数据挖掘基本概念
数据挖掘是一个从大规模数据集中提取隐含的、以前未知的、有潜在应用价值信息的非平凡过程。
-Non-trivial extraction of implicit , previously unknown and potentially useful information from massive collection of data.
与数据库技术的区别
1.数据库技术:从大量的数据里找某个数据,或是简单的数据统计信息。 好比在草堆里找别针。
2.数据挖掘找的不是一个已存在那里的信息。 好比是要设法搞清楚在草堆里有一根针,会造成什么样的后果。
数据挖掘过程
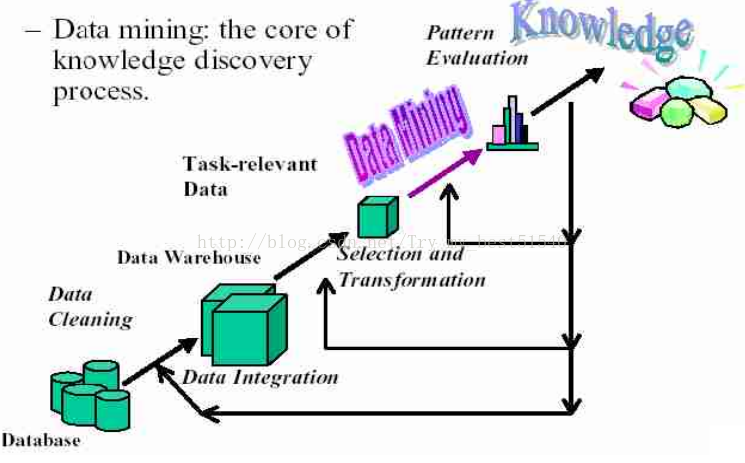
详细过程
- 了解应用领域,掌握相关先验知识以及应用的目标
- 收集并集成数据
- 对数据进行清洁和预处理
- 对数据进行归约和投影(发现有用特征,降维和变量约简)
- 确定适当的数据挖掘功能(总计、分类、回归、关联、聚类)
- 确定数据挖掘算法,并进行数据挖掘
- 对挖掘结果进行评估
- 对挖掘结果进行解释:分析结果
- 应用发现的知识
数据挖掘的数据类型
记录型数据
矩阵数据
文本数据
事物型数据
图表型数据
基因图表
网页链接
社交网络
化学式结构数据
顺序型数据
序列化业务

