划分成两部分D1和D2,同时建立当前节点的左右节点,做节点的数据集D为D1,右节点的数据集D为D2。
(5)对左右的子节点递归的调用1-4步,生成决策树。
-
决策树的剪枝
- 定义:
用验证数据集对生成的树进行剪枝并选择最优子树,损失函数最小作为剪枝的标准重复上面的过程,得到了剪枝后的子树集合后,我们需要用验证集对所有子树的误差计算一遍。可以通过计算每个子树的基尼指数或者平方误差,取误差最小的那个树,得到我们想要的结果。 - 剪枝方法
主要采用的是 CCP 方法,它是一种后剪枝的方法,英文全称叫做 cost-complexity prune,中文叫做代价复杂度。这种剪枝方式用到一个指标叫做节点的表面误差率增益值,以此作为剪枝前后误差的定义。寻找的就是最小值对应的节点,把它剪掉 - 表面误差率增益值
等于节点 t 的子树被剪枝后的误差变化除以剪掉的叶子数量。用公式表示则是:
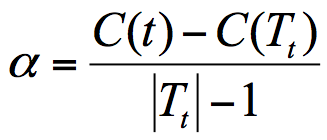
其中 Tt 代表以 t 为根节点的子树,C(Tt) 表示节点 t 的子树没被裁剪时子树 Tt 的误差,C(t) 表示节点 t 的子树被剪枝后节点 t 的误差,|Tt|代子树 Tt 的叶子数,剪枝后,T 的叶子数减少了|Tt|-1。
- 定义:
-
CART 回归的流程包括
构建回归树用平方误差最小化准则,对分类树用基尼指数最小化准则,进行特征选择,生成二叉树:
(1) 遍历每个特征,对于特征,遍历每个取值 s,用切分点 s 将数据集分为两份,计算切分后的误差;
(2) 求出误差最小的特征及其对应的切分点,此特征即被选中作为分裂结点,切分点形成左右分支;
(3) 递归地重复以上步骤。 -
回归树中节点划分的标准
CART 回归树中,用样本的离散程度来评价“不纯度”。分别对应着两种目标函数最优化的标准,即用最小绝对偏差(LAD),或者使用最小二乘偏差(LSD)。这通常使用最小二乘偏差的情况更常见一些。- 最小绝对偏差(LAD)
差值的绝对值为样本值减去样本均值的绝对值:
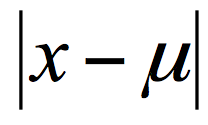
- 最小二乘偏差(LSD)
方差为每个样本值减去样本均值的平方和除以样本个数:
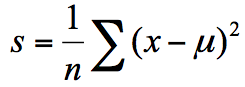
- 最小绝对偏差(LAD)
项目链接
- List item
KNN(K-Nearest Neighbor)
1.定义
-
理解
“近朱者赤,近墨者黑”。最邻近规则分类算法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 -
KNN 的核心思想是
如果一个样本在特征空间中的 K 个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。KNN 算法中,所选择的邻居都是已经正确分
类的对象。通过找出一个样本的 K 个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。KNN 方法在做类别决策时,只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重迭较多的待分样本集来说,KNN方法较其他方法更为适合。
-
过程
(1) 计算测试数据与各个训练数据之间的距离;
(2) 按照距离的递增关系进行排序;
(3) 选取距离最小的 K 个点;
(4) 确定前 K 个点所在类别的出现频率;
(5) 返回前 K 个点中出现频率最高的类别作为测试数据的预测分类。 -
KD 树
KNN 的计算过程是大量计算样本点之间的距离。为了减少计算距离次数,提升 KNN 的搜索效率,人们提出了 KD 树(K-Dimensional 的缩写)。
KD 树是对数据点在 K 维空间中划分的一种数据结构。在 KD 树的构造中,每个节点都是 k 维数值点的二叉树。既然是二叉树,就可以采用二叉树的增删改查操作,这样就大大提升了搜索效率。
不需要对 KD 树的数学原理了解太多,只需要知道它是一个二叉树的数据结构,方便存储 K 维空间的数据就可以了。而且在 sklearn 中,我们直接可以调用 KD 树,很方便。 -
优缺点
优点:简单、容易理解,通过 K 值的增大可具备噪音数据的鲁棒性。
缺点:需要大量的空间去储存已知的实例,算法复杂度高。 -
案例1.分类:
假设,我们想对电影的类型进行分类,统计了电影中打斗次数、接吻次数,当然还有其他的指标也可以被统计到,如下表所示。《战狼》《红海行动》《碟中谍 6》是动作片,《前任 3》《春娇救志明》《泰坦尼克号》是爱情片,但是有没有一种方法让机器也可以掌握这个分类的规则,当有一部新电影的时候,也可以对它的类型自动分类呢?
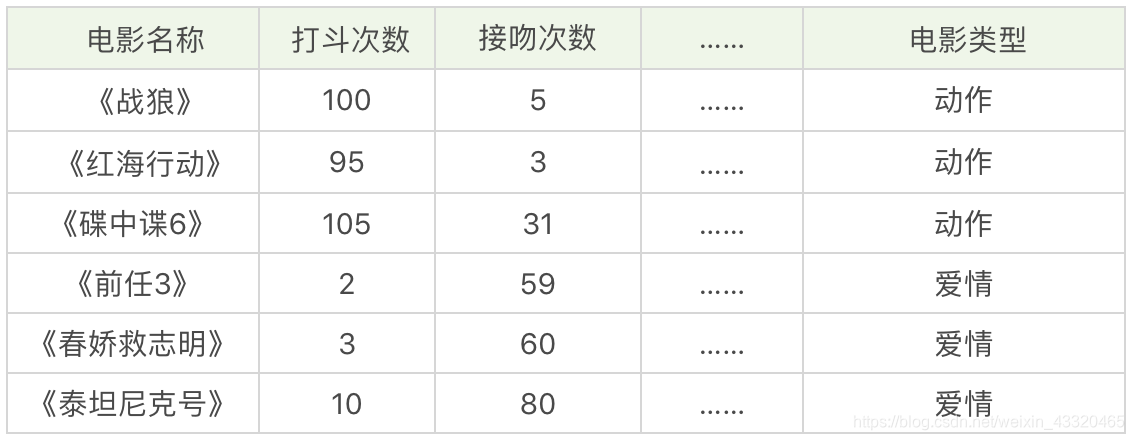
我们可以把打斗次数看成 X 轴,接吻次数看成 Y 轴,然后在二维的坐标轴上,对这几部电影进行标记,如下图所示。对于未知的电影 A,坐标为 (x,y),我们需要看下离电影 A 最近的都有哪些电影,这些电影中的大多数属于哪个分类,那么电影 A 就属于哪个分类。实际操作中,我们还需要确定一个 K 值,也就是我们要观察离电影 A 最近的电影有多少个。 -
案例2.回归
对于一个新电影 X,我们要预测它的某个属性值,比如打斗次数,具体特征属性和数值如下所示。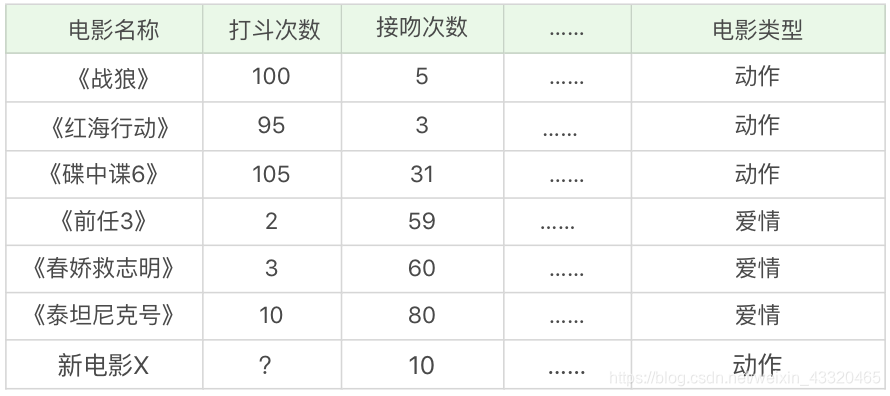
此时,我们会先计算待测点(新电影 X)到已知点的距离,选择距离最近的 K 个点。假设 K=3,此时最近的 3 个点(电影)分别是《战狼》,《红海行动》和《碟中谍 6》,那么它的打斗次数就是这 3 个点的该属性值的平均值,即(100+95+105)/3=100 次。
2.核心解读
-
K 等于不同值时的算法分类结果?
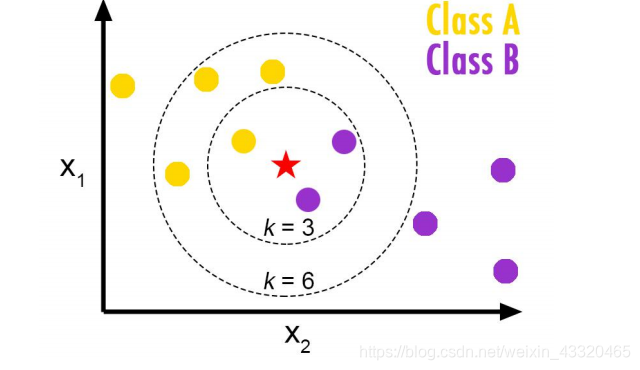
- K 值比较小
就相当于未分类物体与它的邻居非常接近才行。这样产生的一个问题就是,如果邻居点是个噪声点,那么未分类物体的分类也会产生误差,这样 KNN 分类就会产生过拟合。 - K 值比较大
相当于距离过远的点也会对未知物体的分类产生影响,虽然这种情况的好处是鲁棒性强,但是不足也很明显,会产生欠拟合情况,也就是没有把未分类物体真正分类出来。
- K 值比较小
-
K值选择
K 值应该是个实践出来的结果,并不是我们事先而定的。在工程上,我们一般采用交叉验证的方式选取 K 值,交叉验证的思路:
把样本集中的大部分样本作为训练集,剩余的小部分样本用于预测,来验证分类模型的准确性。所以在 KNN 算法中,我们一般会把 K 值选取在较小的范围内,同时在验证集上准确率最高的那一个最终确定作为 K 值。 -
关于距离的度量
两个样本点之间的距离代表了这两个样本之间的相似度。距离越大,差异性越大;距离越小,相似度越大。关于距离的计算方式有下面五种方式:- 欧氏距离;
- 曼哈顿距离;
- 闵可夫斯基距离;
- 切比雪夫距离;
- 余弦距离。
项目链接
- List item
K-Means.
1. 定义
-
简介
K-Means 是一种非监督学习,解决的是聚类问题。K 代表的是 K 类,Means 代表的是中心,可以理解算法的本质是确定 K 类的中心点,当你找到了这些中心点,也就完成了聚类。 -
算法的思想
对于给定的样本集,按照样本之间的距离大小,将样本集划分为 K 个簇,让簇内的点尽量紧密地连在一起,而让簇间的距离尽量的大。 -
- 数据表达式表示
最小值采用的是启发式的迭代方法,假设簇划分为(C1,C2,…Ck),则目标是最小化平方误差 E:
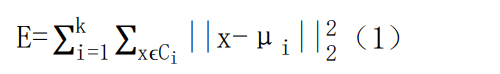
其中μi是簇 Ci的均值向量,有时也称为质心,表达式为:
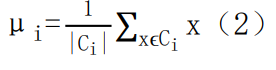
- 数据表达式表示
-
图可以形象描述上式
图(a)表达了初始的数据集,假设 k=2。
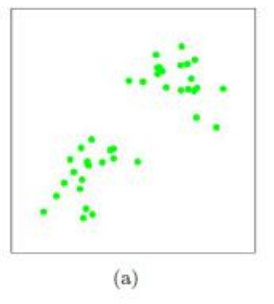
在图(b)中,我们随机选择了两个 k 类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别。
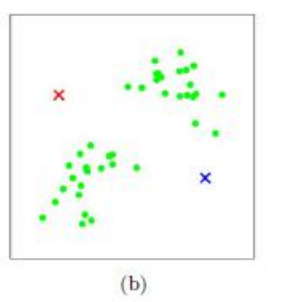
如图 c 所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。
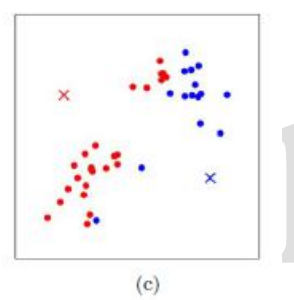
如图(d)所示此时我们对当前标记为红色和蓝色的点分别求其新的质心,新的红色质心和蓝色质心的位置已经发生了变动。
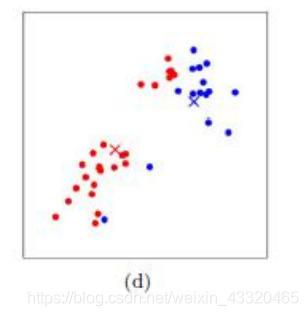
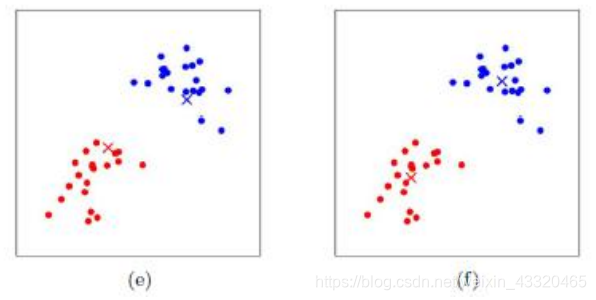
图(e)和图(f)重复了图(c)和图(d)的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如图(f)。
-
优缺点
优点有:比较简单,实现也很容易,收敛速度快;算法的可解释度比较强。
缺点有:K 值的选取不好把握;采用迭代方法,得到的结果只是局部最优;对噪音和异常点比较敏感。
2.核心解读
假设我有 20 支亚洲足球队,想要将它们按照成绩划分成 3 个等级,可以怎样划分?
-
如何确定 K 类的中心点?
-
选取 K 个点作为初始的类中心点,这些点一般都是从数据集中随机抽取的;
一开始我们是可以靠我们的经验随机指派,一流的亚洲球队伊朗。二流的亚洲球队中国。三流的亚洲球队越南。三个等级的典型代表,也就是我们每个类的中心点。 -
将每个点分配到最近的类中心点,这样就形成了 K 个类,然后重新计算每个类的中心点;
计算每个队伍分别到中国、日本、韩国的距离,然后根据距离远近来划 -
纠正中心点:重复第二步,直到类不发生变化,或者你也可以设置最大迭代次数,这样即使类中心点发生变化,但是只要达到最大迭代次数就会结束。中心点在整个迭代过程中,并不是唯一的,只是你需要一个初始值,一般算法会随机设置初始的中心点。
再重新计算这三个类的中心点,如何计算呢?最简单的方式就是取平均值,然后根据新的中心点按照距离远近重新分配球队的分类,再根据球队的分类更新中心点的位置。
-
-
如何将其他点划分到 K 类中?
实际上是关于距离的定义,我们知道距离有多种定义的方式,在 K-Means 和 KNN 中,我们都可以采用欧氏距离、曼哈顿距离、切比雪夫距离、余弦距离等。对于点的划分,就看它离哪个类的中心点的距离最近,就属于哪一类。 -
如何区分 K-Means 与 KNN?
- 两个算法解决数据挖掘的两类问题。K-Means 是聚类算法,KNN 是分类算法。
- 这两个算法分别是两种不同的学习方式。K-Means 是非监督学习,也就是不需要事先给出分类标签,而 KNN 是有监督学习,需要我们给出训练数据的分类标识。
- K 值的含义不同。K-Means 中的 K 值代表 K 类。KNN 中的 K 值代表 K 个最接近的邻居。
项目链接
- List item
Naive Bayes 朴素贝叶斯法
1.相关定义
-
简介
基于贝叶斯定理与特征条件独立假设的分类方法,和决策树模型是使用最为广泛的两种分类模型。相比决策树模型,朴
素贝叶斯模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。具有稳定的分类效率。但是在实际应用中,属性之间相互独立的假设往往是不成立的,给朴素贝叶斯模型的分类准确度带来一定影响。
- 贝叶斯分类
在统计资料的基础上,依据条件概率公式,计算当前特征的样本属于某个分类的概率,选择最大的概率分类 - 预测建模算法
强制假设每个输入变量是独立的,统计的是属性的条件概率 - 朴素
贝叶斯之所以朴素是因为它假设属性是相互独立的,因此对实际情况有所约束,虽然不太现实,但对于绝大多数问题有很好的解决。如果属性之间存在关联,分类准确率会降低。 - 条件概率
训练朴素贝叶斯模型,我们需要先给出训练数据,以及这些数据对应的分类。那么类别概率和条件概率。他们都可以从给出的训练数据中计算出来。一旦计算出来,概率模型就可以使用贝叶斯原理对新数据进行预测。
- 贝叶斯分类
-
数学原理
贝叶斯统计 -
组成
由两种类型的概率组成:1. 每个类别的概率P(Cj);2. 每个属性的条件概率P(Ai|Cj)。
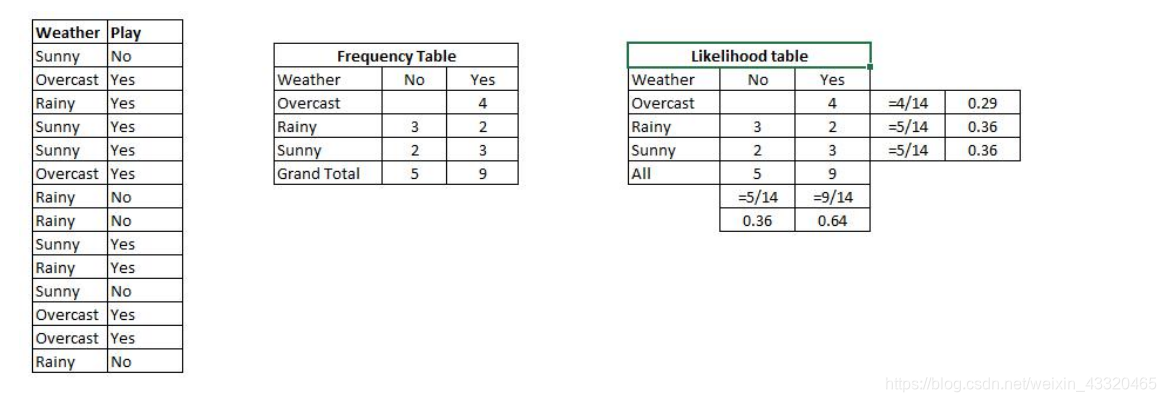
- 类别概率
