05-SNAP处理Sentinel-2 L2A级数据(三)
(原创文章,转载请注明来源!)
前言
上一篇博客制作一个用于上海市崇明岛(小部分属于江苏省)地物分类的Sentinel-2无云影像特征工程数据集,这次利用这个特征工程数据来进一步探索SNAP中的地物分类模块,主要涉及到无监督分类、样本制作、监督分类、掩膜等功能。
数据集
特征工程数据集见与04篇百度链接的文件是相同的:
链接:https://pan.baidu.com/s/1WfLrhjEFz3sT66StQ8pXZQ
提取码:1pya
使用的是Chongming_Island_data文件夹下的Final_result_data文件夹下的chongming_mosaic_stack.dim数据集。
chongming_mosaic_stack.dim数据集包含12个光谱特征,10个纹理特征,4个指数特征,合计26个特征,具体制作过程见04篇。
打开SNAP,并将文件chongming_mosaic_stack.dim拖入到SNAP中,即可打开该数据集,打开RGB真彩色(R:B4波段;G:B3波段;B:B2波段),效果如下:
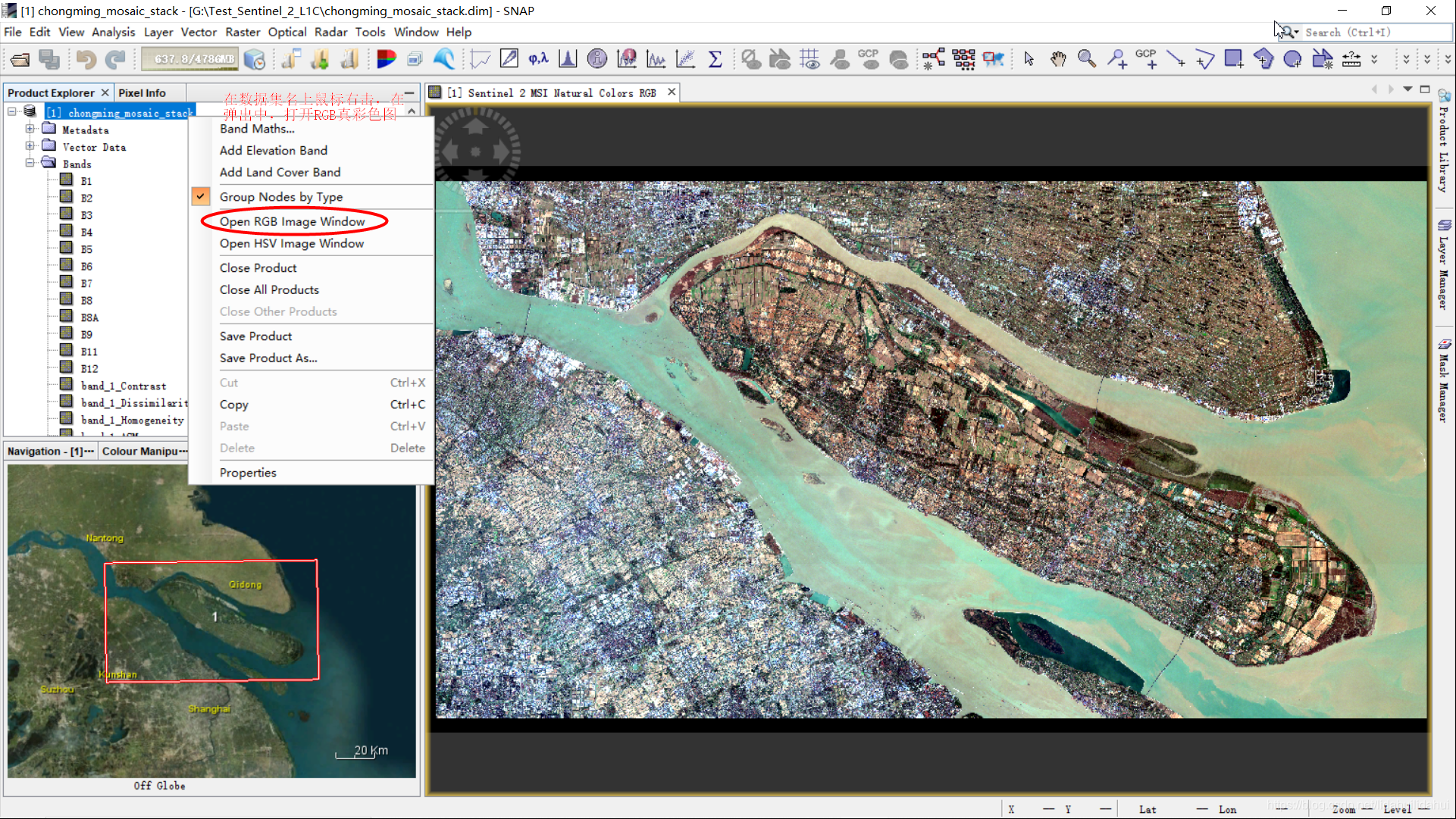
崇明岛简况
崇明岛与台湾岛、海南岛并称中国三大岛屿,同时它是中国最大的河口冲积岛,中国最大的沙岛[1]。全岛地势平坦,土地肥沃,林木茂盛,物产富饶,适宜各类需要量大的作物生长,如水稻、玉米等。根据上海市相关规划,上海市政府要把崇明岛建设成为现代化生态岛区。崇明区的工业、服务业相比上海市其它区域来说要差很多,该地区是上海市的重要农产品(瓜、果、蔬菜、粮食等)来源。
