Presto基本概念
Presto是Facebook开源的MPP SQL引擎,旨在填补Hive在速度和灵活性(对接多种数据源)上的不足。相似的SQL on Hadoop竞品还有Impala和Spark SQL等。这里我们介绍下Presto的基本概念,为后续的笔记做基础。
Operator Model & Iterator Model
MPP(Massive Parellel Processing)系统的鼻祖是一个叫Volcano的并行数据库(论文在此),它提出了一种并行执行SQL的设计,即通过各种Operator(如TableScan、Project、Filter、Aggregate、Exchange、Join等)组成一棵树,树的根节点产生SQL输出,树的叶子节点是各种TableScan,数据从叶子节点流入,一步步被加工直至产生最终结果。这个模型称为Operator Model,这棵树我们称之为执行计划(Plan,在传统数据库里又分为逻辑计划和物理计划)。
在Operator Model执行的过程中,各节点有三种基本状态(或者说要实现三个接口):Open、GetNext、Close。父节点的接口调用一般会递归调用子节点对应的接口。SQL执行时就从根节点Open开始,然后不断调其GetNext接口得到一行输出(后续演变为得到RowBatch),直到没有结果为止,最后调Close。这个模型称为Iterator Model。
Stage
在MPP系统里,一个执行计划经常会被切分为各种子树(一般称为PlanFragment),每个子树可以并行地在多台机器上执行。PlanFragment之间通过Exchange Operator来传递数据,这里就有很多技术(如Shuffle、Broadcast等)。
Presto中一个Stage就对应一个PlanFragment。在Presto的Web UI里可以看到如下的Stage连接图,整个执行计划被划分为若干Stage,每个Stage里都有一个PlanFragment。还可以看到Stage里有很多Operator,我们后面再说。
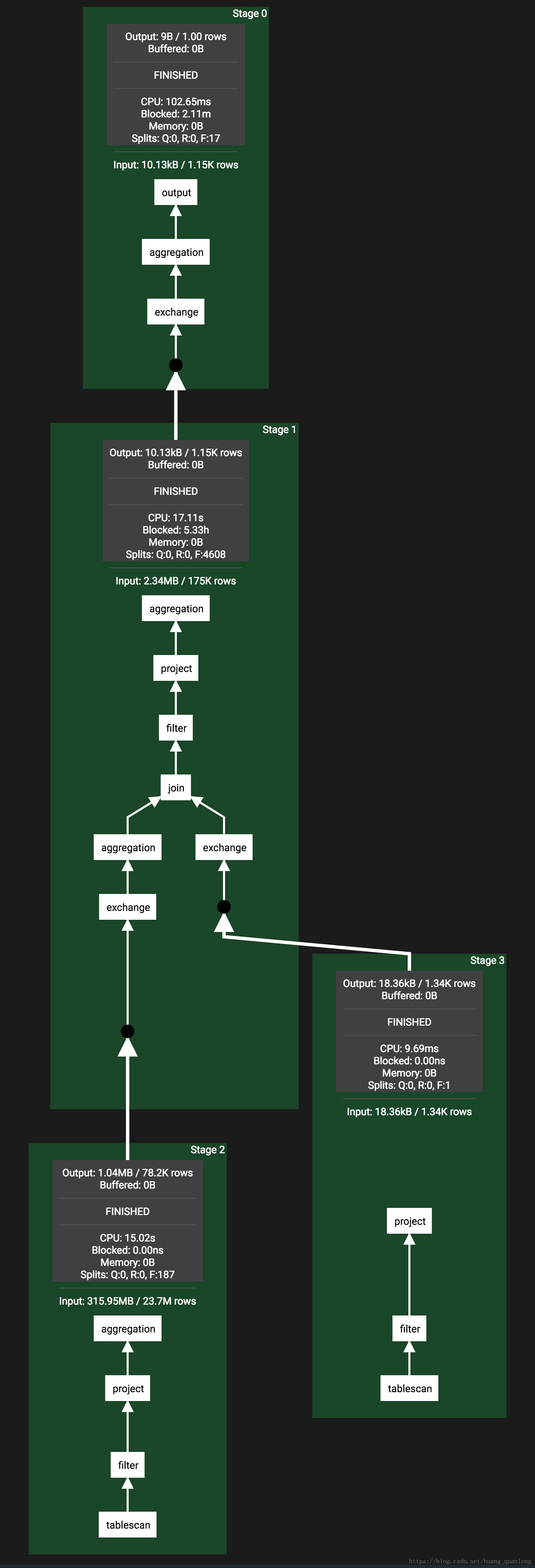
Task