将数据集转换为频率表,然后创建概率表,比如 P(sunny) =0.36 - 条件概率
用朴素贝叶斯计算后验概率,后验概率大的为预测分类。如果天气是 sunny 就出去玩,这样说是 否 正 确 ? 可 以 根 据 后 验 概 率 来 确 定 以 上 说 法 是 否 正 确 ,即P(Yes|Sunny)=P(Sunny|Yes)*P(Yes)/P(Sunny)=0.60>0.5,所以天气好就可以出去玩
- 类别概率
-
适用环境
朴素贝叶斯分类常用于文本分类,尤其是对于英文等语言来说,分类效果很好。它常用于垃圾文本过滤、情感预测、推荐系统等 -
优缺点
- 优点包括:
- 算法的逻辑性十分简单,当数据呈现不同的特点时,朴素贝叶斯的分类性能不会有太大的差异,算法的鲁棒性比较好。
- 当数据集属性之间的关系相对比较独立时,朴素贝叶斯分类算法会有较好的效果。
- 缺点包括:
- 属性独立性的条件同时也是朴素贝叶斯分类器的不足之处。数据集属性的独立性在很多情况下是很难满足的,因为数据集的属性之间往往都存在着相互关联,如果在分类过程中出现这种问题,会导致分类的效果大大降低
- 优点包括:
工作原理
根据以往的经验判断性别就是分类过程
-
离散数据
数据:身高“高”、体重“中”,鞋码“中”,请问这个人是男还是女?- 转化为数学问
用 A1, A2, A3 分别为身高 = 高、体重 = 中、鞋码 = 中。一共有两个类别,假设用 C 代表类别,那么 C1,C2 分别是:男、女,在未知的情况下我们用 Cj 表示。 - 条件概率问题
想求在 A1、A2、A3 属性下,Cj 的概率,用条件概率表示就是 P(Cj|A1A2A3)。 - 贝叶斯公式应用
P(A1A2A3) 都是固定的,我们想要寻找使得 P(Cj|A1A2A3) 的最大值,就等价于求 P(A1A2A3|Cj)P(Cj) 最大值。 - 继续简化
假定 Ai 之间是相互独立的,P(A1A2A3|Cj)=P(A1|Cj)P(A2|Cj)P(A3|Cj),需要从数据集 Ai 和 Cj 中计算出 P(Ai|Cj) 的概率:P(A1|C1)=1/2, P(A2|C1)=1/2, P(A3|C1)=1/4,P(A1|C2)=0, P(A2|C2)=1/2, P(A3|C2)=1/2 - 得出结论
带入到上面的公式得出 P(A1A2A3|Cj),最后找到使得 P(A1A2A3|Cj) 最大的类别 Cj。所以 P(A1A2A3|C1)=1/16, P(A1A2A3|C2)=0
- 转化为数学问
-
连续数据
数据,身高 180、体重 120,鞋码 41,请问该人是男是女呢?连续变量,不能采用离散变量的方法计算概率。样本太少,所以也无法分成区间计算
-数据分布
假设男性和女性的身高、体重、鞋码都是正态分布,男性的身高是均值 179.5、标准差为 3.697 的正态分布
- 分别计算概率
通过样本计算出均值和方差,也就是得到正态分布的密度函数,计算得:
男性的身高为 180 的概率为 0.1069。
男性体重为 120 的概率为 0.000382324
男性鞋码为 41 号的概率为 0.120304111。
- 应用贝叶斯计算总概率
有了密度函数,就可以把值代入,算出某一点的密度函数的值,男性的可能: P(A1A2A3|C1)=P(A1|C1)P(A2|C1)P(A3|C1)=0.10690.0003823240.120304111=4.9169e-6 女的可能性:
P(A1A2A3|C2)=P(A1|C2)P(A2|C2)P(A3|C2)=0.000001474890.0153541440.120306074=2.7244e
- 结论
很明显这组数据分类为男的概率大于分类为女的概率
SVM(Support Vector Machine)
1.基本认知
-
介绍
支持向量机(Support Vector Machine)是一种监督式学习的方法,它广泛的应用于统计分类以及回归分析中。SVM将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个平行超平面的距离最大化。 -
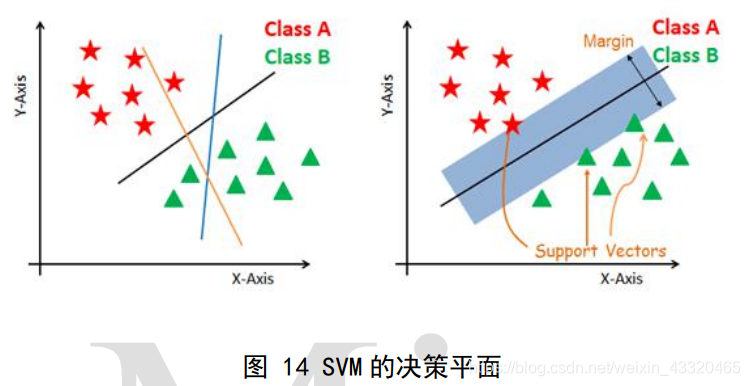
基本思想是
在分类问题中,很多时候有多个解,如下图左边所示,找到集合边缘上的若干数据(称为支持向量),用这些点在理想的线性可分的情况下其决策平面会有多个。而 SVM 的基本模型是在特征空间上找到找到一个超平面(称为决策面)使得训练集上正负样本间隔最大,=这个超平面就是我们的 SVM 分类器。
SVM 算法计算出来的分界会保留对类别最大的间距,即有足够的余量,如图 14 右边所示。能将不同的样本划分开,同时使得样本集中的点到这个分类超平面的最小距离(即分类间隔)最大化,“最大间隔“决策面就是 SVM 要找的最优解,使得支持向量到该平面的距离最大
- 支持向量
离分类超平面最近的样本点,实际上如果确定了支持向量也就确定了这个超平面。所以支持向量决定了分类间隔到底是多少,而在最大间隔以外的样本点,其实对分类都没有意义。 - 超平面
如果在一维空间里就表示一个点,在二维空间里表示一条直线,在三维空间中代表一个平面,当然空间维数还可以更多,这样我们给这个线性函数起个名称叫做“超平面”- 案例
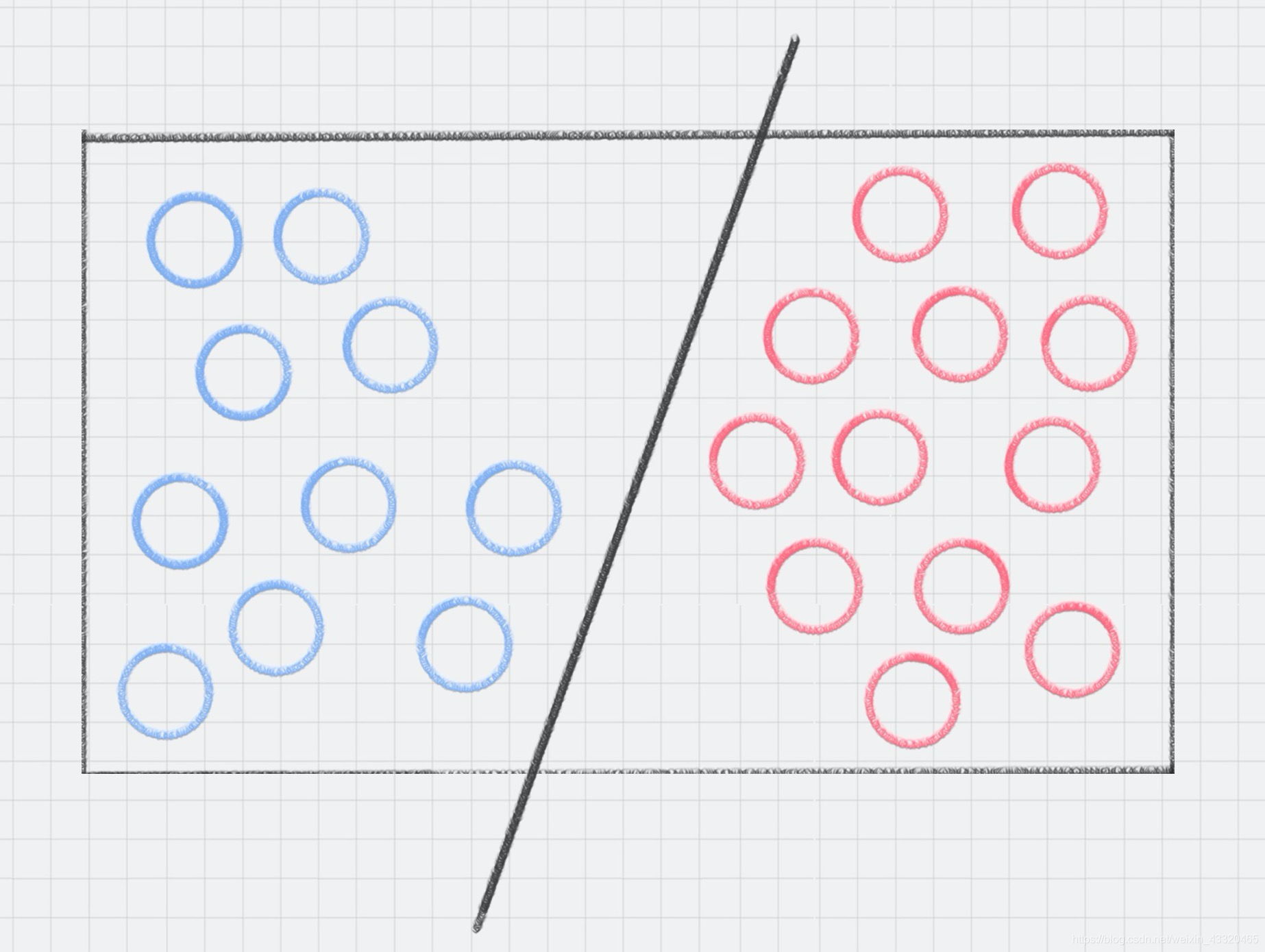
桌子上我放了红色和蓝色两种球,请你用一根棍子将这两种颜色的球分开。 你可以很快想到解决方案,在红色和蓝色球之间画条直线就好了,如下图所示:
练习 2:这次难度升级,桌子上依然放着红色、蓝色两种球,但是它们的摆放不规律,如下图所示。
如何用一根棍子把这两种颜色分开呢?你可能想了想,认为一根棍子是分不开的。除非把棍子弯曲,像下面这样:所以这里直线变成了曲线。如果在同一个平面上来看,红蓝两种颜色的球是很难分开的。那么有没有一种方式,可以让它们自然地分开呢?这里你可能会灵机一动,猛拍一下桌子,这些小球瞬间腾空而起,如下图所示。

在腾起的那一刹那,出现了一个水平切面,恰好把红、蓝两种颜色的球分开。在这里,二维平面变成了三维空间。原来的曲线变成了一个平面。这个平面,我们就叫做超平面。
- 案例
- 分类间隔
点到超平面的距离公式这里我们可以用线性函数来表示
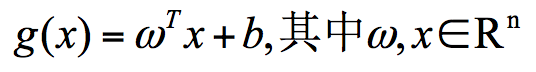 在这个公式里,w、x 是 n 维空间里的向量,其中 x 是函数变量;w 是法向量。法向量这里指的是垂直于平面的直线所表示的向量,它决定了超平面的方向。实际中求超平面公式中的 w* 和 b* 进行求解,需要涉及软间隔、核函数
在这个公式里,w、x 是 n 维空间里的向量,其中 x 是函数变量;w 是法向量。法向量这里指的是垂直于平面的直线所表示的向量,它决定了超平面的方向。实际中求超平面公式中的 w* 和 b* 进行求解,需要涉及软间隔、核函数 - 决策面
其实我们可以有多种直线的划分,比如下图所示的直线 A、直线 B 和直线 C,分类环境不是在二维平面中的,而是在多维空间中,这样直线 C 就变成了决策面 C - 最优决策面
在保证决策面不变,且分类不产生错误的情况下,我们可以移动决策面 C,直到产生两个极限的位置:如图中的决策面 A 和决策面 B。极限的位置是指,如果越过了这个位置,就会产生分类错误。这样的话,两个极限位置 A 和 B 之间的分界线 C 就是最优决策面。
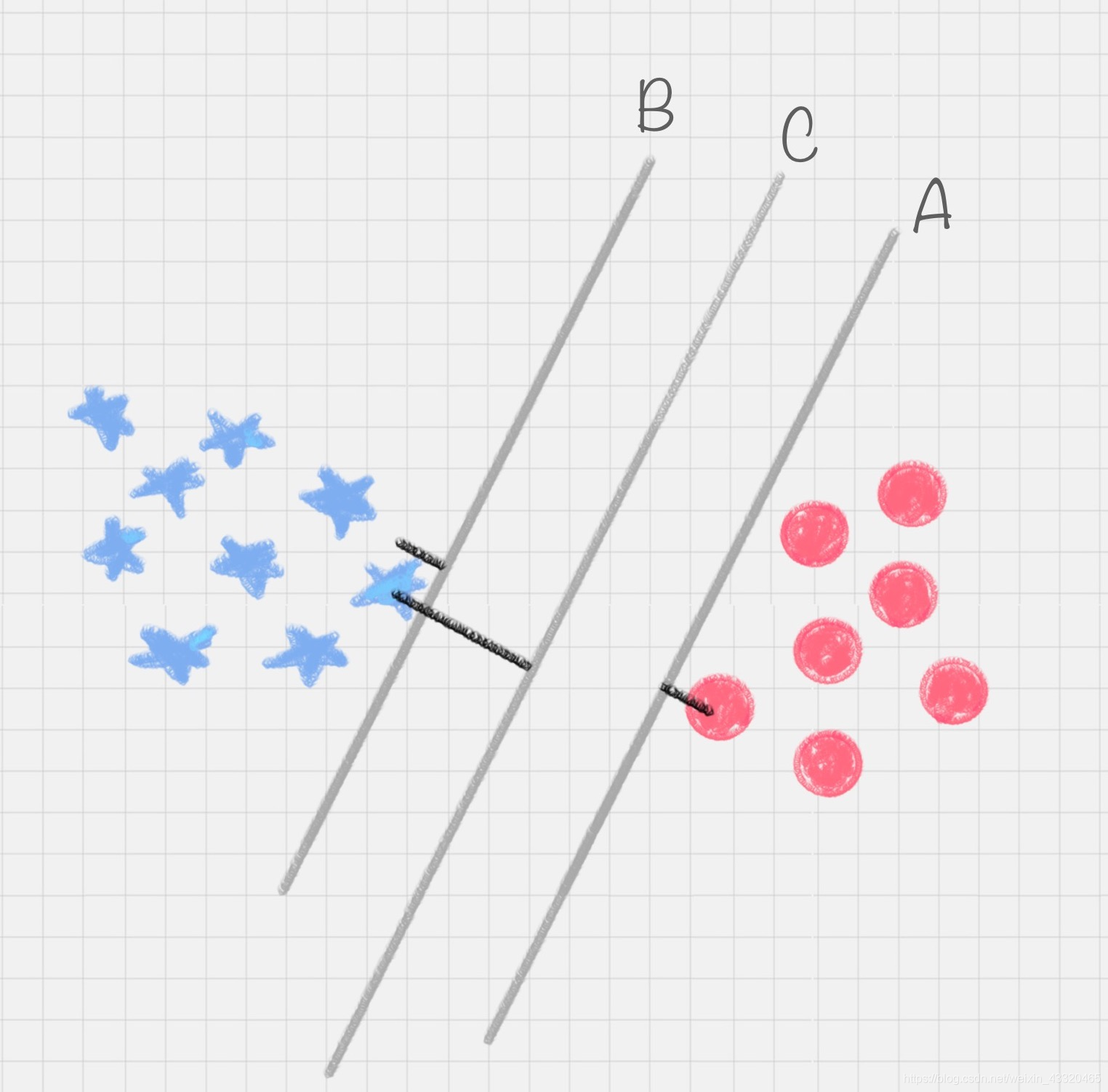
- 分类间隔margin
极限位置到最优决策面 C 之间的距离,就是“分类间隔”。某类样本集到超平面的距离是这个样本集合内的样本到超平面的最短距离。 - 分类间隔的大小
我们用 di 代表点 xi 到超平面 wxi+b=0 的欧氏距离。因此我们要求 di 的最小值,用它来代表这个样本到超平面的最短距离。di 可以用公式计算得出,其中||w||为超平面的范数,di 的公式可以用解析几何知识进行推导,这里不做解释
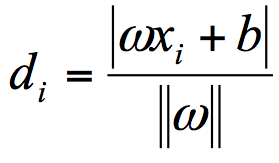
- 最大间隔max margin
如果我们转动这个最优决策面,你会发现可能存在多个最优决策面,它们都能把数据集正确分开,这些最优决策面的分类间隔可能是不同的,而那个拥有“最大间隔”(max margin)的决策面就是 SVM 要找的最优解。支持向量就是离分类超平面最近的样本点,决定了分类间隔到底是多少, - 最大间隔的优化模型
目标就是找出所有分类间隔中最大的那个值对应的超平面。在数学上,这是一个凸优化问题(凸优化就是关于求凸集中的凸函数最小化的问题,这里不具体展开)。通过凸优化问题,最后可以求出最优的 w 和 b,也就是我们想要找的最优超平面。中间求解的过程会用到拉格朗日乘子,和 KKT(Karush-Kuhn-Tucker)条件。数学公式比较多,这里不进行展开。
- 支持向量
-
分类器类别
- 完全线性可分情
硬间隔指的就是完全分类准确,不能存在分类错误的情况线性可分是个理想。完全线性可分情况下的线性分类器,也就是线性可分的情况,是最原始的 SVM,它最核心的思想就是找到最大的分类间隔; - 大部分线性可分 软间隔
就是允许一定量的样本分类错误,实际数据会存在噪音 - 线性不可分 非线性支持向量机
在解决线性不可分问题时,它可以通过引入核函数,巧妙地解决了在高维空间中的内积运算,从而很好地解决了非线性分类问题。如下图所示,通过核函数的引入,将线性不可分的数据映射到一个高维的特征空间内,使得数据在特征空间内是可分的。
 核函数:线性核、多项式核、高斯核、拉普拉斯核、sigmoid 核,或者是这些核函数的组合
核函数:线性核、多项式核、高斯核、拉普拉斯核、sigmoid 核,或者是这些核函数的组合
- 完全线性可分情
-
SVM寻找最大间隔的意义
支持向量机之所以坚持寻找最大边缘超平面,是因为它具有最好的泛化能力。它不仅使训练数据具有最佳的分类性,而且为测试数据的正确分类留下了很大的空间。 -
优缺点
- 优点在于:
- 有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
- 能找出对任务至关重要的关键样本;
- 采用核技巧之后,可以处理非线性分类/回归任务。
- 缺点包括:
- 训练时间长;
- 当支持向量的数量较大时,预测计算复杂度较高。因此支持向量机目前只适合小批量样本的任务,无法适应百万甚至上亿样本的任务。
- 优点在于:
2.项目
EM(Expectation Maximization
1.基本认知
- 简介
EM 的英文是 Expectation Maximization,所以 EM 算法也叫最大期望算法。EM 算法直接的应用就是求参数估计,最初是为了解决数据缺失情况下的参数估计问题。EM 算法是最常见的隐变量估计方法,在机器学习中有极为广泛的用途,例如常被用来学习高斯混合模型的参数、隐式马尔科夫算法、LDA主题模型的变分推断等。 - EM 算法的工作原理
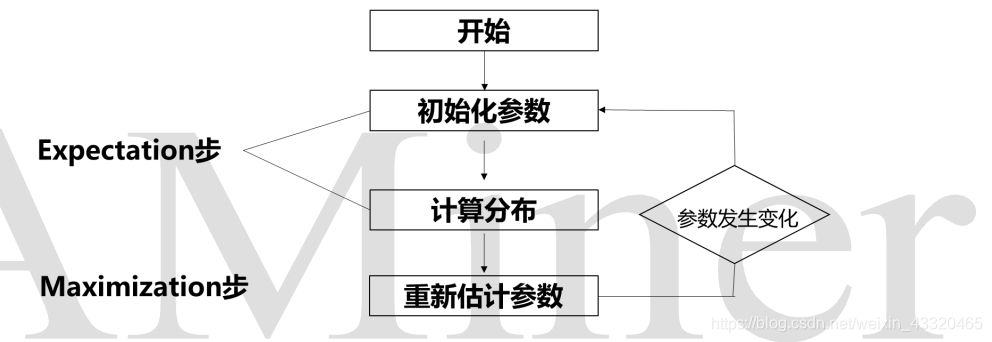
