转载自:https://blog.csdn.net/lidahuilidahui/article/details/107005979
08-SNAP的命令行处理工具gpt及其批处理(Sentinel-1和Sentinel-2为例)
导语
如果我告诉你,SNAP中仅需一行代码即可以完成某地整年Sentinel卫星影像的预处理,而仅仅需要数小时而已,你是否该对SNAP该“刮目相看”了?
前言
用过SNAP GUI(图形用户界面)界面的同学,常常抱怨SNAP显示慢、处理速度慢、没有GPU加速功能等,这些在SNAP官方论坛中已经有许多用户提及到,SNAP官方开发者早开始着手解决这些问题。其中主要的原因是SNAP的源码是使用Java写的,相对于C/C++等编译语言来说,正常情况下在进行大数据量运算时速度明显慢一些,另一个问题就是java虚拟机在SNAP经常不能及时释放内存,导致大数据量的处理或报错或者很慢。当然,使用Java有明显的一个好处,那就是跨平台(windows、linux、unix、Mac系统)运行,开发很大的便利。显示慢的一个原因,我觉得应该是SNAP保存影像数据时是不像ENVI、ArcGIS没有创建相应的影像金字塔辅助文件,另一方面如果创建金字塔,又会耗费不少硬盘空间,总之各有利弊。
不过,也不是说没有办法加快SNAP的运行速度。硬件上,大运行内存明显能加速加速大数据量影像的处理,而固态硬盘则明显改善影像数据的读写速度,这些都是常规的硬件加速方法,但是需要花费一定的费用;软件上,使用SNAP的流程图或者命令行工具gpt可以明显加速数据的处理速度,这是我一直提倡在SNAP处理Sentinel卫星影像的方式,原因是其避免了大量中间过程的数据读写过程。当然,gpt工具已经是编译后二进制程序(像C/C++等编译后的.exe可执行程序一样),而非Java虚拟机识别jar程序(Java字节码程序),这对运算速度又有一定的提升。当然,SNAP的Python包snappy或者利用Java源码结合多进程、多线程技术、分块技术并行计算也是一种加速的办法。
这次,探讨的是SNAP的命令行工具gpt,接下来,你可以看到使用gpt工具给数据处理速度带来质的飞跃,并且,这是在仅需要少量(一句或者几句)的代码即可以高效地完成数据处理。这里,要感谢SNAP官方开发者在命令行工具的出色设计,使得我们可以非常简单地实现Sentinel等卫星的快速预处理以及常规的遥感处理操作。
尽管本文是以Windows10系统为例的,但是在linux,mac系统使用SNAP的gpt工具命令是类似的。
(博主最近购买了两个16G内存条(每个约400元),将运行内存升级到了32G(之前是16G),有条件可以结合电脑的实际情况买个内存条升级一下,在SNAP中的体验应该会有很大提升。不过,除了后文的批量处理,小内存的电脑(4G或8G)可能会出现内存不足的报错,前面的一些简单gpt命令行操作应该是毫无压力。本文,除了最后的Sentinel-1 IWGRDH批量处理操作要求内存高(应该需要16G内存)外,其余的操作应该8G内存就可以。不一定要像博主,非要达到32G。不过,大的运行内存,相对而言,处理大数据会方便许多!另外,应该确保C盘至少有20G的空间,以便存放SNAP或者gpt运行时产生的大量临时文件)
gpt命令行工具简介
尽管使用SNAP GUI界面可以不编写代码,通过鼠标的点击即可以完成众多处理操作,但是,一旦你熟悉了SNAP的gpt工具,处理起来Sentinel卫星数据就会非常得心应手,就像“切瓜炒菜”那样自然、简单。一些没有命令行编程,可能黑漆漆的界面,可能感到恐惧,其实,早期的电脑就是只有这样的命令行界面(包括现在linux、mac系统仍保留这样设计),这只过回到比较原始的编程界面上,和普通的IDE界面编写程序基本是一样的,除了语法有点区别。实际上,启动GUI界面,占用不少的系统资源,在资源有限的系统上是会拖慢程序的运行速度的。庆幸的是,我们只需要掌握少数的SNAP的gpt命令行工具命令即可以完成多数的处理了。好了,讲了那么多,究竟是不是这样,需要体验过才相信!
gpt命令行工具的位置
gpt命令行工具(gpt.exe)位于SNAP安装路径下snap文件夹下的bin文件夹下(和snap64.exe在同一文件夹下),如下是博主的安装路径:E:\SNAP\install_path\snap\bin
如下图: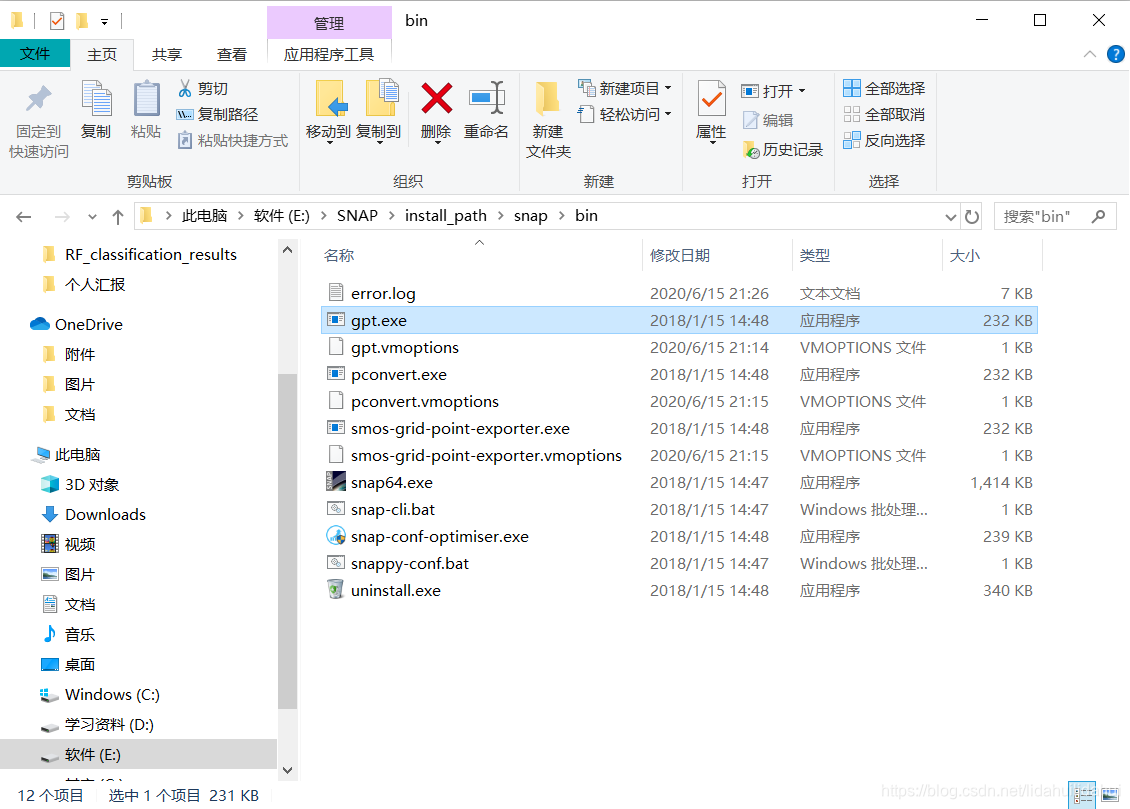
如果你看不到后缀名.exe,你可能需要设置一下显示文件扩展名以及隐藏的项目: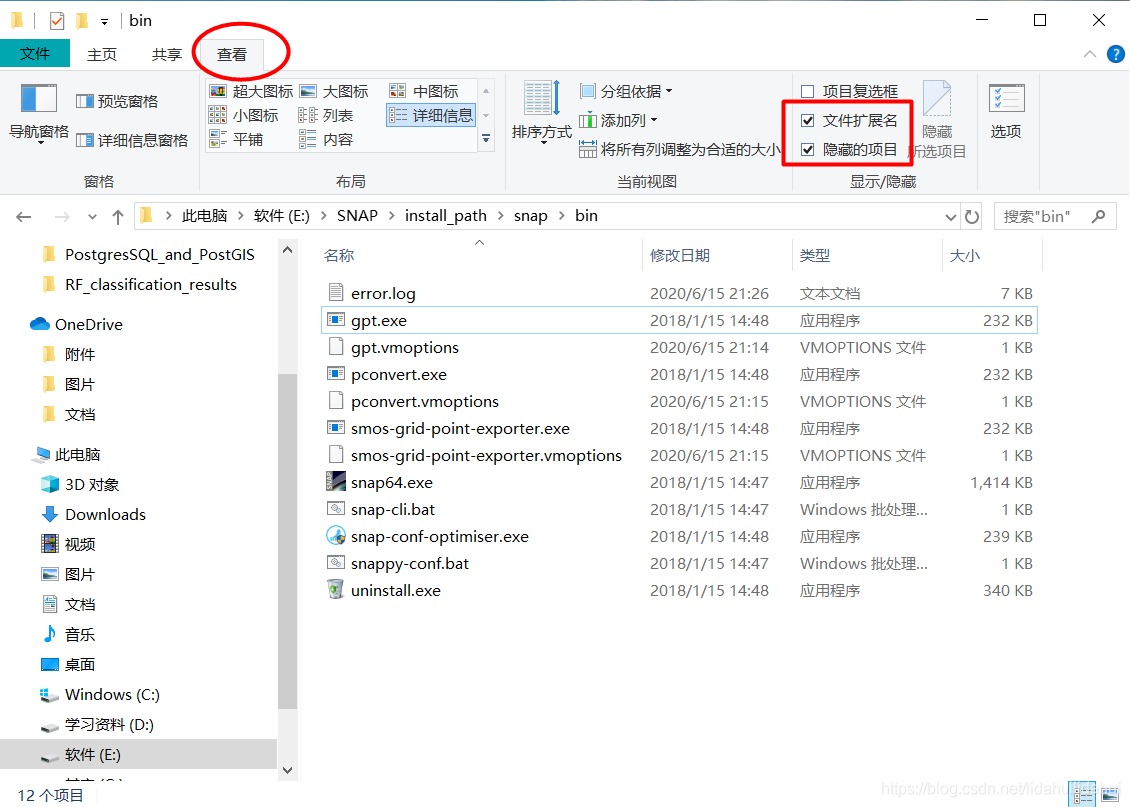
在上图中,你可以看到多个.exe程序(以及对应的配置文件.vmoptions),其中snap64.exe是启动SNAP GUI界面的主程序, pconvert.exe是一个数据转换程序。如果你在命令行中输入:snap64,你会发现SNAP GUI见面启动了(实际上,SNAP桌面快捷方式绑定的正是这个程序)。
在当前文件路径下启动命令行界面: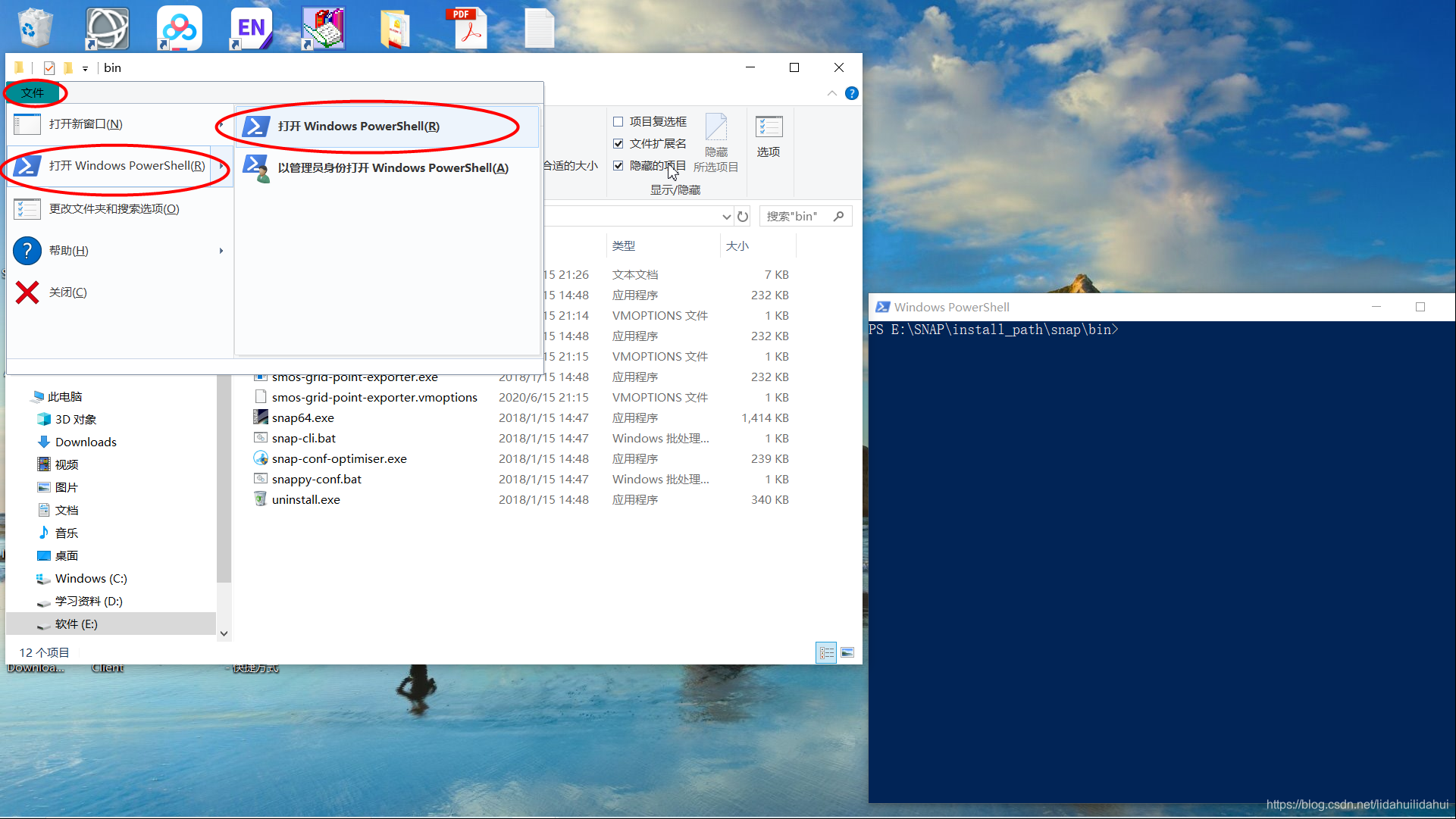
或者按shift键+鼠标右键单击:
在命令行界面输入:snap64(或者snap64.exe),你会发现SNAP的GUI界面打开了。
为了避免每次调用gpt不用在SNAP安装路径下启动命令行界面,建议你将SNAP的安装路径下snap文件夹下的bin文件夹添加用户环境变量中: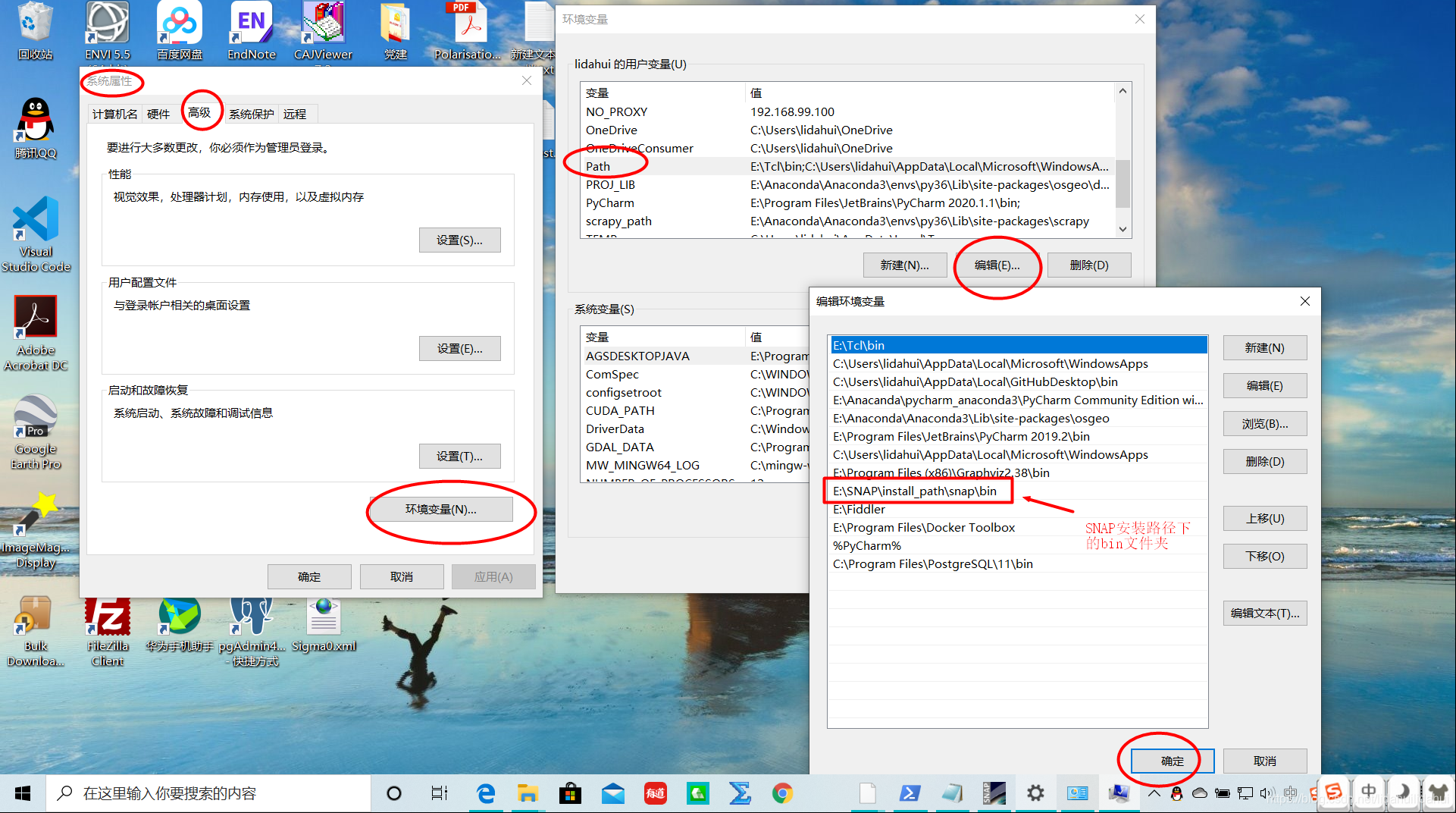
gpt命令行语法参数
在打开的命令行界面输入:
gpt -h
- 1
(可能需要等待数十秒,因为这个命令行包括的操作和命令太多了,稍后会显示一大片的英文文档说明,鼠标往前拉,先看下前面的参数。绝大数情况下,我们不要记住那么多得参数,只需要在用到的时候找到其即可)
可以看到其语法说明(Usage),尖括号<>表示必须要填写的参数,中括号[]表示可选的参数,竖线 |: 用于分隔多个互斥参数,含义为“或”,使用时只能选择一个。如果你想看下命令行常见语法格式说明符可以看下这篇博客命令行语法格式及特殊字符。
# <op>表示某一操作符,<graph-file>表示SNAP流程图文件(xml文件);见Arguments参数
# <options>表示可选参数,-h, -e, -f等等,见Options选项
# <source-file-1>表示源数据文件,当然后面还可以多个源数据文件
gpt <op>|<graph-file> [options] [<source-file-1> <source-file-2> ...]
- 1
- 2
- 3
- 4
(#号表示的是注释说明)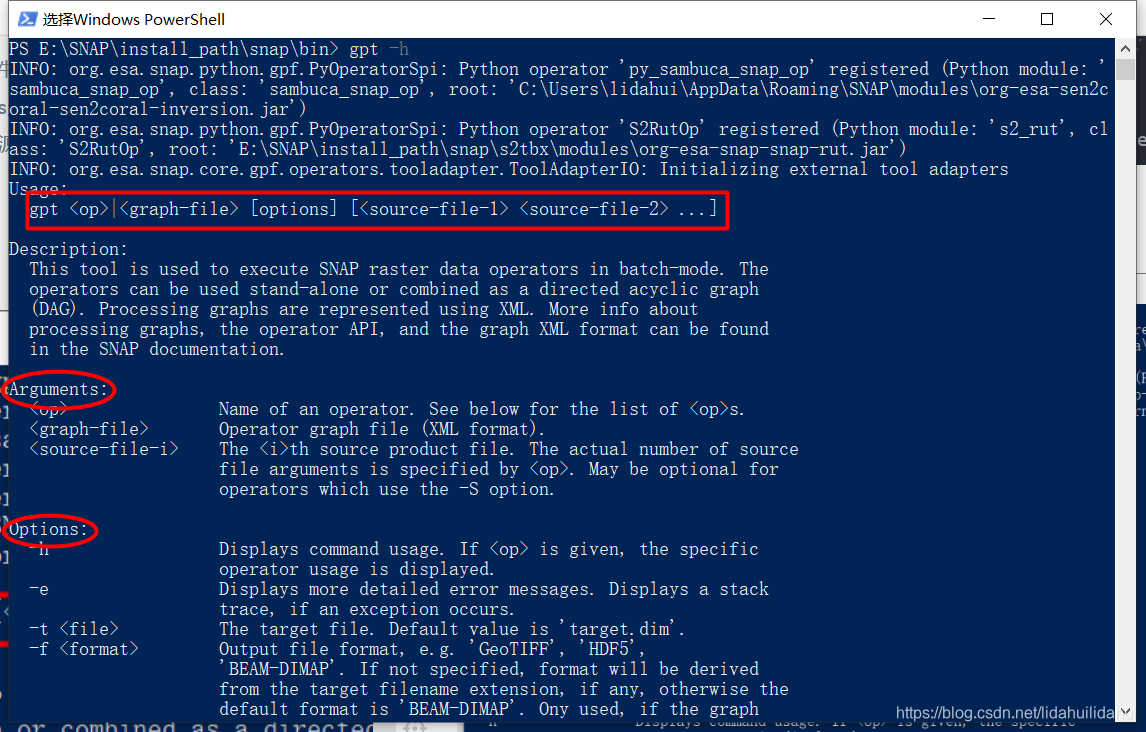
有几个Options参数是比较重要的(你可能暂时看不懂-S和-P参数的说明,不过,不重要,带着疑问继续往下看,后面展示其用法时,再讨论其表示的意思):
- -h: 显示帮助命令;
- -t <file>: 表示输出文件名(用file表示),如果没有这个参数,默认输出的文件名是target.dim;
- -f <format>:表示输出的格式(用format表示),默认的是“BEAM-DIMAP”,当然你也可以输入“GeoTIFF”, "ENVI"等格式输出;
- -S<source>=<file> :这是由xml文件定义的源文件参数变量${<source>}指示(为什么是-S?答案是简写,S表示source的第一个字母)。
- -P<name>=<value>:这个参数和-S<source>=<value>是类似的,但是更加通用,可以在xml文件设置名称字值对变量(为什么是-P?答案也是简写,P表示parameters的第一个字母)。后面批处理是会展示其用法;
如果你继续往下拉,可以看到Opterators,其下均是SNAP支持的操作(按字母升序排列,A->Z):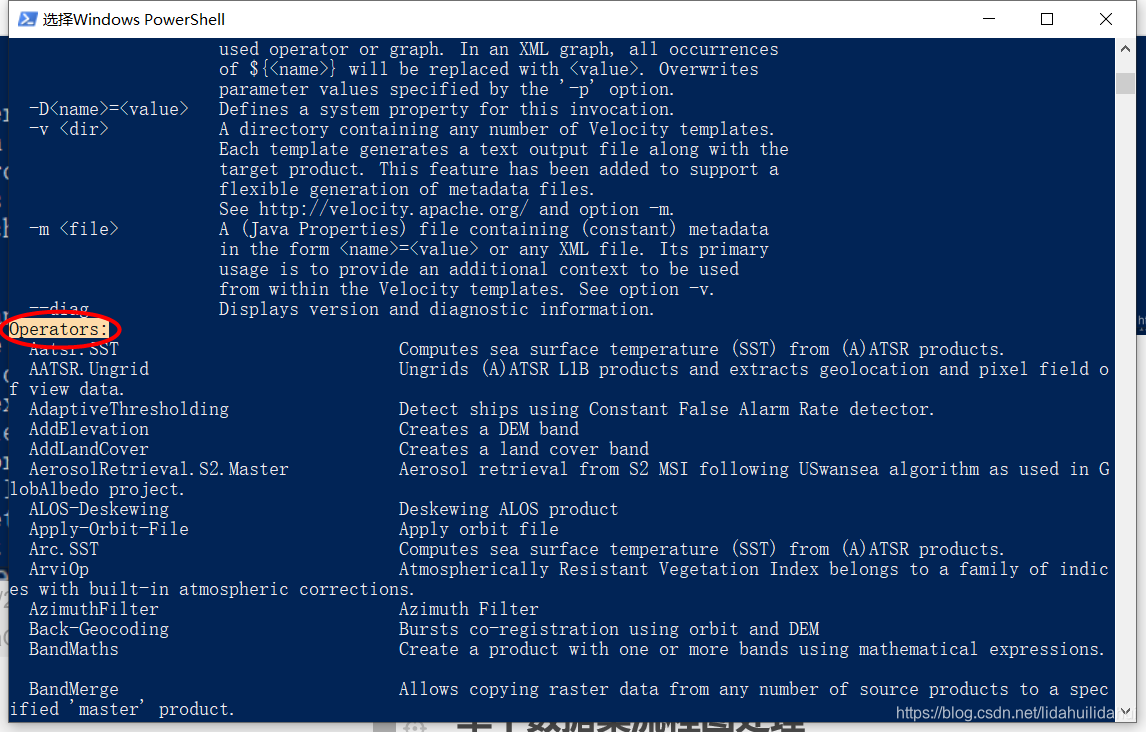
数据源
Sentinel-1数据
以覆盖上海市的sentinel-1 IW GRDH 产品数据(2019年6月-2020年5月)为例(源数据无需解压):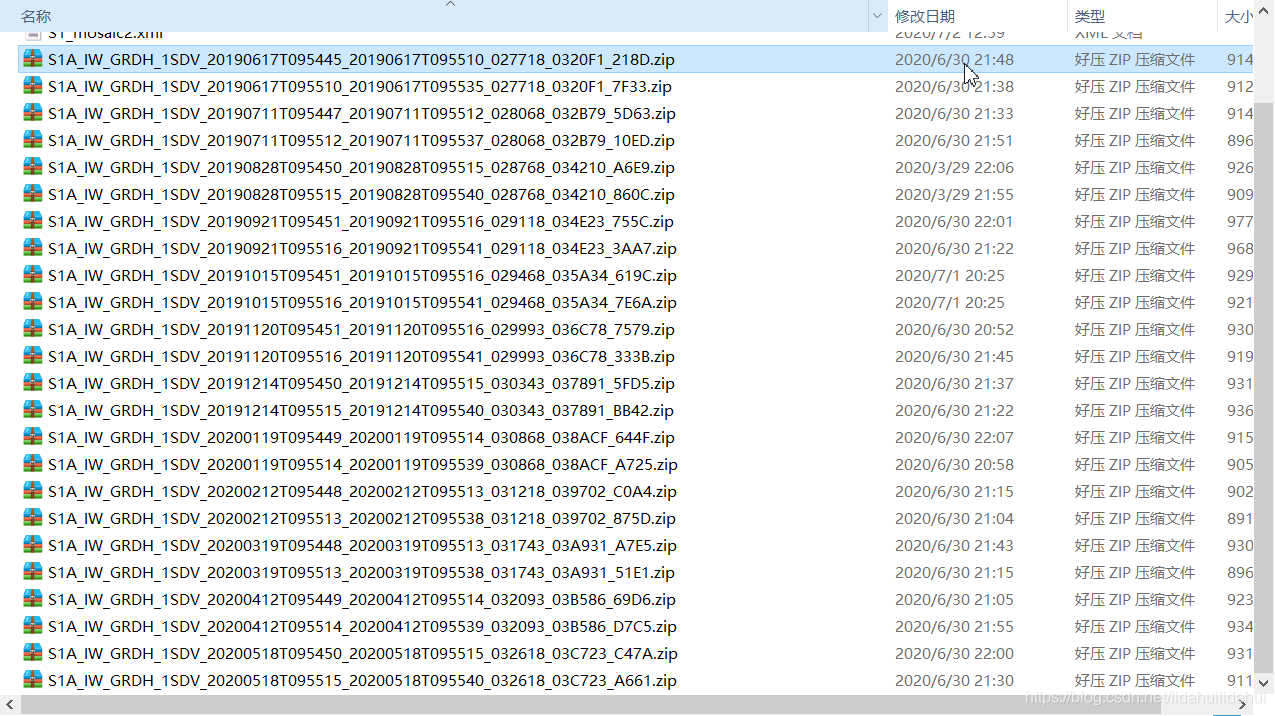
范围如下: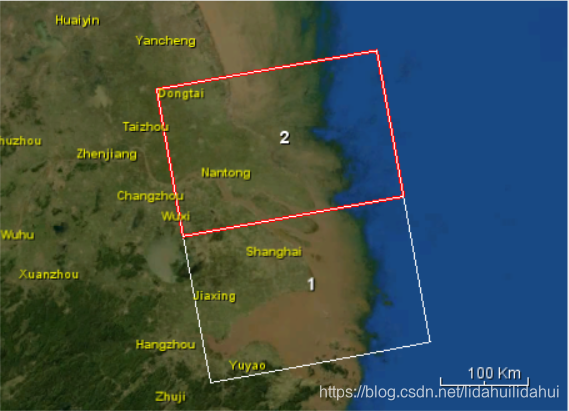
Sentinel-2数据
以覆盖位于山东省东营市的黄河三角洲区域为例,以下为其2019年1月-201912月的近似无云(云量少于5%)的Sentinel-2 L2A影像(源数据无需解压):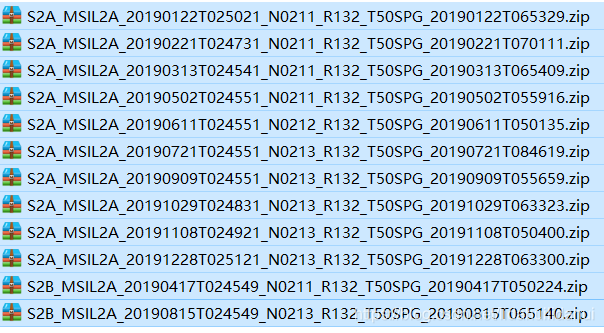
范围如下: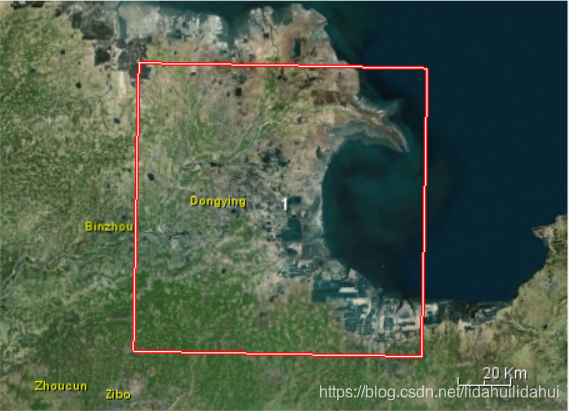
gpt实现单一操作
单个数据集单一操作处理
Sentinel-2 NDVI计算
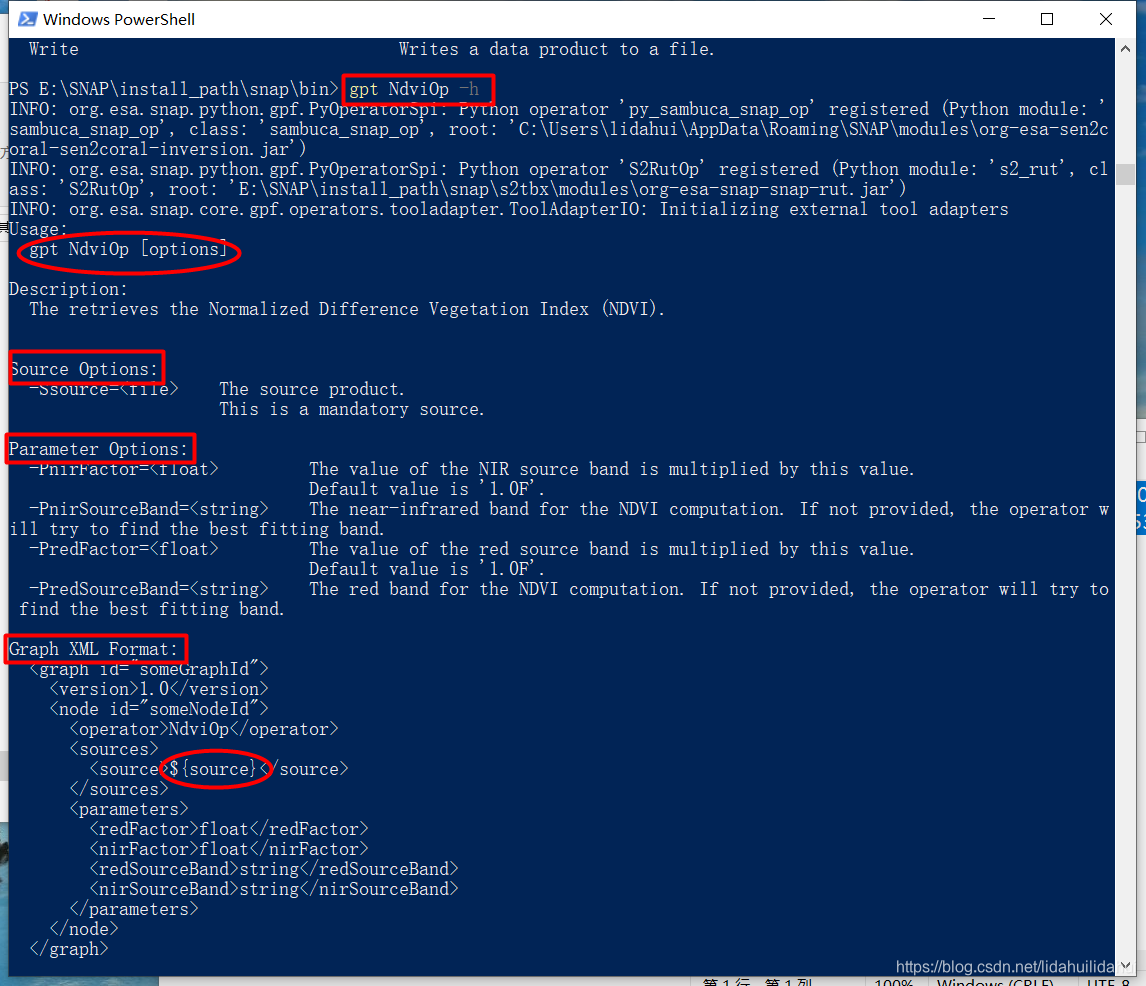
在上述的gpt命令行参数界面Operators的参数表中往下拉找到N字母开头的NdviOp操作,这就是我们要找的SNAP的NDVI计算命令行操作, 在命令行界面下,输入:gpt NdviOp -h, 可以查看该操作符命令参数的相关说明(gpt,NdviOp可以混写大小写,但带-的参数,需要严格区分大小写,例如这里-h)。
gpt NdviOp -h
- 1
可以看到如下的参数说明:
源文件参数 -Ssource=<file>,表示源数据,file用文件名代替,尖括号表示该参数是必须的,不可缺失,后面float,string的尖括号也表示相同的意思;
-PnirFactor=<float>,-PredFactor=<float> 分别表示近红外波段,红光波段的比例调节因子,在我们常用的NDVI计算其比例因子均为1,这里的默认值为1.0F(表示浮点数的1.0),通常我们不需要输入这个参数;
-PnirSourceBand=<string> , -PredSourceBand=<string> 分别表示近红外波段,红光波段,string表示波段名;
其后,还跟有一个Graph XML Format,显示该操作默认调用的xml文件内容, 这里你看到其中在<sources>节点中含有的${source},所以我们源文件用的参数是-Ssource=<file>。假如我用的xm文件中<sources>节点将${source}改为${input},这时我们转入源文件,则源文件参数用法变为变为-Sinput=<file>。这里,暂时该不了其默认的xml文件,暂时搁置着个改动一会先。
该操作的命令行见Usage:
# optional表示可选项参数,即上面带-的相关参数,如-Ssource等
gpt NdviOp [optional]
- 1
- 2
先简单展示一下,博主的源数据文件夹以及输出文件夹位置: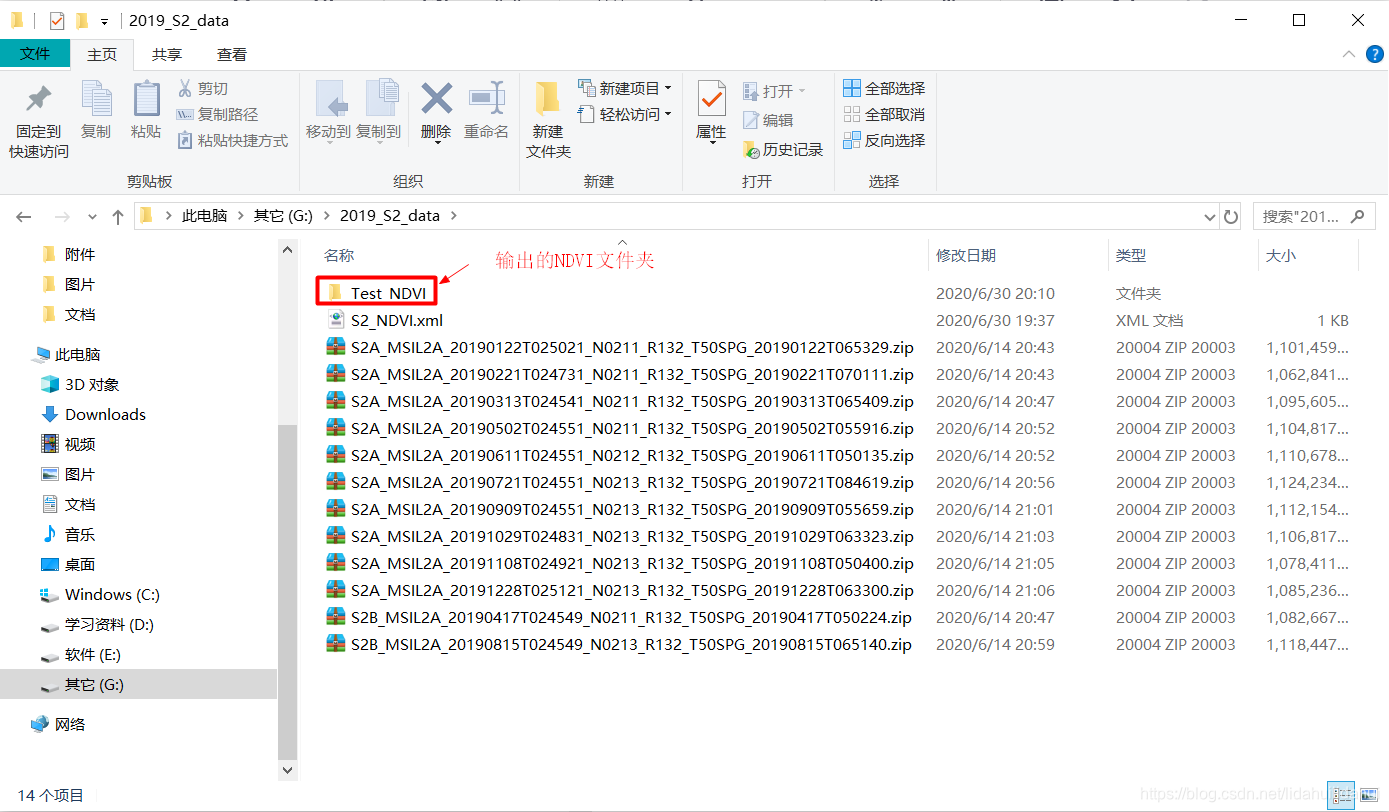
以第一景数据为例,即S2A_MSIL2A_20190122T025021_N0211_R132_T50SPG_20190122T065329.zip