无监督分类
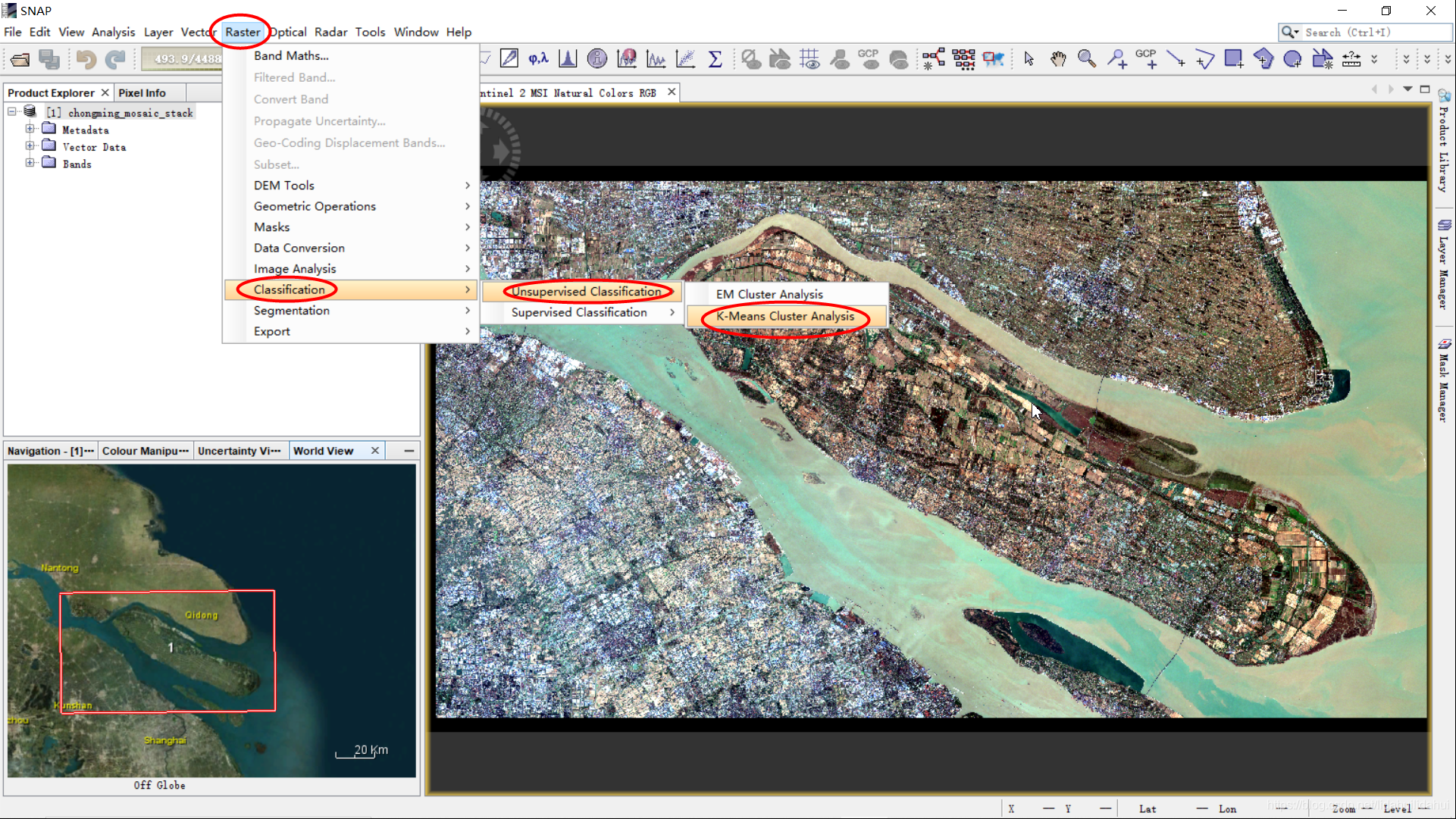
无监督分类也可以称为聚类,是指对不加标签的数据特征进行分类,可以看作“让数据自己介绍自己”的过程。其分类结果只是对不同类别达到了区分,但并不能确定类别的属性,其类别的属性是通过分类结束后目视判别或实地调查后确定[2]。无监督分类不需要训练样本集。SNAP(V6.0)的无监督分类算法目前只有K-Means和EM两种分类算法,其具体原理请查阅机器学习有关的书籍。这里以K-Means算法为例,简单介绍一下SNAP中无监督分类过程:
准备好数据特征集好,在下图位置打开K-Means Cluster Analysis工具:
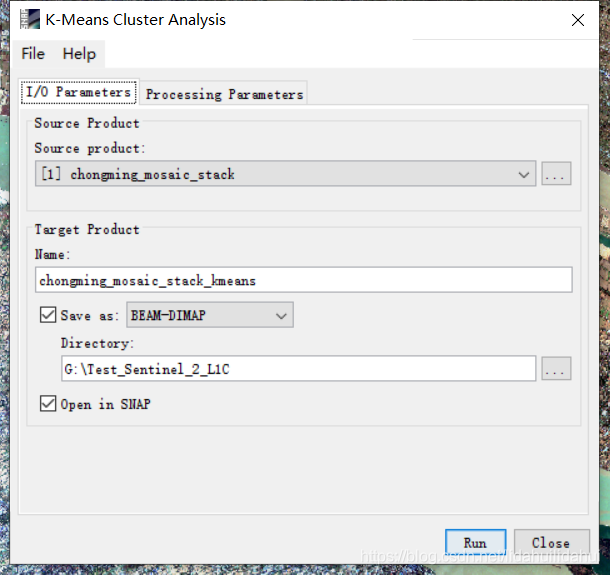
输入输出参数面板,修改或者保持默认即可(这里保留默认值)。
参数面板设置,说明见下图:
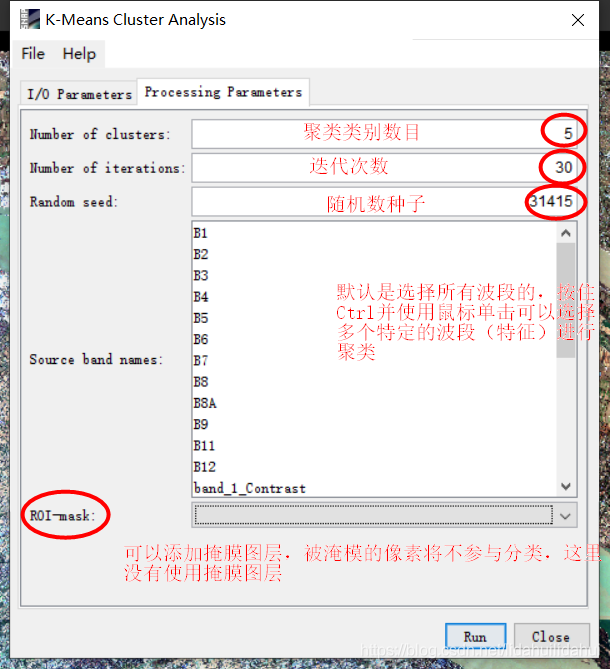
这里选择的聚类类别数目(Number of clusters)是5;算法迭代次数(Number of iterations)是30次;随机数种子(Random seed)设置为31415(系统默认值),你可以修改为别的整数;Source band names选择了所有的波段(也就是默认的情况);ROI-Mask这里设置为空。设置好参数好,点击Run。K-Means分类过程耗费的时间和你设置的参数和分类数据集数据量大小都有关,一般分类类别数目和迭代次数波段数目越大,耗费的时间越长。