EM 算法是一种求解最大似然估计的方法,通过迭代优化策略,来找出样本的模型参数。三个主要的步骤:初始化参数、观察预期、重新估计。1.根据己经给出的观测数据,估计出模型参数的值;2.E 步:通过旧的参数来计算隐藏变量(缺失数据的值);3.M 步:通过得到的隐藏变量的结果来重新估计参数。反复迭代,直到收敛(参数不再发生变化),得到我们想要的结果,迭代结束。
假设你炒了一份菜,想要把它平均分到两个碟子里,该怎么分?1.先给每个碟子初始化一些菜量,碟子 A 和碟子 B 中菜的份量就是想要求得的模型参数。2.观察份量的差距,两步完成期望步骤(Expectation)。3.如果结果存在偏差就需要重新估计参数,调整 A 和 B 的参数,这个就是最大化步骤(Maximization)。 - 最大似然”
Maximum Likelihood,最大可能性,相同年龄下男性的平均身高比女性的高一些,有一男一女,财产男同学高的可能性会很大。 - 最大似然估计
是一种通过已知结果,估计参数的方法。指的就是一件事情已经发生了,然后反推更有可能是什么因素造成的。还是用一男一女比较身高为例,假设有一个人比另一个人高,反推他可能是男性。 - EM 聚类的工作原理
把潜在类别当做隐藏变量,样本看做观察值,就可以把聚类问题转化为参数估计问题。 - EM 算法是一个框架
EM 算法相当于一个框架,你可以采用不同的模型来进行聚类,常用的 EM 聚类有 GMM 高斯混合模型和 HMM 隐马尔科夫模型。GMM(高斯混合模型)聚类比如下面这两个图,可以采用 GMM 来进行聚类

GMM 是通过概率密度来进行聚类,聚成的类符合高斯分布(正态分布)。而 HMM 用到了马尔可夫过程,在这个过程中,我们通过状态转移矩阵来计算状态转移的概率。HMM 在自然语言处理和语音识别领域中有广泛的应用。 - 优缺点
- 优点:
- 相比于 K-Means 算法,EM 聚类更加灵活。K-Means 是通过距离来区分样本之间的差别的,且每个样本在计算的时候只能属于一个分类,称之为是硬聚类算法。而 EM 聚类在求解的过程中,实际上每个样本都有一定的概率和每个聚类相关,叫做软聚类算法。软的输出概率,硬的要给出答
- 缺点
- 传统 EM 算法对初始值敏感,聚类结果随不同的初始值而波动较大。总的来说,EM 算法收敛的优劣很大程度上取决于其初始参数。
- 优点:
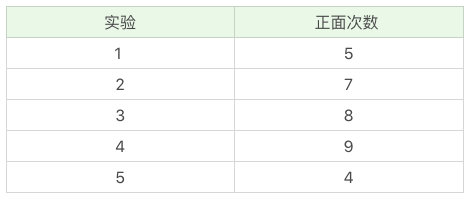
2.案例:EM 算法的基本思想
假设我们有 A 和 B 两枚硬币,实际情况是我不知道每次投掷的硬币是 A 还是 B,那么如何求得硬币 A 和硬币 B 出现正面的概率呢?我们做了 5 组实验,每组实验投掷 10 次,然后统计出现正面的次数,实验结果如下:
- 初始化参数。投掷硬币这个过程中存在隐含的数据,即我们事先并不知道每次投掷的硬币是 A 还是 B。假设我们知道这个隐含的数据,并将它完善,可以得到下面的结果:
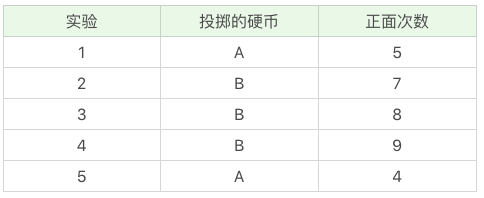
求得硬币 A 和 B 出现正面次数的概率:
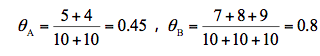
我们假设硬币 A 和 B 的正面概率(随机指定)是θA=0.5 和θB=0.9。 - 计算期望值,通过假设的参数来估计未知参数
假设实验 1 投掷的是硬币 A,那么正面次数为 5 的概率为:

假设实验 1 是投掷的硬币 B ,那么正面次数为 5 的概率为:
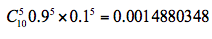
实验 1 更有可能投掷的是硬币 A。对实验 2~5 重复上面的计算过程,可以推理出来硬币顺序应该是{A,A,B,B,A}。 - 通过猜测的结果{A, A, B, B, A}来完善初始化的参数θA 和θB。然后一直重复第二步和第三步,直到参数不再发生变化。
Page Rank.
1.介绍
-
简介
PageRank 这个概念引自论文影响力因子,一篇论文的被引述的频度——即被别人引述的次数越多,一般判断这篇论文的权威性就越高。PageRank 算法是 Google 排名运算法则(排名公式)的一个非常重要的组成部分,目的就是要找到优质的网页,不仅为用户提供想要的内容,而且还会从众多网页中筛选出权重高的呈现给用户。做法:每个到页面的链接都是对该页面的一次投票,被链接的越多,就意味着被其他网站投票越多。
-
简化模型
出链指的是链接出去的链接。入链指的是链接进来的链接。比如图中 A 有 2 个入链,3 个出链。
一个网页的影响力 = 所有入链集合的页面的加权影响力之和,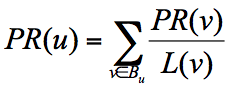
u 为待评估的页面,Bu 为页面 u 的入链集合。针对入链集合中的任意页面 v,它能给 u 带来的影响力是其自身的影响力 PR(v) 除以 v 页面的出链数量,即页面 v 把影响力 PR(v) 平均分配给了它的出链,这样统计所有能给 u 带来链接的页面 v,得到的总和就是网页 u 的影响力,即为 PR(u)。出链会给被链接的页面赋予影响力,当我们统计了一个网页链出去的数量,也就是统计了这个网页的跳转概率。
一共有 4 个网页 A、B、C、D。它们之间的链接信息如图所示:
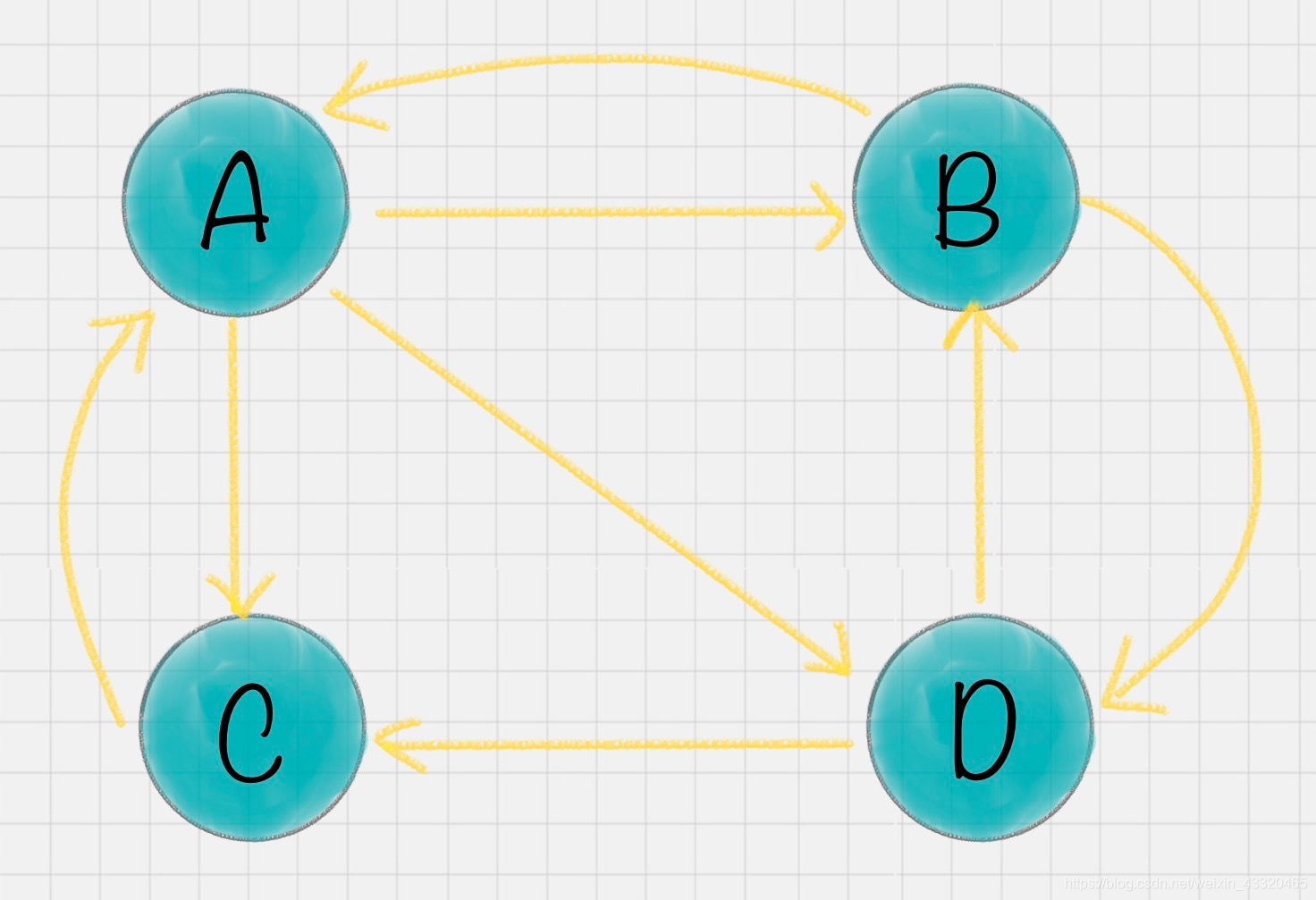
A 有三个出链分别链接到了 B、C、D 上,跳转概率均为 1/3。B 有两个出链,跳转概率为 1/2。A、B、C、D 这四个网页的转移矩阵 M:
假设 A、B、C、D 四个页面的初始影响力都是相同: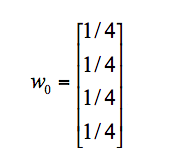
第一次转移之后,各页面的影响力 w1 变为:

再用转移矩阵乘以 w1 得到 w2 结果,直到第 n 次迭代后 wn 影响力不再发生变化,可以收敛到 (0.3333,0.2222,0.2222,0.2222),也就是对应着 A、B、C、D 四个页面最终平衡状态下的影响力 -
两个问题:
- 等级泄露(Rank Leak):如果一个网页没有出链,就像是一个黑洞一样,吸收了其他网页的影响力而不释放,最终会导致其他网页的 PR 值为 0。
- 等级沉没(Rank Sink):如果一个网页只有出链,没有入链(如下图所示),计算的过程迭代下来,会导致这个网页的 PR 值为 0(也就是不存在公式中的 V)。针对等级泄露和等级沉没的情况,我们需要灵活处理。
-
随机浏览模型
为了解决简化模型中存在的等级泄露和等级沉没的问题,提出了 PageRank 的随机浏览模型。
他假设了这样一个场景:用户并不都是按照跳转链接的方式来上网,还有一种可能是不论当前处于哪个页面,都有概率访问到其他任意的页面,比如说用户就是要直接输入网址访问其他页面,虽然这个概率比较小.所以他定义了阻尼因子 d,这个因子代表了用户按照跳转链接来上网的概率,通常可以取一个固定值 0.85,而 1-d=0.15 则代表了用户不是通过跳转链接的方式来访问网页的,比如直接输入网址。
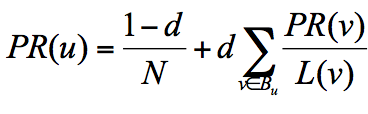
其中 N 为网页总数,这样我们又可以重新迭代网页的权重计算了,因为加入了阻尼因子 d,一定程度上解决了等级泄露和等级沉没的问题。
Google 不断地重复计算每个页面的 PageRank,如果给 每个页面一个随机 PageRank 值(非 0),那么经过不断地重复计算,这些页面 的 PR 值会趋向于稳定,也就是收敛的状态 -
应用
只要是有网络的地方,就存在出链和入链,就会有 PR 权重的计算,也就可以运用我们今天讲的 PageRank 算法。- 社交网络领域
- 微博粉丝数并不一定等于他的实际影响力。如果按照 PageRank 算法,还需要看这些粉丝的质量如何。如果有很多明星或者大 V 关注,那么这个人的影响力一定很高。如果粉丝是通过购买僵尸粉得来的,那么即使粉丝数再多,影响力也不高
- 工作场景中,比如说脉脉这个社交软件,它计算的就是个人在职场的影响力。如果你的工作关系是李开复、江南春这样的名人,那么你的职场影响力一定会很高。反之,如果你是个学生,在职场上被链入的关系比较少的话,职场影响力就会比较低。
- 社交网络领域
Apriori
1.基本认知
-
简介
Apriori 算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。已被 广泛的应用到商业、网络安全等各个领域。在实际工作中,我们常用 FP-Growth 来做频繁项集的挖掘。当然 Apriori 的改进算法除了 FP-Growth 算法以外,还有 CBA 算法、GSP 算法。- 关联规则
最早是由 Agrawal 等人在 1993 年提出的。在 1994 年 Agrawal 等人又提出了基于关联规则的 Apriori 算法,至今 Apriori 仍是关联规则挖掘的重要算法。
- 关联规则
-
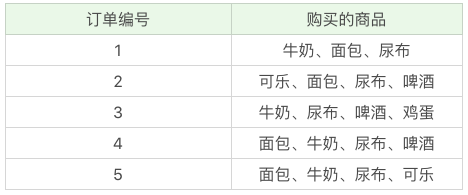
重要概念
-
项集 itemset
它可以是单个的商品,也可以是商品的组合。 -
支持度
支持度是个百分比,度量 一个集合在原始数据中出现的频率。指的是:某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大
在这个例子中,我们能看到“牛奶”出现了 4 次,那么这 5 笔订单中“牛奶”的支持度就是 4/5=0.8。同样“牛奶 + 面包”支持度就是 3/5=0.6。 -
最小支持度Min Support
支持度是针对项集来说的,因此可以定义一个最小支持度,只保 留最小支持度的项集 。 -
频繁项集
频繁项集就是支持度大于等于最小支持度 阈值的项集,所以小于最小值支持度的项目就是非频繁项集,而大于等于最小支持度的项集就是频繁项集 -
置信度
置信度是个条件概念,就是说在 A 发生的情况下,B 发生的概率是多少。它指的就是当你购买了商品 A,会有多大的概率购买商品 B,在上面这个例子中:
置信度(牛奶→啤酒)=2/4=0.5,代表如果你购买了牛奶,有多大的概率会购买啤酒?
置信度(啤酒→牛奶)=2/3=0.67,代表如果你购买了啤酒,有多大的概率会购买牛奶? -
提升度
我们在做商品推荐的时候,重点考虑的是提升度,因为提升度代表的是“商品 A 的出现,对商品 B 的出现概率提升的”程度。
还是看上面的例子,如果我们单纯看置信度 (可乐→尿布)=1,也就是说可乐出现的时候,用户都会购买尿布,那么当用户购买可乐的时候,我们就需要推荐尿布么?
实际上,就算用户不购买可乐,也会直接购买尿布的,所以用户是否购买可乐,对尿布的提升作用并不大。
我们可以用下面的公式来计算商品 A 对商品 B 的提升度:
提升度 (A→B)= 置信度 (A→B)/ 支持度 (B)
这个公式是用来衡量 A 出现的情况下,是否会对 B 出现的概率有所提升。
所以提升度有三种可能:
提升度 (A→B)>1:代表有提升;
