presto:
https://blog.csdn.net/u011596455/article/details/86558218
部署:
https://blog.csdn.net/weixin_33701564/article/details/91894251
使用的技术,如向量计算,动态编译执行计划,优化的ORC和Parquet Reader等
presto不太支持存储过程,支持部分标准sql
presto的查询速度比hive快5-10倍
上面讲述了presto是什么,查询速度,现在来看看presto适合干什么
适合:PB级海量数据复杂分析,交互式SQL查询,支持跨数据源查询
不适合:多个大表的join操作,因为presto是基于内存的,多张大表在内存里可能放不下
presto是一个交互式查询引擎,可以在很短的时间内返回查询结果,秒级,分钟级,能访问很多数据源
Presto支持的数据源和存储格式:
Hadoop/Hive connector与存储格式:
HDFS,ORC,RCFILE,Parquet,SequenceFile,Text
开源数据存储系统:
MySQL & PostgreSQL,Cassandra,Kafka,Redis
其他:
MongoDB,ElasticSearch,HBase
执行过程:
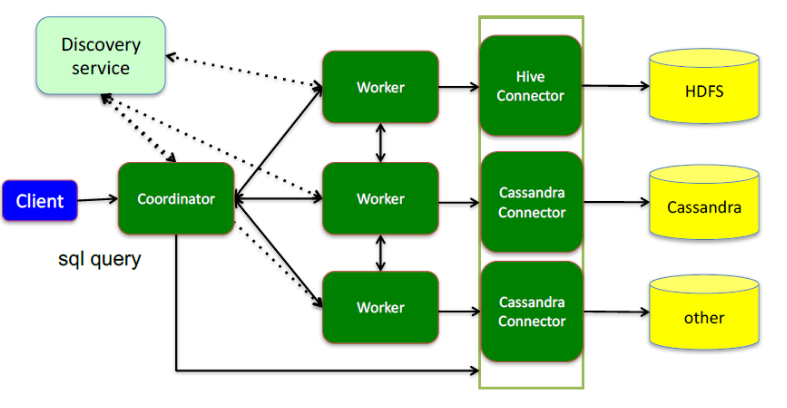
Coordinator(考第内ter),是一个中心的查询角色,它主要的一个作用是接受查询请求,将他们转换成各种各样的任务,将任务拆解后分发到多个worker去执行各种任务的节点
1、解析SQL语句
2、⽣成执⾏计划
3、分发执⾏任务给Worker节点执
Worker,是一个真正的计算的节点,执行任务的节点,它接收到task后,就会到对应的数据源里面,去把数据提取出来,提取方式是通过各种各样的connector:
1、负责实际执⾏查询任务
Discovery service,是将coordinator和woker结合到一起的服务:
2、Worker节点启动后向Discovery Server服务注册
3、Coordinator从Discovery Server获得Worker节点
coordinator和woker之间的关系是怎么维护的呢?是通过Discovery Server,所有的worker都把自己注册到Discovery Server上,Discovery Server是一个发现服务的service,Discovery Server发现服务之后,coordinator便知道在我的集群中有多少个worker能够给我工作,然后我分配工作到worker时便有了根据
最后,presto是通过connector plugin获取数据和元信息的,它不是数据存储引擎,不需要有数据,presto为其他数据存储系统提供了SQL能⼒,客户端协议是HTTP+JSON