点击Run,大约45分钟后,分类结束。看下结果:
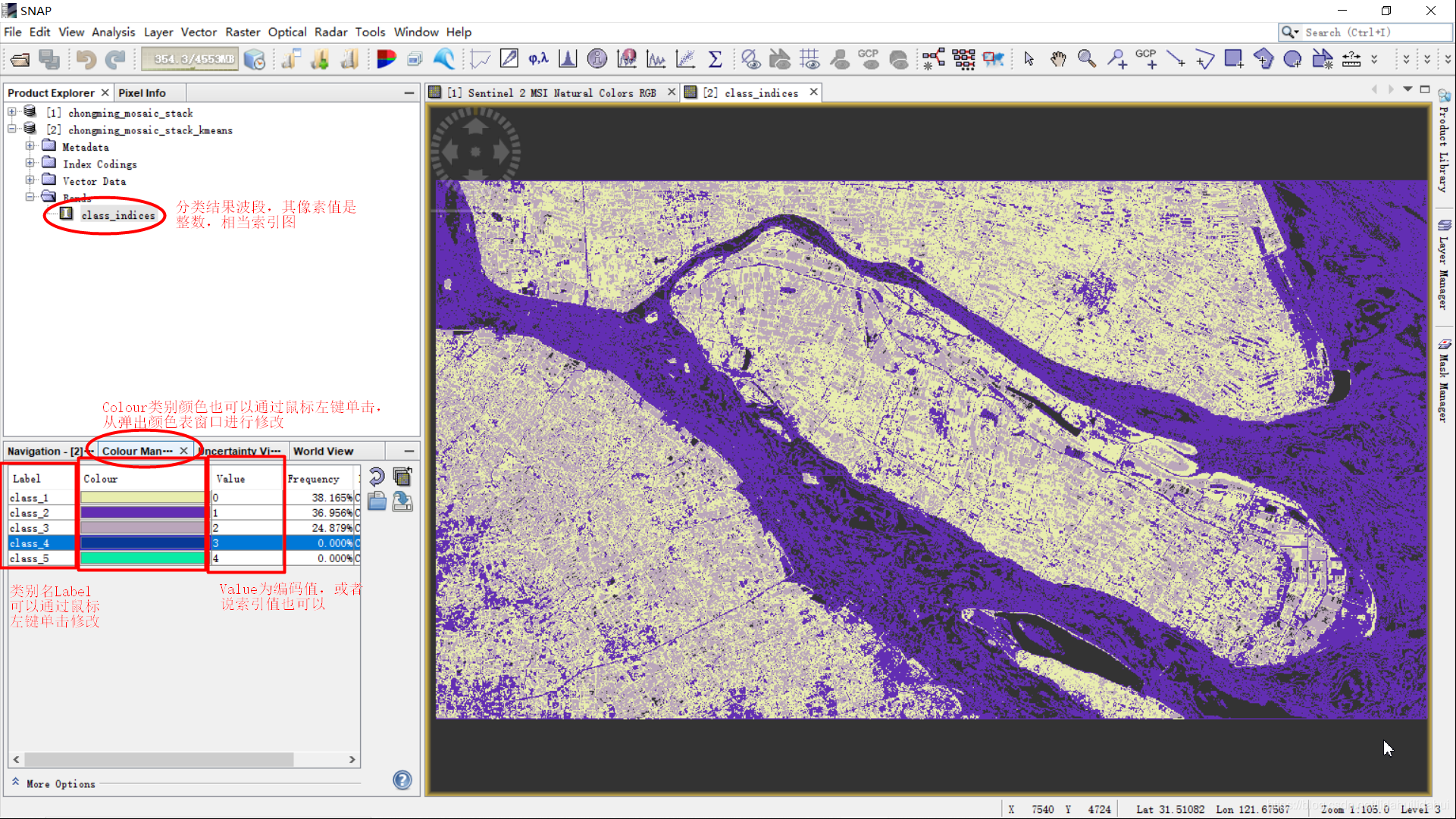
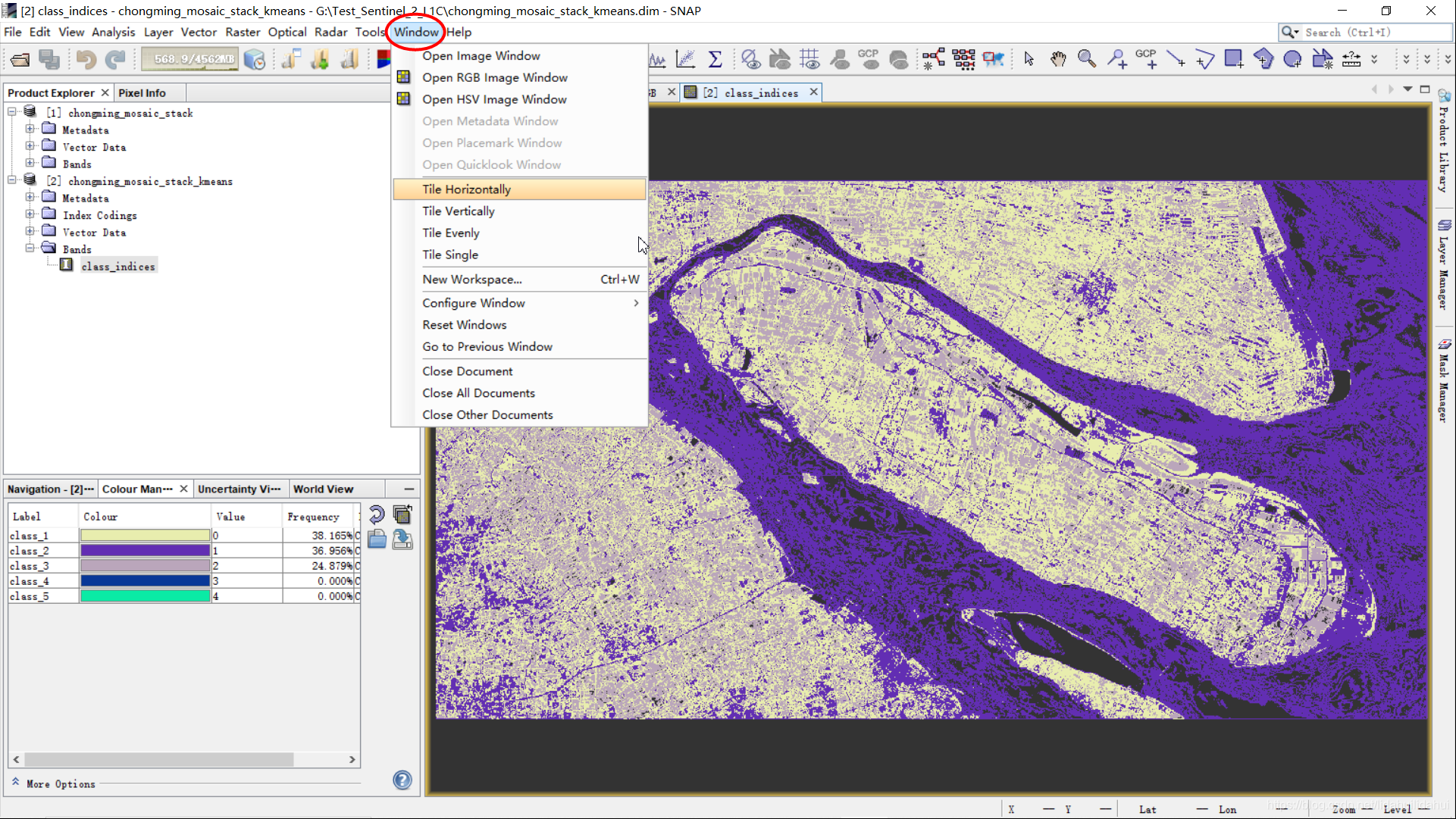
将分类结果和RGB真彩色图水平分屏对比显示,选择Windows—>Tile Horizontally:
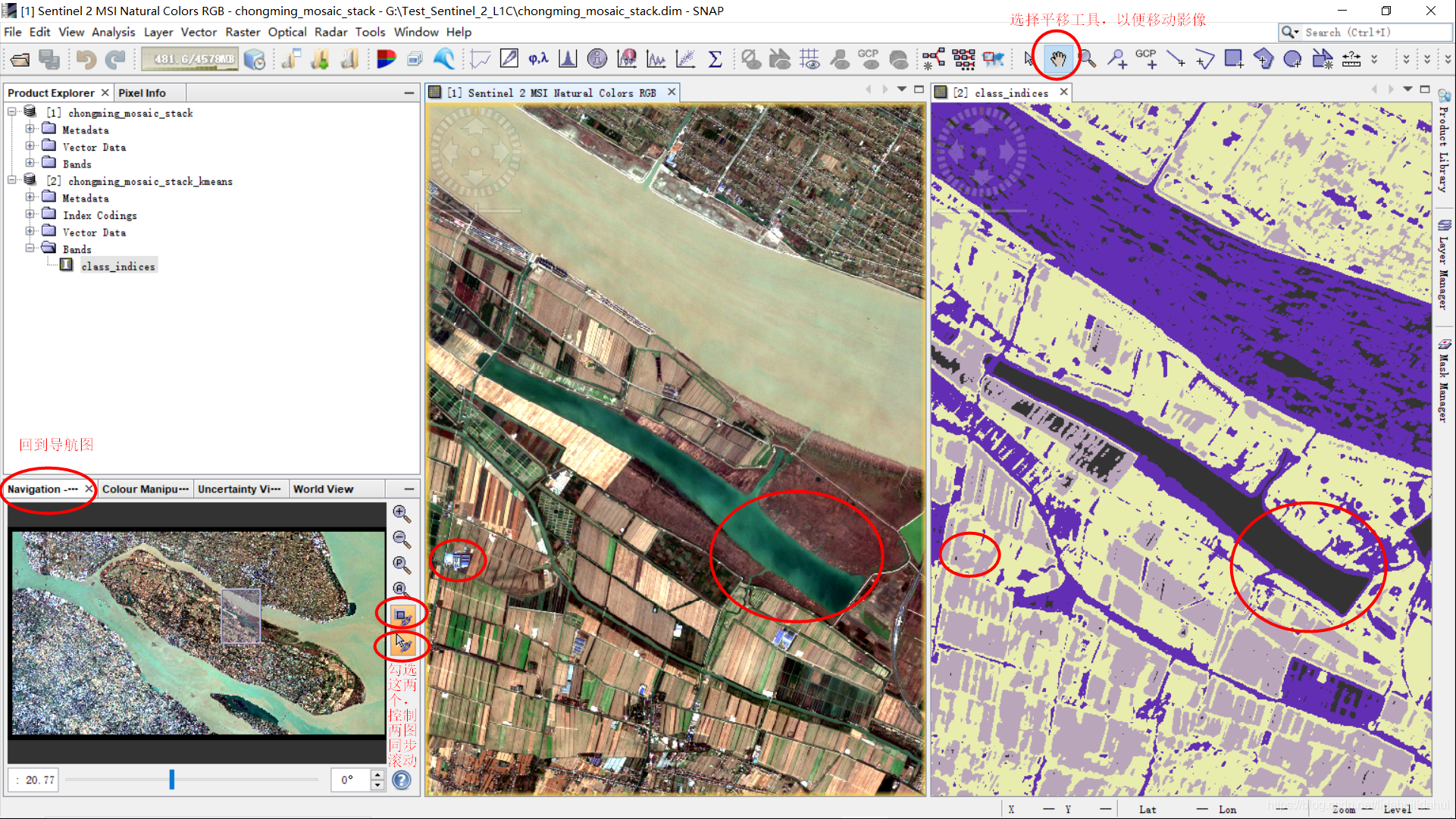
图中某处位置,可以看到分类结果是比较差的(大红圈中的水体存在混淆,小红色圈建筑没有识别出来等):
可以看到无监督分类结果不理想。不过,博主在这个K-Means分类时,并不严谨,因为各个特征的量纲和数量级不一样,这里是需要对特征数据集进行标准化。K-Means是基于某种距离进行分类(SNAP中使用的欧式距离,参考该算法的帮助文档),如果不对特征数据集进行标准化,会导致不同的特征对距离的贡献存在明显差异。当然,K-Means参数设置(分类数目等)也可能对分类结果有较大影响。一般而言,无监督分类的结果要比监督分类的结果要差。这样,重点是监督分类,对无监督分类不过多地加以讨论。
监督分类
在遥感影像地物分类中,现在基本上都是选择监督分类,因为其精度相对较高。监督分类通过对数据的若干特征与若干标签(类型)之间的关联性进行建模,只要模型被确定,就可以应用到新的数据集上。
