探探的实践:https://mp.weixin.qq.com/s?__biz=MzA4ODg0NDkzOA==&mid=2247487119&idx=1&sn=6e09abb32392e015911be3a1d7f066e5&source=41#wechat_redirect
一、竞品调研

当前的一些开源方案,这些存储方案里面可以分为两种:
- 一种是可以自定对象名称的;
- 另外一种是系统自动生成对象名称。
我们的对象名是自己生成的,里面包含了业务逻辑。
1、像 FS 就是国内大佬开源的一个分支存储,但是因为不能自定义文件名所以不合适。
2、还有像领英的 Ambry、MogileFS 其实都不能自定对象名的,所以是不合适的。
3、LeoFS 对我们来说不是很可控,所以不合适。
4、TFS 是淘宝开源的,但是目前已经很少有人维护它并且也不是很活跃,所以当时就没有考虑。
5、ceph 是一个比较强大的分布式存储,但是它整个系统非常复杂需要大量的人力进行维护,对我们的产品不是很符合,所以暂时不考虑。
二、初识MinIO
1、MinIO的架构
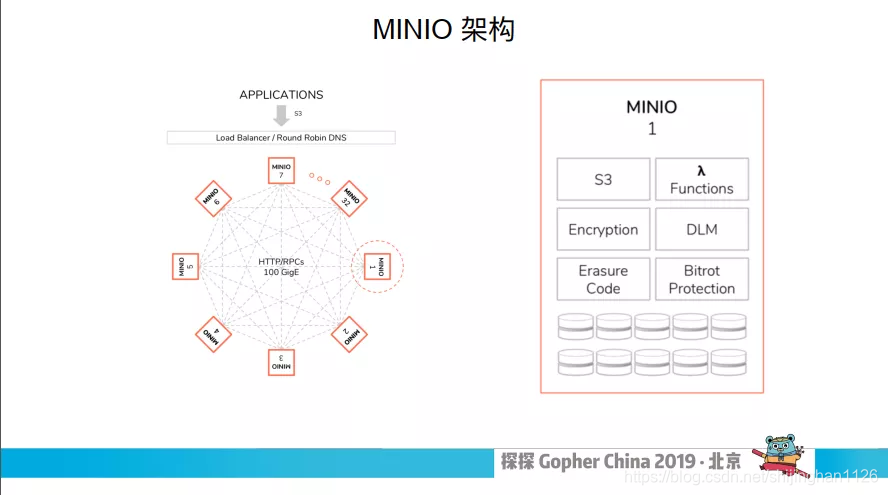
左边是 MINIO 集群的示意图,整个集群是由多个角色完全相同的节点所组成的。因为没有特殊的节点,所以任何节点宕机都不会影响整个集群节点之间的通信。
通过 rest 跟 RPC 去通信的,主要是实现分布式的锁跟文件的一些操作。
右边这张图是单个节点的示意图,每个节点都单独对外提供兼容 S3 的服务。
2、MinIO概念介绍:Drive和Set
- Drive:可以理解为一块磁盘
- Set:一组Drive的集合
- 一个对象存储在一个Set上
- 一个集群划分为多个Set
- 一个Set包含的Drive数量是固定的
- 默认由系统根据集群规模自动计算得出
- MINIO_ERASURE_SET_DRIVE_COUNT
- 一个SET中的Drive尽可能分布在不同的节点上
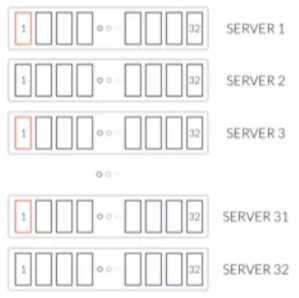
上图中,每一行是一个机器节点,这里有32个集群,每个节点里有一个小方块,我们称之为Drive,Drive可简单地理解为磁盘。一个节点有32个Drive,相当于32个磁盘。
Set是另外的概念,Set是一组Drive的集合,所有红色标识的Drive组成了一个Set。
一个对象最终是存储在一个Set里面的。
3、MinIO核心流程
3.1、数据编码
Erasure Code:冗余编码
- 将一个对象编码成若干个数据块和校验块
- Reed-Solomon算法
- 低冗余、高可靠
MinIO的编码方式,我们简称为Erasure Code码,是通过算法还原数据的方法。MinIO使用Reed-Solomon算法,该算法把对象编码成若干个数据块和校验块。
为了表述方便,把数据库和校验块统称为编码块,之后我们可以通过编码块的一部分就能还原出整个对象。
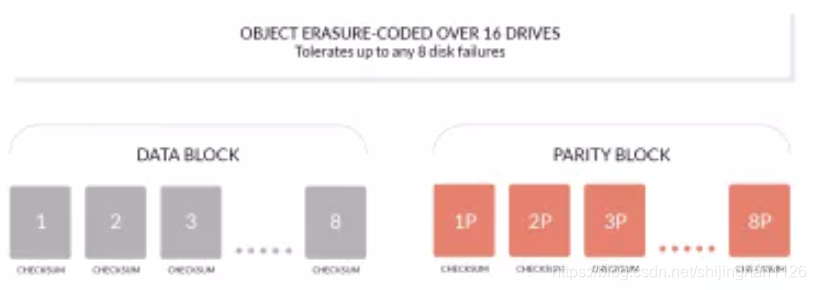
如上图,如我们所知,一个对象存储在一个Set上面,这个Set包含16个Drive,其中灰色的一半是数据库,橙色的一半是校验块,这种方式最多能忍受一半的编码丢失或损坏。所有编码块的大小是原对象的2倍,跟传统多副本存储方案相比,他只冗余存了一份,但可靠性更高。

接下来讲Bit Rot Protection,直译就是腐烂。它只物理设备上的一些文件细微的损坏,还没有被操作系统所硬件所察觉,但是他已经损坏了。
Bit Rot Protection:
- HighwayHash
MinIO把之前的编码块进行 HighwayHash 编码,最后要校验这个编码,以确保每个编码是正确的。
基于 Erasure Code 和 Bit Rot Protection 这两个特性,所以MinIO的数据可靠性做的高。
另外,MinIO提供了一个管理工具,可以对所有编码块进行校验,如果发现编码块有问题,再去修复它。
3.2、存储形式

上图直观地展示了每个节点上的数据存放形式。所有对象的编码块和meta信息,最终是以目录和文件的形式,存储在文件系统上的。
比如My Bucket就是在所有节点的顶级目录创建了对应的目录叫My Bucket。然后当我们上传一个对象的时候,就会在这个对象所对应的Set上面创建一个目录叫My Object,之后把所有编码块的数据跟meta信息都保存在此目录下面,这就是MinIO的真实存储数据的方式。
meta数据是json文件,编码块是part.1文件。黑色的右图是meta信息示例图,里面除了包含正常的meta信息外,还包括了怎样做ec编码,以便之后可以解码出来。
3.3、上传和下载流程
1、上传流程:
1)先根据对象名去做一个Hash,计算出对应的Set,然后来创建临时目录。创建临时目录的目的是为了确保数据强一致性,所以中间数据都会被写入到这个临时目录里(直到所有数据写完后,再统一把目录写入到最终的路径上)
2)接下来读数据编码,每次最多读10M的数据处理,然后做编码,再被写入到磁盘上,循环的过程就是把数据保存下来。
3)数据保存完后,再写meta信息。
4)然后挪到最终的位置上,删除临时目录。
2、读取流程:
1)先根据对象名做Hash,找到对象对应的Set
2)然后去读取meta信息,通过meta信息来获得编码的方式,然后去解码。它是以10M数据做EC编码,读的时候也是逐个part解析,每个part给他做解码,然后写入到一个io write里面。
备注:我们刚刚说了,做EC码时,只要一半的编码块就能还原整个对象,所以读meta时读了N份,但是读数据时只要读N/2就可以了。
四、部署和扩容
1、如何部署
#启动一个12个节点的MinIO集群,每个节点有12个Drive
minio server http://10.3.1.{
1...12}/data/{
1...12}
MinIO的部署默认不需要配置文件,几秒钟就可以把集群搭建起来,把简洁做到了极致。
2、MinIO压测
可采用 cosBench 工具做压测,cosBench是专门对对象存储做压测的工具。
在12个节点,每个节点12个盘,混合读写64KB。
结果是:
1、读请求:4千QPS,响应的平均延迟是35毫秒;
2、写请求:900 QPS时,平均响应时间是45毫秒。
五、MinIO的局限
局限1、搭建集群后,不允许扩容
MinIO一旦集群搭建成功后,就不可以更改集群节点数。因为存在在MinIO的对象到底存储在哪个Set,是通过名字做Hash去找的,一旦节点数变了落点就错乱了。