好了,是时候展示其命令行用法(注意=两边不要有空格,-t参数是没有等号的,输入和保存的文件路径可能需要你手动修改一下,这里的输出文件名为S2A_MSIL2A_20190122T025021_N0211_R132_T50SPG_20190122T065329_ndvi.dim,加了后缀并且使用了标准的SNAP格式BEAM-DIMAP,如果后缀名改为.tif,默认是以“GeoTiff”格式输出,当然在命令行上,加上-f “GeoTIFF”)。
# 虽然是一句命令,但是添加路径后,显得很长。可以将最后一行命令复制到一个.txt文件中,
# 在.txt文本中也容易编辑命令。确认命令无误后,
# 打开命令行界面(在命令行界面中点击鼠标右键则可以粘贴拷贝的文本了)
# -Ssource表示源文件的绝对路径(尽管也可以使用相对路径,但是绝对路径安全一些),
# 为什么在路径中添加了双引号,这样可以避免路径中出现空格导致路径被分隔开识别
# -PnirSourceBand表示近红外波段名,Sentinel-2对应的近红外波段名为B8
# -PredSourceBand表示红光波段名,Sentinel-2对应的红光波段名为B4,
# B8与B4分辨率均为10m,且栅格影像大小一样,所以可以直接进行ndvi的计算
# -t 表示输出的文件名,路径也是添加了双引号,注意博主加了后缀_ndvi.dim
gpt NdviOp -Ssource="G:\2019_S2_data\S2A_MSIL2A_20190122T025021_N0211_R132_T50SPG_20190122T065329.zip" -PnirSourceBand="B8" -PredSourceBand="B4" -t "G:\2019_S2_data\Test_NDVI\S2A_MSIL2A_20190122T025021_N0211_R132_T50SPG_20190122T065329_ndvi.dim"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(寻找命令需要耗费几十秒的时间,执行计算ndvi的命令大概需要两分钟的时间,速度还算可以)
由于博主已经将SNAP安装路径下的bin文件夹(gpt.exe的父路径)添加到了环境变量中,所以我可以在任意一个文件夹打开命令行窗口,这里是在输入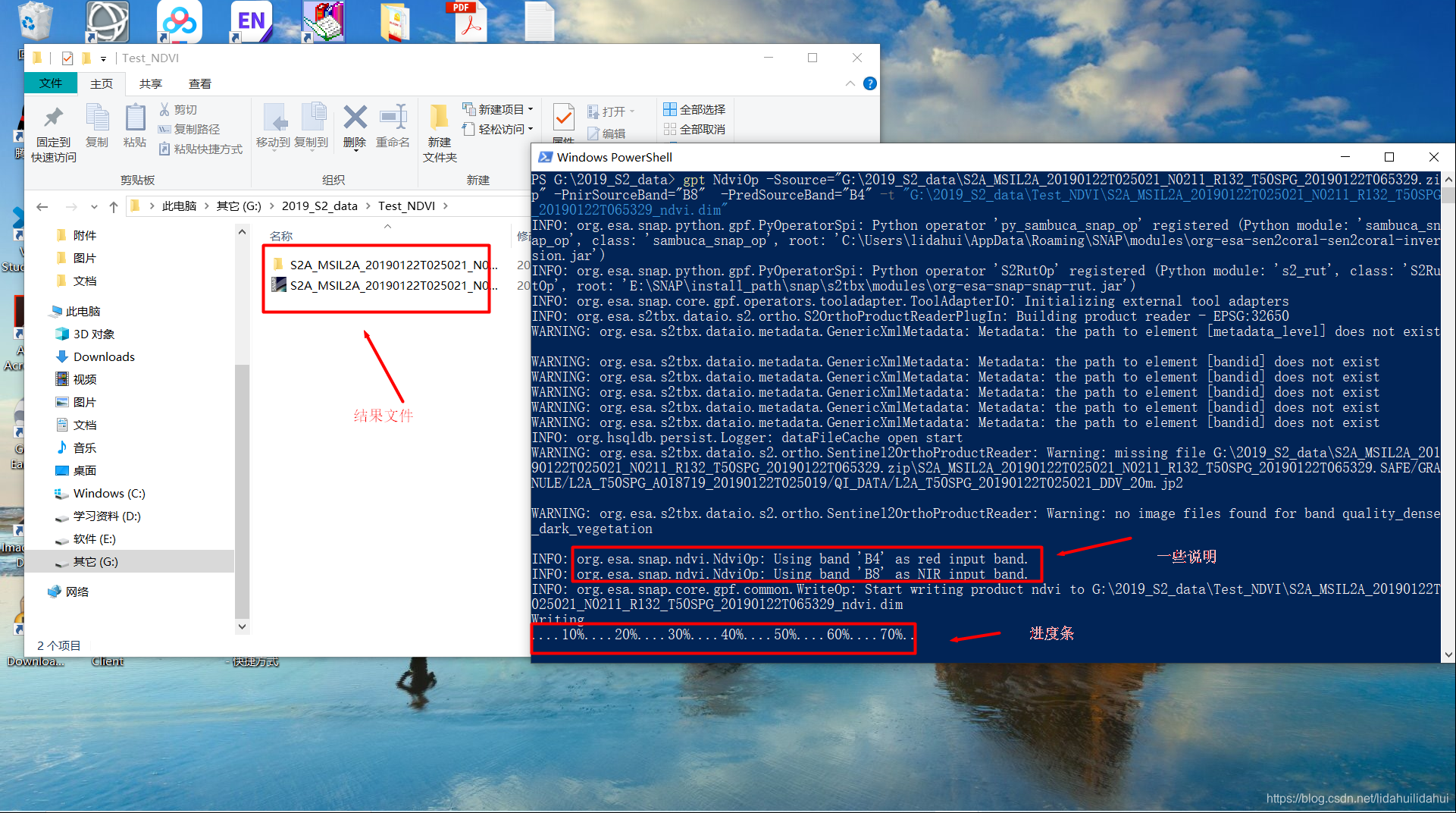
我们将原始数据(.zip),以及生成对应的的NDVI导入SNAP查看效果: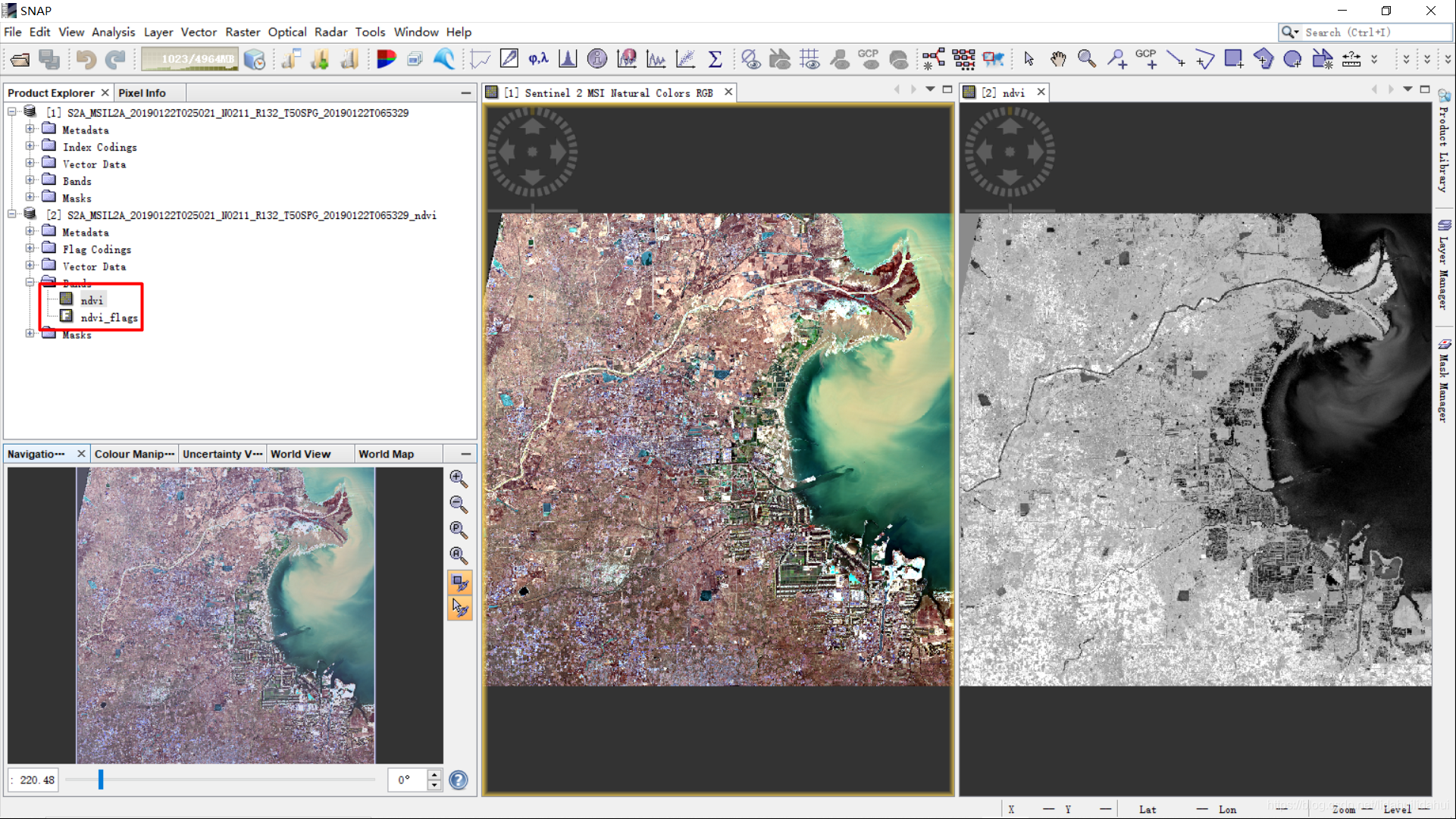
perfect! 你可以在SNAP的命令行界面中调用NDVI工具来计算,结果应该是一样的。
(当然,仅仅处理单个数据集和单个操作并没有展现出gpt的优势所在,甚至,你还需要记录那么多的命令行参数,展现其威力的地方更多地体现在批处理上,保持一点耐心,继续往下看)
Sentinel-1 轨道校正
其实使用辐射定标操作演示更好的,但是轨道校正通常是SNAP中SAR数据处理的第一步,也无妨,这里仅仅演示Sentinel-1的gpt单一操作命令行处理。
同样地可以通过命令行命令:
gpt -h
- 1
找到轨道校正的操作符命令名称:Apply-Orbit-File(如果你熟悉SNAP的GUI界面是很容知道的)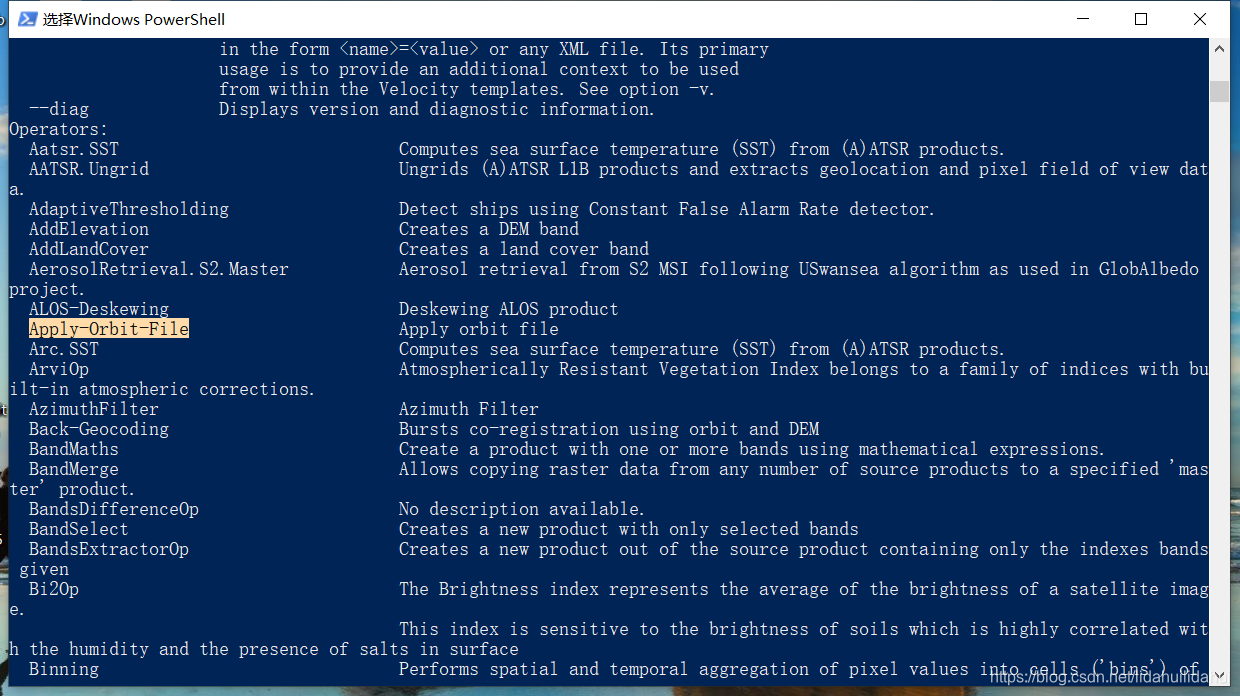
接下来查看该命令符的用法:
gpt Apply-Orbit-File -h
- 1
可以看到其用法和参数(注意到其中Parameter Options下的三个-Pxxx参数都有默认值,我们在使用命令行命令中可以不加以设置):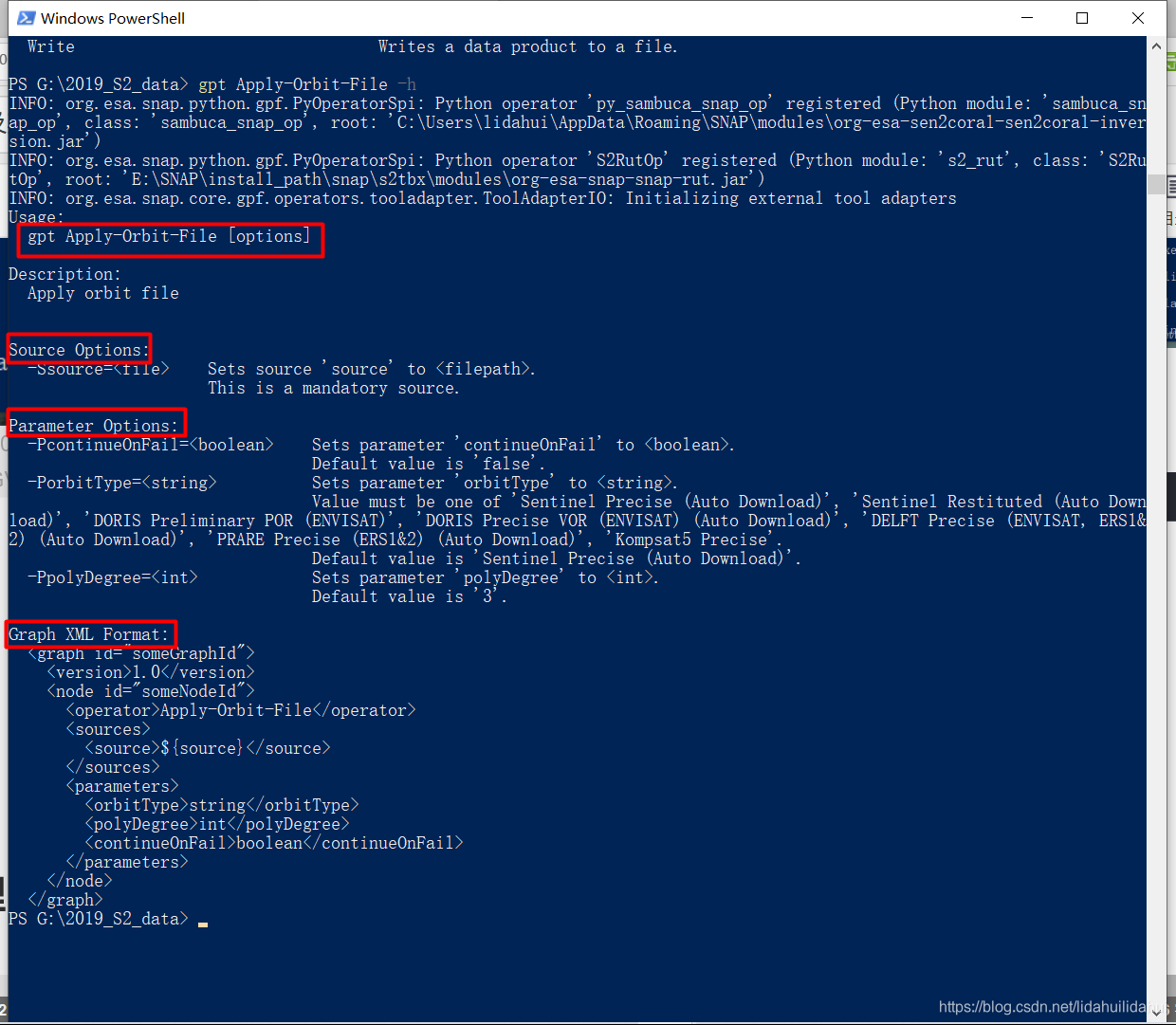
当然,其默认的参数设置和SNAP的GUI界面默认参数是一一对应(SNAP中,每一个GUI操作界面都可以查看其对应xml文件参数):
打开SNAP的GUI界面(可以导入已经Sentinel-1数据,或者不导入也无关系),点击Radar—>Apply Orbit File,可以打开该操作的GUI界面。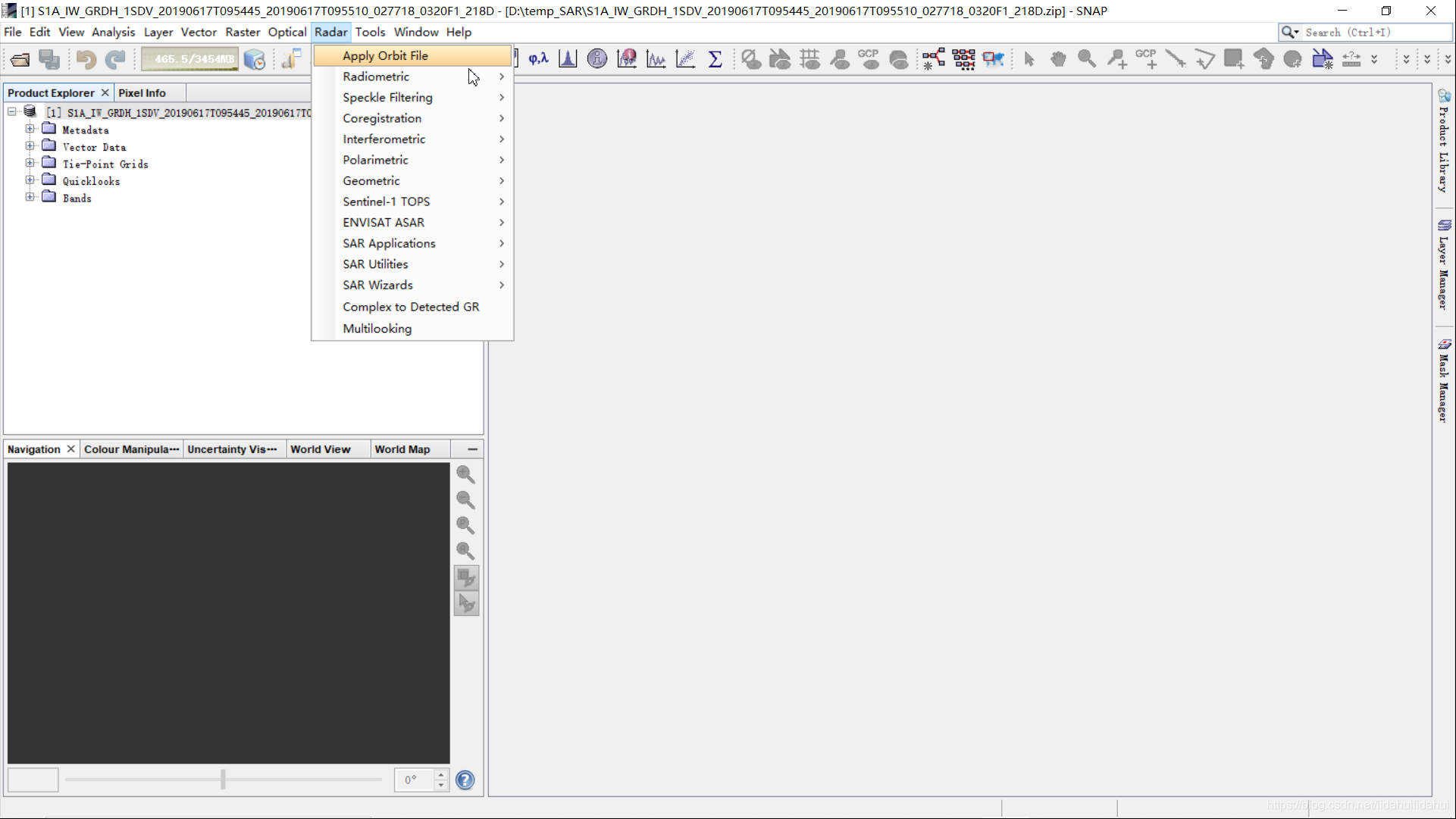
然后,点击File—>Display Parameters…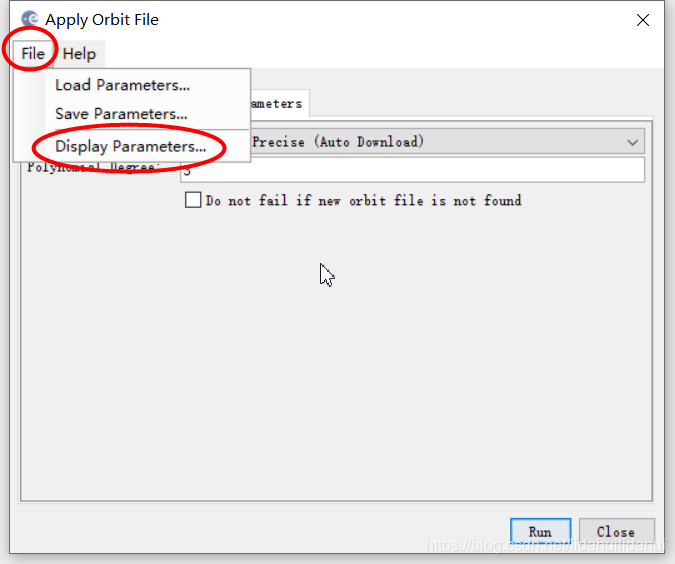
查看参数(可以和命令行Apply-Orbit-File操作大的参数对比一下,可见它们参数的默认值是相同的,参数名也是相同的,除了命令行参数中多带了-P字眼。前面提到,-P中P是parameters的首字母):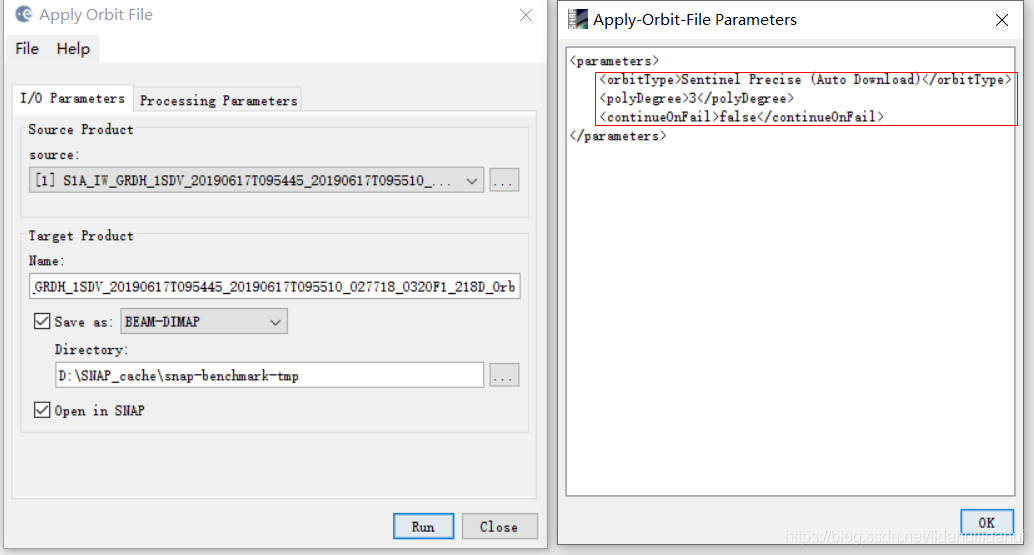
这里以该景Sentinel-1 IW GRDH数据为例:
S1A_IW_GRDH_1SDV_20190617T095445_20190617T095510_027718_0320F1_218D.zip
好了,是时候展示一下其用法了。由于我们使用默认参数,相对前一个计算NDVI的命令来说,这个要简单一些(注意=两边不要有空格,-t参数是没有等号的,输入和保存的文件路径可能需要你手动修改一下,这里的输出文件名为S1A_IW_GRDH_1SDV_20190617T095445_20190617T095510_027718_0320F1_218D_Ort.dim,加了后缀并且使用了标准的SNAP格式BEAM-DIMAP,如果后缀名改为.tif,默认是以“GeoTiff”格式输出,当然在命令行上,加上-f “GeoTIFF”)。