SNAP中关于监督分类算法有好几种,这里以目前主流的随机森林分类算法为例,选择随机森林算法的原因有好几个:一是算法分类效率高(训练和预测速度都比较快),即使数据集很大,也不要很长时间(相较于支持向量机等算法);二是集成分类算法(随机决策树集成),算法分类精度一般比较高(分类精度其实取决于很多参因素,与数据集,样本,算法及其参数等都有关,这里是通常情况下的对比);三是特征数据集不要标准化,因为其是基于特征区间进行的概率分类,而不是基于距离进行的分类。
监督分类需要有训练样本。下面以SNAP中的监督分类随机森林分类算法为例,对其分类过程进行介绍。
分类类别的确定
在分类之前,首先,要确定的就是分类目标(类别)。结合崇明岛以及数据集的分辨率、数量等实际情况,这里确定分类类别为5类,分别为:林地,农用地,裸地,建设用地,水体。这里的类别确定还是比较简单直接了,实际上结合实际需要和结果好好考虑的。不过,作为演示,这里不太讲究了。
创建训练样本集
在创建训练样本之前,可以先把前面的无监督分类算法的结果关掉。SNAP创建样本集与别的遥感软件不太一样,虽然都是通过矢量图来创建区域,但是,其不是通过直接添加一个类别属性来加以区分的,二是通过矢量数据集来区别类别的。SNAP每一类地物需要建立一个矢量数据集,五类就需要5个。
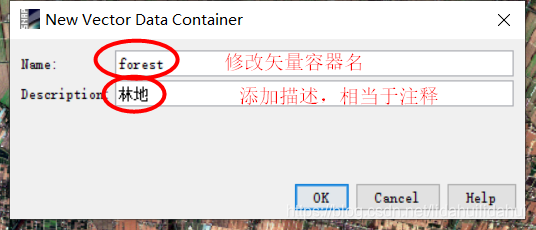
创建矢量容器
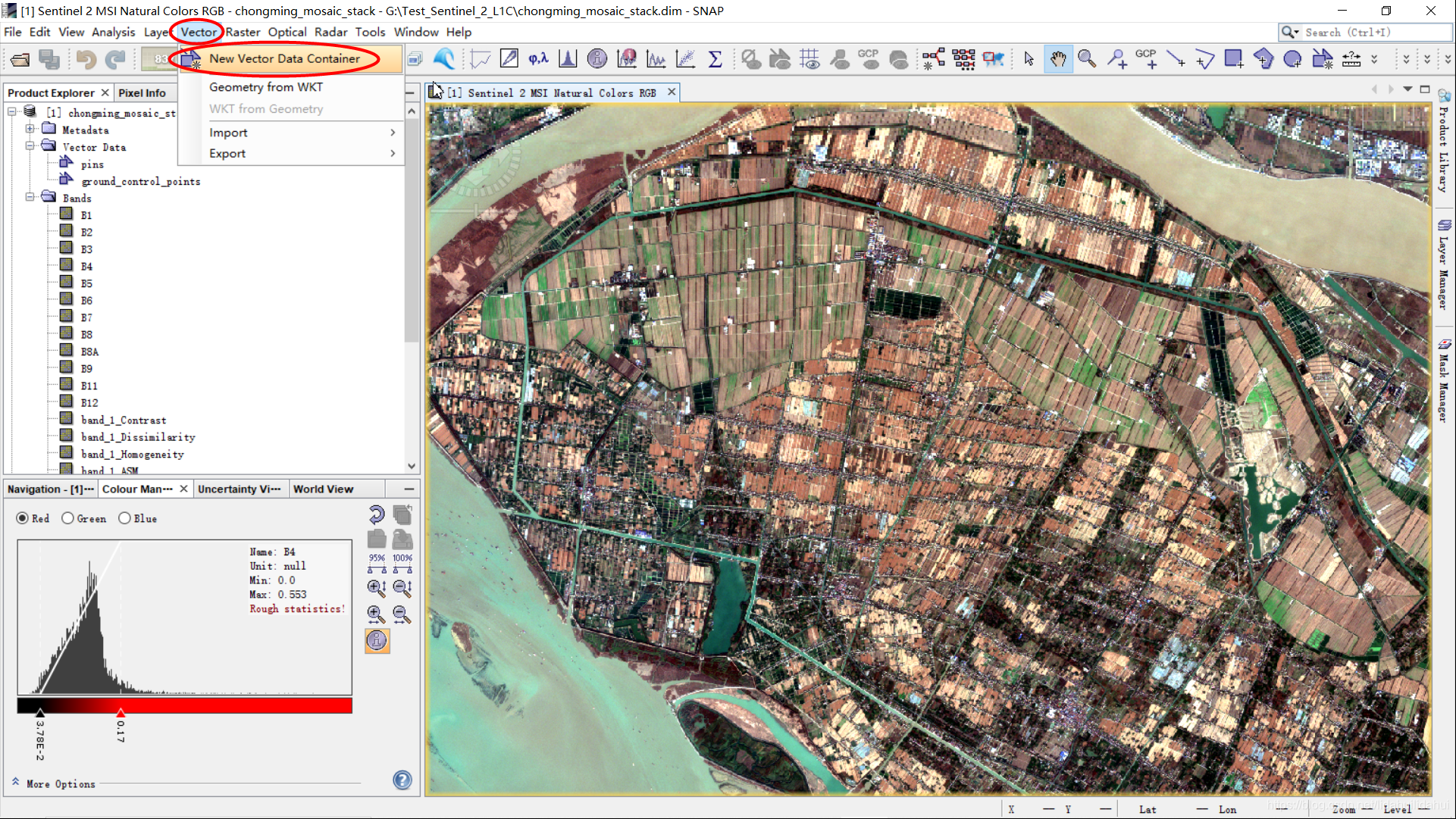