Stage只是定义了执行计划怎么划分,接下来会被调度到各个机器上去执行,每一个实例就称为一个Task,也就是说Presto里Task是Stage的实例。一般来说,一台机器(Presto里的Worker)只会运行一个Stage的一个实例。当然它会跑多个Task,但它们一般来说是属于不同的Stage的。因为理论上来说同一个Stage的Task实例是相同的,在一台机器上跑两个跟跑一个是机同的(Task里面已经有并行了)。
在Presto的Web UI里可以看到如下的Task Overview,默认情况下一个Stage最多在一个Worker上跑一个Task。Task ID由两部分组成,第一部分是Stage ID,第二部分为该Task在对应Stage里的ID。可以看到同个Stage下的不同Task是跑在不同机器上的(一般一台机器只跑一个Presto Worker)。
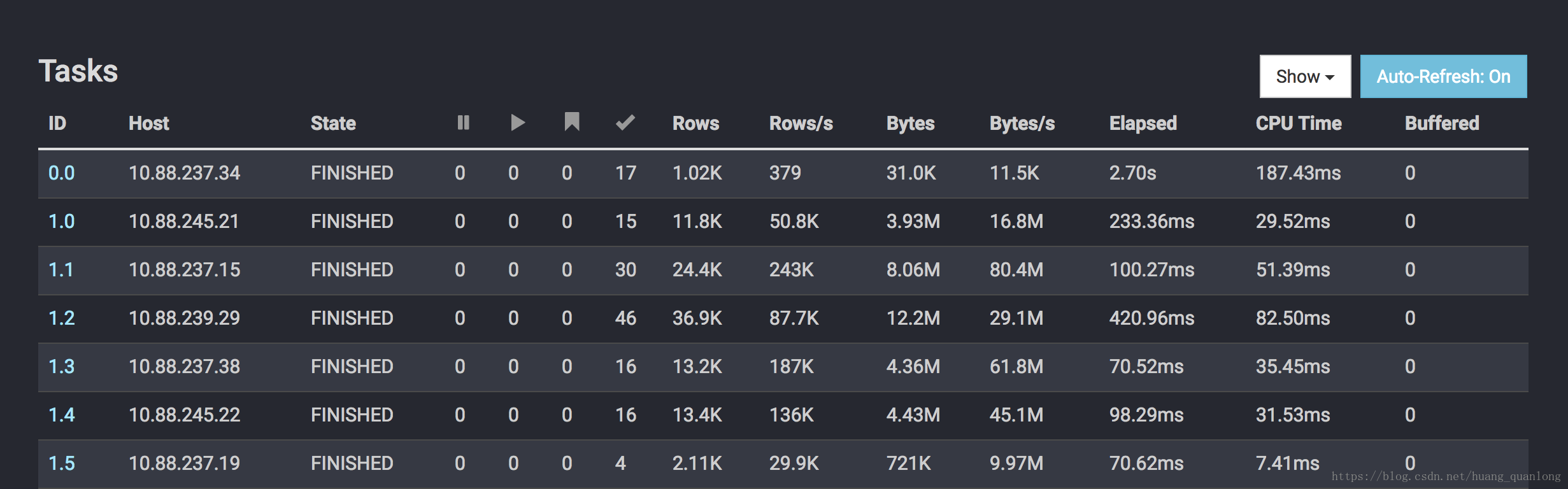
Pipeline
每个Task执行一个Stage的逻辑,也可以说就是执行一个PlanFragment里的Operator,这些Operator的最佳并行度可能是不同的。比如说做Tablescan的并发可以很大,但做Final Aggregation(如Sort)的并发度只能是一。基于这个考虑,一个PlanFragment又会被切分为若干Pipeline,每个Pipeline由一组Operator组成,这些Operator被设置同样的并行度。Pipeline之间会通过LocalExchangeOperator来传递数据。
在Presto的Web UI里可以看到下面的Pipeline图。Driver的数目就是这个Pipeline的并行度。
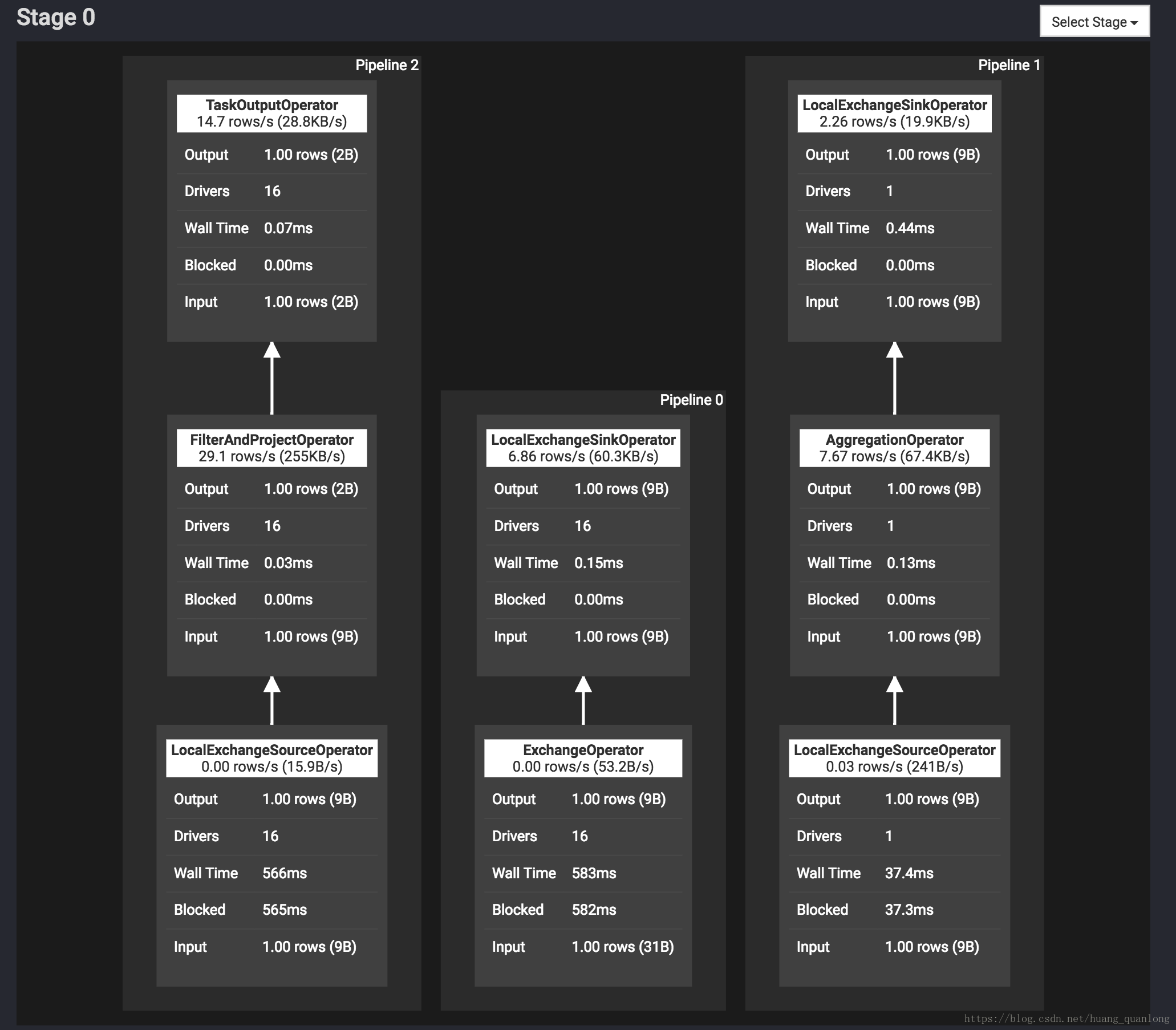
Driver
Pipeline其实是一个虚拟的概念,它的实例就叫Driver。可以说Pipeline就是DriverFactory,用来create Driver的。每一个Driver由一串Operator组成,负责接收一组输入数据,并产生一组输出数据。Driver里不再有并行度,每个Driver都是单线程的。
Split
Split就是一组数据,可以认为是一个RowBatch,也可以说是Table的一个分片。对于Hive中的表,一个Split就是HDFS文件的一个分片。可能是一个Block的大小(如果文件格式支持分片,如ORC、Parquet等),也可能是整个文件(如果文件格式不支持分片,如zip文件)。具体地,可以看源码中HiveSplit的定义:
public class HiveSplit
implements ConnectorSplit
{
private final String clientId;
private final String path; // HDFS中的文件路径
private final long start; // Split在文件中的起始位置
private final long length; // Split的长度
private final Properties schema;
private final List<HivePartitionKey> partitionKeys;
private final List<HostAddress> addresses; // 对应Block所在的DataNode地址
private final String database;
private final String table;
private final String partitionName;
private final TupleDomain<HiveColumnHandle> effectivePredicate;
private final OptionalInt bucketNumber;
private final boolean forceLocalScheduling;
private final Map<Integer, HiveType> columnCoercions;
...
}总结
Presto的基本概念就介绍到这里,总结一下:
- Stage对应一个PlanFragment
- Task是Stage的实例
- 每个PlanFragment会被拆分为若干Pipeline
- Pipeline的实例是Driver
- Split是Table的一个分片,在Hive中可以对应HDFS文件的一个分片