# 虽然是一句命令,但是添加路径后,显得很长。可以将最后一行命令复制到一个.txt文件中,
# 在.txt文本中也容易编辑命令。确认命令无误后,
# 打开命令行界面(在命令行界面中点击鼠标右键则可以粘贴拷贝的文本了)
# -Ssource表示源文件的绝对路径(尽管也可以使用相对路径,但是绝对路径安全一些),
# 为什么在路径中添加了双引号,这样可以避免路径中出现空格导致路径被分隔开识别
# -t 表示输出的文件名,路径也是添加了双引号,注意博主加入后缀_Orb.dim
gpt Apply-Orbit-File -Ssource="D:\temp_SAR\S1A_IW_GRDH_1SDV_20190617T095445_20190617T095510_027718_0320F1_218D.zip" -t "D:\temp_SAR\test_apply_orbit_file\S1A_IW_GRDH_1SDV_20190617T095445_20190617T095510_027718_0320F1_218D_Orb.dim"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果(大概一两分钟的时间):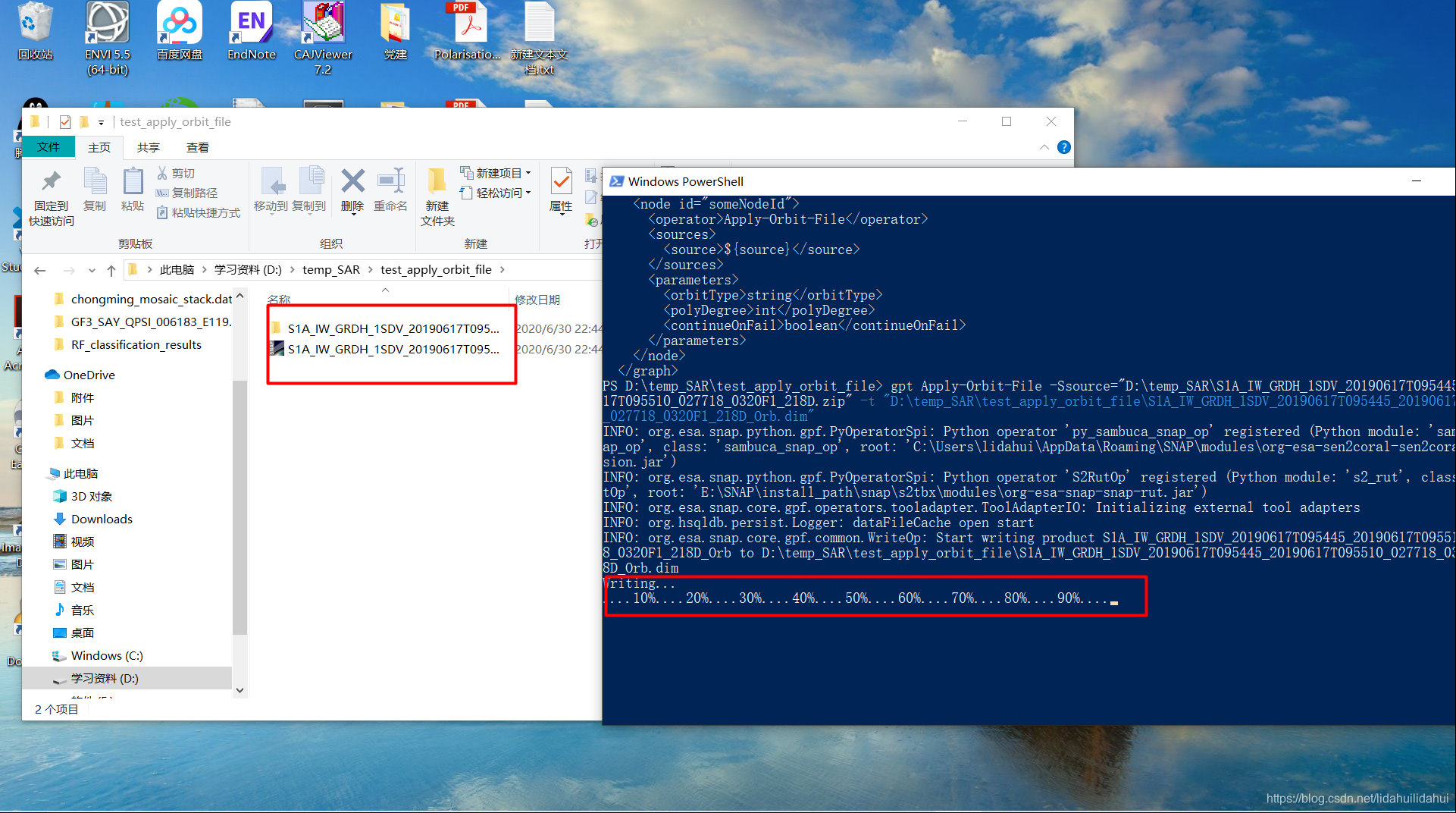
将原始数据和轨道校正后的数据导入看看结果正确与否: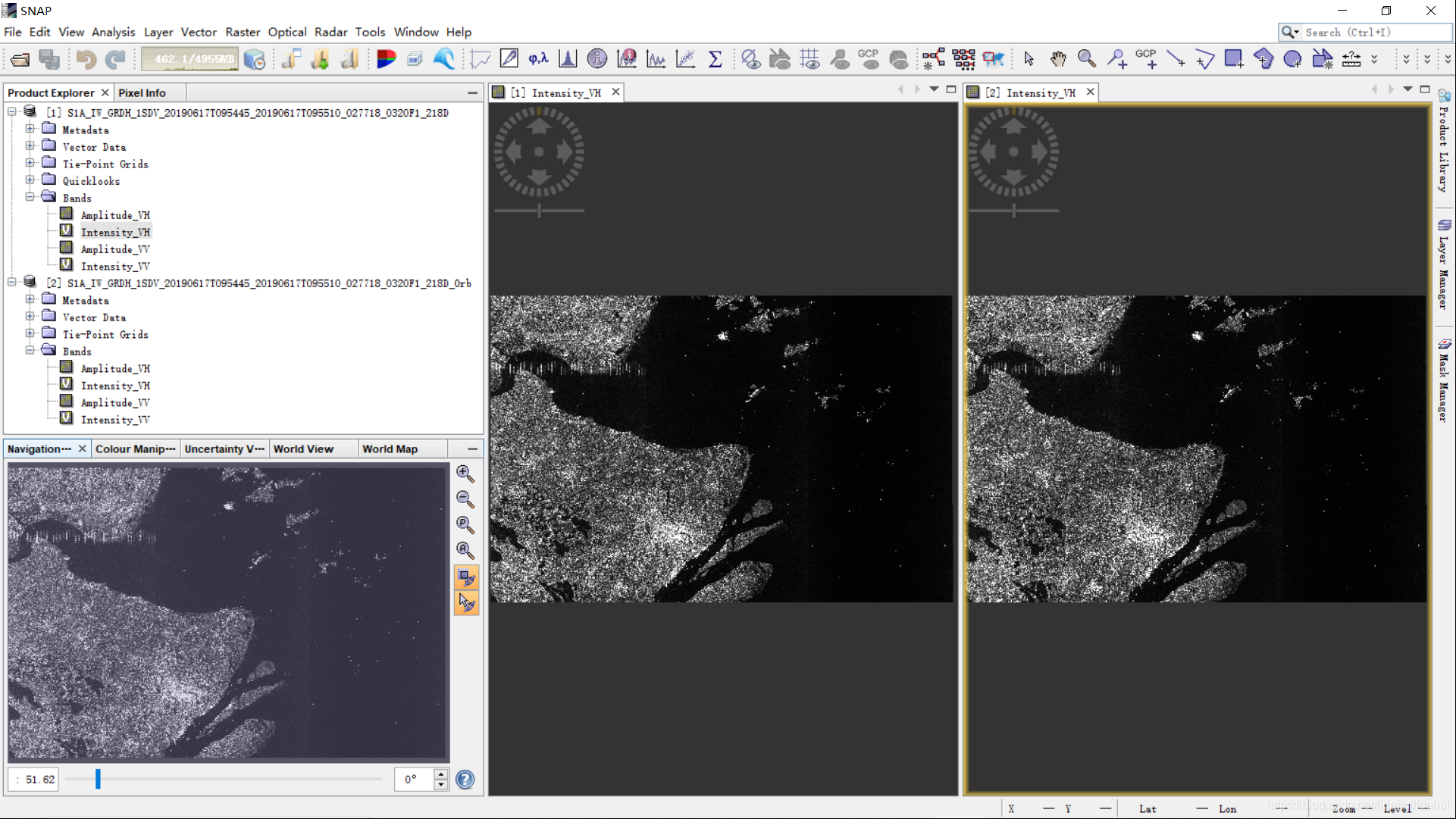 perfect!正确无误。好了,接着讲一下单一操作的批处理了。
perfect!正确无误。好了,接着讲一下单一操作的批处理了。
多个数据集批量单一操作处理
(批量处理时要确保你的硬盘有足够的存储空间,下载数据集最后单独放在一个文件夹下,不用使用中文路径)
Sentinel-2时序NDVI计算
如果你有某一地区的多景Sentinel-2影像数据,你应该很希望获得其时序NDVI曲线,这可能是植被、农作物等地物分类或监测常见的时序特征曲线,可能这是Sentinel-2多时相分析最常见的需求了。不过借助SNAP的gpt命令行工具,很容易实现这个需求。已经下载了2019年黄河三角洲每月的Sentinel-2 L2A影像,只需要在gpt命令行实现批量ndvi计算(执行NdviOp操作符)即可。
注意PowerShell(这是一个类似Linux终端的命令行,但是语法又不完全和linux)和windows 标准命令行命令不一样,下面的语法要在标准命令行代码性需要在标准命令行运行才可以。幸运的是很容易在PowerShell命令行窗口进入windows 标准命令行窗口, 只需要在PowerShell命令行窗口(该命令行带有PS的提示符)输入cmd即可:
cmd
- 1
博主的数据放在这个文件夹(G:\2019_S2_data)下, 输出目录为G:\2019_S2_data\Test_NDVI(尽管该目录下有上一次单一数据集的ndvi操作结果,但是批量不会有影响,默认是会覆盖该数据集,当然,你也可以手动删除它):
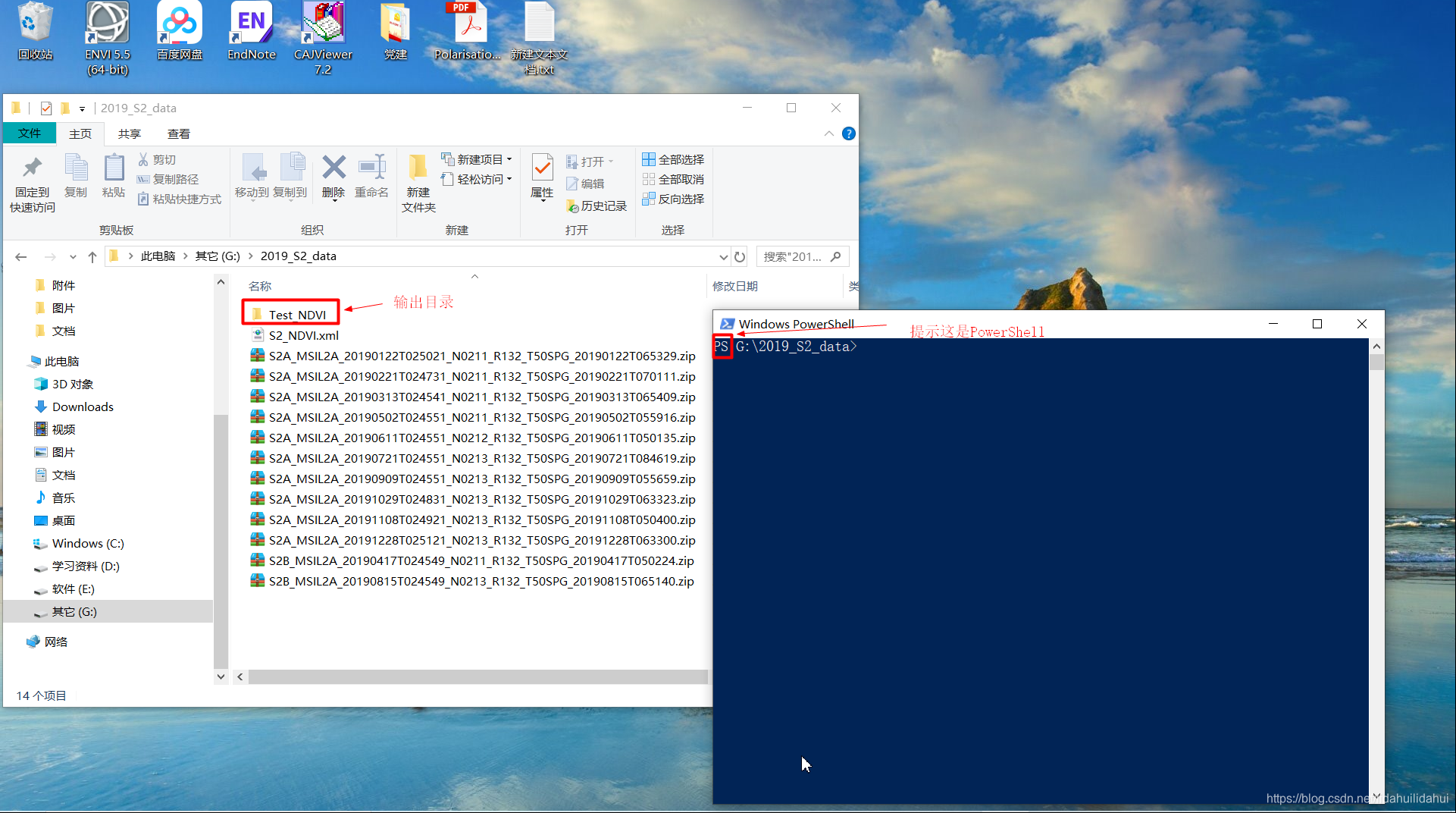
在输入文件目录启动PowerShell,然后输入cmd,切换到windows标准的命令行窗口: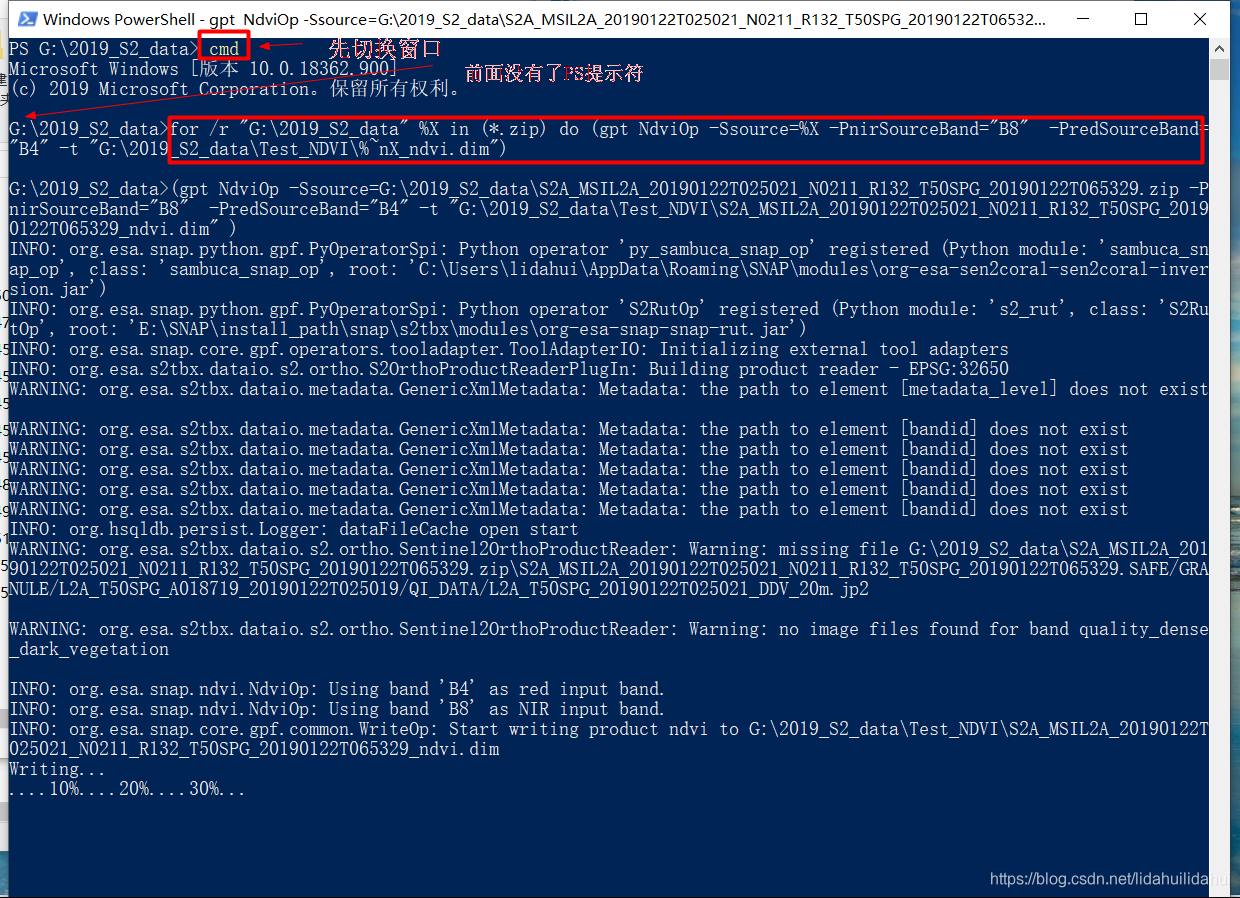
然后才输入下面最后一句命令(见上面的执行界面):
(如果你需要处理自己的数据集,只需修改对应的输入、输出目录路径即可)
# 虽然仍是一句命令,但是添加路径后,显得很长。可以将最后一行命令复制到一个.txt文件中,
# 在.txt文本中也容易编辑命令。确认命令无误后,
# 打开命令行界面(在命令行界面中点击鼠标右键则可以粘贴拷贝的文本了)
# /r "G:\2019_S2_data" 表示在该路径下迭代文件,这是博主存放源数据的目录
# %X是迭代变量,这里用于表示迭代的zip文件绝对路径
# *.zip 是正则表达式语法,这里是后缀含有.zip的文件
# -Ssource=%X 表示gpt的源文件
# -t "G:\2019_S2_data\Test_NDVI\%~nX_ndvi.dim" 表示输出文件完整绝对路径,
# G:\2019_S2_data\Test_NDVI是博主的输出文件路径,
# %~nX表示获取XXXX.zip文件不带后缀.zip的文件名。
# 注意博主这里的输出文件添加了后缀_ndvi.dim
for /r "G:\2019_S2_data" %X in (*.zip) do (gpt NdviOp -Ssource=%X -PnirSourceBand="B8" -PredSourceBand="B4" -t "G:\2019_S2_data\Test_NDVI\%~nX_ndvi.dim")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(如果,你对windows命令行for循环命令不是很了解,你可以参考一下这篇文章BAT 批处理脚本教程(详细篇脚本之家补充))
另外,我想证明SNAP的gpt命令行的执行效率高,一种简单的方式,是你可以打开任务监测器看下其CPU利用率(如果你感兴趣的话可以和SNAP GUI界面执行对比一下):
大约需要10分钟左右的时间(12景影像,平均每景不到一分钟):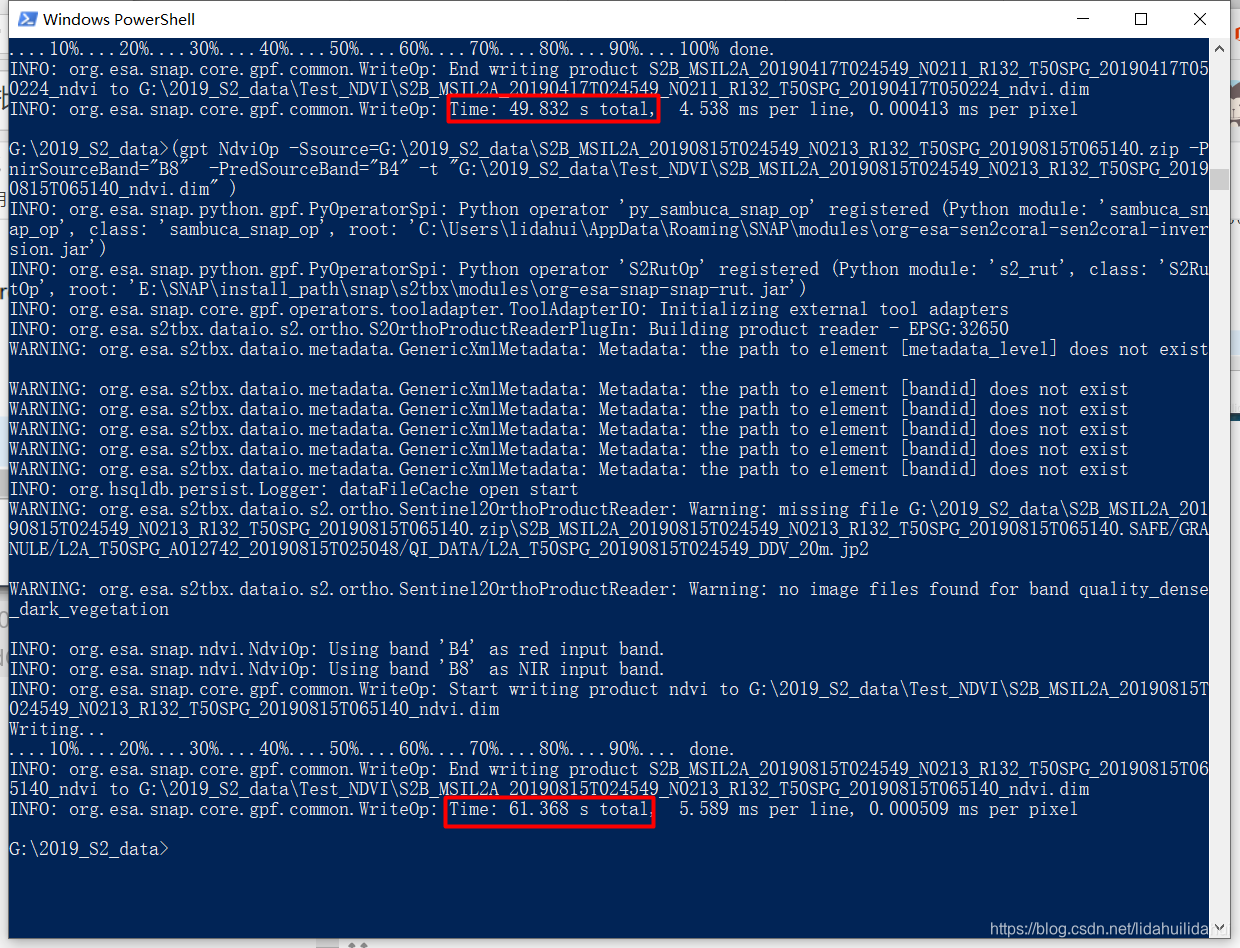
到输出数据目录看看: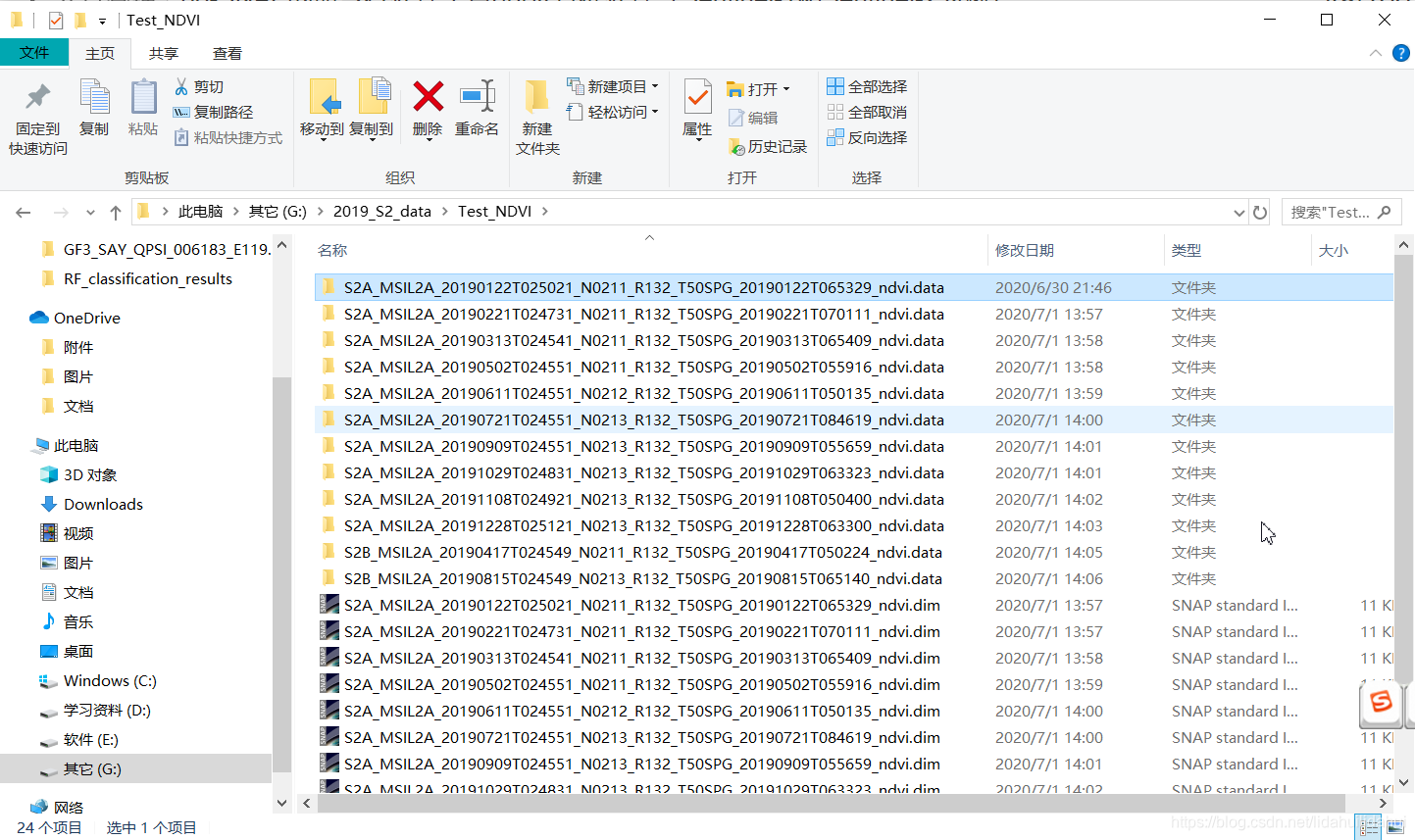
很好!我要的结果全部在。
当然,黄河三角洲2019年各月份的NDVI影像我们已经有了,接下来看下如何在SNAP GUI界面中查看某点(通常可以是你的实测点,如果你有该点的经纬度坐标的话)的时序曲线:
先导入数据:
打开一景ndvi影像: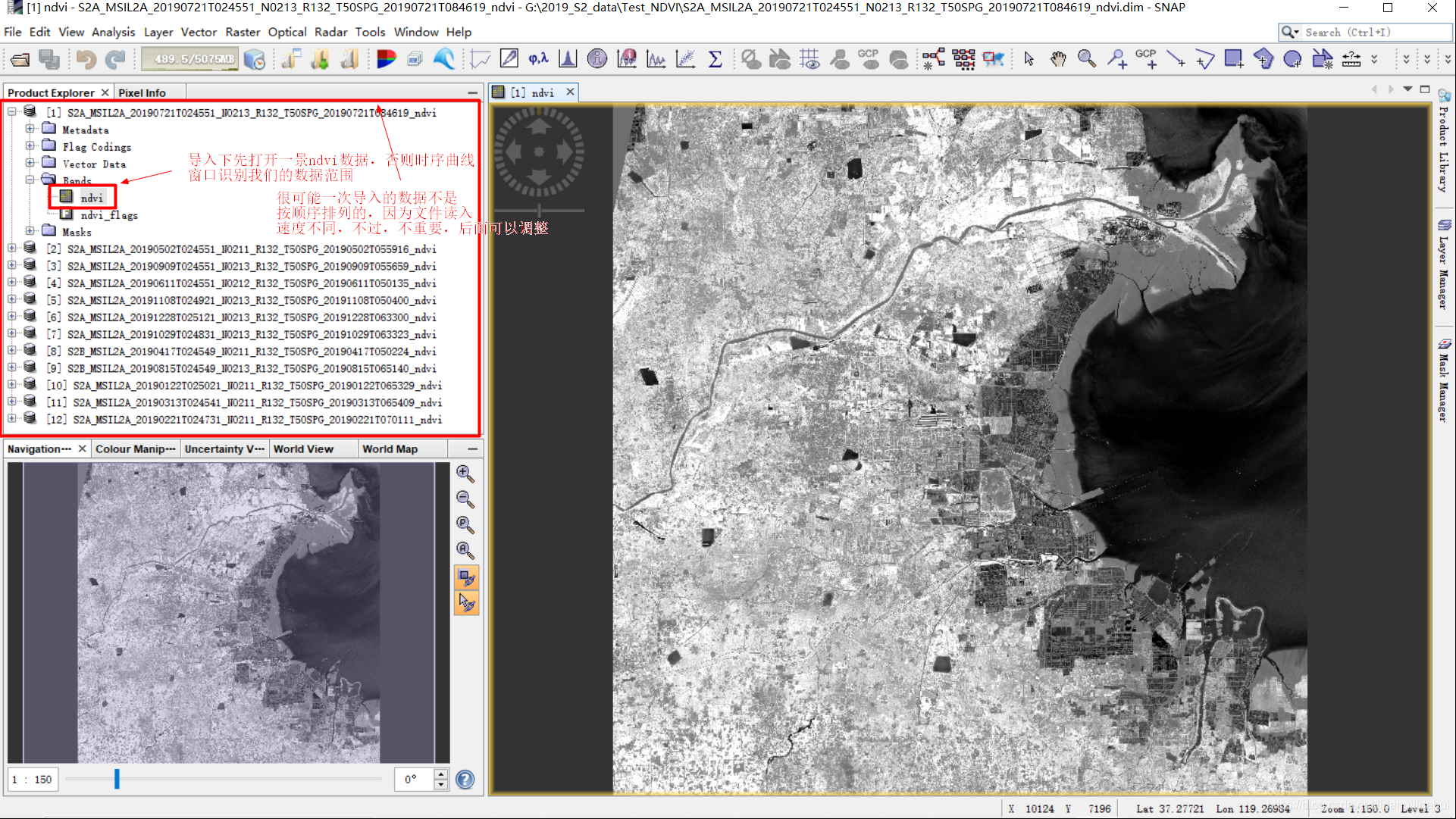
在此之前,先回答一个疑问:按照同一个足迹(按哥白尼数据中心同一搜索框,或者你称为研究区也是可以的)下载的Sentinel-2数据是否还需要配准?答案是不需要的,因为欧空局哥白尼数据中心在生产Sentinel-2影像已经做过几何校正(正射校正)了(利用其近乎遍布全球的控制点,调整和控制误差几何误差),当然,如果你实地测了大范围的控制点,并且你能确保测量的准确性,也是可以做一下配准。如果是同一个研究区(同一个足迹)的Sentinel-2(S2A,S2B,单一源)源影像,是无须配准的,但是,如果是不同源的数据,如Sentinel-2和landsat,Sentinel-1和Sentinel-2,不同源数据融合的话,最好还是配准一下。
为了让你看下Sentinel-2影像的几何校正(正射校正)效果,可以借助打开前四景ndvi影像,均匀分屏显示(并且我可以告诉你,连影像大小,栅格像素数都是一致):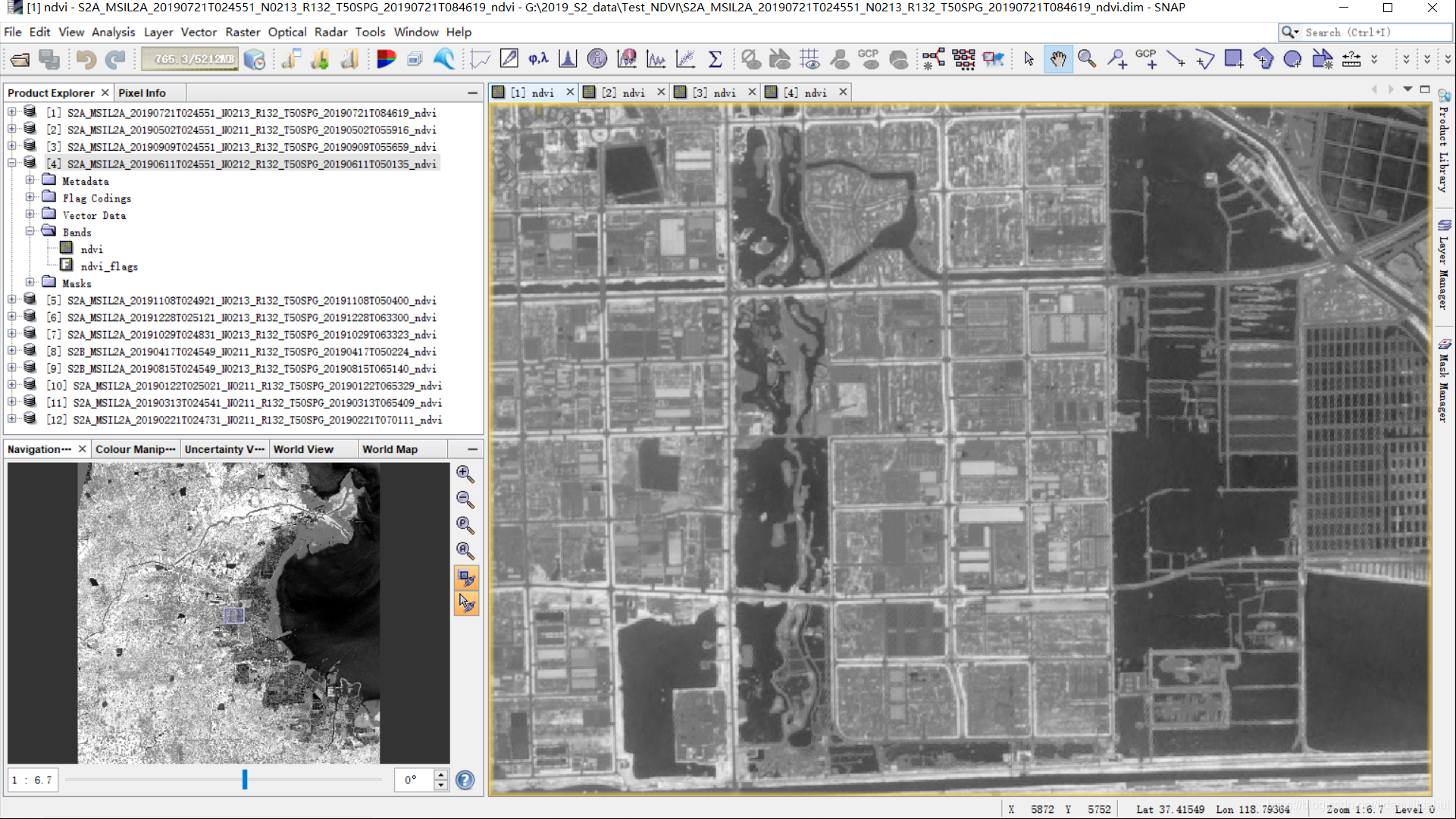
均匀分屏: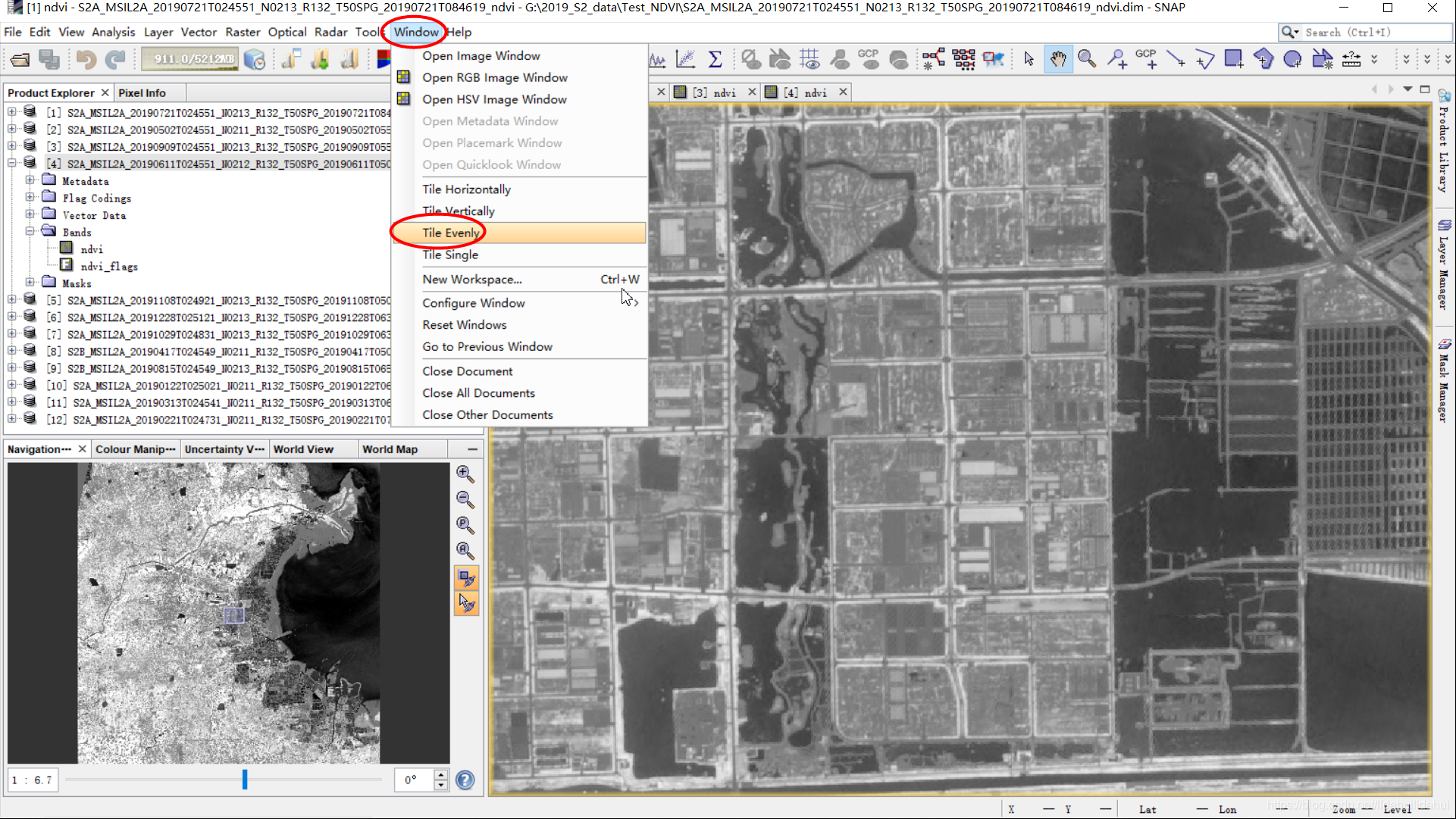
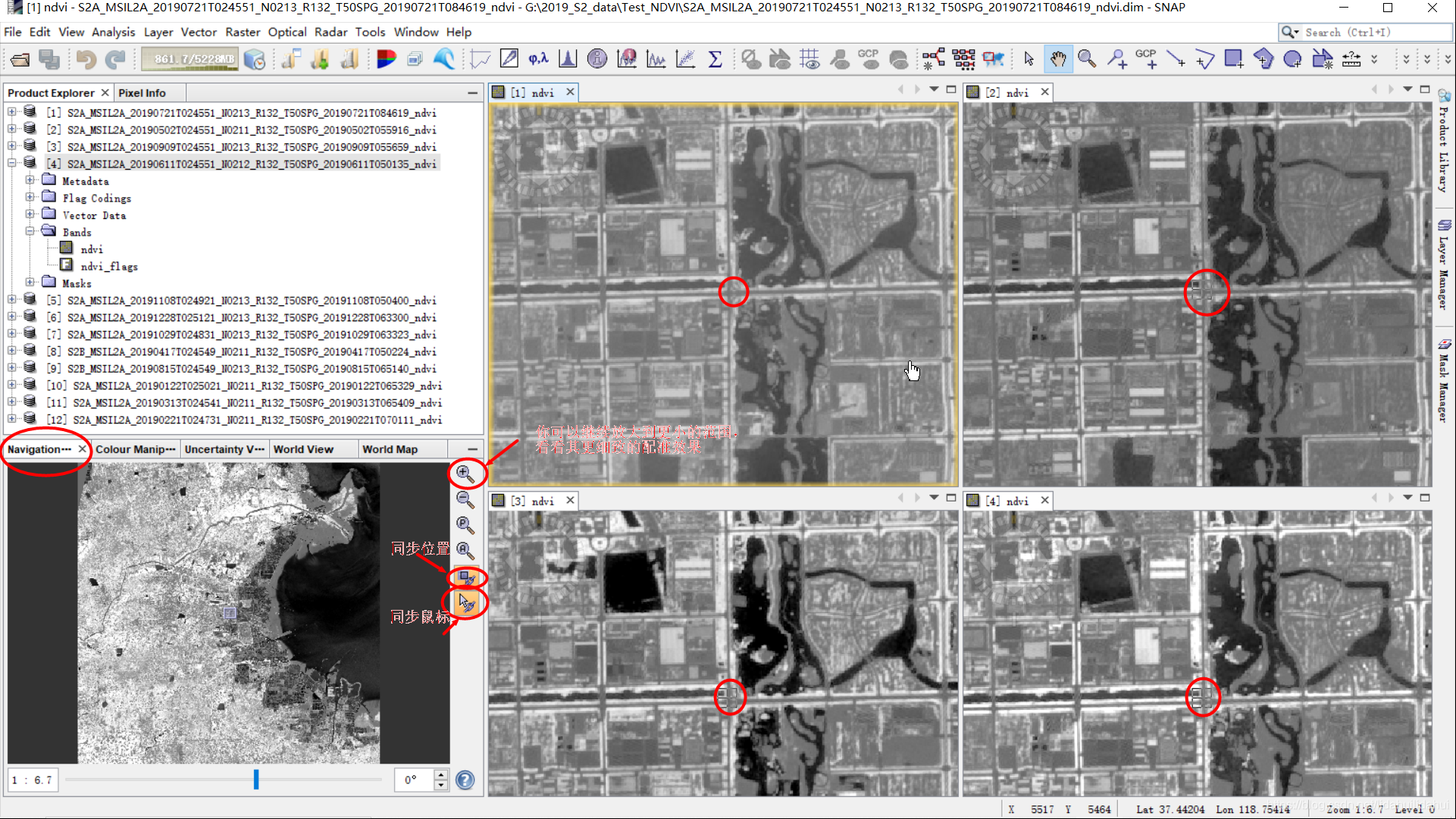
如果和光产卫星数据对比一下,你就会惊讶于Sentinel-2数据的几何校正效果。
很好,我们的Sentinel-2 NDVI数据集是一一对应的,接下来可以看下其时序曲线了。
(可以打开的后3个ndvi的影像窗口)
打开时序曲线窗口(见下图):
时序曲线设置窗口:
(尽管你可以通过向上或向下箭头一一调整数据集的顺序,时期按照日期递增顺序排列,但这样对于时序曲线窗口而言不是必须的,时序曲线窗口自动提取日期并绘制其时间对应的时间序列曲线)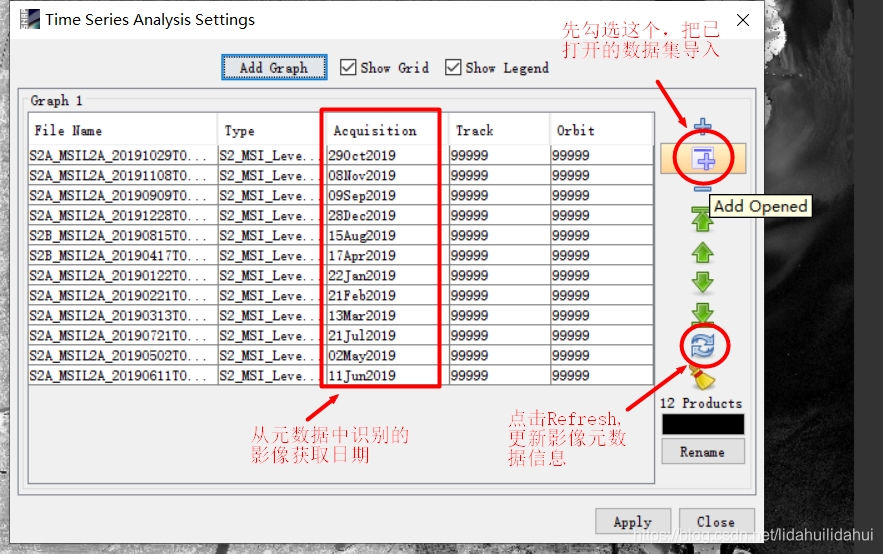
筛选绘制的波段(这里的ndvi_flag对我们来说不是很有用的信息,它是一个标志波段,衡量ndvi质量的, 见04篇博客)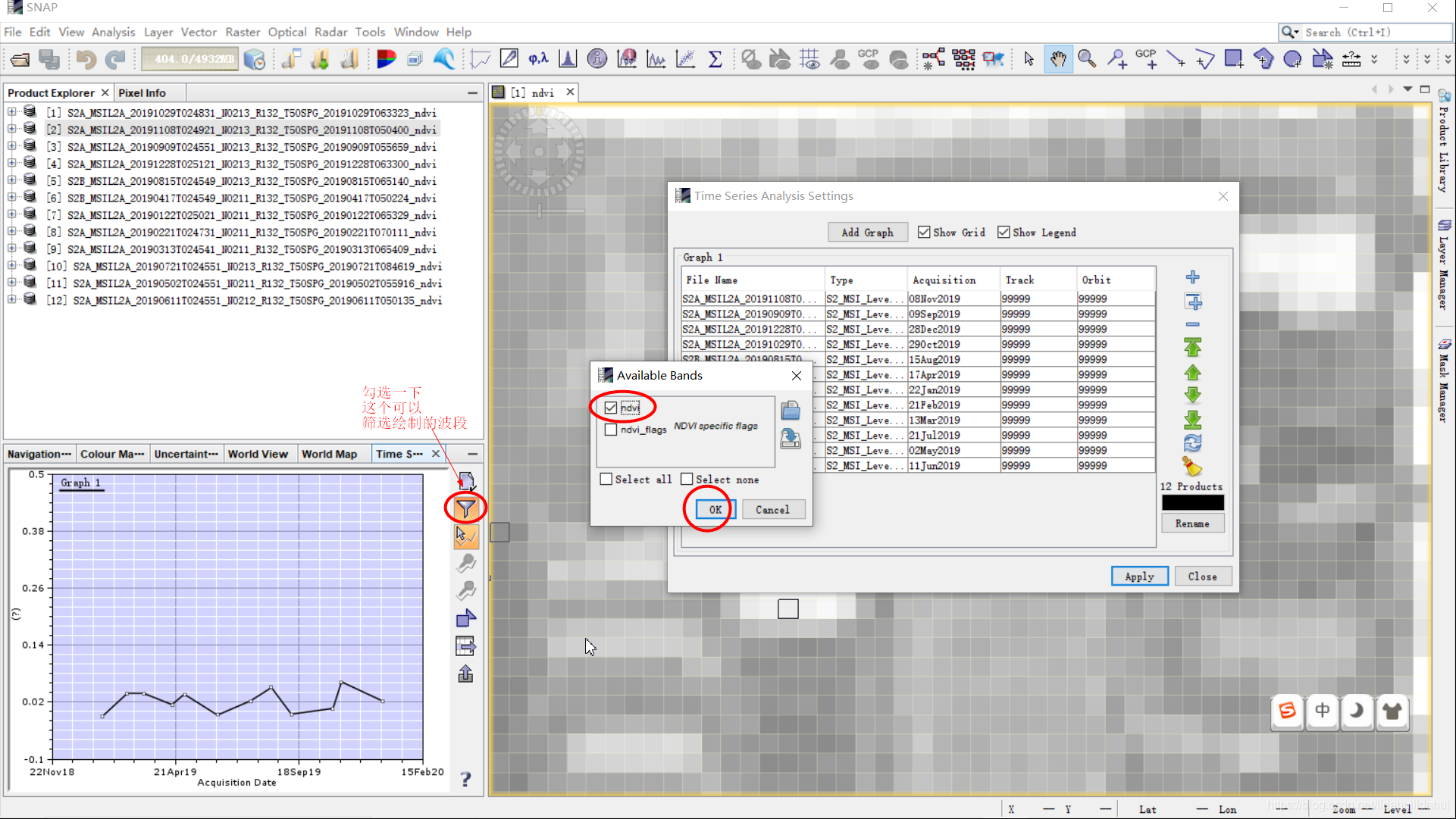
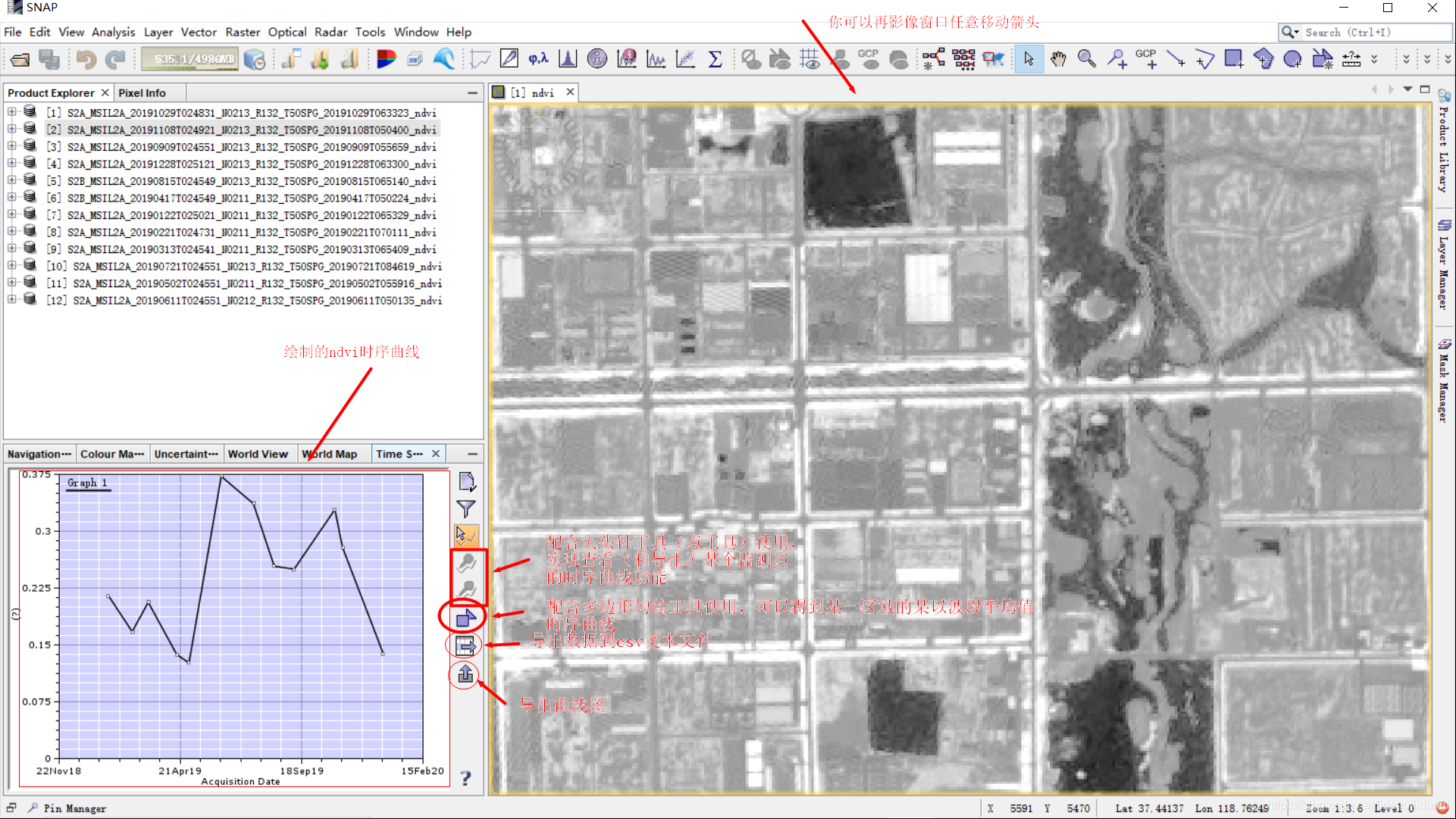
更多的说明请查看SNAP官方论坛Time Series (Temporal) of NDVI的讨论。
Sentinel-1批量轨道校正
有了上述经验,Sentinel-1 IW GRDH 批量轨道校正也是轻易的事情。
博主的Sentinel-1源数据集目录为D:\temp_SAR,输出目录为D:\temp_SAR\test_apply_orbit_file: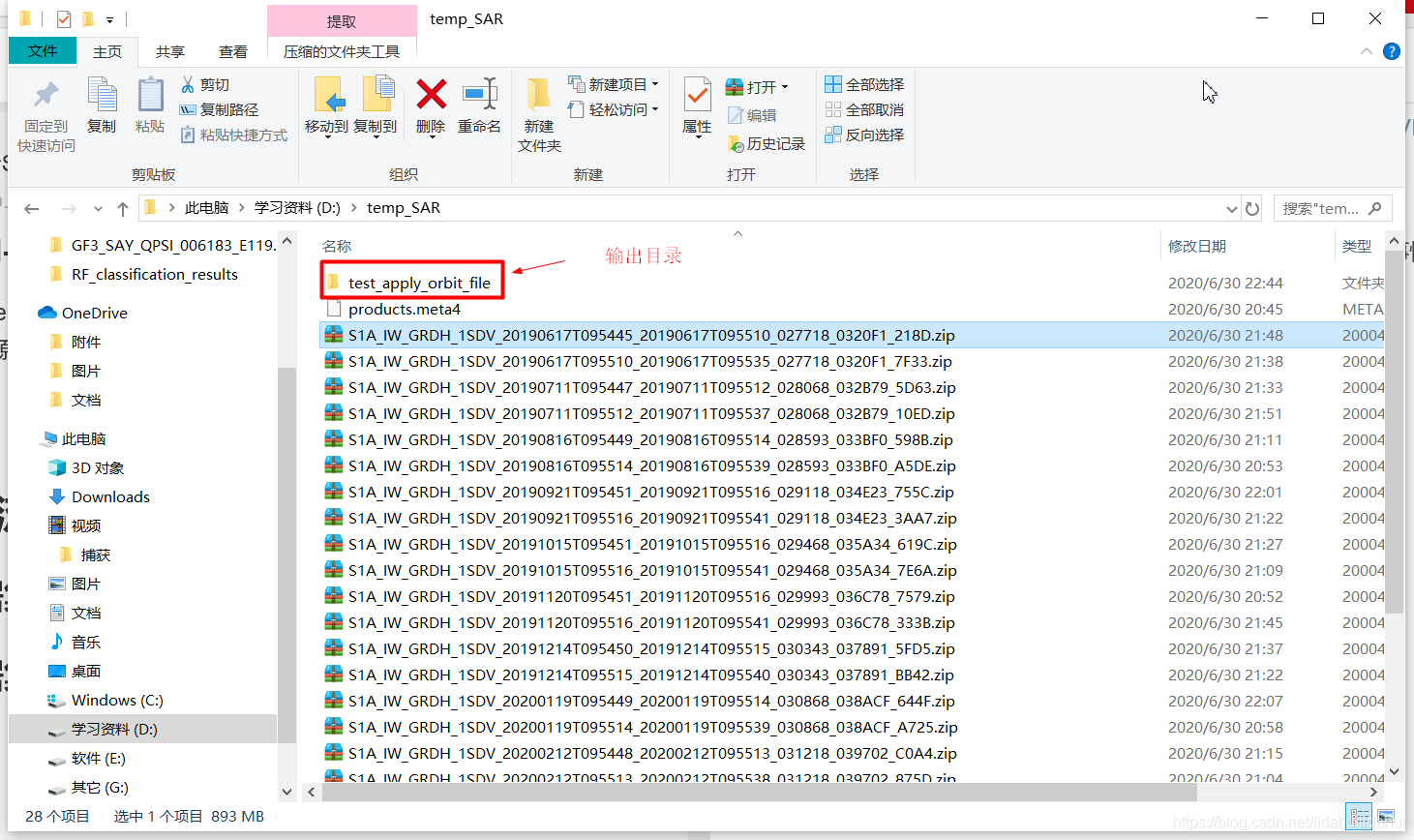
批量校正命令:
(如果你需要处理自己的数据集,只需修改对应的输入、输出目录路径即可)
# 虽然仍是一句命令,但是添加路径后,显得很长。可以将最后一行命令复制到一个.txt文件中,
# 在.txt文本中也容易编辑命令。确认命令无误后,
# 打开命令行界面(在命令行界面中点击鼠标右键则可以粘贴拷贝的文本了)
# /r "D:\temp_SAR" 表示在该路径下迭代文件,这是博主存放源数据的目录
# %X是迭代变量,这里用于表示迭代的zip文件绝对路径
# *.zip 是正则表达式语法,这里是后缀含有.zip的文件
# -Ssource=%X 表示gpt的源文件
# -t "D:\temp_SAR\test_apply_orbit_file\%~nX_Orb.dim" 表示输出文件完整绝对路径,
# D:\temp_SAR\test_apply_orbit_file是博主的输出文件路径,
# %~nX表示获取XXXX.zip文件不带后缀.zip的文件名。
# 注意博主这里的输出文件添加了后缀_Orb.dim
for /r "D:\temp_SAR" %X in (*.zip) do (gpt Apply-Orbit-File -Ssource=%X -t "D:\temp_SAR\test_apply_orbit_file\%~nX_Orb.dim")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
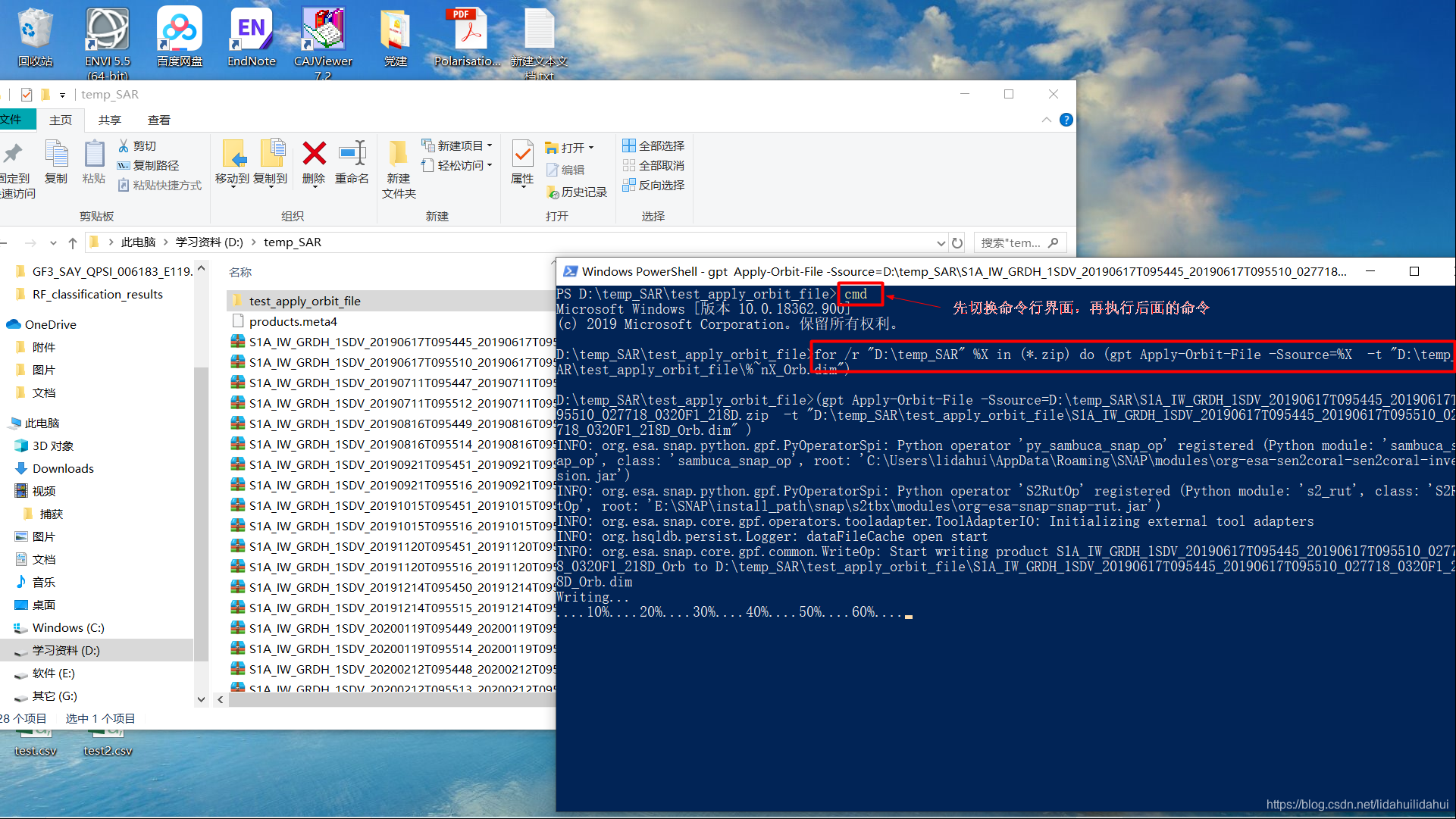
结束了(大约每景1分半,24景需要40分钟左右的时间):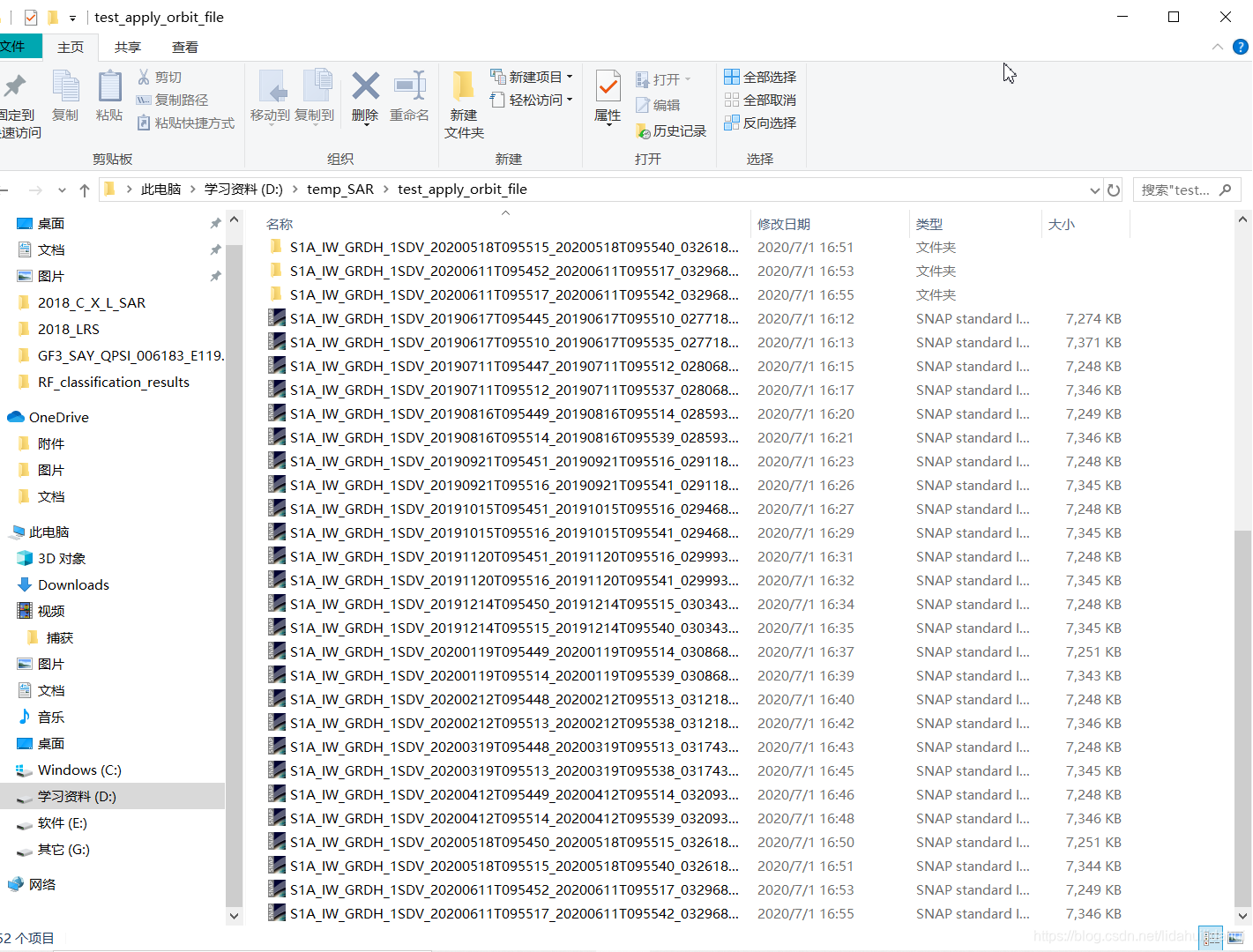
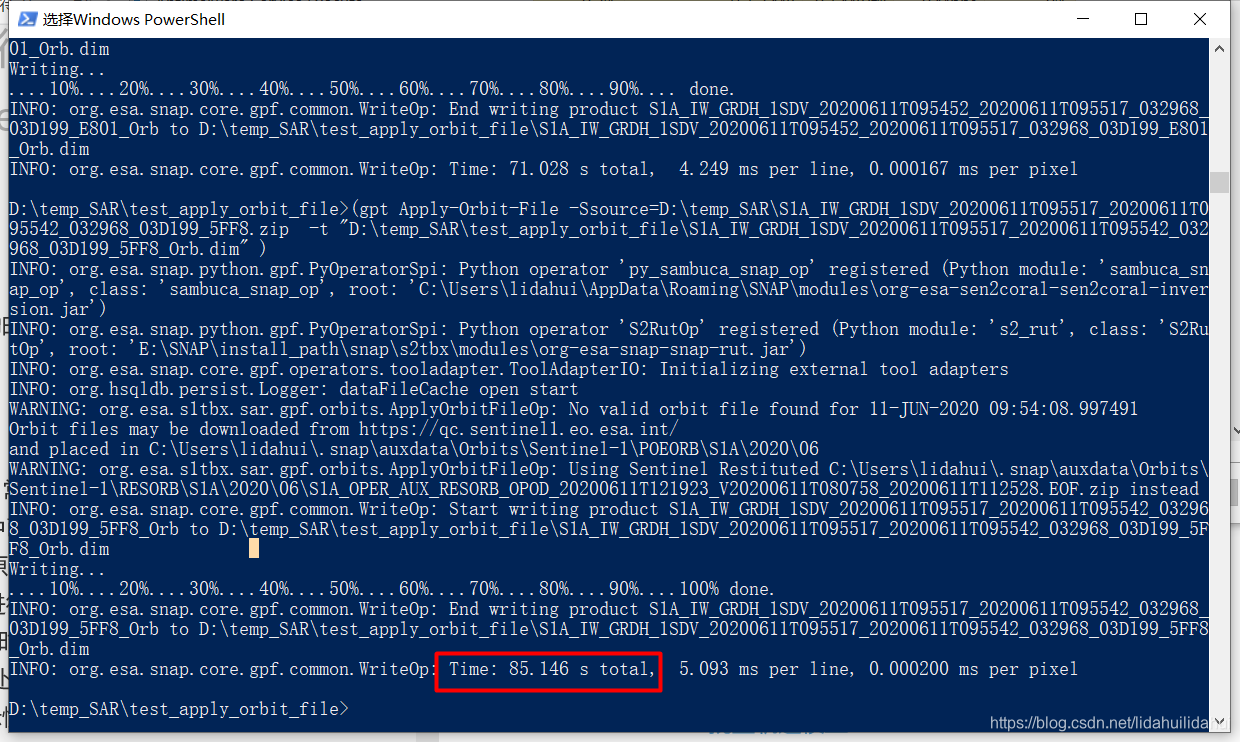
就单个操作的处理,对于Sentinel-1来说不是很有用,Sentinel-1(或者别的SAR数据)的预处理往往需要多步(类似流程图的处理操作)。
gpt搭配流程图实现流程式处理
如果仅仅在gpt中执行单个处理操作,未免有点“大材小用”了,gpt的高效处理在流程式操作才能体现出来。
本篇博客所用的流程图文件以及代码见百度云盘:
链接:https://pan.baidu.com/s/1vxkJX0S4_TWx-N1r7pOfTA
提取码:eak9
单个数据集流程图处理
Sentinel-2 L2A 数据集流程式处理
仍然以S2A_MSIL2A_20190122T025021_N0211_R132_T50SPG_20190122T065329.zip
这景数据为例。
来创建一个Sentinel-2 L2A 用于分类特征数据集,流程如下图(如果你对流程图的步骤不是很熟悉,可以看下04篇博客波段叠加部分):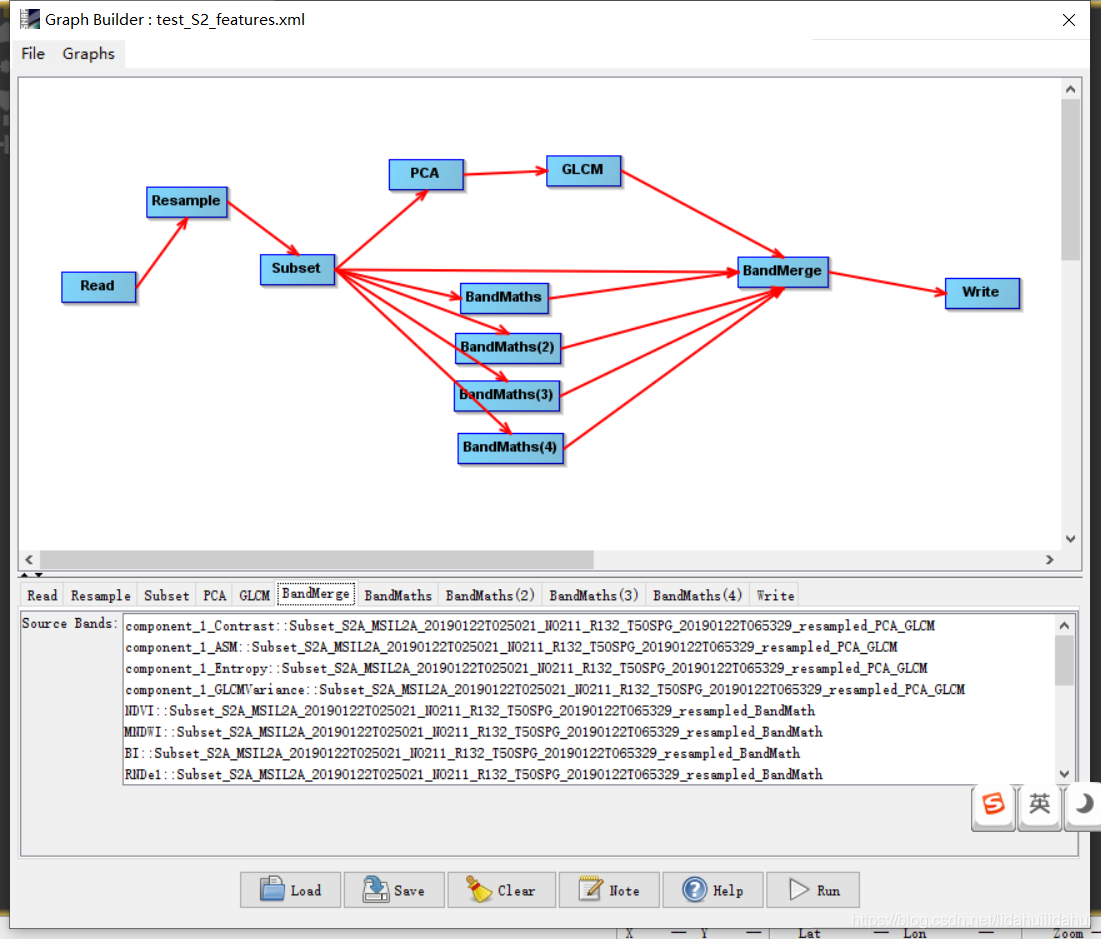
这个流程图(创建流程图一定注意步骤顺序,否则很容易出错)实际上是博客03和04篇博客的步骤总结,具体是先现将Sentinel-2数据重采样至10米(以10米波段2分辨率为依据),然后裁剪出黄河三角洲区域,随后做主成分变换(提取3个主成分),利用得到第一个主成分通过其共生纹理矩阵计算其四个纹理特征(对比度、二阶角动量、熵、方差);通过波段运算计算NDVI(归一化植被指数)、MNDWI(改进归一化水体指数)、BI(土壤亮度指数)、NDre1(红边波段归一化指数1)四个指数特征;最后,将纹理特征、指数特征和原来的光谱特征通过BandMerge工具叠加起来,写入到数据集。
各个流程节点参数(只对需要注意的参数进行标注):
Read:
Resample: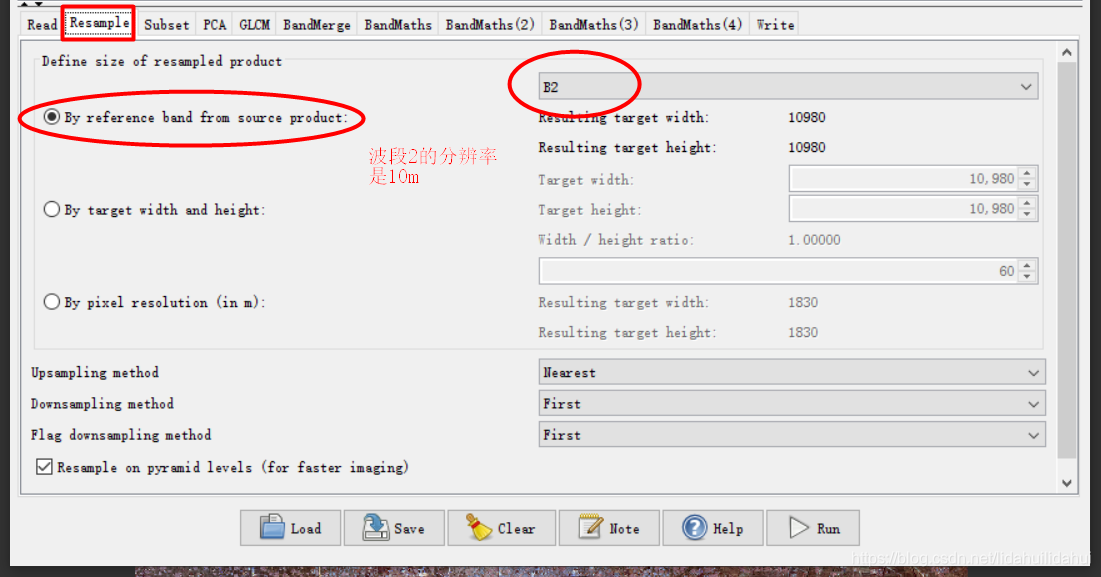
Subset: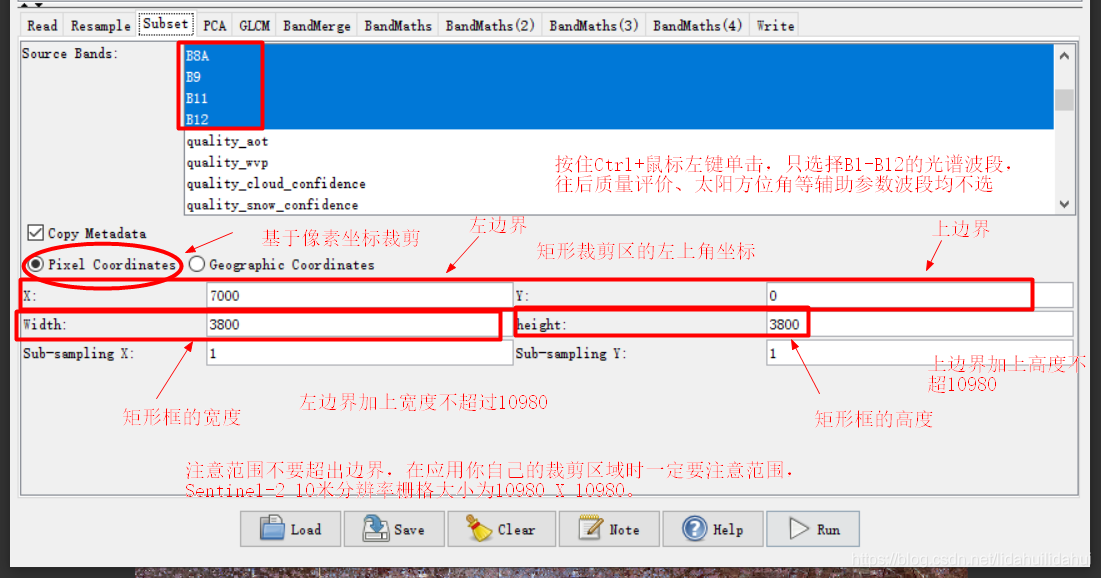
PCA: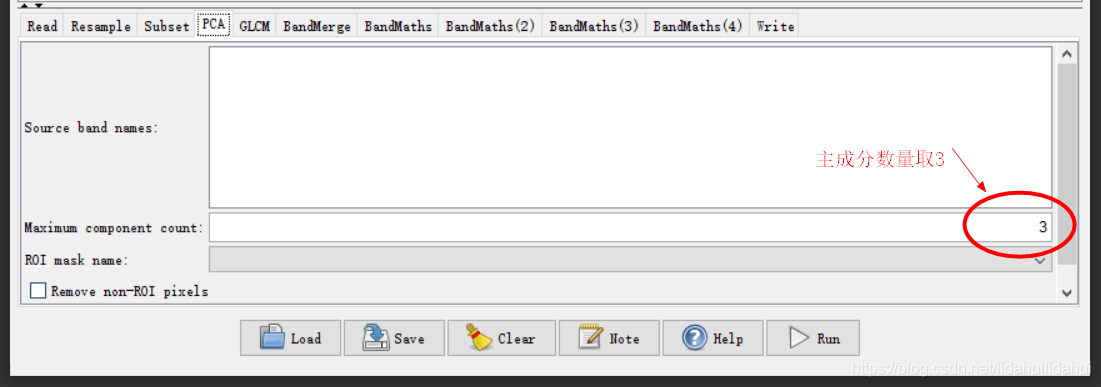
GLCM: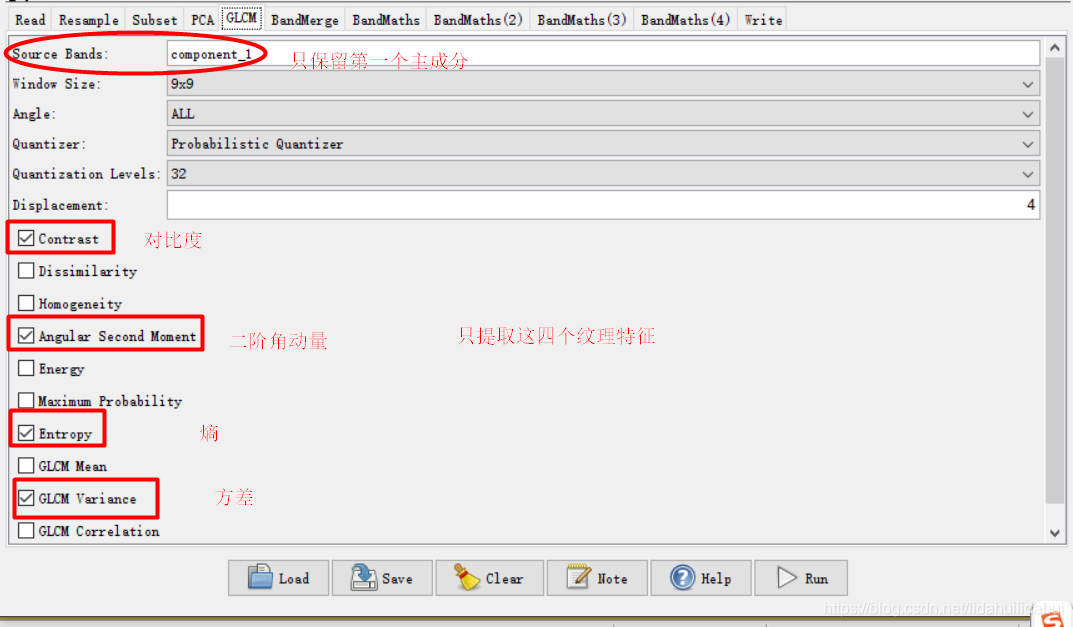
BandMaths: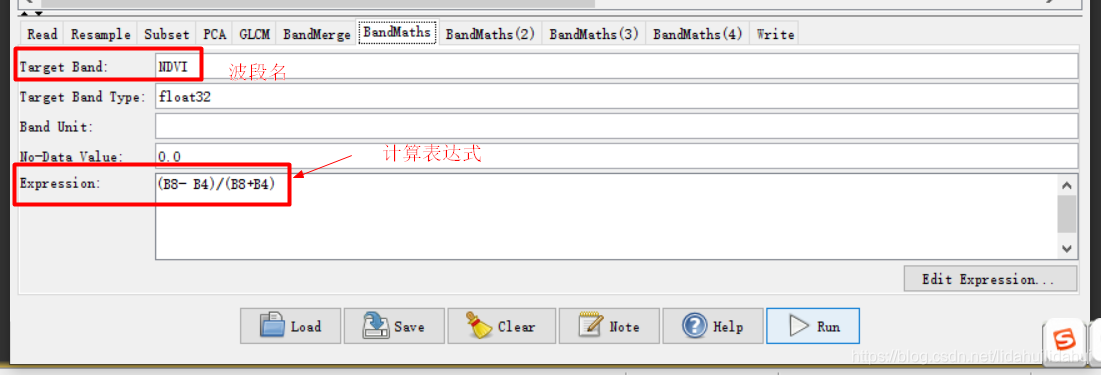
BandMaths(2):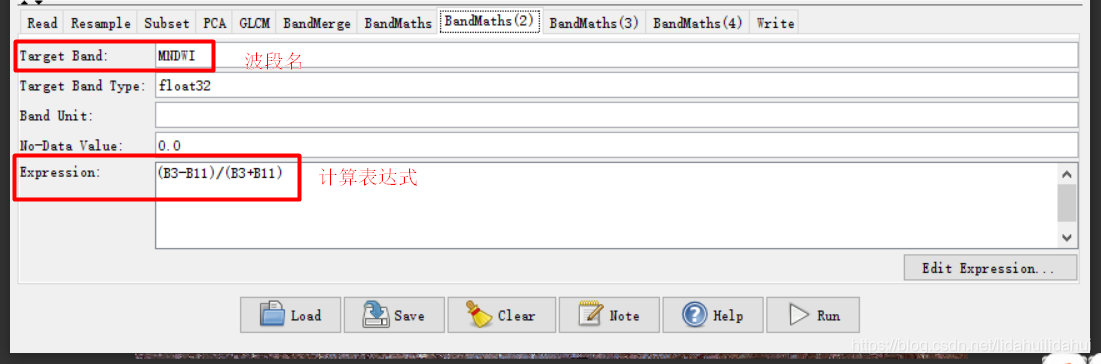
BandMaths(3):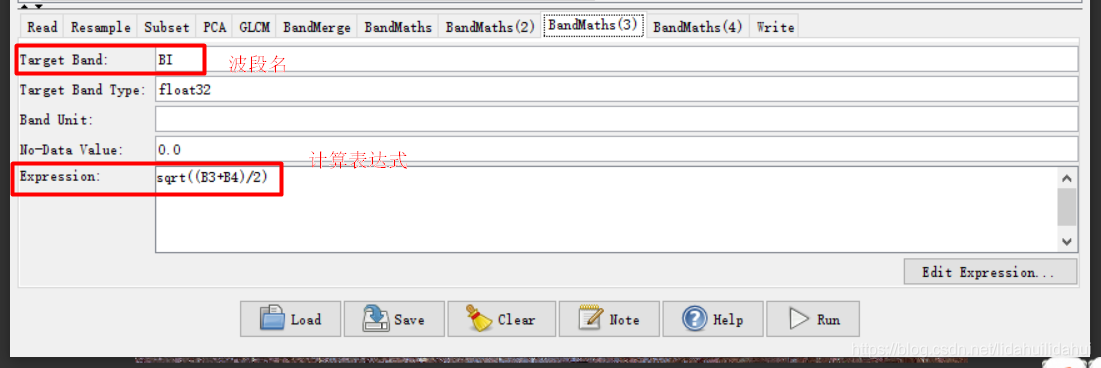
BandMaths(4):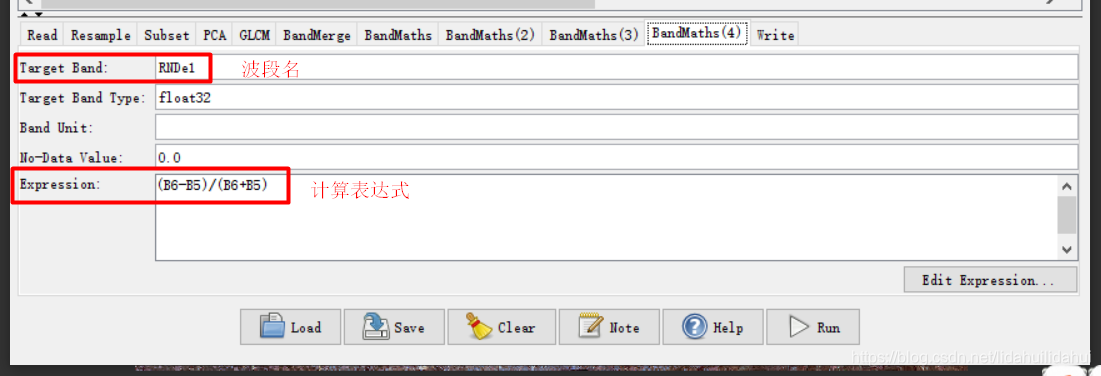
BandMerge: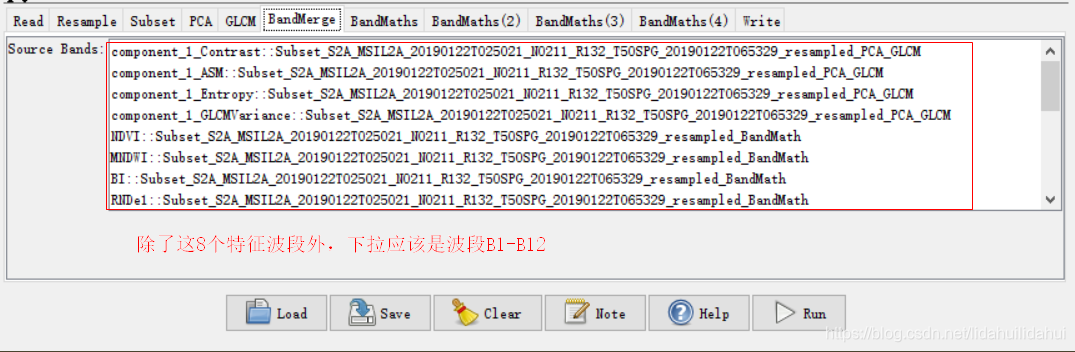
Write:
(博主创建了一个源数据目录下创建了一个S2_features文件夹用于保存生成的Sentinel-2特征数据集)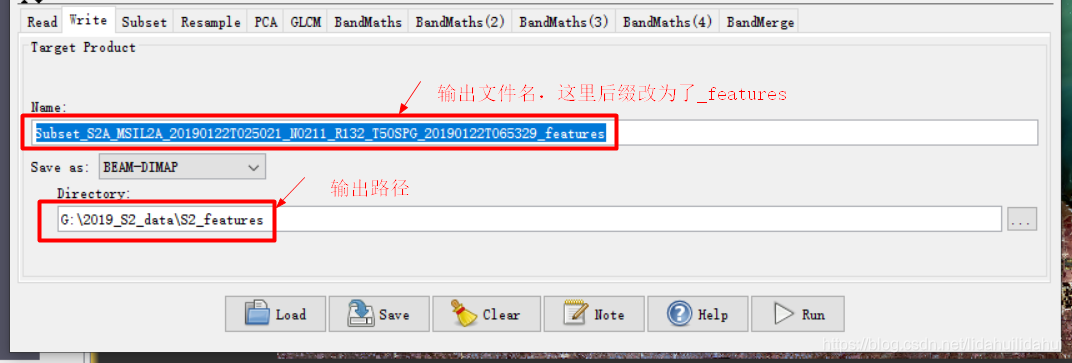
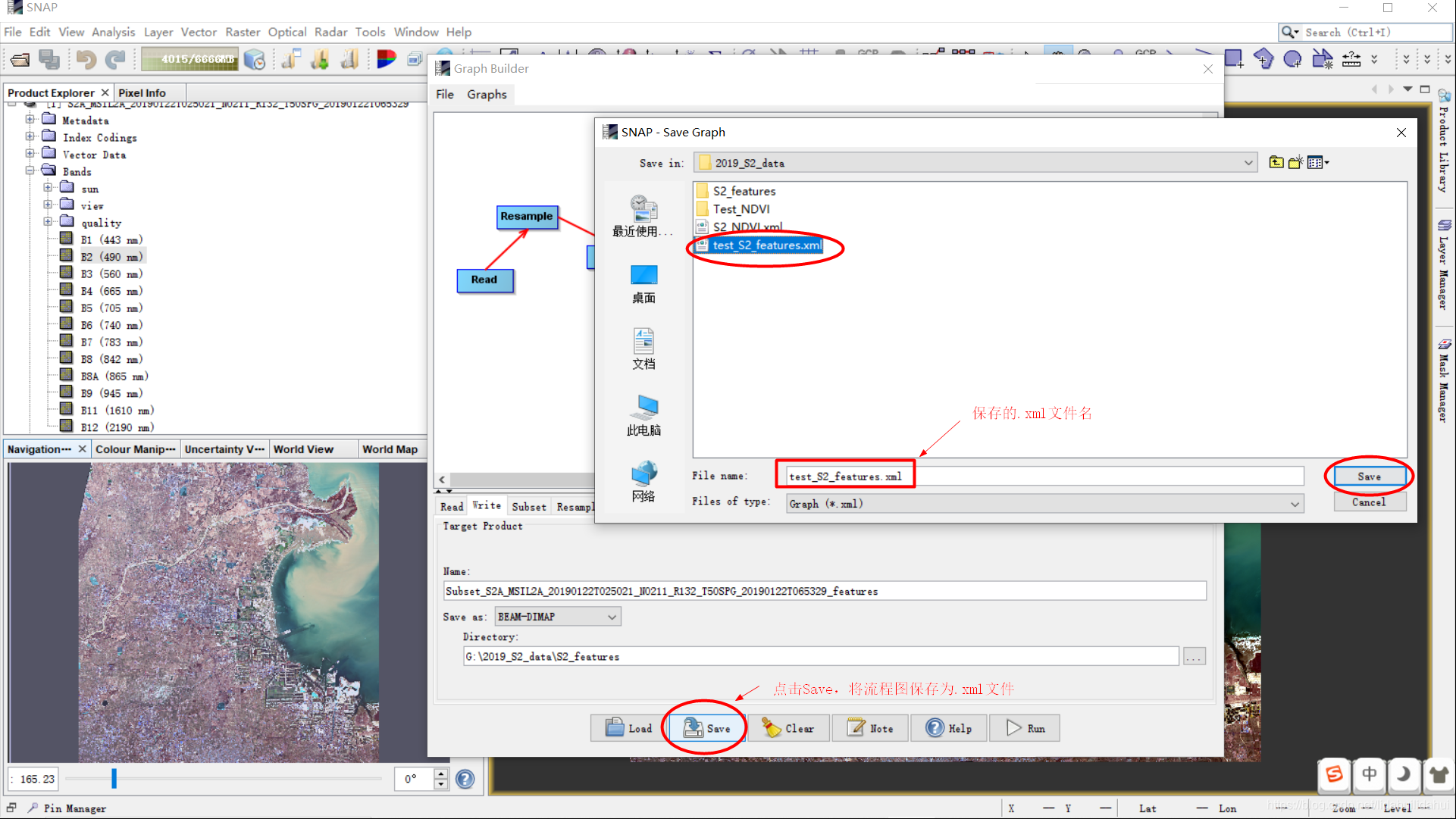
然后关闭流程图窗口,关闭SNAP,进入保存的流程图xml文件,查看流程图文件: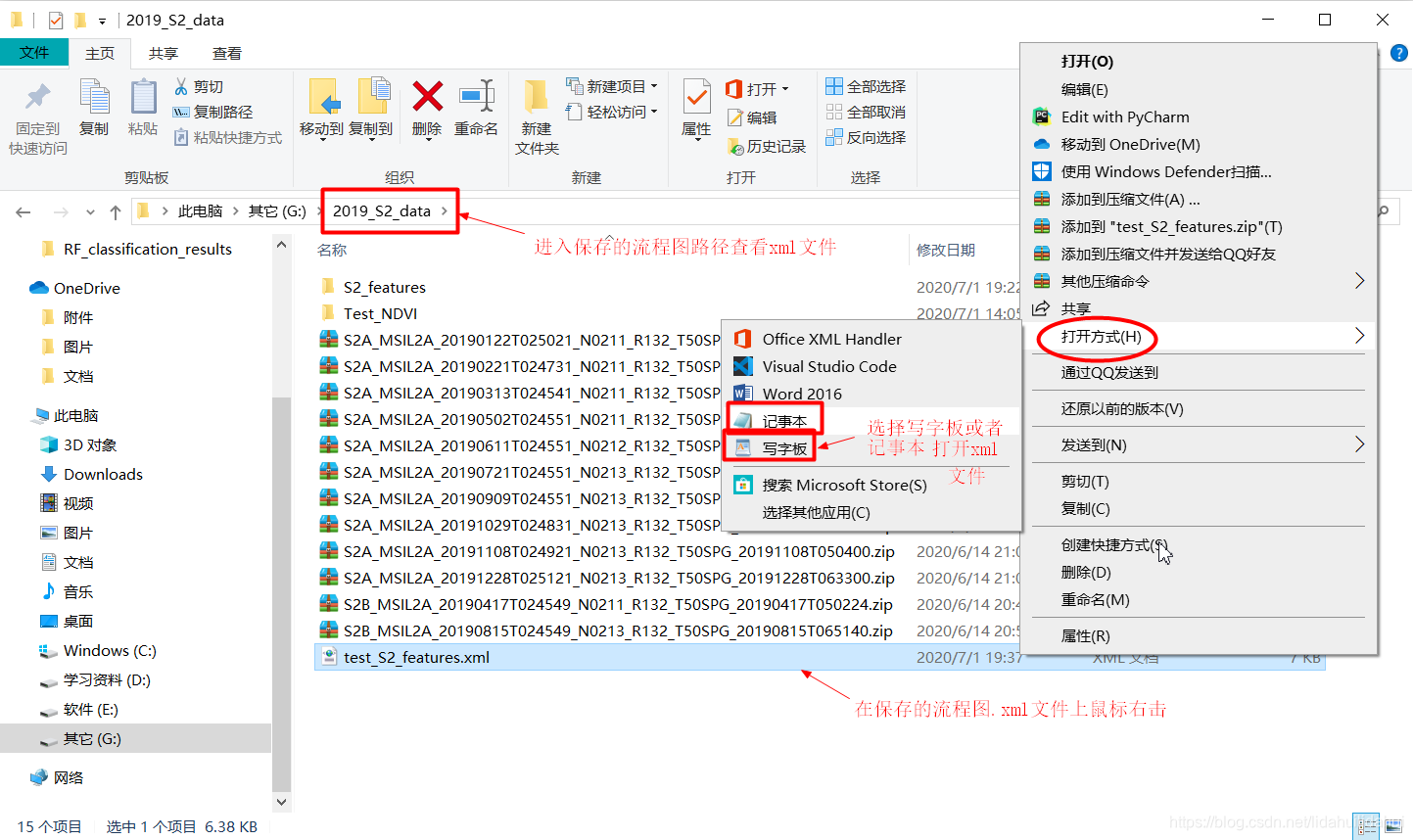
可以看下其节点内容(如果你熟悉html网页文件的话,应该可以识别每个节点的内容),先看看其内容,以增强你对流程图参数文件认识,不要改动其中的内容。
(上下拖动鼠标浏览后,可以关闭该xml文件)
我告诉你接下来,只需要使用gpt命名行输入一句命令即可以执行该景数据的预处理,启动一个PowerShell命令行窗口:
# G:\2019_S2_data\test_S2_features.xml为流程图文件的绝对路径,
# 你可能结合自己的流程图文件改动一下路径
# 因为我们在创建流程图时定义数据集的输入与输出
# 所以这里命令行参数没有输入和输出参数
gpt G:\2019_S2_data\test_S2_features.xml
- 1
- 2
- 3
- 4
- 5
不好意思,上述复杂的流程图计算,博主使用gpt命令行工具,仅用了两分钟(不到一个上小便的时间)就完成计算了(当然,博主把研究区裁剪到了近似原来的1/10,数据量少了很多,但是其效率仍然很高):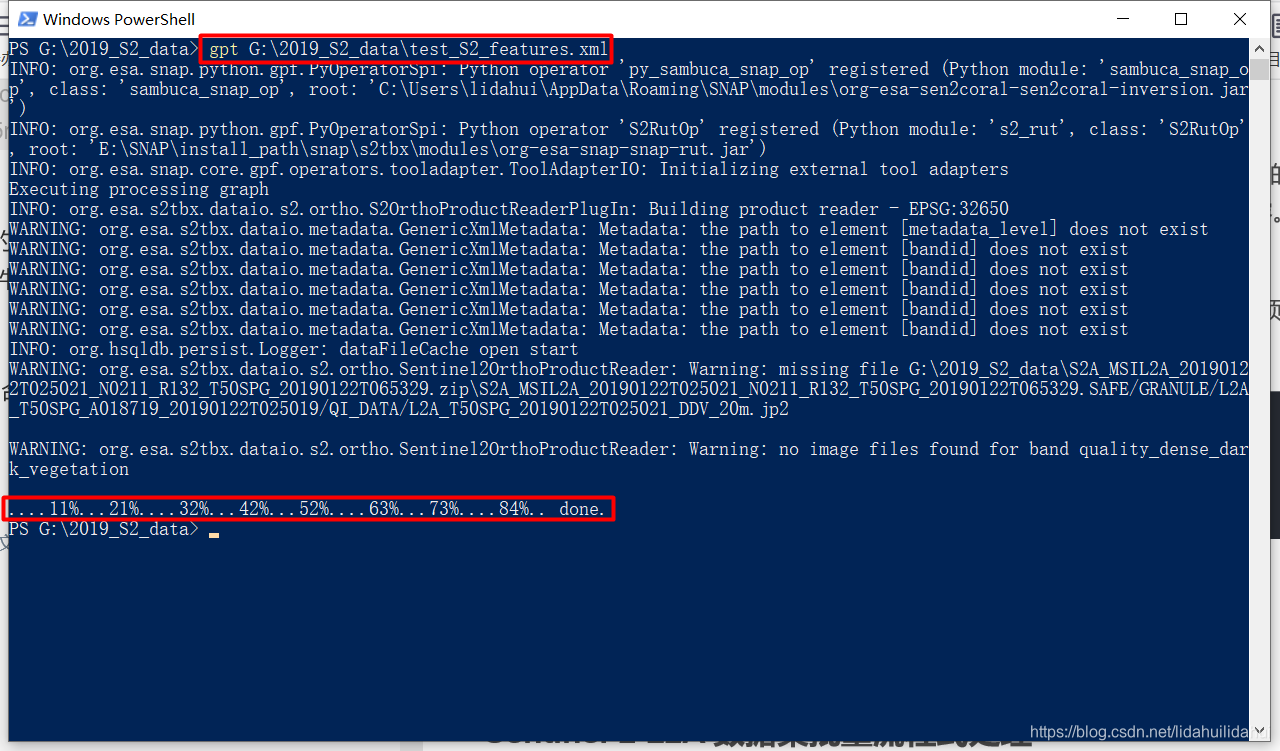 生成的数据集:
生成的数据集:
将该数据导入SNAP看下效果: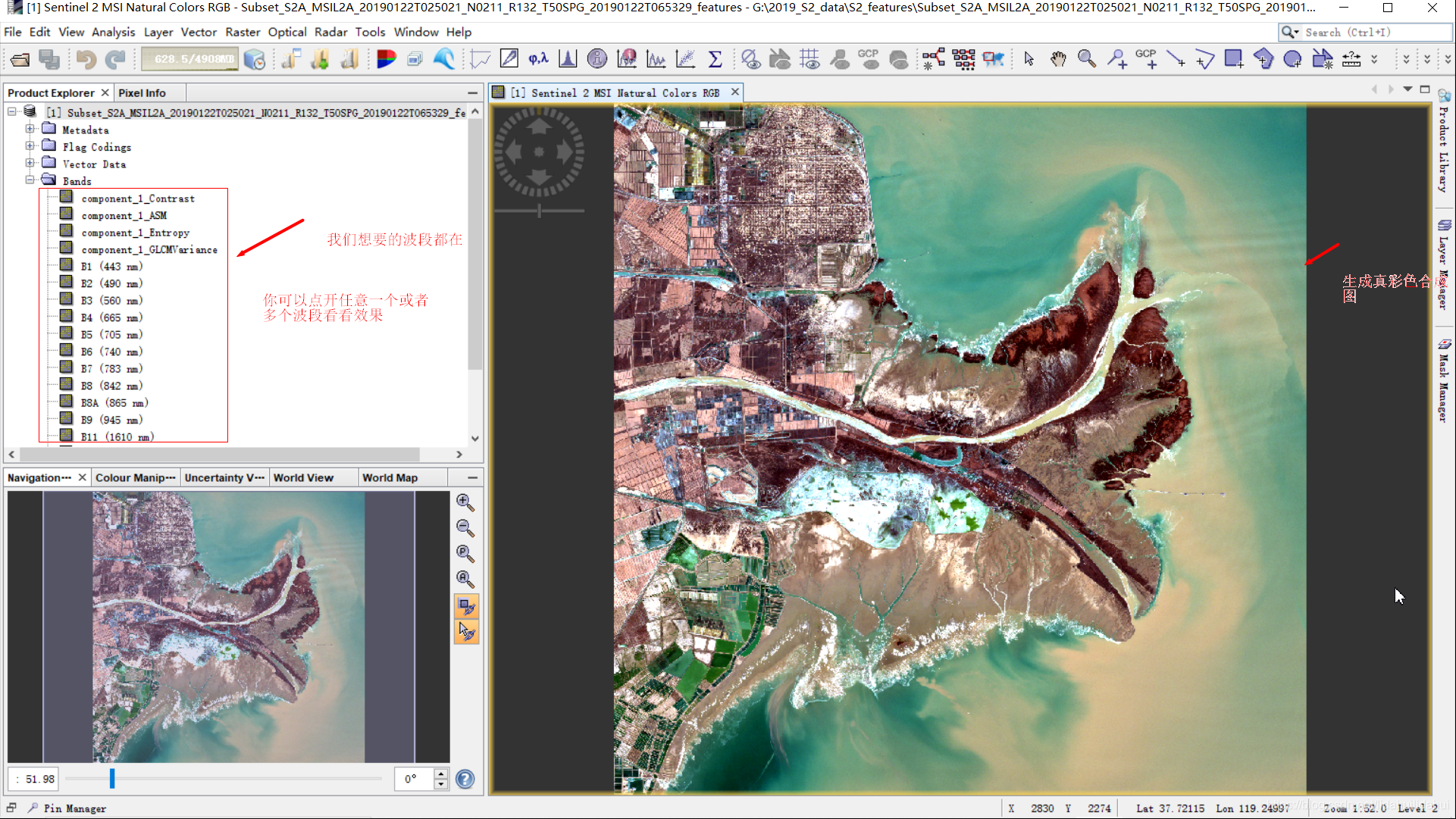
perfect!就是这样轻松愉快就得到了一个用于分类的数据集。
如果你想利用这个数据集来做随机森林分类,请参考05篇博客。
Sentinel-1 IW GRDH 数据集流程式处理
仍然以07篇该景数据为例:
创建的流程图请参考博客07篇流程图预处理部分预处理部分: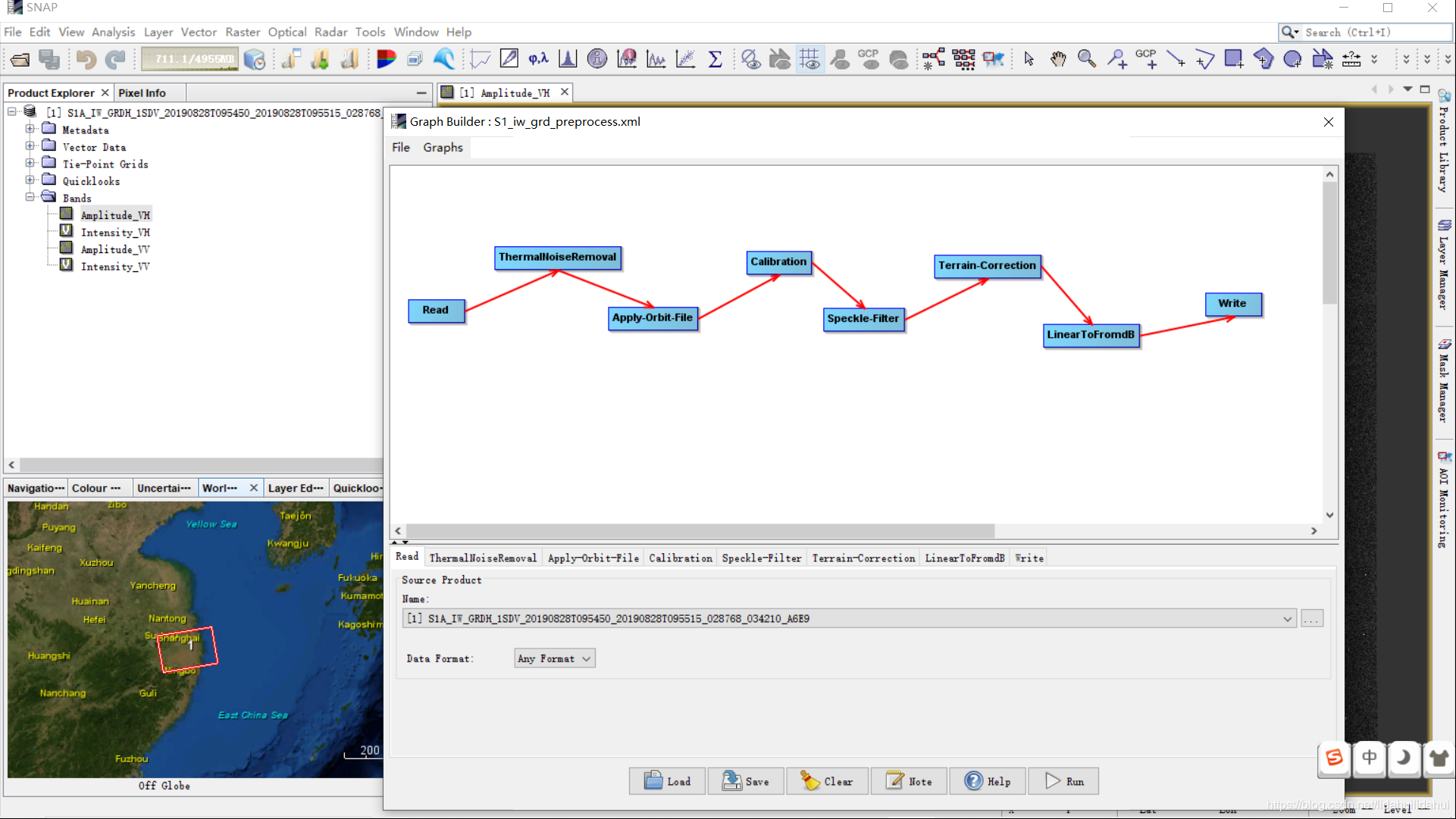
该流程图的各节点参数均与07篇流程图预处理部分的路程图参数相同: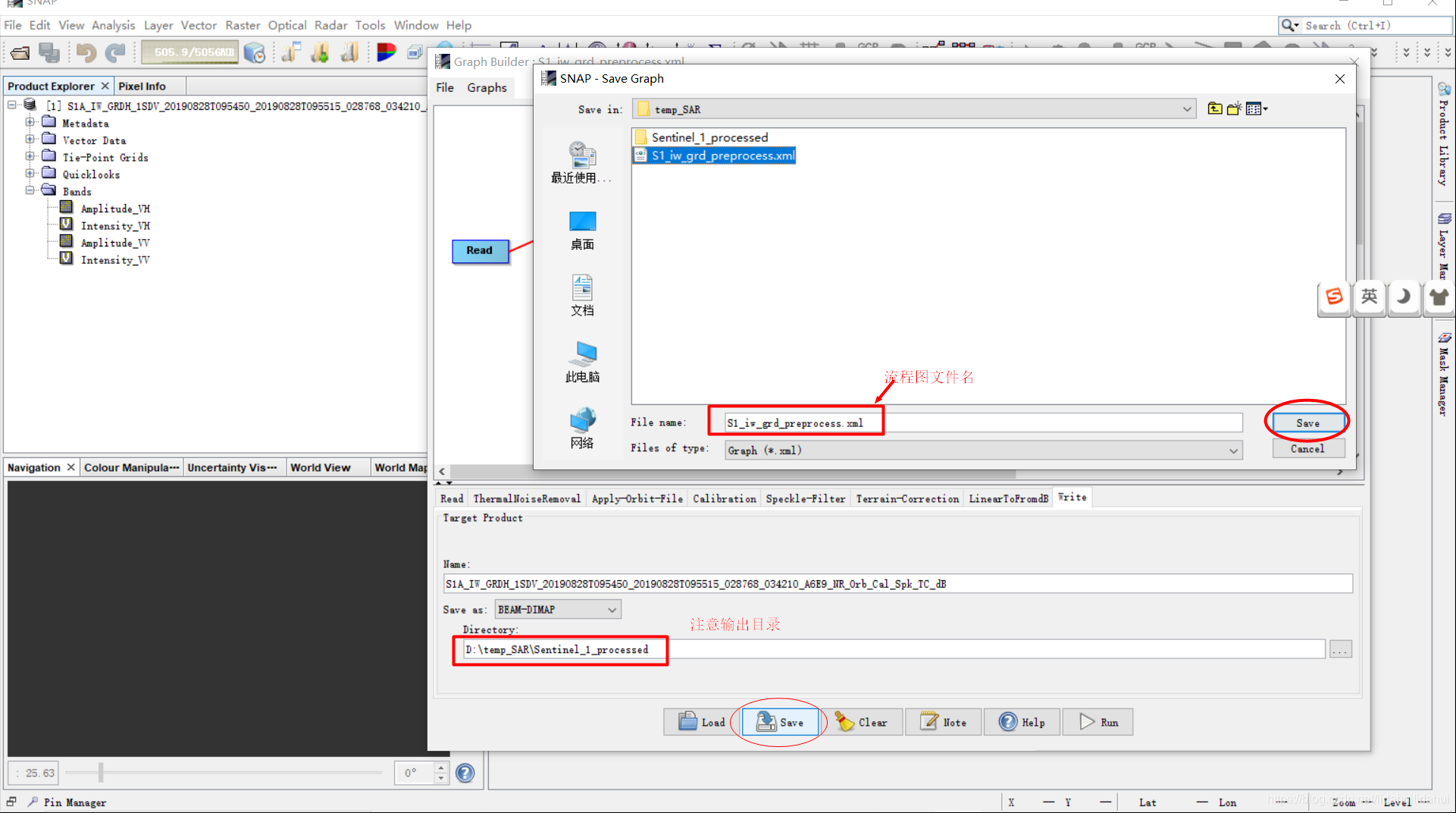
然后关闭流程图窗口和SNAP。
博主的源数据和保存的流程图文件目录为D:\temp_SAR,要保存的输出文件目录为D:\temp_SAR\Sentinel_1_processed。
在源数据文件目录启动一个PowerShell窗口,输入以下一句命令:
# D:\temp_SAR\S1_iw_grd_preprocess.xml为流程图文件的绝对路径,
# 你可能结合自己的流程图文件改动一下路径
# 因为我们在创建流程图时定义数据集的输入与输出
# 所以这里命令行参数没有输入和输出参数
gpt D:\temp_SAR\S1_iw_grd_preprocess.xml
- 1
- 2
- 3
- 4
- 5
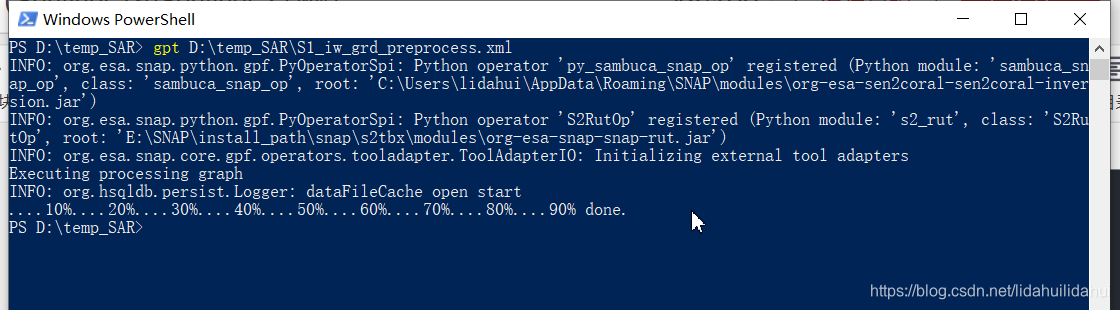
大概需要耗费10左右分钟的时间,便处理完成。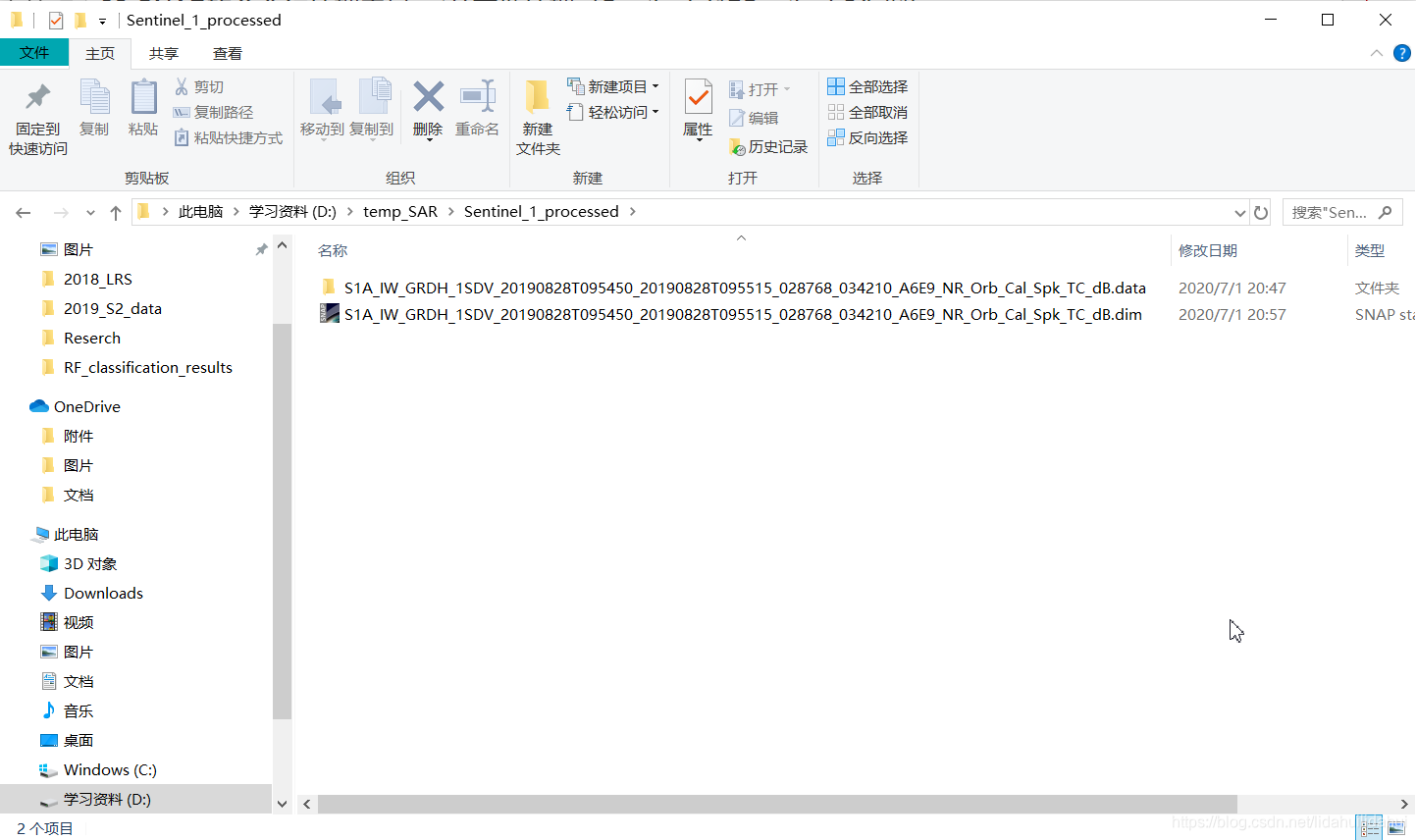
将预处理后的数据导入SNAP查看一下效果: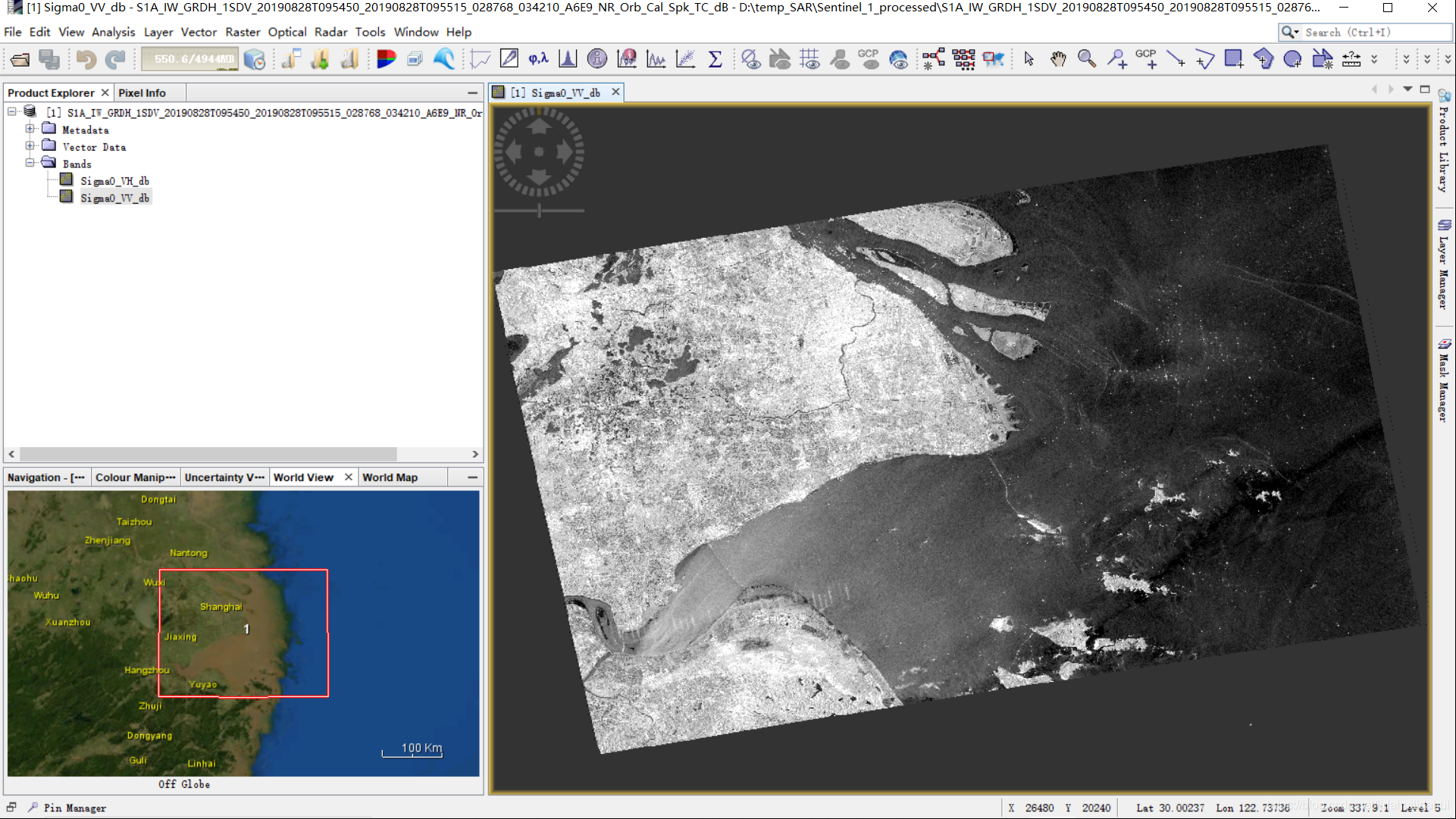
gpt工具很好地完成了处理!
多个数据集批量流程图处理
绝大多数SNAP中的功能在流程图中都能找到其操作名,包括部分添加到SNAP的第三插件,而只要是流程图带有的节点操作,在SNAP的gpt中都是可以实现的。
Sentinel-2 L2A 数据集批量流程式处理
(我估算了一下运算量,应该8G运行内存的电脑是可以实现这个流程图的批处理的,因为流程图做做了裁剪操作,运行内存的电脑跑这个批处理可能比较吃力)
有时候我们希望得到同一地区多景Sentinel-2特征数据集,以便分析其时序特征或时序变化化又或者进行多时相的分类或变化检测等。幸运的是利用流程图文件和gpt命令行工具,我们很容易实现数据量批处理。
利用上述Sentinel-2 L2A 数据集流程式处理部分,创建的流程图文件和gpt工具很容易实现获取多景Sentinel-2特征数据集的批量处理。但是,我们需要对流程图xml文件做一些小修改:
先打开相应的流程图文件: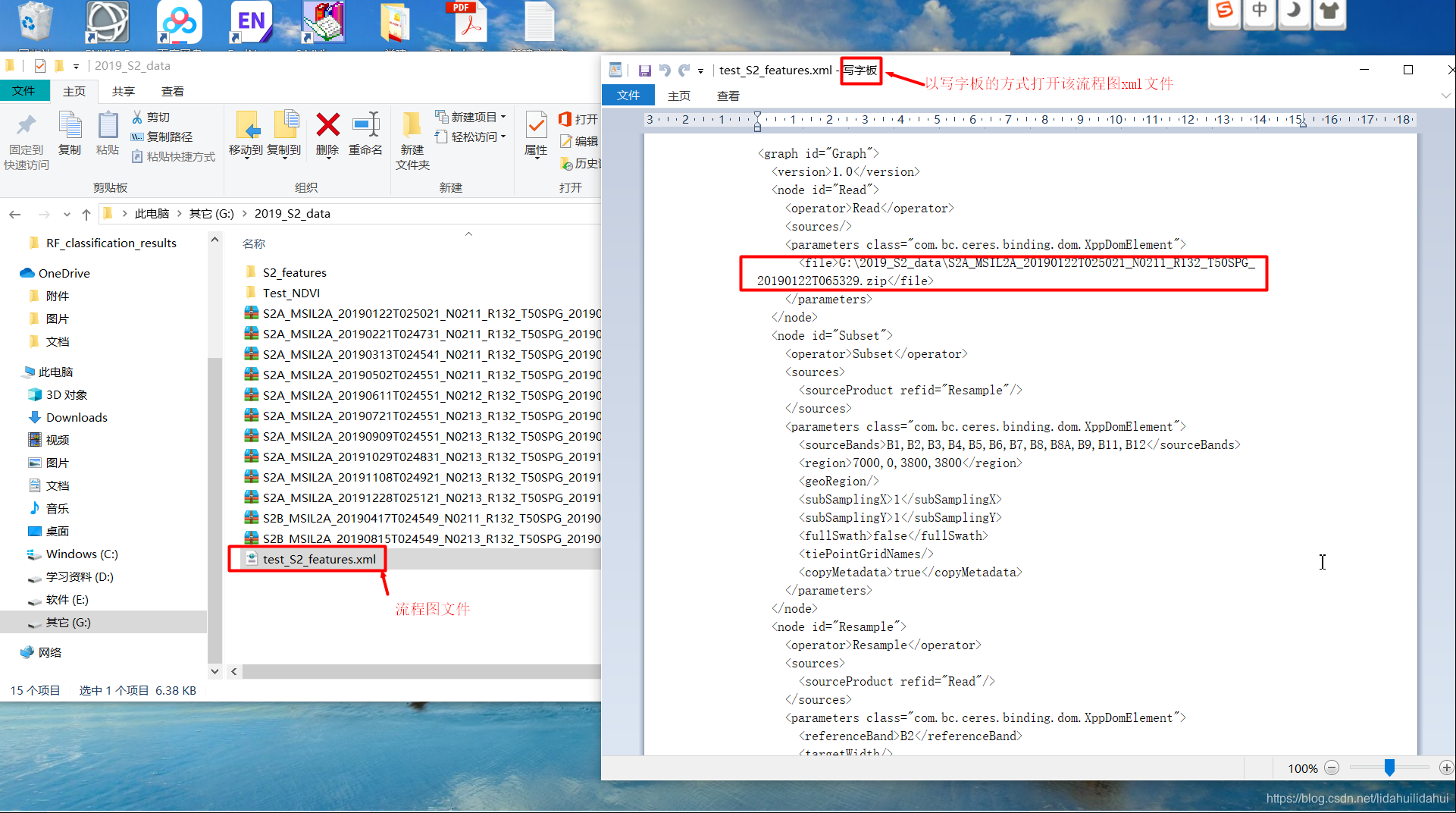
我们需要修改输入和输出节点的文件,设置gpt命令行-P参数变量:
对于输入节点<node id=“Read”>的<file>内容:
由:
<file>G:\2019_S2_data\S2A_MSIL2A_20190122T025021_N0211_R132_T50SPG_20190122T065329.zip</file> 改为:
<file>$input</file>
gpt命令行-P参数变量,由美元符$开头指示,input是其变量名。
即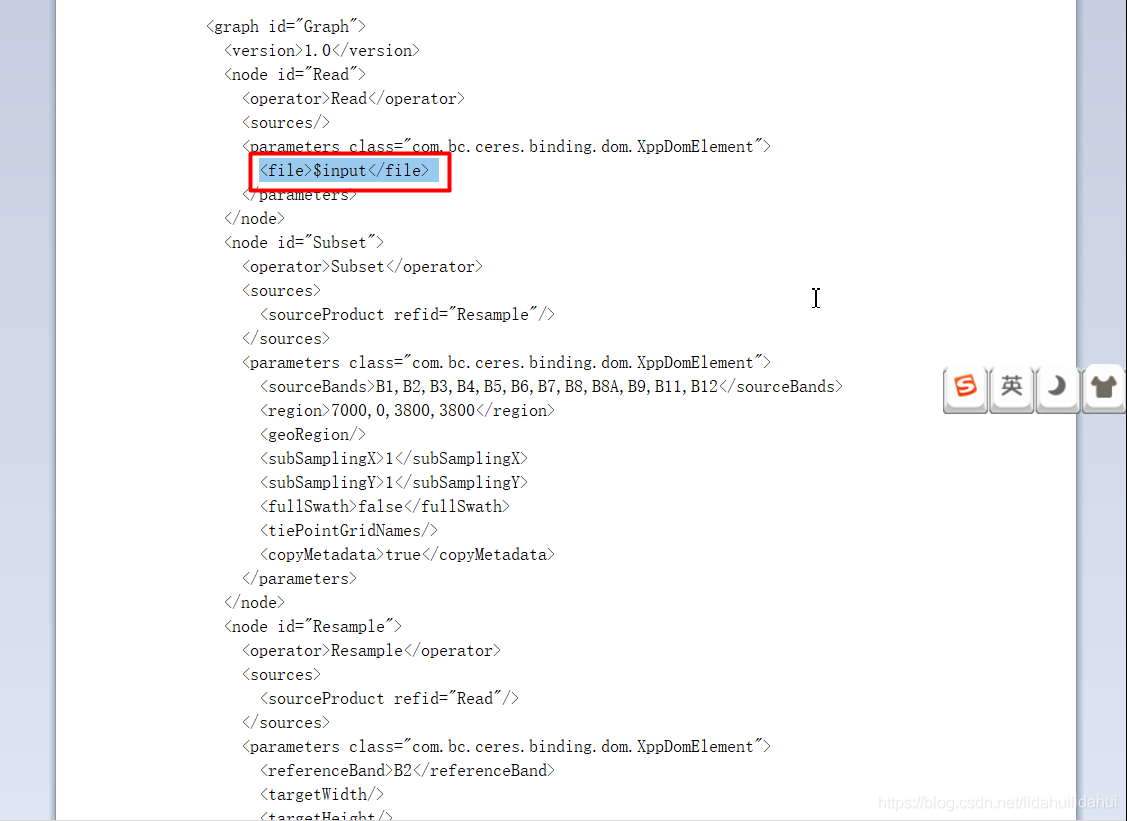
对于输出节点<node id=“Read”>的<file>内容: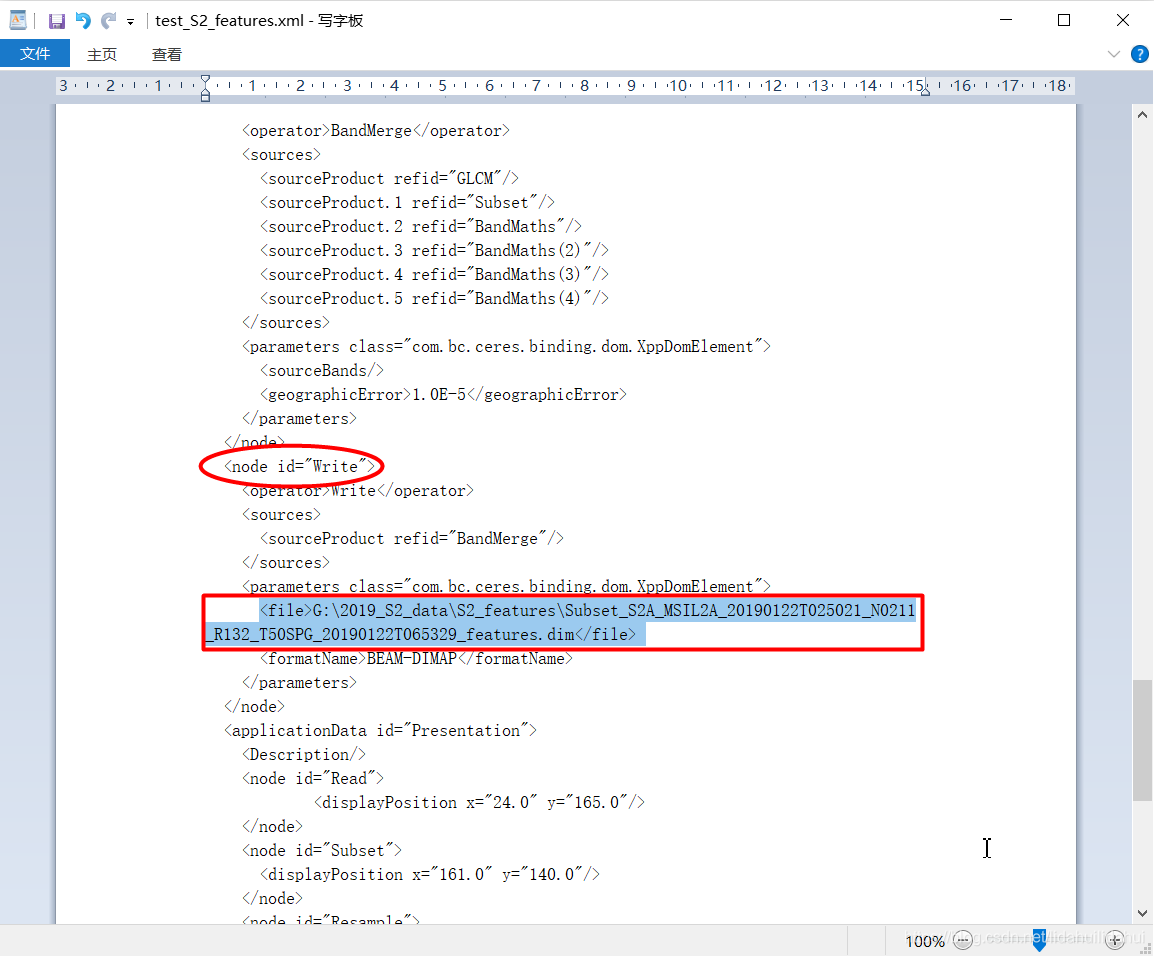
由 <file>G:\2019_S2_data\S2_features\Subset_S2A_MSIL2A_20190122T025021_N0211_R132_T50SPG_20190122T065329_features.dim</file> 改为:
<file>$output</file>
gpt命令行-P参数变量,由美元符$开头指示,output是其变量名。
即: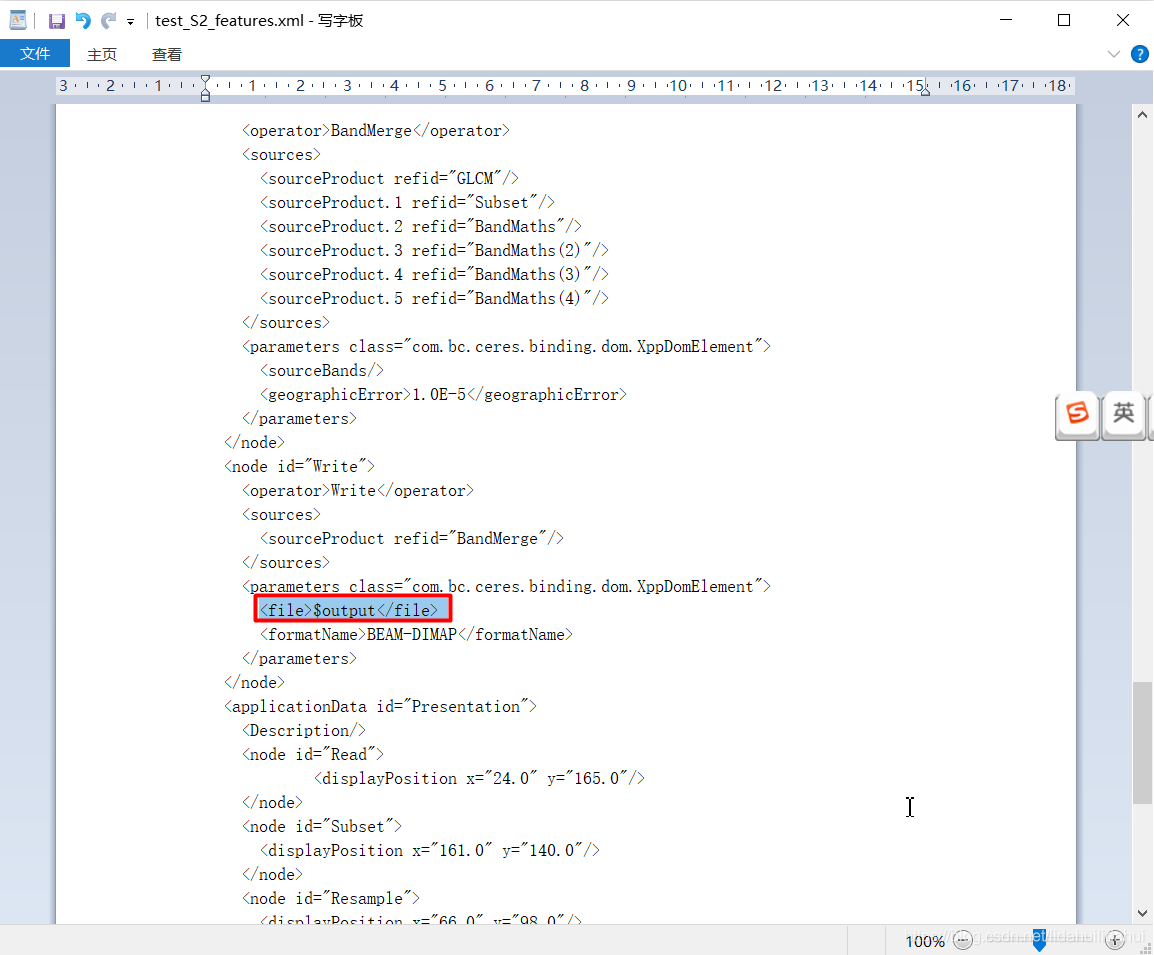
(尽管这里只把gpt命令行工具-P参数变量定义了输入文件和输出文件变量,但是你可以借助美元符$将流程图的任意参数定义为-P参数变量,例如你可以可能需要定义输出数据的分辨率、选择输出的波段、坐标系统等。)
完成这两处的修改后,关闭该xml文件,到源数据目录下启动一个PowerShell窗口:
注意,批处理先要进入windows标准命令行窗口(先输入cmd)
然后输入下面一句命令:
# 你可能需要结合实际调整一下你的输入目录和输出目录
# /r "G:\2019_S2_data" 表示迭代目录
# %X 表示设置的迭代变量,即某个(.zip)文件名的绝对路径
# G:\2019_S2_data\test_S2_features.xml 表示要处理的流程图文件的绝对路径
# -Pinput=%X 其中-Pinput表示流程图中input变量(-P参数变量),%X表示引用的文件名
# -Poutput="G:\2019_S2_data\S2_features\Subset_%~nX_features.dim" ,
# -Poutput表示流程图中的output变量(-P参数变量), G:\2019_S2_data\S2_features表示输出文件的父目录
# Subset_%~nX_features.dim 取出去掉文件名的后缀名.zip,
# 并加了前缀Subset_, 后缀_features.dim
for /r "G:\2019_S2_data" %X in (*.zip) do (gpt G:\2019_S2_data\test_S2_features.xml -Pinput=%X -Poutput="G:\2019_S2_data\S2_features\Subset_%~nX_features.dim")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
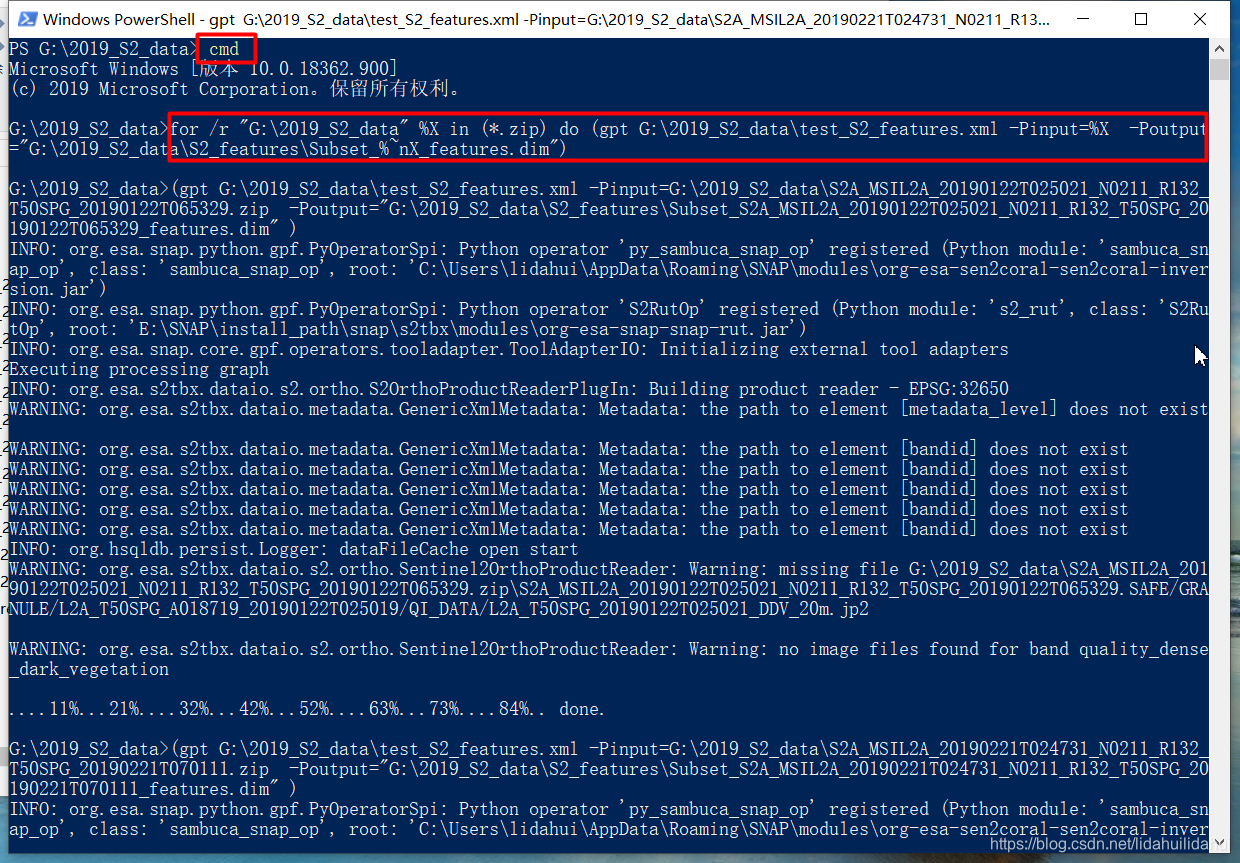
大概花费了半小时(12景数据),还算可以啦!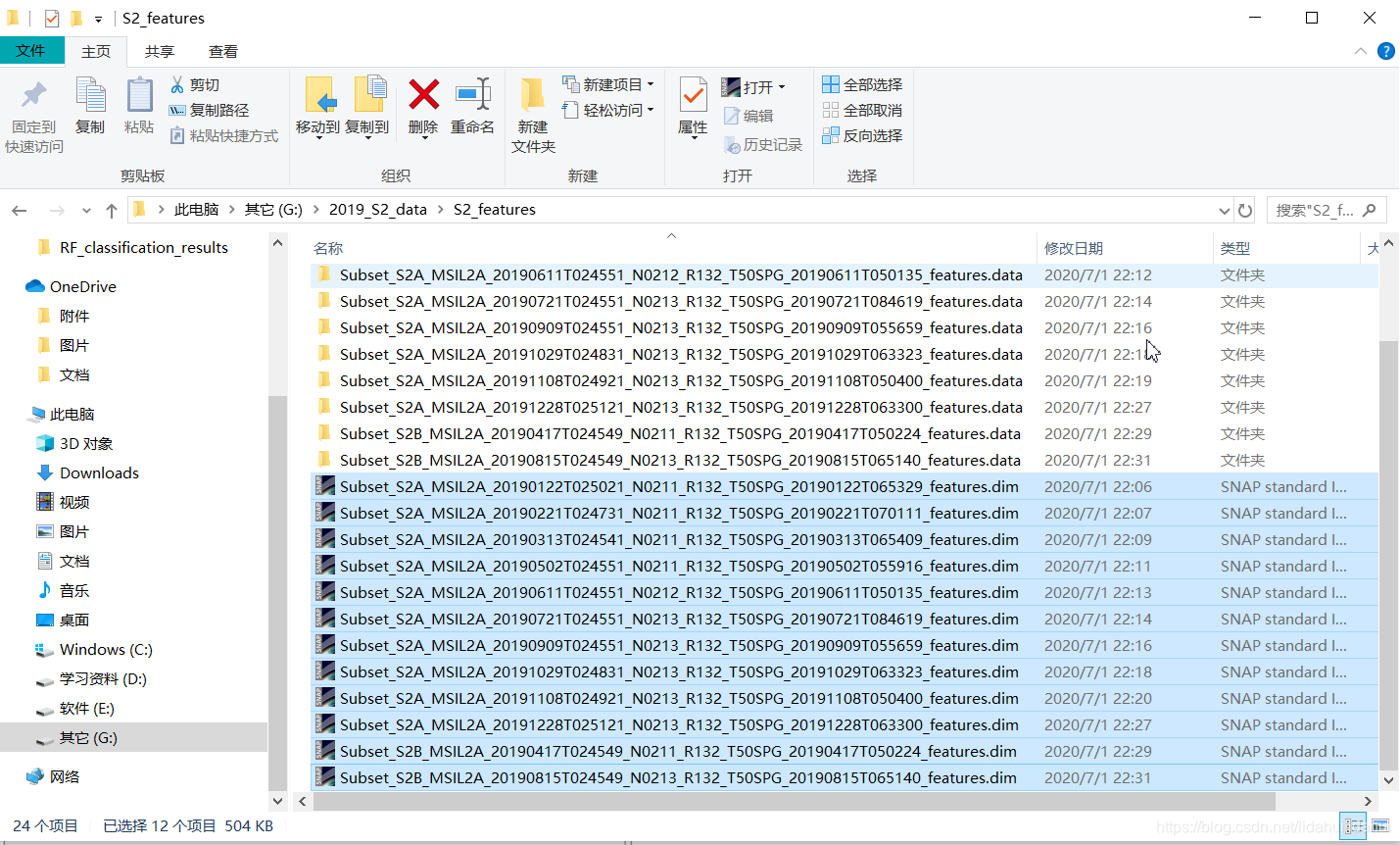
打开SNAP检查一下数据(很nice):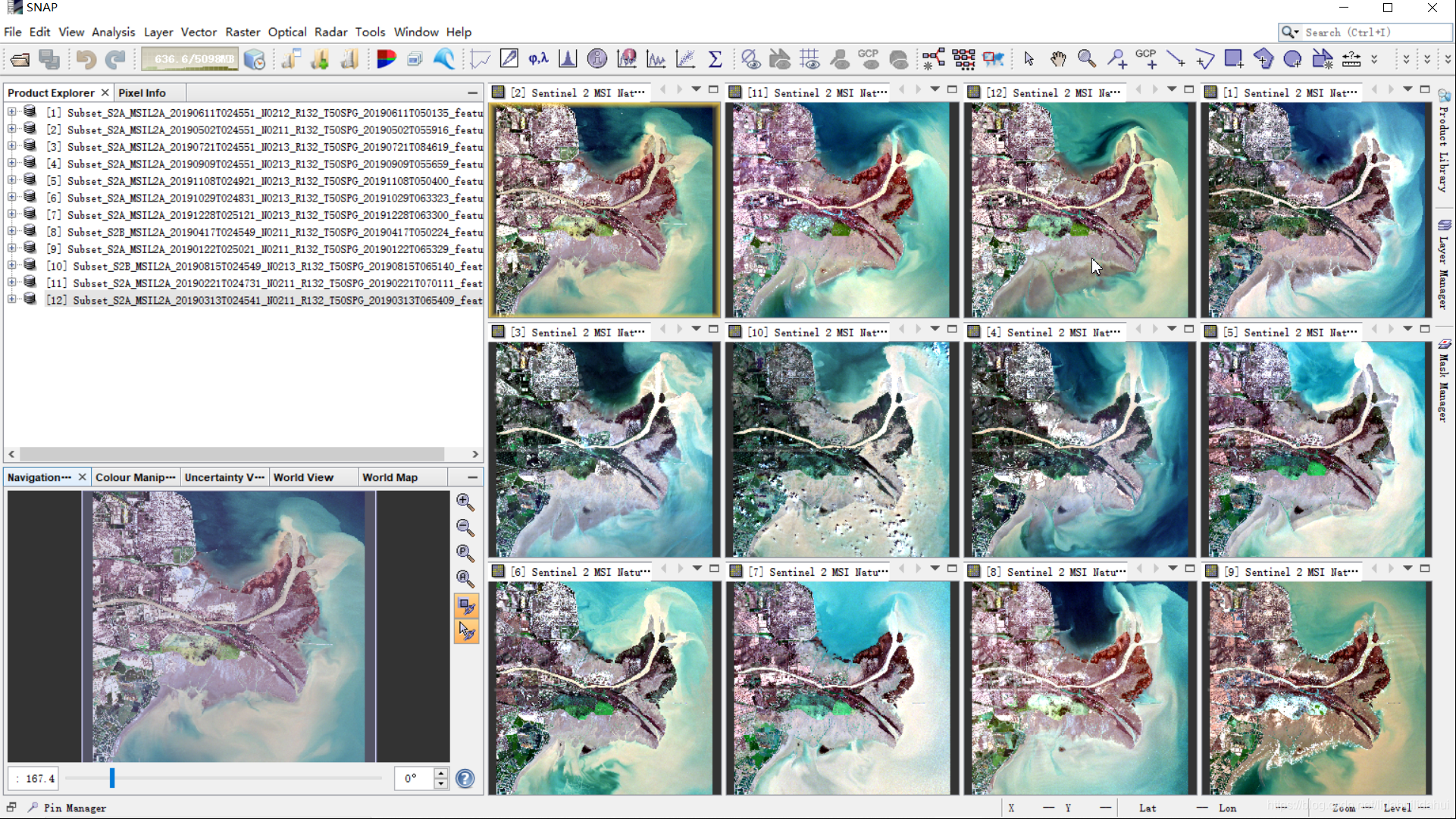
Sentinel-1 IW GRDH 数据集批量流程式处理
(由于这里是需要两景Sentinel-1 IW GRDH进行镶嵌,对运行内存要求较高,我估算了一下,8G运行内存的电脑可能比较吃力,16G运行内存的电脑应该是没有问题的,另外,你需要确保保存数据目录有足够的存储空间,Sentinel-1的数据通常很大,这里镶嵌后的一景约5G大小)
同样,如果你需要对Sentinel-1 IW GRDH数据做同样的处理,定义gpt命令行工具的输入和输出的-P参数变量(当然,还可以有其它的-P参数变量)。
这次博主使用的流程图见07篇 博客方式3:TOPSAR技术镶嵌,该流程图比较复杂,如下: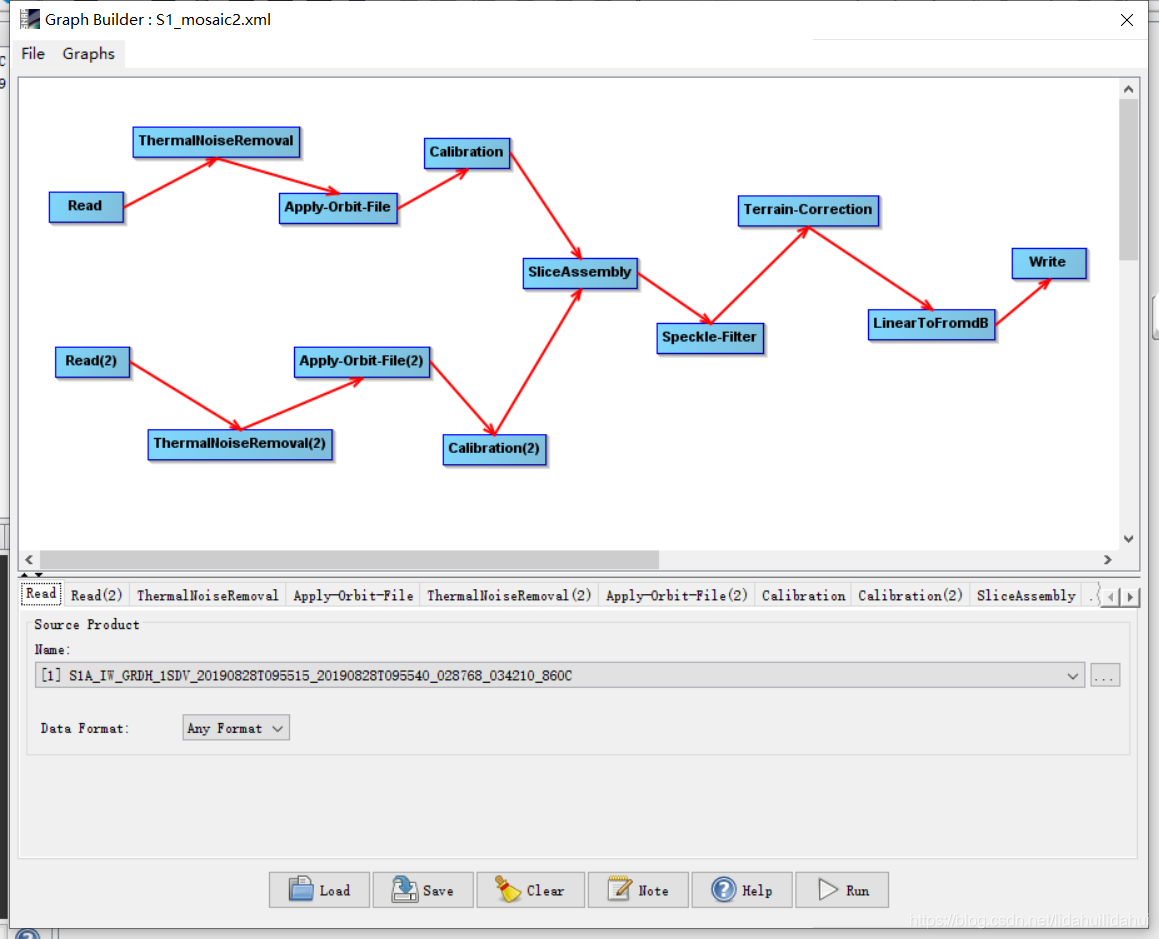
(有两个输入,1个输出,该流程图的参数与07篇 博客方式3:TOPSAR技术镶嵌,这里不再重复赘述了)
因为需要由同一天相邻的顺轨上下两景Sentinel-1 IW GRDH影像来合成覆盖整个上海市范围的影像,这就会带来烦恼,如何在批量的数据集中确保镶嵌时的刚好对应的是同一天相邻的顺轨上下两景?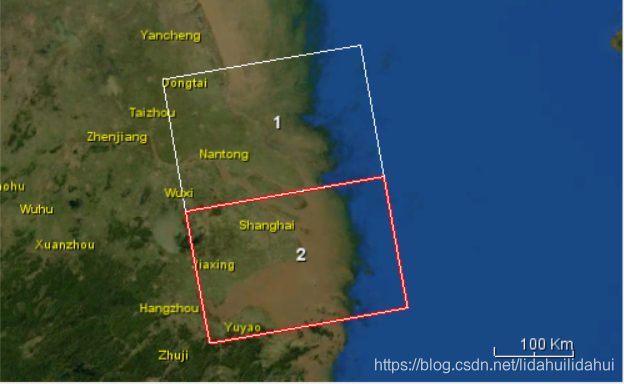
但是,要是在命令行中迭代两个变量会麻烦一些,并且提取文件名信息也有点麻烦!我并没有找到合适的cmd命令,但是,的确要办法实现的,结合C语言毫无疑问是可以实现的。除了这个麻烦,还可能还有一个麻烦,就是gpt的占用内存不能及时释放的问题,导致程序变慢甚至报错。
考虑到后面要介绍snappy,这里使用Python调用cmd命令,优雅地实现这个批量处理。Python中众多很方便的库包,我们仅用标准库即可。关于gpt的内存释放问题,这里使用的一种技巧是杀死进程,强制释放JVM(java虚拟机)的内存。即每一次调用cmd进程,执行完命令后,关闭该cmd进程,再新启动一个cmd进程处理。
思路已有,接下来。我们需要修改流程图文件(这里文件名为:S1_mosaic2.xml),定义3个-P参数变量:
节点<Read>:
由:
<file>G:\test\S1A_IW_GRDH_1SDV_20190828T095515_20190828T095540_028768_034210_860C.zip</file>
改为:
<file>$input1</file>
gpt命令行-P参数变量,由美元符$开头指示,input1是其变量名。
节点<Read(2)>:
由:
<file>G:\test\S1A_IW_GRDH_1SDV_20190828T095515_20190828T095540_028768_034210_860C.zip</file>
改为:
<file>$input2</file>
gpt命令行-P参数变量,由美元符$开头指示,input2是其变量名。
变动前: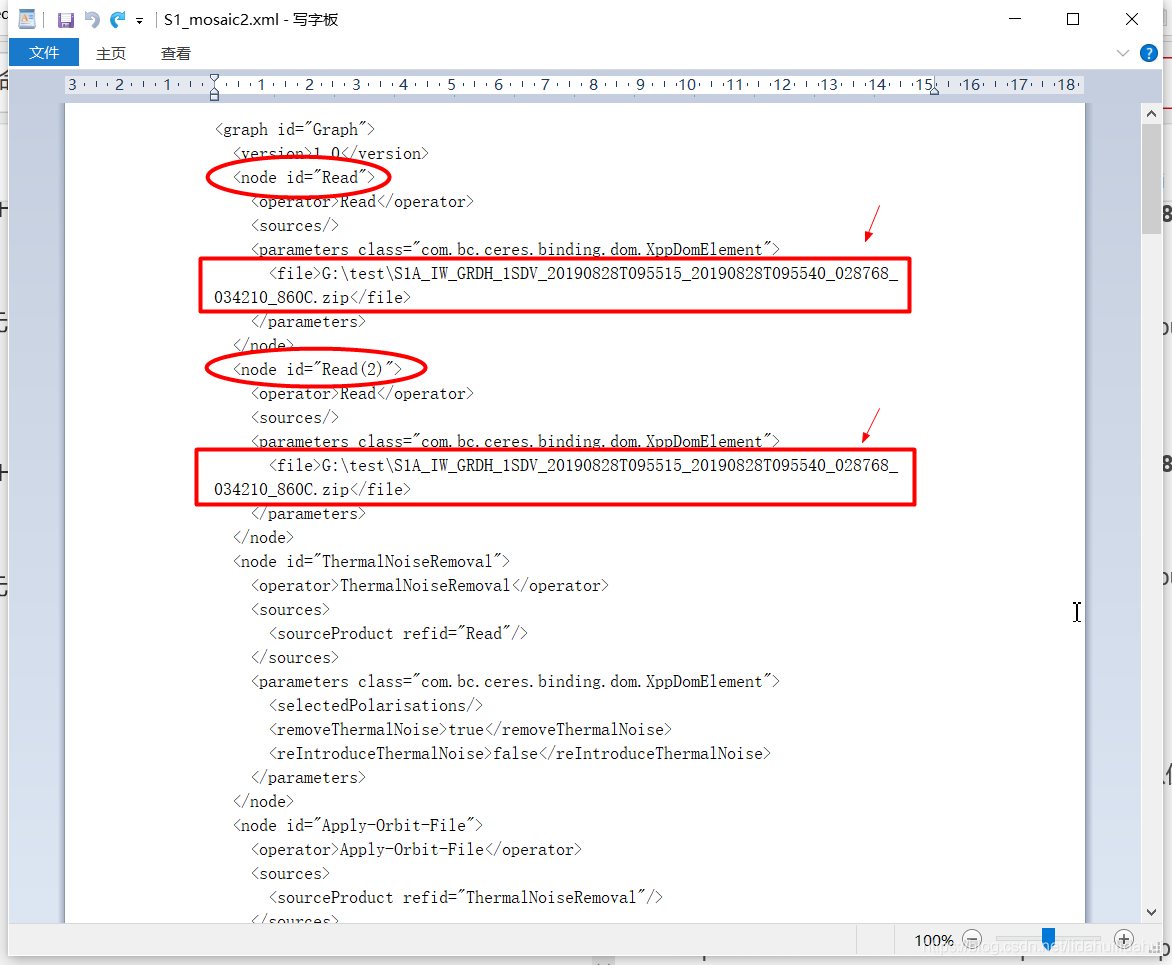 变动后:
变动后: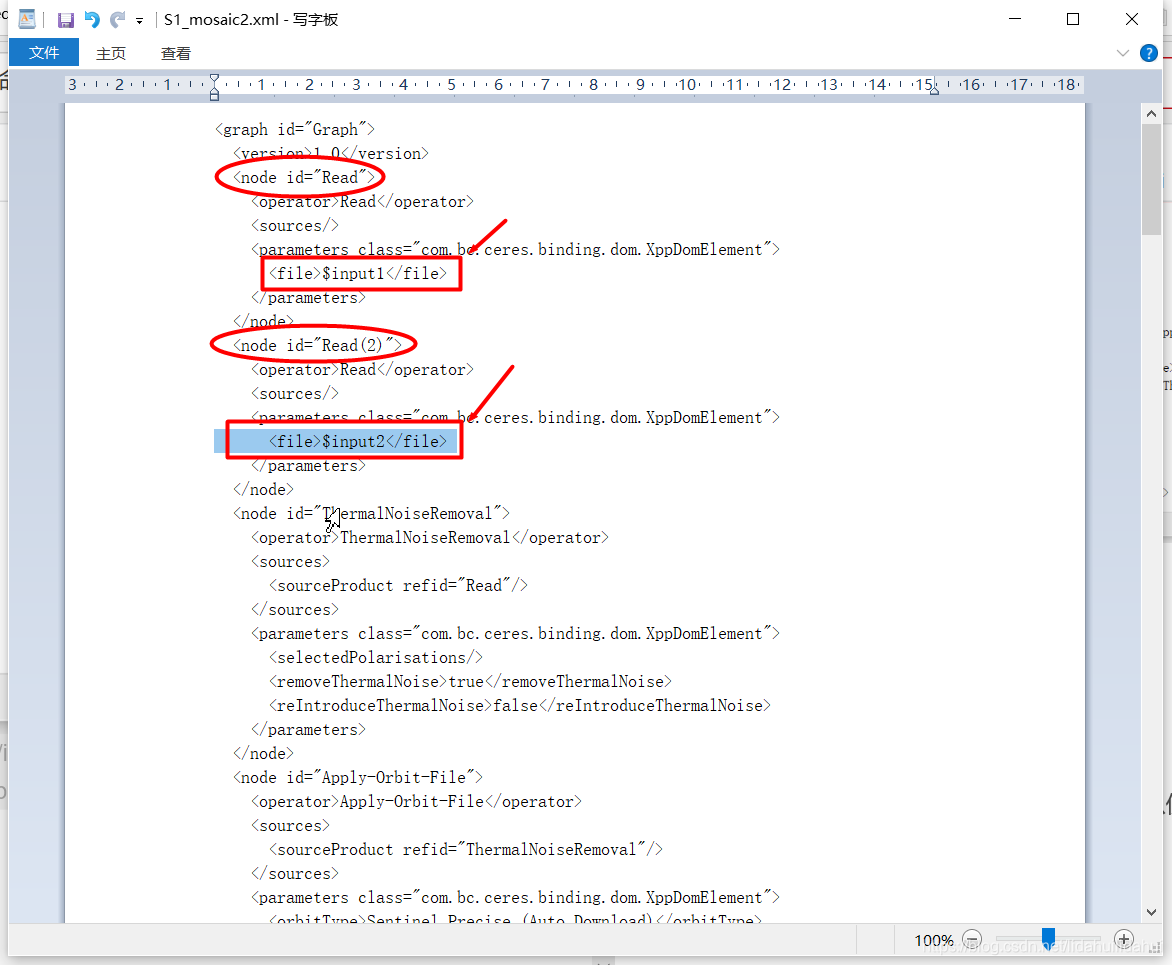
节点<Write>:
由:
<file>G:\test\S1A_IW_GRDH_1SDV_20190828T095515_20190828T095540_028768_034210_860C.zip</file>
改为:
<file>$input2</file>
gpt命令行-P参数变量,由美元符$开头指示,input2是其变量名。
变动前: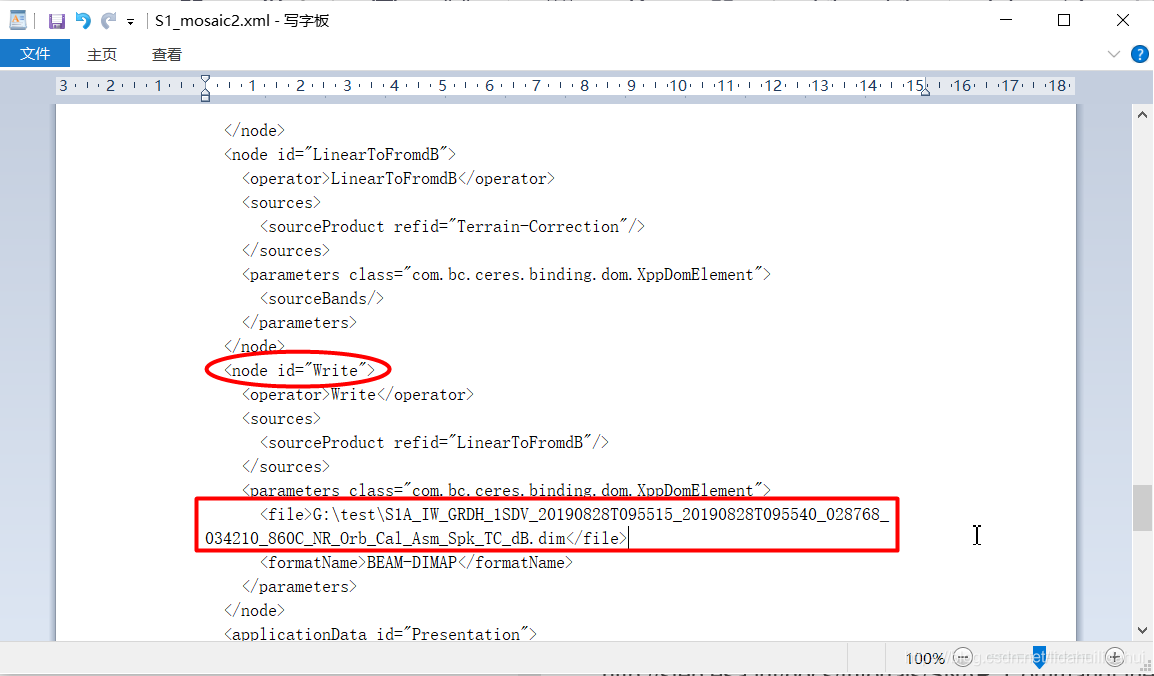
变动后: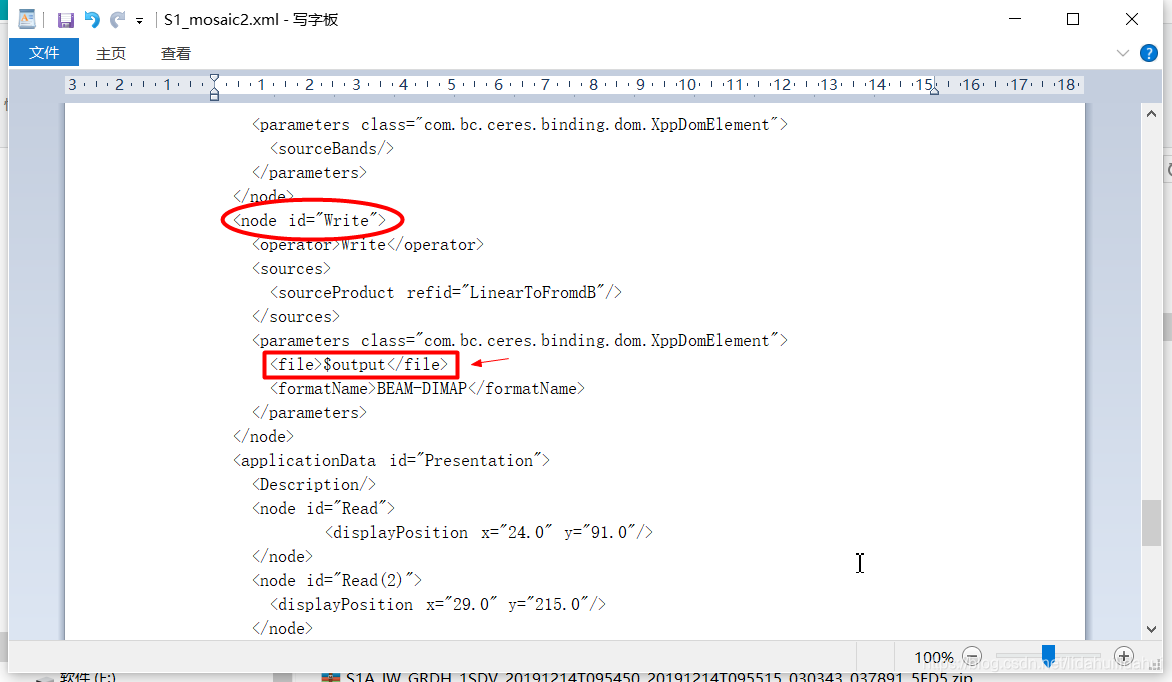
OK! 修改完毕!万事俱备,只欠东风!