我们通过矢量容器(Vector Data Container,相当于GIS中的图层)来创建每一类训练样本矢量数据集,点击Vector—>New Vector Data Container:
矢量编辑工具
查看矢量数据管理器帮助文档
首先,可以通过在搜索框中输入Vector Data,打开Vector Data Management的帮助文档,查看矢量数据管理器的帮助文档:
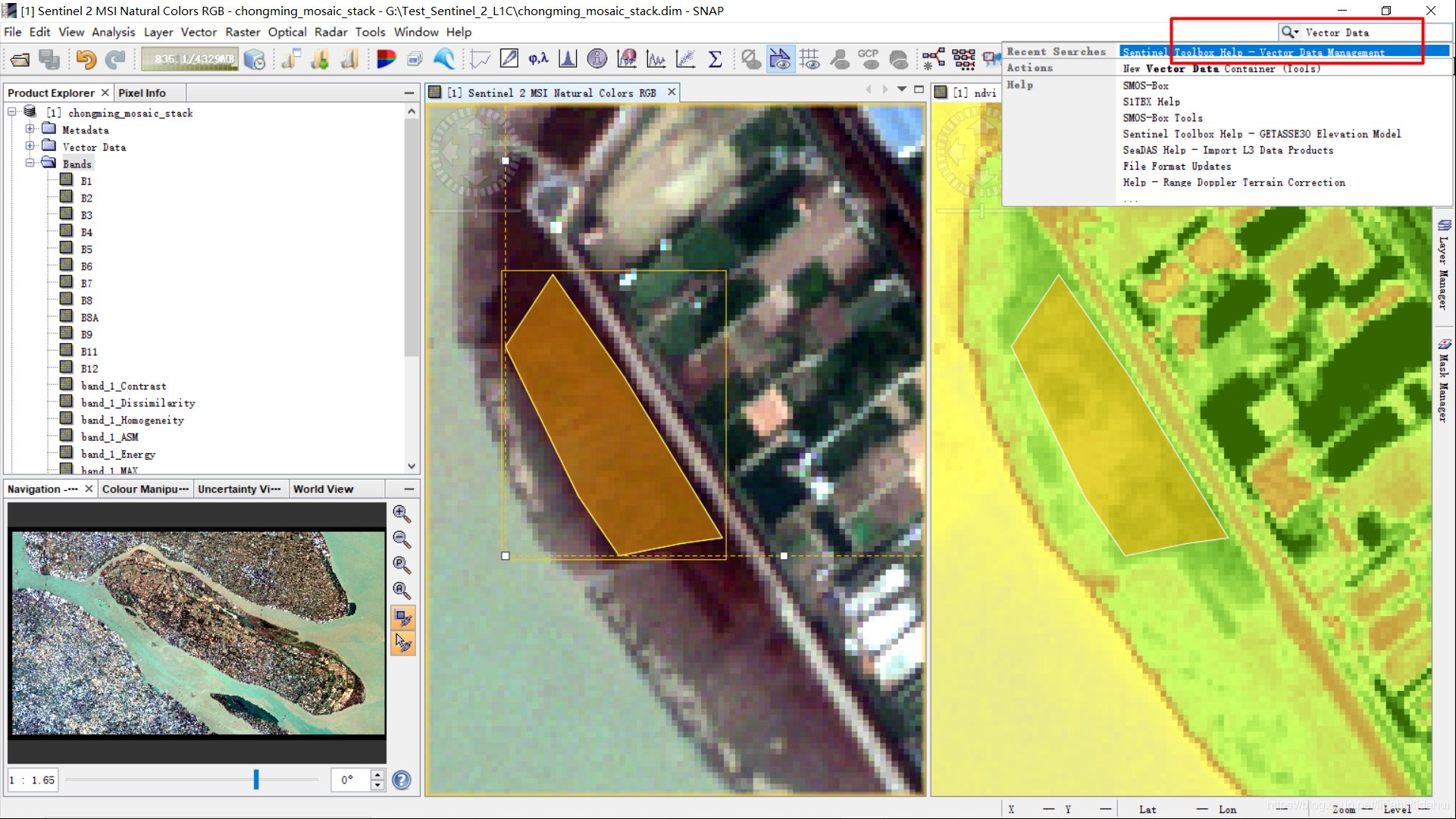
如果你比较耐心看的话,应该是可以看懂帮助文档的说明的:
勾绘多边形
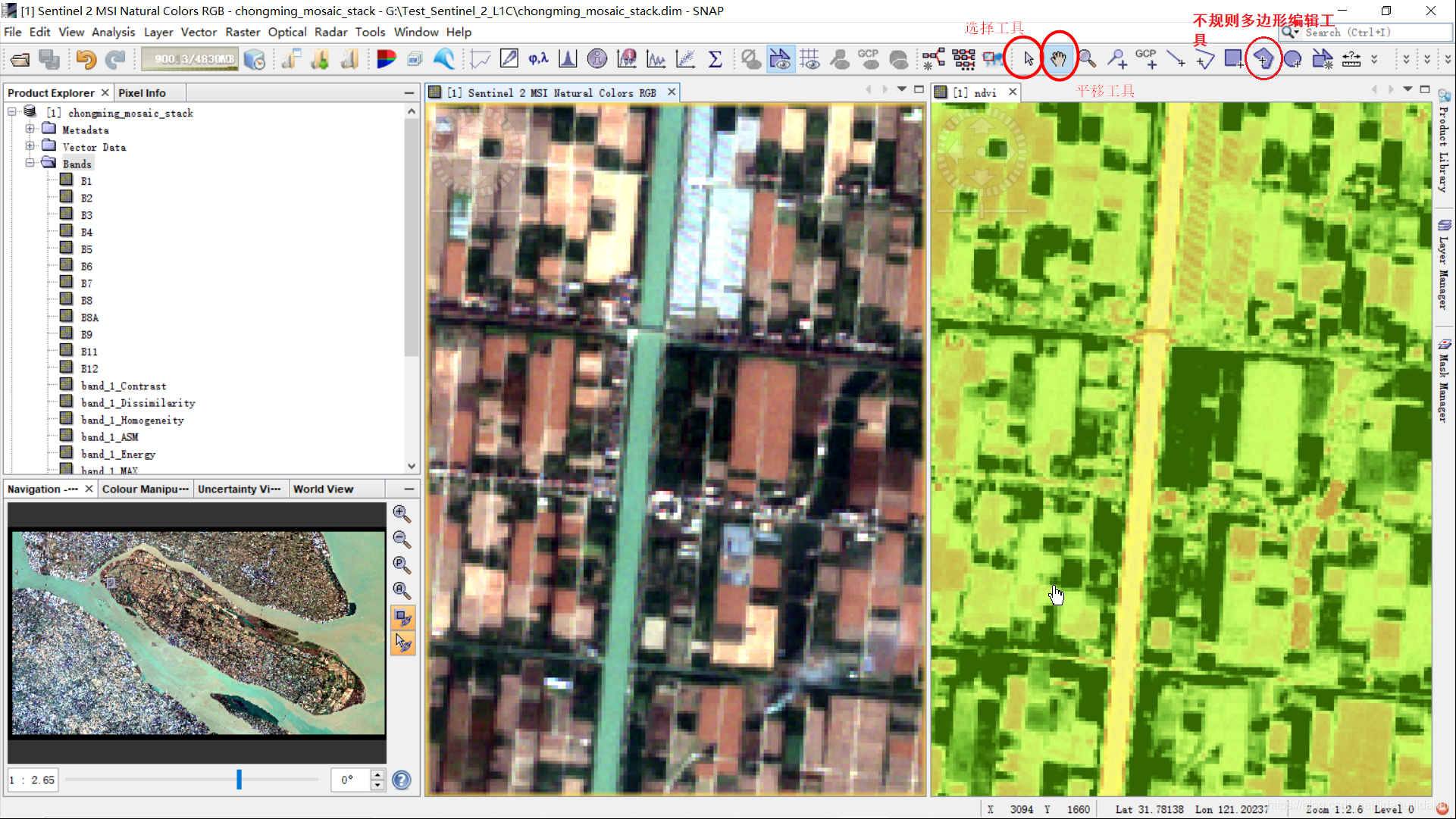
创建矢量容器后,可以在左侧Vector Data文件夹下找到该矢量容器(如forest)。在右上角上可以找到多种矢量编辑工具,用于勾选样本。
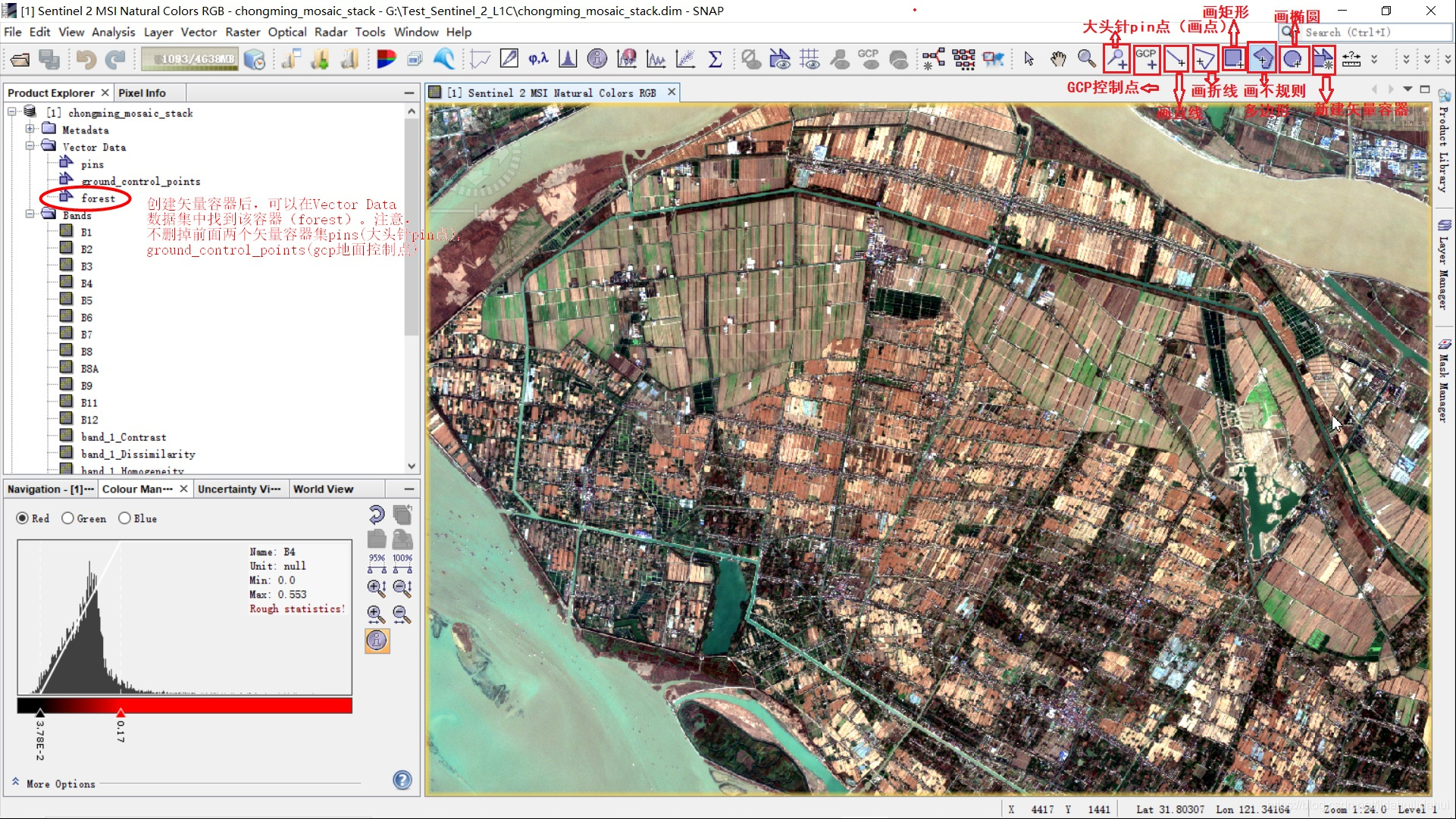
在勾选林地或者农作物的时候可以打开ndvi等植被相关的波段,来指导勾选样本,这里打开ndvi波段,水平分屏(Windows—>Tile Horizontally),借助ndvi能协助勾选样本:
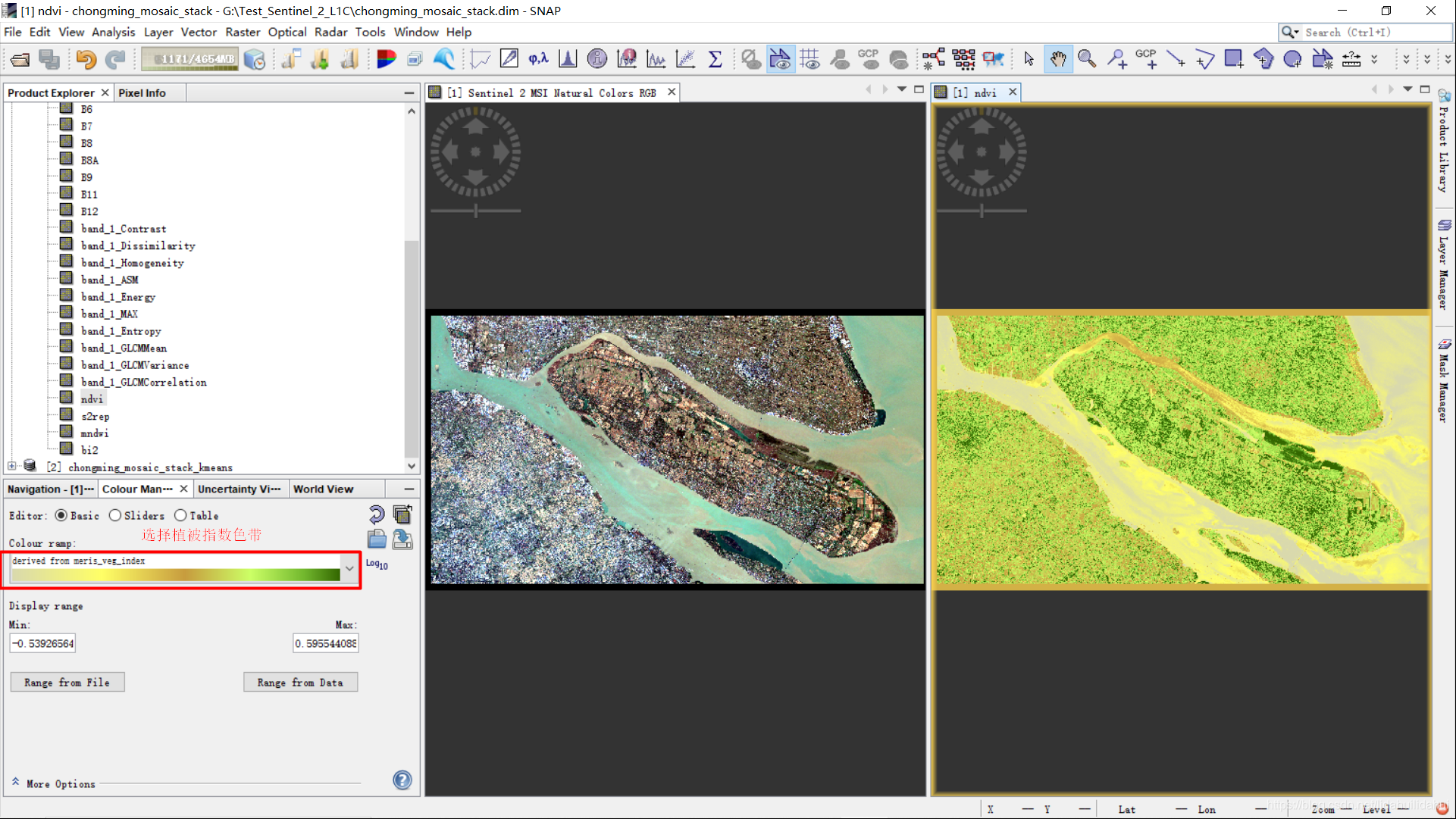
回到导航窗口,鼠标单击一下RGB图,并勾选同步滚动的两个选项,移动(鼠标左键)和放大(鼠标滚动)窗口到崇明岛西北部分,准备开始勾选样本(崇明岛这个地方,博主去过几次,虽然没跑遍,一些基本的认识是有的,通常林地河道两侧,通常林地轮廓不是规则的矩形,在岛边会存在一些湿地林地,种植区可能存在一些果树之类的作物。要将其和农作物相靠目视相区分还是比较困难的,并且不同林地密度也不一样,不过这里作为演示,不要太讲究了)。
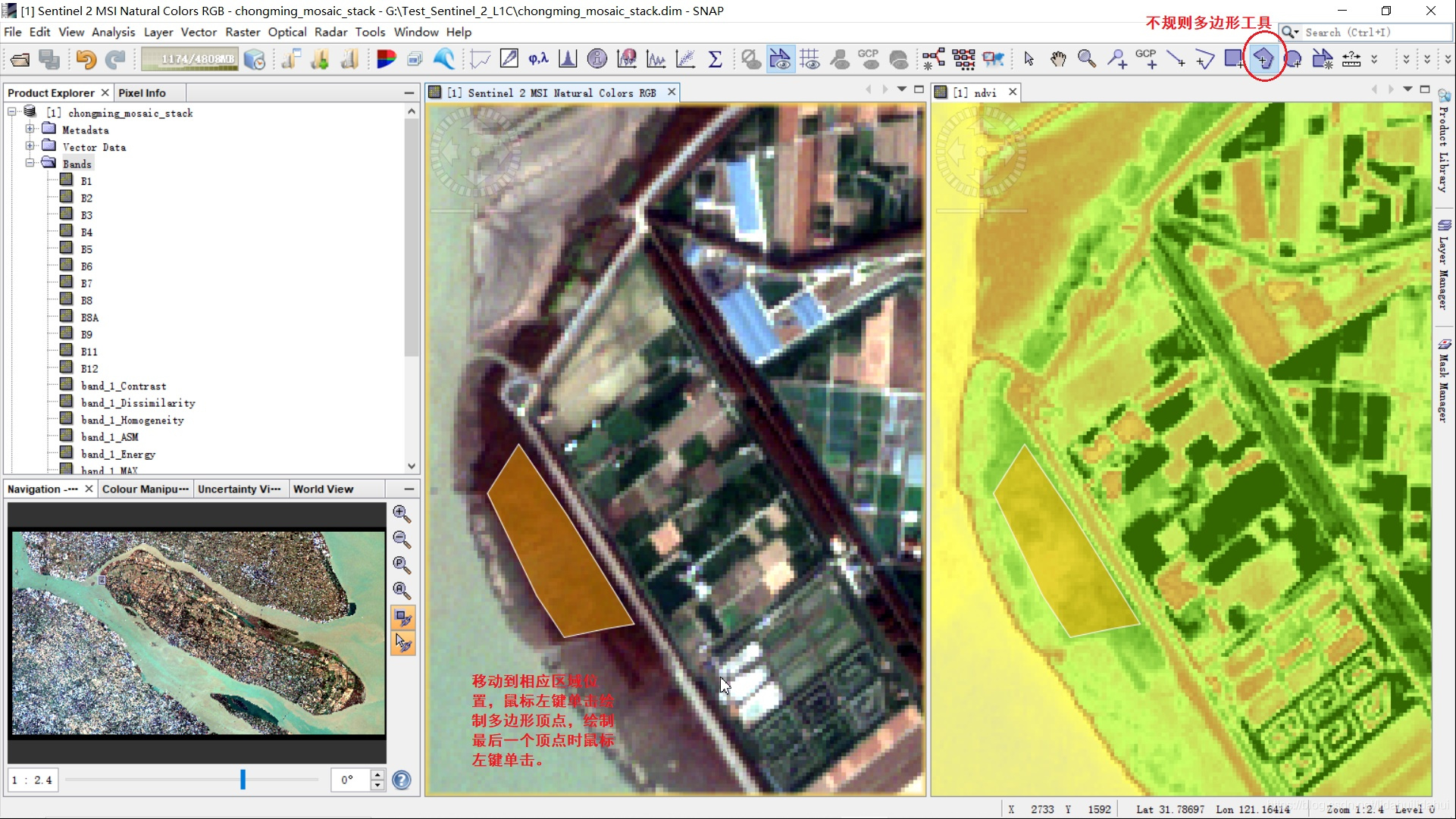
这里使用的是不规则多边形编辑工具,鼠标单击该工具(图中红褐色(乃至黑色)的应该是林地,可以打开Google Earth看下)。
鼠标左键放至合适位置,鼠标左键勾选多边形顶点(不应少于3个),绘制最后一个顶点时,鼠标左键双击结速绘制。
修改或删除图形位置或者端点
选择模式1
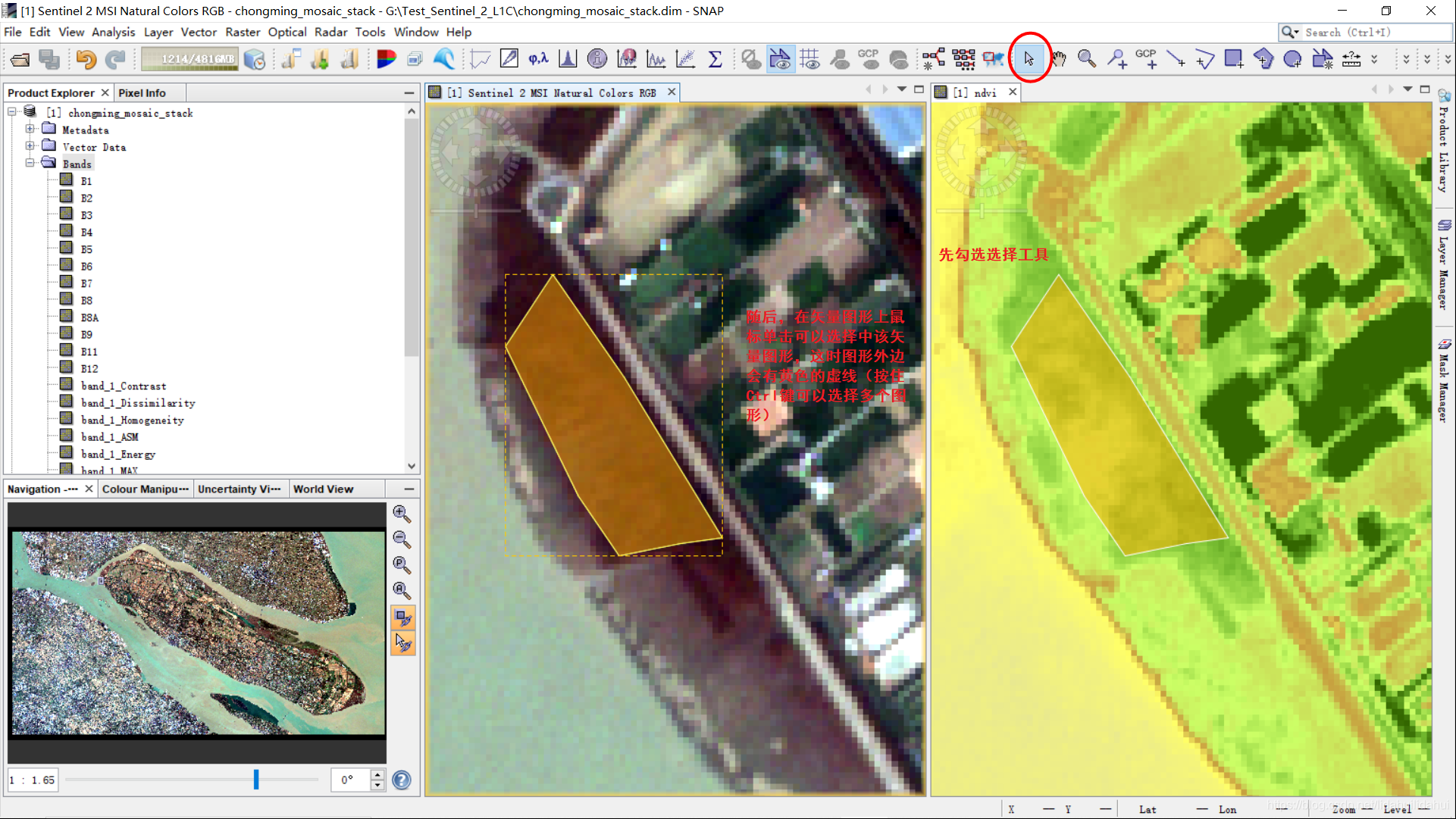
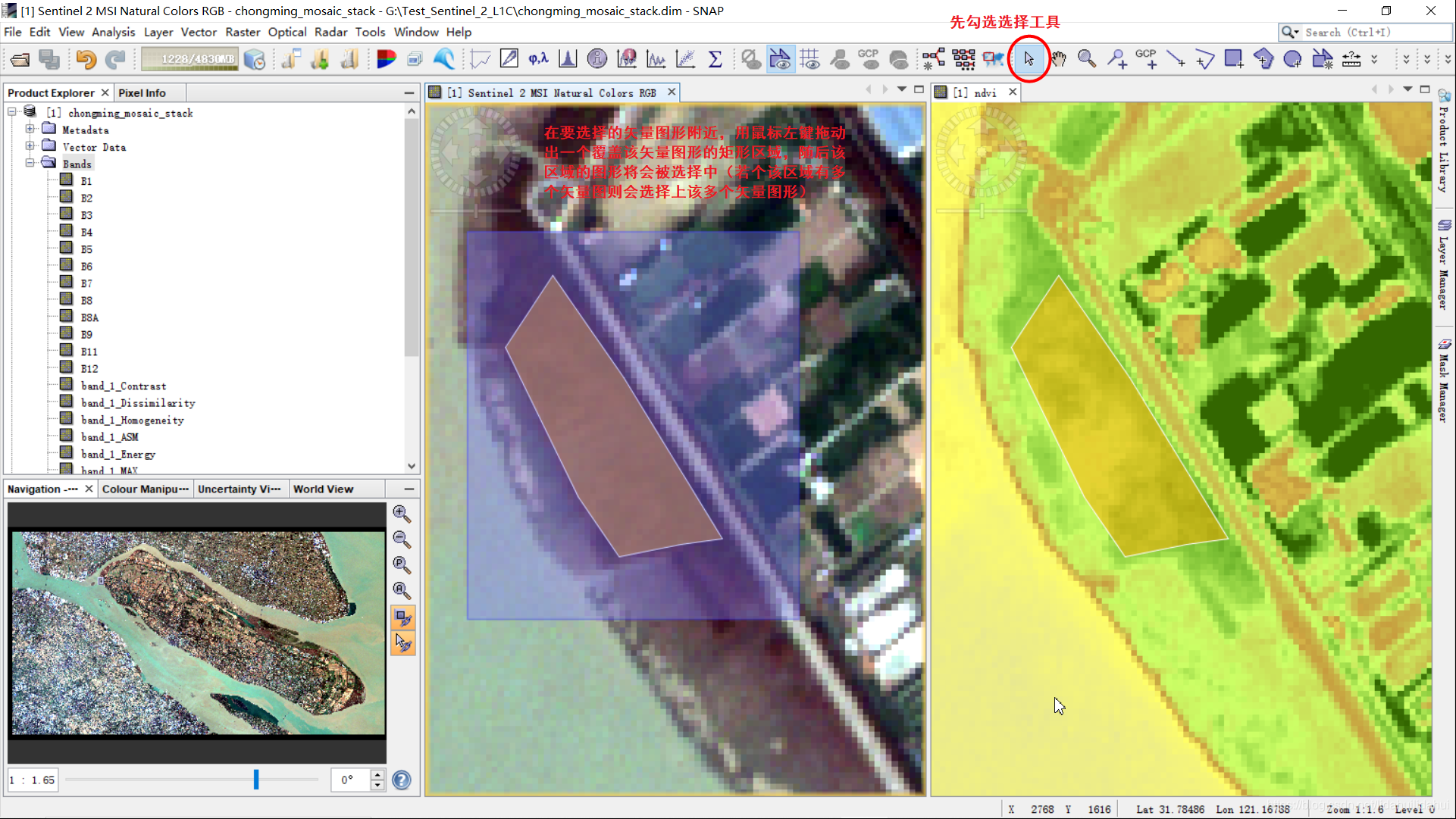
绘制多边形时,有可能后续还需要修改顶点位置。若要图形位置或修改顶点或者删除该矢量图形,则先要选中该矢量图形。先勾选选择工具,随后移动鼠标可以在该图形位置上鼠标单击(如果要选择多个,可以按住Ctrl键,点击鼠标左键选择多个多边形),图中的矢量图的矩形黄色虚线轮廓表明这是选择模式1形态。
也可以通过下面方式选中该矢量图形:
从帮助文档中,可以看到矢量编辑工具有三种选择模式,可以从图形矩形轮廓和端点形态区别这三种形态。

在选择模式1下,可以在该图形上按住鼠标左键直接平移该矢量图形的位置。选择模式1中有黄色矩形虚线轮廓。
选择模式2
如果再在该矢量图形上鼠标左键单击一次,将进入选择模式2。该模式下可以平移、添加或者删掉矢量图形的端点选择模式2除了有黄色矩形虚线轮廓,端点会显示为白色,表示端点可以移动。
平移端点:鼠标箭头移动到要移动位置的端点上,鼠标左键点击该端点(会选中该端点,端点会变成黄色),长按住鼠标左键移动位置即可;
添加端点:鼠标箭头放在从某个矢量图端点上,鼠标左键单击该端点(会选中该端点,端点会变成黄色),再同时按住Ctrl键和鼠标左键即可拖动一个新的端点出来;
删减端点:在删减掉的矢量图形端点上鼠标左键单击,以选中该矢量图形,再移动鼠标将该端点至其前一个端点或后一个端点上,再按一下Ctrl键即可删掉该端点。
选择模式3
在模式2下,再在矢量图形范围内鼠标左键(非端点位置)单击一次,将进入选择模式3上。选择模式3除了有黄色矩形虚线轮廓,其轮廓端点会显示为白色。选择模式3下,可以拉伸放大或缩小该矢量图形(当然也可以平移)。
3种选择模式同时激活
进入模式3后,如果再在矢量图形范围内鼠标左键(非端点位置)单击一次,三种选择模式将同时激活,三种模式可以编辑的内容,都可以编辑。

删除矢量图形
删除图形:可以在上述该矢量图形的四种选择模式下,按键盘上的Delete(Del)删掉该矢量图形
退出矢量编辑选择模式
在三种选择模式同时激活的情况下,如果再在矢量图形范围内鼠标左键(非端点位置)单击一次,所有退出所有选择模式
刚开始可能不习惯,需要多次练习。熟悉后,操作就会快很多。
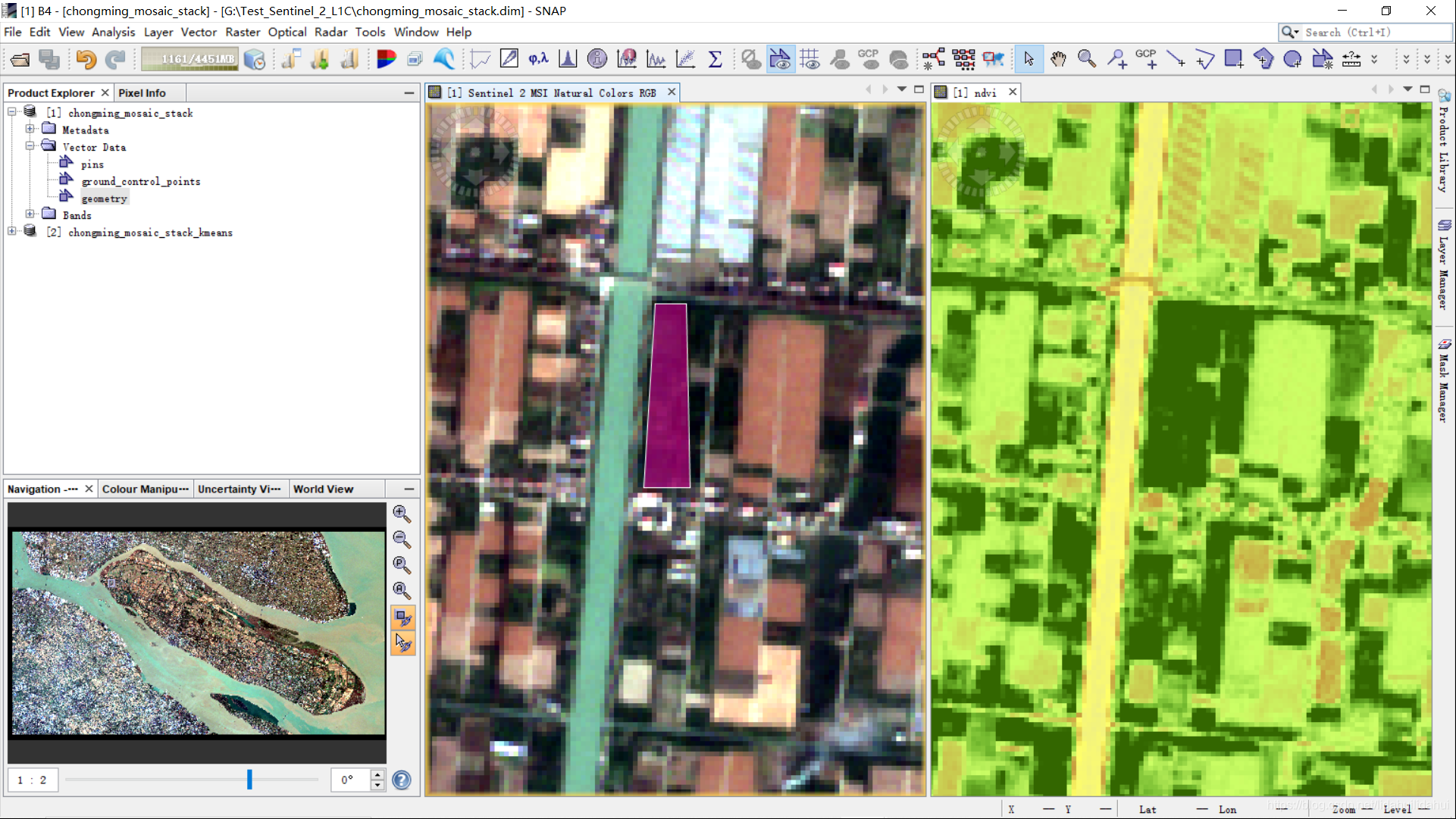