基因序列数据
时空数据
数据挖掘的任务
预言(Prediction Methods)
-用历史预测未来
描述(Description Methods)
-了解数据中潜在的规律
- 分类[ Predictive ]
在众多的分类知识发现算法中最广泛使用的是分治算法(divide-and-conquer algorthms)
分治算法归纳生成树状结构,成为决策树。
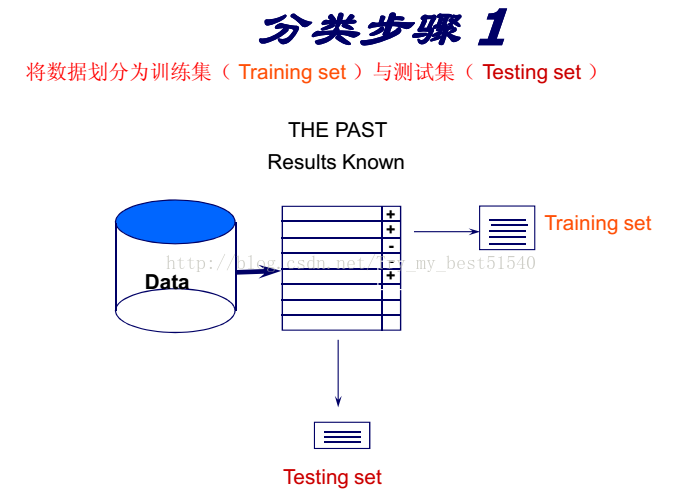
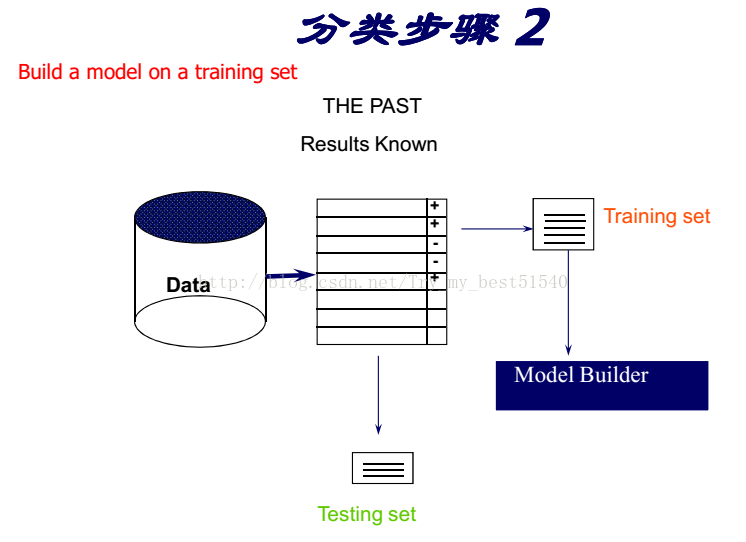
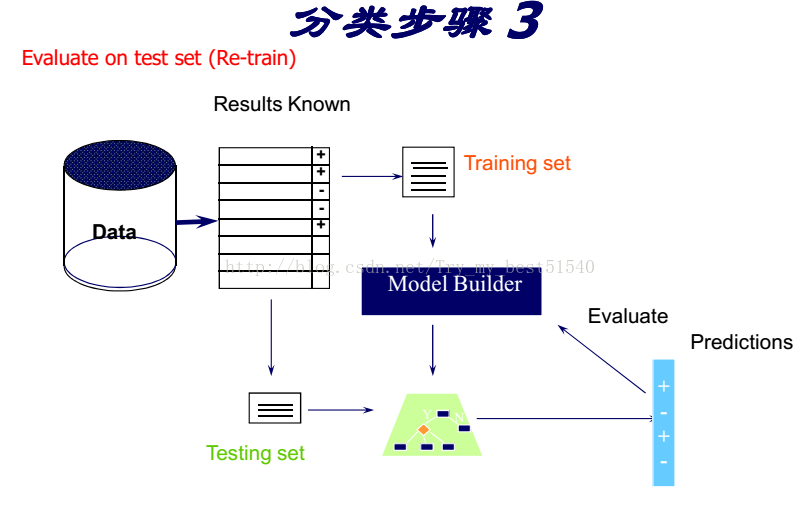
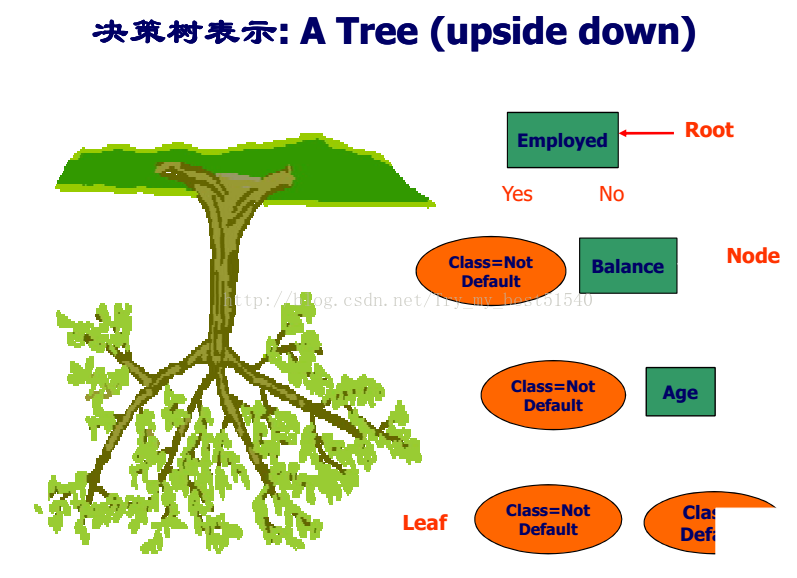
决策树学习的目标
基于客户属性,将客户分为不同的子群体(在同一个群体中的例子数据同一个类别)
- 聚类[ Description ]
Given a set of data points , each having a set of attributes , and a similarity measure among them , find clusters such that
Data points in one cluster are more similar to one another
Data points in separate clusters are less similar to one another.
Similarity Measures:
-Euclidean Distance if attributes are continuous. 欧几里得距离
(一定要标准化)量纲的问题
对属性绝对地敏感(可能过于细分)
-Other Problem-specific Measures. 一些具体问题方法
余弦相似度计算
聚类的应用:
Market Segmentation 市场细分
Document Clustering 文本聚类
- 关联规则挖掘[ Descriptive ] Association Rule Discovery
支持度:两件事同时发生的概率
置信度:一件事发生时另一件事情发生的概率
应用: Marketing and Sales Promotion 哪种商品可以促进另一种商品的销售
Supermarket shelf management 哪些商品适合放在一起
- 序列模式发现[ Descriptive ] Sequential Pattern Discovery

Examples

应用:
网页搜索时旁边的推荐

- 社团挖掘[ Descriptive ]
- 文本挖掘[ Predictive ]
SVMs机器 (Support Vector Machines)
SVMS are a rare example of a methodology where geometric intuition , elegant mathematics , throretical guarantees , and practical use meet.
四个方面: 几何、数学、理论、实践
数据挖掘的一些挑战性问题
1.高维数据和高速数据流挖掘
超高维分类问题(数百万或数十亿的特征如生物信息数据)
超高速的数据流
2.有序的和时间序列数据
如何有效准确地聚类、分类和预测趋势?
用来预测的时间序列数据有噪声数据干扰
3.从复杂数据中挖掘复杂知识
图挖掘
不是独立对等分布的数据
结合数据挖掘和知识推理
知识兴趣度的研究
4.网络结构中的数据挖掘
社会网络
计算机网络的挖掘(检测异常、需要处理大规模的以太网链接:检测、跟踪、丢弃信息包)
5.移动计算环境下的数据挖掘
移动计算环境下数据挖掘技术的发展方向
面向用户
构建人性化的人机交互方式
可以处理动态数据的主动式数据挖掘系统
移动计算环境下数据挖掘的主要应用有:
用户移动模式挖掘
基于数据挖掘的位置管理
6.生物信息的数据挖掘
新的状况产生新的问题
特别的大规模问题:生物数据挖掘,如HIV疫苗设计,DNA,化学属性,3D结构,功能属性->需要融合
7.挖掘结果的可视化显示
8.安全、隐私和数据完整性
9.处理非静态、不稳定和成本敏感的数据
有的数据库高度不稳定
有很多成本和获益的信息,但是没有一个全面的模型来描述盈利和亏本
数据可能包含样本代入的倾向性
Conclusions:
