Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎; 它被设计为用来专门进行高速、实时的数据分析,以弥补 Hive 在速度和对接多种数据源上的短板;专门为交互式查询所设计,提供分钟级乃至亚秒级低延时的查询性能。
1.1 Presto 架构
Presto 是典型的 MPP 架构,由一个 Coordinator 和多个 Worker 组成,其中 Coordinator 负责 SQL 的解析和调度,Worker 负责任务的具体执行。可配置多个不同类型的 Catalog,实现对多个数据源的访问。
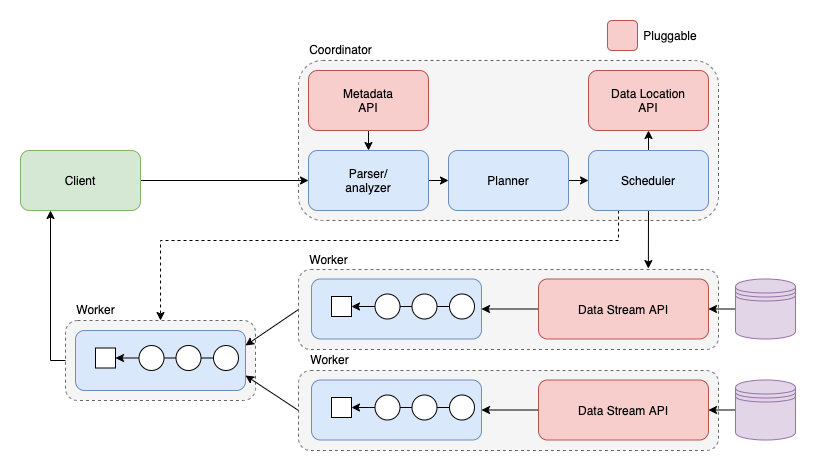
1.2 Presto 执行查询过程
- Client 发送请求给 Coordinator。
- SQL 通过 ANTLR 进行解析生成 AST。
- AST 通过元数据进行语义解析。
- 语义解析后的数据生成逻辑执行计划,并且通过规则进行优化。
- 切分逻辑执行计划为不同 Stage,并调度 Worker 节点去生成 Task。
- Task 生成相应物理执行计划。
- 调度完后根据调度结果 Coordinator 将 Stage 串联起来。
- Worker 执行相应的物理执行计划。
- Client 不断地向 Coordinator 拉取查询结果,Coordinator 从最终汇聚输出的 Worker 节点拉取查询结果。
1.3 Presto 为何高性能
- Pipeline, 全内存计算。
- SQL 查询计划规则优化。
- 动态代码生成技术。
- 数据调度本地化,注重内存开销效率,优化数据结构,Cache,非精确查询等其它技术。
1.4 Presto优化
-
Coordinator 节点不作为计算节点,只作为协调节点;
-
每台物理机只部署一个 Presto 节点,无其他任何竞争服务;
-
JVM 配置为 G1 回收器、最大堆内存为物理内存的 75%;
-
设置堆外内存最大使用量 MaxDirectMemorySize;
-
设置 glibc 的参数 export MALLOC_ARENA_MAX=1 ;