(实际代码是不长的,博主加了详细的注释,应该是不难理解的。另外,在此之前,一定要检查C盘是否有足够的存储空间,至少应该要有20G,在前面gpt命令行操作过程中应该。以下代码可能你还需要更改输入、输出路径和输出文件名前、后缀名)
# -*- coding: utf-8 -*-
# Author: 超级禾欠水
# Python 3.6.7 win64
# 导入相关库
import os
import glob
import subprocess
import time
# Sentinel-1 IW GDRH元数据压缩包存放目录,输入目录
data_path = r'D:\temp_SAR'
# 保险起见, 对找到的元数据(.zip)按文件名进行排序
# 这样同一天的影像相邻的
datas = sorted(glob.glob(os.path.join(data_path, '*.zip')))
# 流程图文件路径
xml_file = r'D:\temp_SAR\S1_mosaic2.xml'
# 输出目录
output_path = r'D:\temp_SAR\Sentinel_1_processed'
# 将同一天的两景影像分别存于两个列表part1_datas, part2_datas
# 因为排序过文件名,可以确定同一天相邻的两景影像分别存于两个
part1_datas = datas[::2]
part2_datas = datas[1::2]
for input1, input2 in zip(part1_datas, part2_datas):
# 获取输入文件的文件名
basename_input1 = os.path.basename(input1)
# 提取日期时间
date = basename_input1.split('_')[4][:8]
# 打印日期
print("date:", date)
# 输出的文件名, 后缀名'.dim'表示这里使用SNAP的标准文件格式(BEAM-DIMAP)
out_file = 'S1_Shanghai_' + date + '.dim'
# 输出文件的绝对路径
output = os.path.join(output_path, out_file)
# 要调用的命令行参数列表
command = ['gpt', xml_file, '-Pinput1=' + input1,
'-Pinput2=' + input2, '-Poutput=' + output]
# 如果你想看实际的命令行窗口命令可以取消下面print语句的注释
#print(' '.join(command))
# 以“杀死进程”的方式调用cmd(windows标准命令行窗口)
# 相当于在命名行执行命令“gpt xml_file -Pinput1=input1 -Pinput2=input2 -Poutput=output”
subprocess.check_output(command)
# “以退为进”----分布式爬虫的处理“哲学”,休眠30s,等待释放内存
# 避免gpt因为内存不能及时释放,拖慢程序运行或者导致出错
time.sleep(30)
print("All done!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
只需在python中执行该程序就可以(你应该可以听到你电脑的“唰唰唰”的风扇,因为CPU的利用率很可能飙升到100%,要知道gpt默认调用所用CPU核来计算,你电脑有多少个,便调用多少个核)。
Pycharm中的运行界面(大约25分钟的时间得到一景镶嵌后的上海市全境影像, 由于数据量很大,需要耐心等待一下):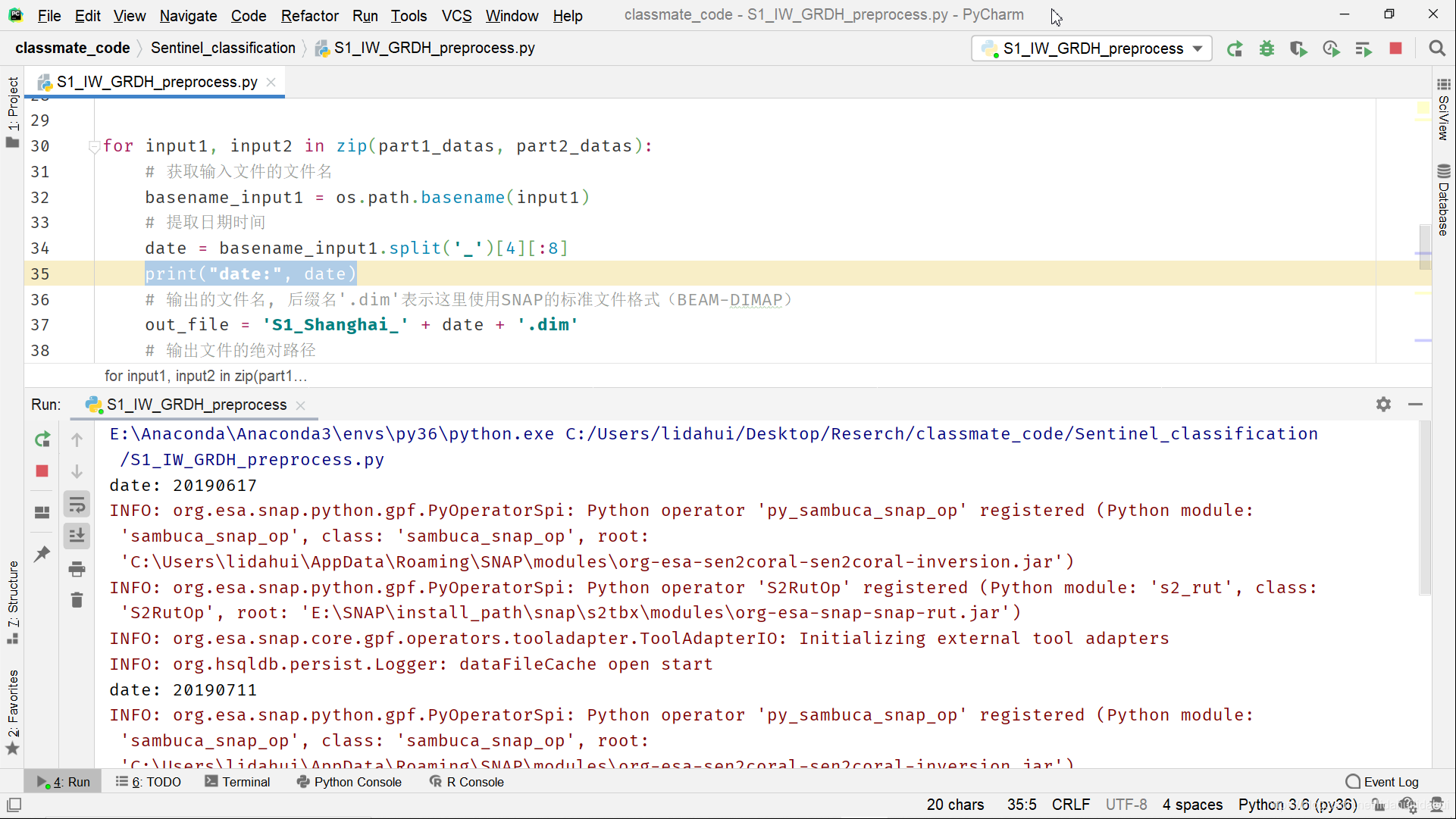
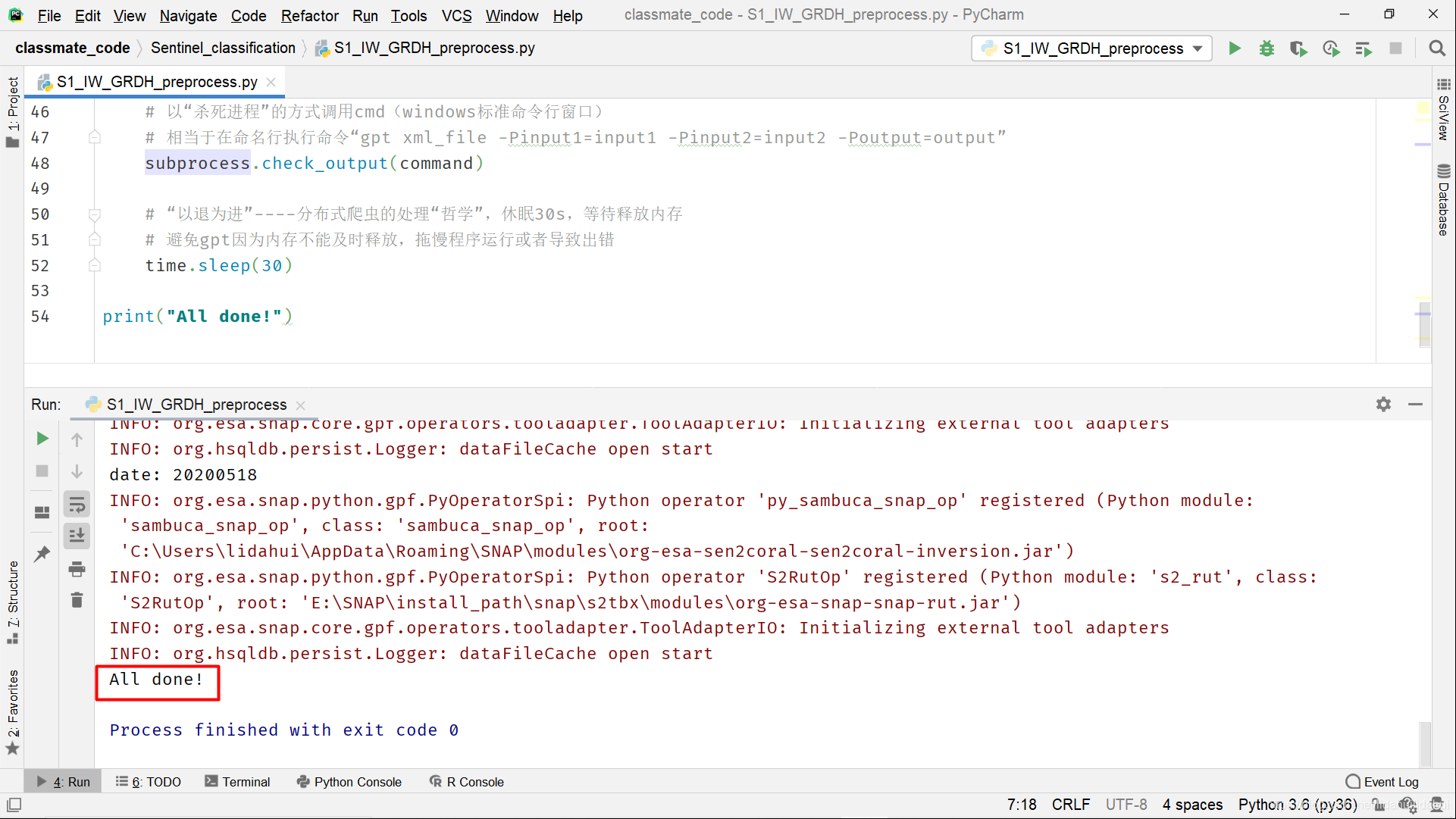
最终可以得到12景覆盖上海市的Sentinel-1 IW GRD影像(2019年6-2019年5月,每月一景),总共耗费了5小时多的时间: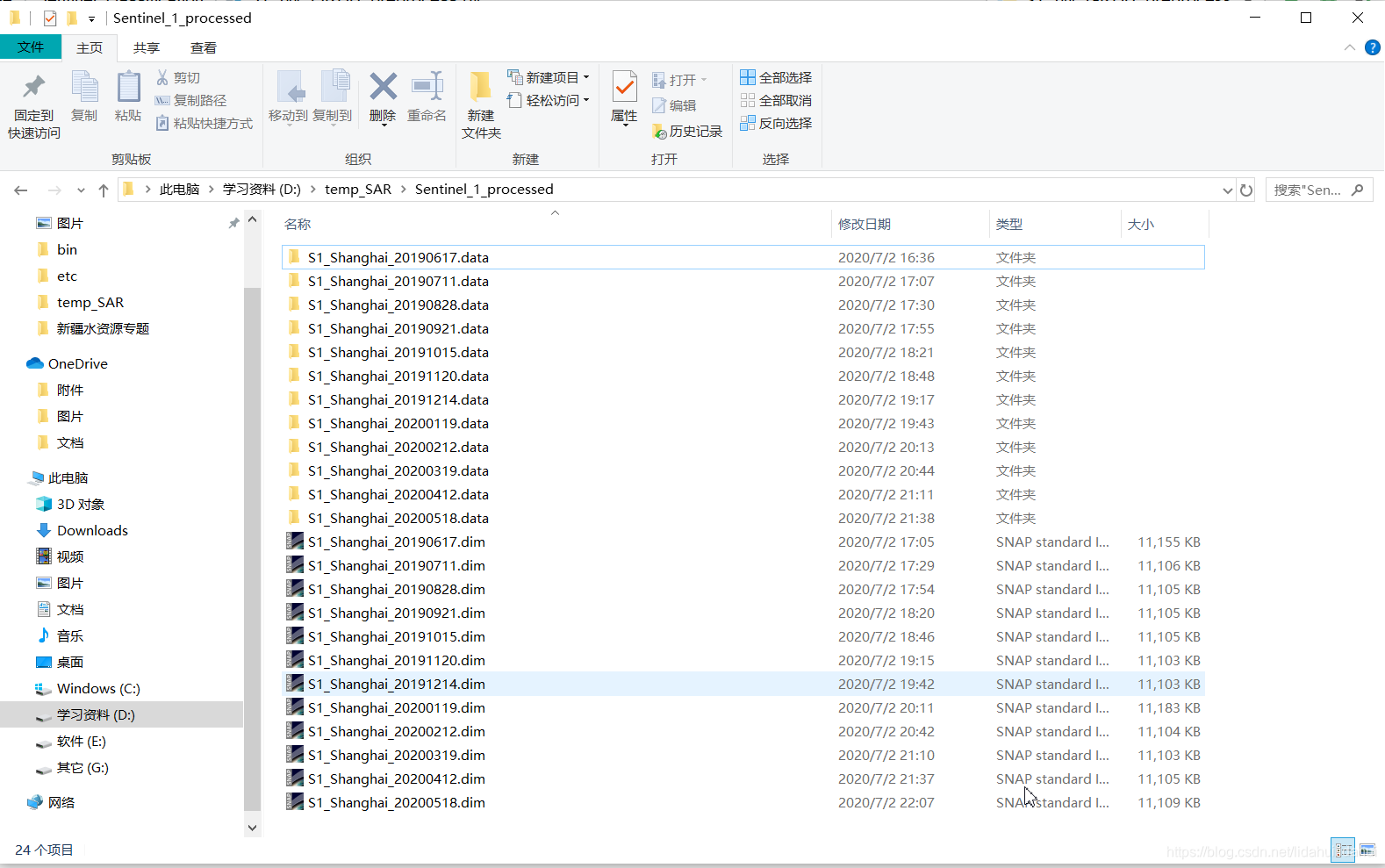
导入SNAP看下结果(这里打开4景VH通道来看看):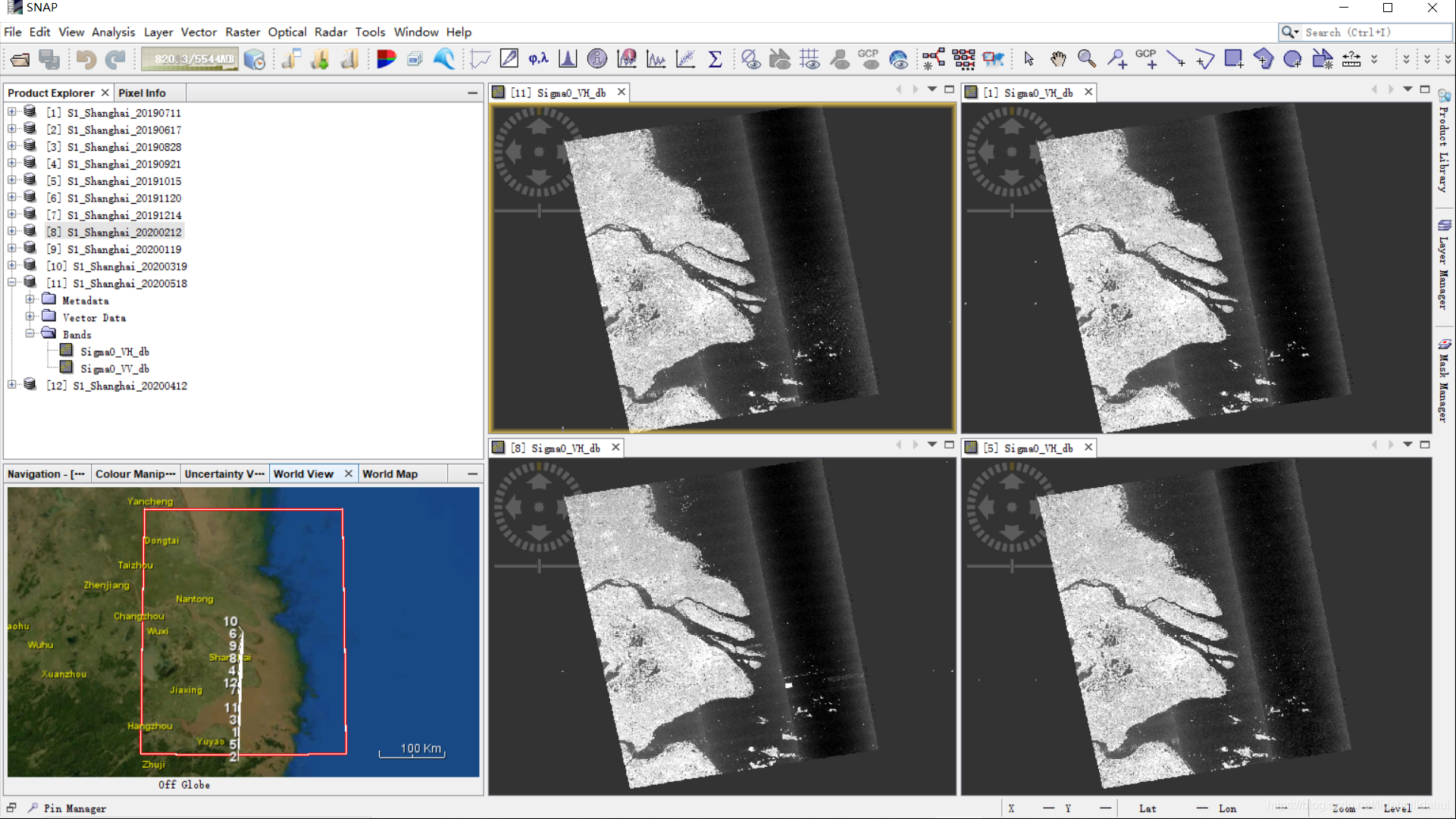
OK !正确无误!
类似于前面的Sentinel-2 NDVI时序曲线,一旦我们有了多景Sentinel-1影像数据,我们同样可以轻易获得其SAR后向散射系数时序曲线(我这里想演示12景的时序曲线的,但是比较卡,因为整个上海市范围内的数据量太大了,约60G, 这里演示4景的)。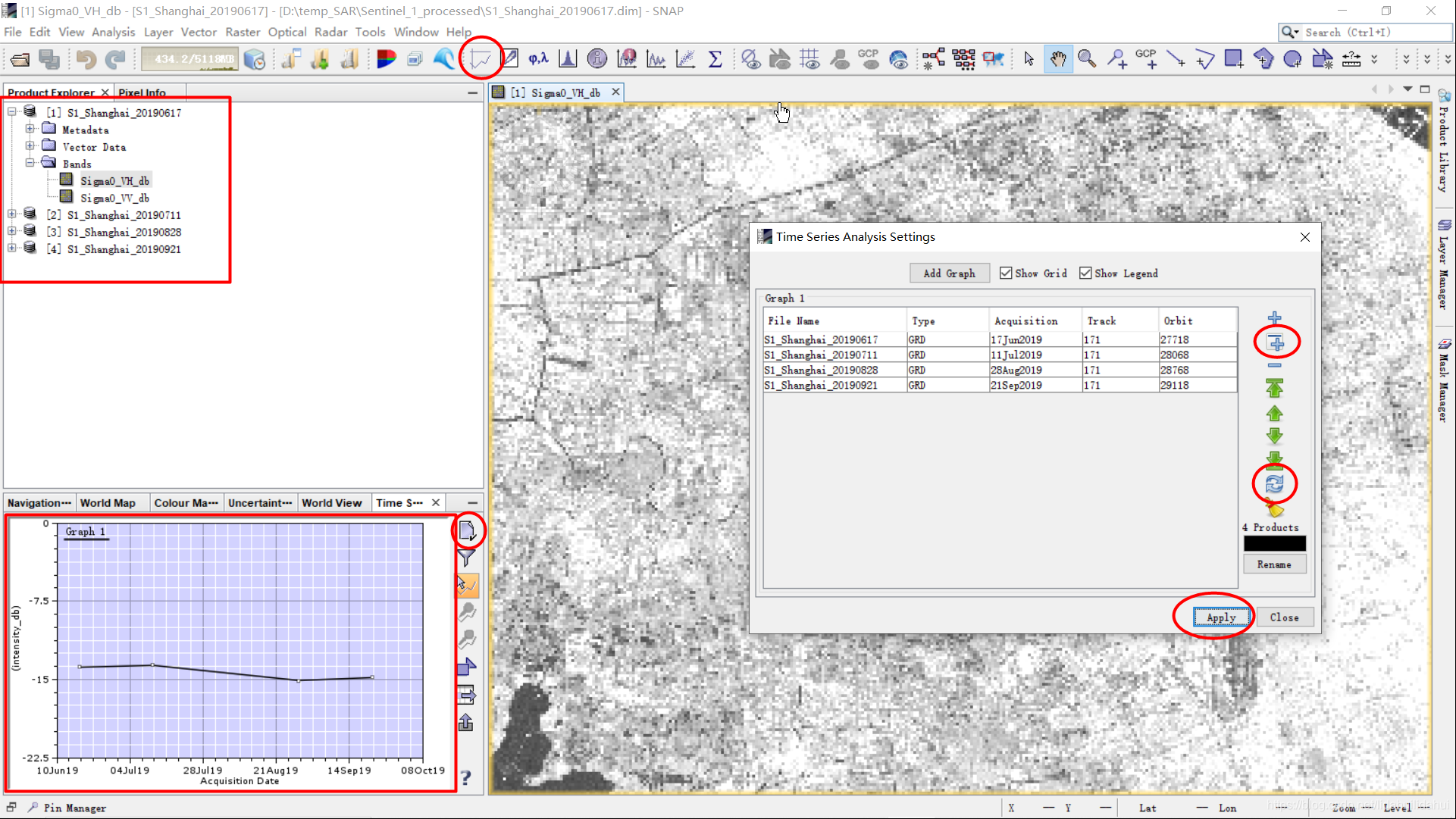
证明了我们的操作是无误的!See you!
后语
希望你能认识到SNAP的gpt命令行常见用法,以便高效地完成哨兵数据的处理。本文虽然只是介绍一些基本的操作,但是,SNAP可以做到更多的。事实上,SNAP完成不少卫星数据的处理,并不是只能处理Sentinel系列卫星(像landsat、Modis、ALOS、ENVISAT等都可以),只是处理Sentinel卫星是其优势所在。
尽管本文没有提及更高级的处理技术,例如多进程、分块处理等,但是,这些在SNAP中保留了其接口,无论是gpt还是其python包snappy或者Java源码都是可以实现,当然别的编程语言也可以实现,只是相对而言,自己需要做更多的工作。下篇介绍snappy的一些基本知识,或许能加深你的一些印象!
最后,如果你对欧空局开源软件处理软件SNAP及其snappy开发处理感兴趣,可以加入博主创建的欧空局SNAP处理交流群:665903216(这个群已满人),欧空SNAP处理交流群(二):1102493346。
祝好!
参考文献
[1] SNAP Wiki博客gpt工具批处理介绍https://senbox.atlassian.net/wiki/spaces/SNAP/pages/70503475/Bulk+Processing+with+GPT
[2] SNAP Command Line Tutoriall http://step.esa.int/docs/tutorials/SNAP_CommandLine_Tutorial.pdf
[3] 张磊,宫兆宁,王启为,金点点,汪星.Sentinel-2影像多特征优选的黄河三角洲湿地信息提取[J].遥感学报,2019,23(02):313-326.
[4] 李鹏,黎达辉,李振洪,王厚杰.黄河三角洲地区GF-3雷达数据与Sentinel-2多光谱数据湿地协同分类研究[J].武汉大学学报(信息科学版),2019,44(11):1641-1649.