提升度 (A→B)=1:代表有没有提升,也没有下降;
提升度 (A→B)<1:代表有下降
-
-
Apriori 算法的工作原理
关联分析,从数据集中发现项与项(item 与 item)之间的关系——有两个目标: 频繁项集frequent itemset、关联规则。频繁项集指经常一块出现的物品集合;关联规则暗示两 种物品之间可能存在很强的关系。-
规则:通过排除法来选择频繁项集和关联规则,
(1) 如果某个项集是频繁的,那么它的所有子集也是频繁的;
(2) 如果某个项集是非频繁的,那么它的所有超集也是非频繁的;
(3) 基于此,Apriori算法从单元素项集开始,通过组合满足最小支持 度的项集来形成更大的集合。 -
递归流程:
- K=1,计算 K 项集的支持度;
- 筛选掉小于最小支持度的项集;
- 如果项集为空,则对应 K-1 项集的结果为最终结果。
- 否则 K=K+1,重复 1-3 步。
-
步骤
- 找出所有的频繁项集(frequent itemset),这些项集出现的频繁性至少和预定义的最小支持度一样。
首先我们把上面案例中的商品用 ID 来代表,牛奶、面包、尿布、可乐、啤酒、鸡蛋的商品 ID 分别设置为 1-6,上面的数据表可以变为:
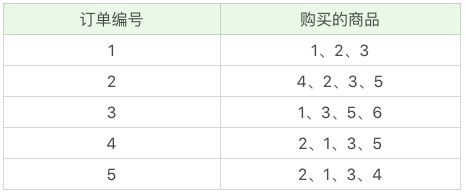 假设我随机指定最小支持度是 50%,也就是 0.5。
假设我随机指定最小支持度是 50%,也就是 0.5。 - 由频繁项集产生强关联规则,这些规则必须满足最小支持度 和最小可信度
1.先计算单个商品的支持度,也就是得到 K=1 项的支持度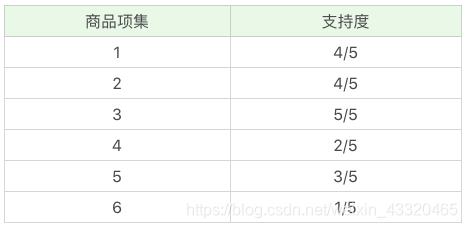
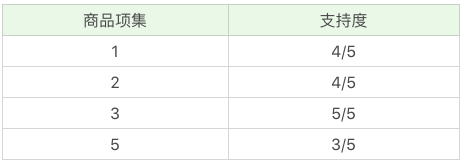
因为最小支持度是 0.5,所以你能看到商品 4、6 是不符合最小支持度的,不属于频繁项集,于是经过筛选商品的频繁项集就变成:
- 使用第一步找到的频繁项集产生期望的规则,产生只包含 集合的项的所有规则,其中每一条规则的右边只有一项,一旦这些规则被生成, 那么只有那些大于用户给定的最小可信度的规则才被留下来。为了生成所有频 繁项集,使用了递归的方法。
2.将商品两两组合(根据规则2),得到 k=2 项的支持度
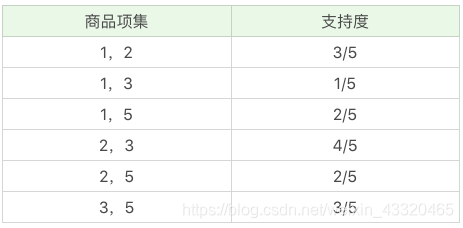
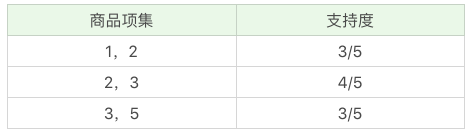
筛掉小于最小值支持度的商品组合,可以得到:
3.K=3 项的商品组合,可以得到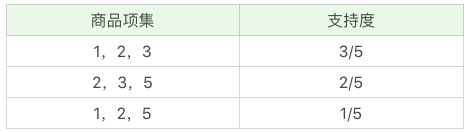
再筛掉小于最小值支持度的商品组合,可以得到
-
-
改进算法:FP-Growth 算法
- Apriori 优点,算法简单明了,没有复杂的理论推导,也易于实现
- Apriori 缺点,会浪费很多计算空间和计算时间:
- 可能产生大量的候选集。因为采用排列组合的方式,把可能的项集都组合出来了;
- 每次计算都需要重新扫描数据集,来计算每个项集的支持度。
- FP-Growth 算法,它的特点是:
- 创建了一棵 FP 树来存储频繁项集。在创建前对不满足最小支持度的项进行删除,减少了存储空间。
- 整个生成过程只遍历数据集 2 次,大大减少了计算量。
-
FP-Growth 的原理
1. 创建项头表(item header table)
项头表包括了项目、支持度,以及该项在 FP 树中的链表。初始的时候链表为空。
创建项头表的作用是为 FP 构建及频繁项集挖掘提供索引。这一步的流程是先扫描一遍数据集,对于满足最小支持度的单个项(K=1 项集)按照支持度从高到低进行排序,这个过程中删除了不满足最小支持度的项。

2. 构造 FP 树
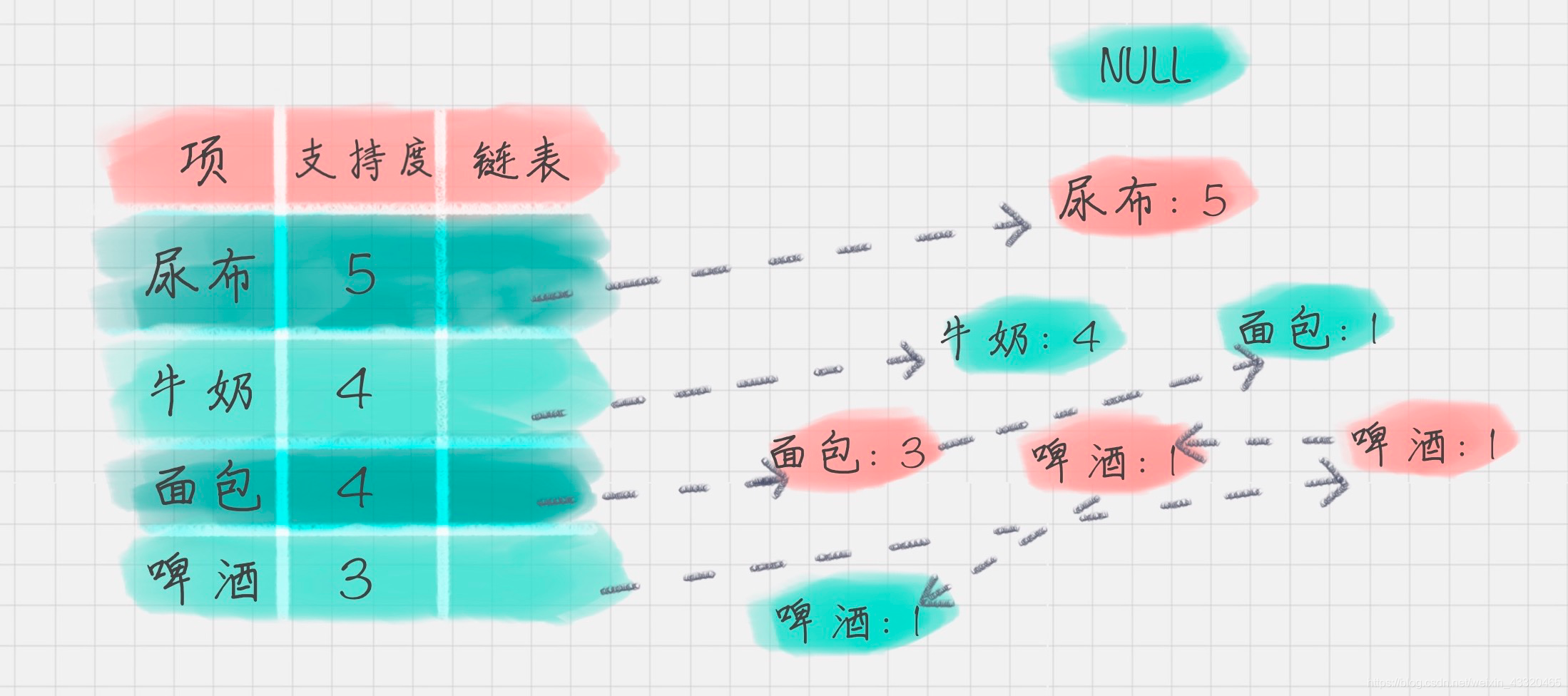
FP 树的根节点记为 NULL 节点。整个流程是需要再次扫描数据集,对于每一条数据,按照支持度从高到低的顺序进行创建节点(也就是第一步中项头表中的排序结果),节点如果存在就将计数 count+1,如果不存在就进行创建。同时在创建的过程中,需要更新项头表的链表
- 通过 FP 树挖掘频繁项集
具体的操作会用到一个概念,叫“条件模式基”,它指的是以要挖掘的节点为叶子节点,自底向上求出 FP 子树,然后将 FP 子树的祖先节点设置为叶子节点之和。
“啤酒”的节点为例,从 FP 树中可以得到一棵 FP 子树,将祖先节点的支持度记为叶子节点之和,得到:
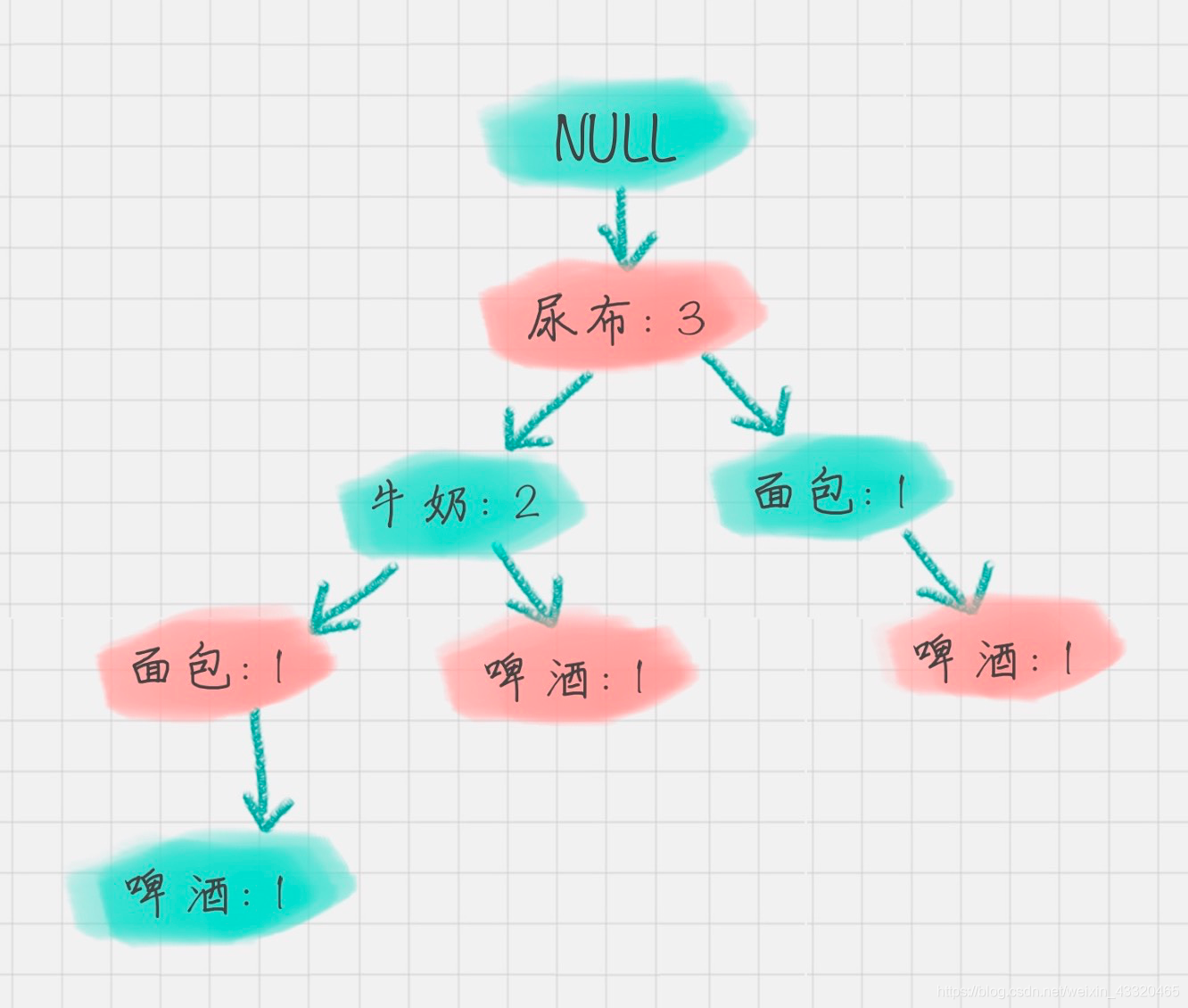
相比于原来的 FP 树,尿布和牛奶的频繁项集数减少了。这是因为我们求得的是以“啤酒”为节点的 FP 子树,也就是说,在频繁项集中一定要含有“啤酒”这个项。你可以再看下原始的数据,其中订单 1{牛奶、面包、尿布}和订单 5{牛奶、面包、尿布、可乐}并不存在“啤酒”这个项,所以针对订单 1,尿布→牛奶→面包这个项集就会从 FP 树中去掉,针对订单 5 也包括了尿布→牛奶→面包这个项集也会从 FP 树中去掉,所以你能看到以“啤酒”为节点的 FP 子树,尿布、牛奶、面包项集上的计数比原来少了 2。条件模式基不包括“啤酒”节点,而且祖先节点如果小于最小支持度就会被剪枝,所以“啤酒”的条件模式基为空。
同理,我们可以求得“面包”的条件模式基为:
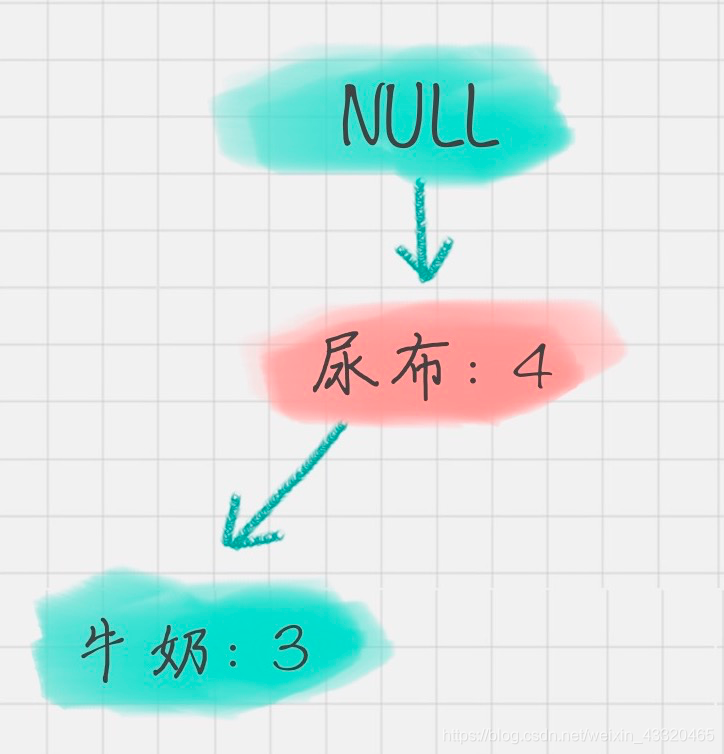
- 通过 FP 树挖掘频繁项集
AdaBoost.
1.基本认知
-
简介
AdaBoost 算法,Adaptive Boosting,中文含义是自适应提升算法,分类算法中的集成算法。其核心思想是其实是针对同一个训练集训练不同的分 类器(弱分类器),然后把这些弱分类器根据不同的权重组合,构成一个更强的最终分类器 (强分类器)。
实际上 AdaBoost 算法是一个框架,你可以指定任意的分类器,通常我们可以采用 CART 分类器作为弱分类器 -
组合公式
假设弱分类器为 Gi(x),它在强分类器中的权重 αi,那么就可以得出强分类器 f(x):
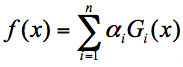
-
如何得到弱分类器,也就是在每次迭代训练的过程中,如何得到最优弱分类器?
通过改变样本的数据分布来实现的。
(1) 先通过对N个训练样本的学习得到第一个弱分类器;
(2) 将分错的样本增加权重和其他的新数据一起构成一个新的N个的训练样本, 再基于上一次得到的分类准确率,来确定这次训练样本中每个样本的权重,将修改过权值的新数据集送给下层分类器进行训练,得到第二个弱分类器,整个训练过程如此迭代地进行下去;
(3) 将第1、2步都分错了的样本加上其他的新样本构成另一个新的N 个的训练样本,通过对这个样本的学习得到第三个弱分类器;
(4) 最终分类器最后融合成强分类器。即某个数据被分为哪一类要由各分类器 权值决定。
Dk+1 代表第 k+1 轮训练中,样本的权重集合,其中 Wk+1,1 代表第 k+1 轮中第一个样本的权重,以此类推 Wk+1,N 代表第 k+1 轮中第 N 个样本的权重,因此用公式表示为:
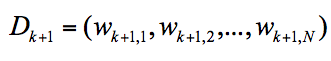
第 k+1 轮中的样本权重,是根据该样本在第 k 轮的权重以及第 k 个分类器的准确率而定,具体的公式为:
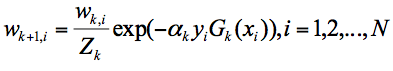
该算法其实是简单的弱分类算法的提升过程,这个过程通过不断地训练,可以提高对数据的分类能力。这样做的好处就是,通过每一轮训练样本的动态权重,可以让训练的焦点集中到难分类的样本上,最终得到的弱分类器的组合更容易得到更高的分类准确率。 -
每个弱分类器在强分类器中的权重是如何计算的?
基于这个弱分类器对样本的分类错误率来决定它的权重。实际上在一个由 K 个弱分类器中组成的强分类器中,如果弱分类器的分类效果好,那么权重应该比较大,如果弱分类器的分类效果一般,权重应该降低。所以我们需要用公式表示就是:
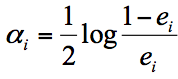
其中 ei 代表第 i 个分类器的分类错误率。 -
主要解决
两类问题、 多类单标签问题、多类多标签问题、大类单标签问题和回归问题。 -
优缺点
- 优点
- Aadboost 算法系列具有较高的检测速率,且不易出现过拟合现象。
- 缺点
- 该 算法在实现过程中为取得更高的检测精度则需要较大的训练样本集,执行效果 依赖于弱分类器的选择,搜索时间随之增加,故训练过程使得所用时间非常大, 也因此限制了该算法的广泛应用。
- 优点
算法示例
假设我有 10 个训练样本如下所示,希望通过 AdaBoost 构建一个强分类器
有 3 个基础分类器:
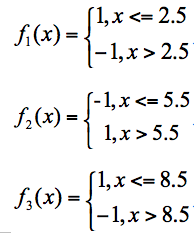
- 第一轮训练中,我们得到 10 个样本的权重为 1/10,即初始的 10 个样本权重一致,D1=(0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1)。
分类器 f1 的错误率为 0.3,也就是 x 取值 6、7、8 时分类错误;
分类器 f2 的错误率为 0.4,即 x 取值 0、1、2、9 时分类错误
分类器 f3 的错误率为 0.3,即 x 取值为 3、4、5 时分类错误。
f1、f3 分类器的错误率最低,因此我们选择 f1 或 f3 作为最优分类器,假设我们选 f1 分类器作为最优分类器,即第一轮训练得到: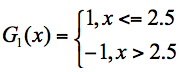
分类器权重公式得到:
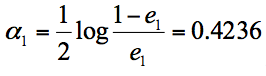
- 然后我们对下一轮的样本更新求权重值,代入 Wk+1,i 和 Dk+1 的公式,可以得到新的权重矩阵:D2=(0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。
- 在第二轮训练中,我们继续统计三个分类器的准确率,可以得到分类器 f1 的错误率为 0.16663,也就是 x 取值为 6、7、8 时分类错误。分类器 f2 的错误率为 0.07154,即 x 取值为 0、1、2、9 时分类错误。分类器 f3 的错误率为 0.0715*3,即 x 取值 3、4、5 时分类错误。3 个分类器中,f3 分类器的错误率最低,因此我们选择 f3 作为第二轮训练的最优分类器,即:
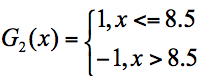
根据分类器权重公式得到:
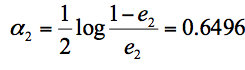
- 同样,我们对下一轮的样本更新求权重值,代入 Wk+1,i 和 Dk+1 的公式,可以得到 D3=(0.0455,0.0455,0.0455,0.1667, 0.1667,0.01667,0.1060, 0.1060, 0.1060, 0.0455)。
- 在第三轮训练中,我们继续统计三个分类器的准确率,可以得到分类器 f1 的错误率为 0.10603,也就是 x 取值 6、7、8 时分类错误。分类器 f2 的错误率为 0.04554,即 x 取值为 0、1、2、9 时分类错误。分类器 f3 的错误率为 0.1667*3,即 x 取值 3、4、5 时分类错误。
在这 3 个分类器中,f2 分类器的错误率最低,因此我们选择 f2 作为第三轮训练的最优分类器,即: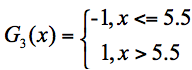
我们根据分类器权重公式得到: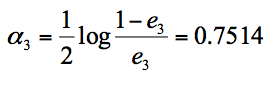
- 假设我们只进行 3 轮的训练,选择 3 个弱分类器,组合成一个强分类器,那么最终的强分类器 G(x) = 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)
模型效果评估
预测模型评估:
MSE
Mean squared error,均方误差。
参数估计值与参数真值之差平方的期望值,
用于评估数据的变化程度,MSE值越小,模型精确度越高。
RMSE
均方误差的算术平方根
MAE
mMean absolute error.平均绝对误差,绝对误差的平均值。平均绝对误差在一些问题上能够更好地反映预测误差的实际情况。
二分类模型评估:
| 预测为正例 | 预测为负例 | |
|---|---|---|
| 实际为正例 | TP:True Positive。 | FN:False Negative |
| 实际为负例 | FP:False Positive | TN:True Negative |
-
正例反例
是一个相对概念。正想里通常我是我们所关注的结果。 -
精确率precision,TP/(TP+FP)
预测为正例的正确率。实际问题中更关注准确率,样本的正负例分布并不均匀。 -
召回率recall,TP/(TP+FN)
实际为正例的正确率 -
正确率,(TP+TN)/(TP+FP+FP+TN)
判断的总正确率 -
pr曲线
以precision(精准率)和recall(召回率)这两个为变量而做出的曲线,其中recall为横坐标,precision为纵坐标。
一条PR曲线要对应一个阈值。通过选择合适的阈值,比如50%,对样本进行划分,概率大于50%的就认为是正例,小于50%的就是负例,从而计算相应的精准率和召回率。
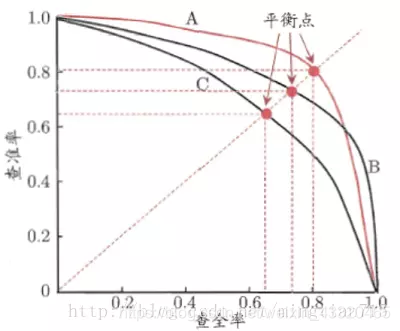
如果一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则可断言后者的性能优于前者,例如上面的A和B优于学习器C。但是A和B的性能无法直接判断,我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点或者是F1值。平衡点(BEP)是P=R时的取值,如果这个值较大,则说明学习器的性能较好。而F1 = 2 * P * R /( P + R ),同样,F1值越大,我们可以认为该学习器的性能较好。 -
ROC曲线
用来刻画二分类问题的图形。
横轴是假正例率(FPR),纵轴是真正例率(TPR)。
(1)真正类率(True Postive Rate)TPR: TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。
(2)负正类率(False Postive Rate)FPR: FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例。
我们可以发现:TPR=Recall。 -
AUC:
ROC曲线一定会经过(0,0)和(1,1)两个点。在此基础上,要尽量使曲线下方所围成的面积最大化。这部分面积称为AUC。在解释性较强的问题中会经常用到。 -
多分类问题的评估方法
- 将多分类问题转化了二分类问题
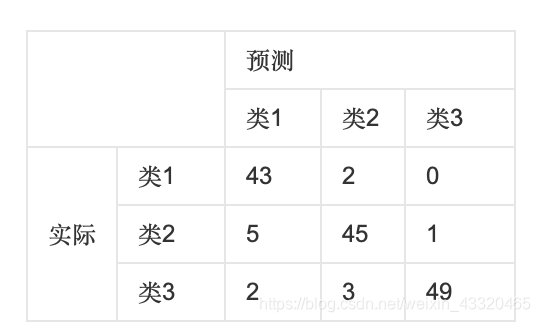
将最关心的分类作为正例,其余作为负例 - 混淆矩阵
- 将多分类问题转化了二分类问题