局限2、大集群最大节点数为32
MinIO实现了一个峰值锁叫DSync。它在节点数量少时,性能非常高;但节点数量过多时,性能就下降了。功能实现的最大节点就是32,所以导致MinIO单个集群的最大节点数也是32。
官方回复是,他们十年做GlusterFS的经验看,一个超大的集群是难以维护的,尤其是宕机之后的恢复时间也特别长,所以他们在做MinIO的时候一个核心设计理念就是简单,易于维护。
扩容方案
1、可同时向多个集群写入
2、当集群容量达到阈值,从写集群中剔除,变成只读
3、读取的时候,根据编码到文件名上的集群信息,从而路由到正确的集群。
MinIO本身提供一个叫联合模式的方式来组建集群,但是要额外引入其他依赖。可以考虑在LB层根据其请求里面的一些header信息做流量转发。
当配置多个集群的时候,可以先从配置中获取可用的集群,再从LB上根据请求的header信息,可控制向哪个集群写。当某个集群的容量达到阈值时,可以从配置中剔除该集群,把他变成只读集群。读取的时候把集群ID或信息码编码到文件名上去,这样可以通过解析文件名就能获取到对应的集群。
六、关于IO
IO有Buffered IO 和 Direct IO:
- buffered IO:在读写的时候回经过一个page Cache
- Direct IO:是绕过page Cache,直接对磁盘操作,所以性能会差些。
再回顾下MinIO的写入流程:MinIO数据最终的形式是写入文件系统的文件,也就是随机写的。随机写的性能肯定不如顺序写。
其次,EC编码在低冗余情况下是高可靠的,但同时也让他写入数量变多了,基本上一个对象写入需要做2N次操作,其实N次是数据的操作,N是meta的操作。基于上述原理,可总结出下述优化方案:
优化方案1、小文件合并成大文件
小文件合并成大文件,只需要把底层文件的部分稍微改一下,把原来随机写的小文件改成顺序写的大文件,这样就可以利用page cache来提供磁盘的能力。
具体实现:预先打开一个文件,分配一个固定的空间,目的是保证文件在磁盘上真是存储的数据是连续的。当写文件的时候,就给加锁,保证数据写入,因为这些原因,小文件的索引需要保存下来,所以我们引入了一个levelDB像大文件的ID和size的一些东西,之所以采用level DB是因为他的性能非常好。
接下来看MinIO的读流程:它主要发生在IO的地方有两个:一个是meta信息,然后再读data的时候,至少从N/2个节点上读取。每一次读取meta或者data的时候包括两部分:第一个从levelDB中读取索引,从大文件中读取对应的数据。
然后我们针对这个做了一个优化方案,我们把meta信息,因为meta信息没多少,我们把他压缩到level DB里,直接读就行了,不用读索引了。
再回顾下MinIO的读流程:
1、从N个节点上读取meta信息
2、至少从N/2个几点上读取data
3、每一次读取的时间包括两部分:
- 从level DB读取索引
- 从大文件中读取对应的数据
4、并发读的最终时间取决于最长的一个
优化方案总结
1、将meta信息压缩后,直接存入level DB,减少一组IO
2、将level DB存在性能更高的SSD
3、降低单个Set的Drive数量