确认该矢量多边形无误后。再通过选择工具(箭头)和平移工具(手指图标),移动窗口位置至下一个区域,再次选择不规则多边形编辑工具,勾绘训练样本区域。
再次将鼠标左键放至合适位置,鼠标左键勾选多边形顶点(不应少于3个),绘制最后一个顶点时,鼠标左键双击结速绘制。
如此反复,勾绘30-80个样本区域(注意覆盖崇明岛东西南北区域,也就是说,如果可能的话,训练样本尽量分散开。这里的样本数量比较多,因为区域比较大,你可以结合实际情况进行调整。)
为了评价分类的效果,还需要每一个地物创建验证样本(每一个地物,10-30个样本),其它要求和训练样本相同,如分布尽量均匀,同质等。在创建混淆矩阵时需要用到这个验证样本。
博主这里创建了5个地物的训练样本区域以及它们对应的验证样本区域供10个矢量数据集,其中,带有_valid后缀的是验证样本集(见下图红色框)。如下图所示(bare_land,construction_land,crop,forest,water分别代表裸土、建设用地,农用地,林地,水体):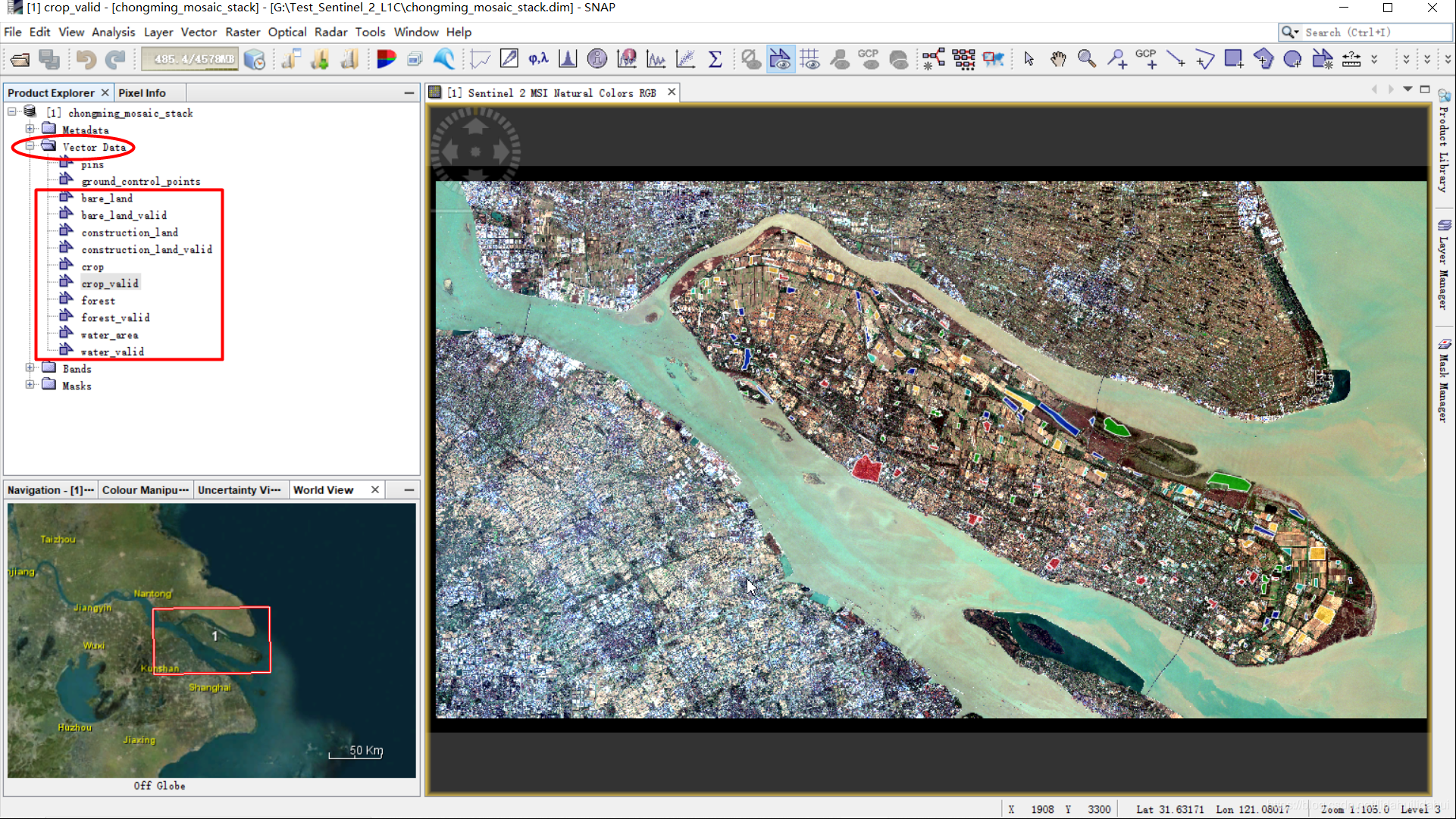
矢量图层属性修改
有时候在SNAP中新建一个矢量容器集(相当一个矢量图层)需要修改矢量(这里的样本是不规则多边形)图形的属性,如颜色,边框,线条等。可以利用Layer Editor (图层编辑器)来修改。
方式一
在打开的影像集中,先点击要修改的矢量图层(例如这里选择的crop_valid矢量图层),然后选择Layer—>Layer Editor
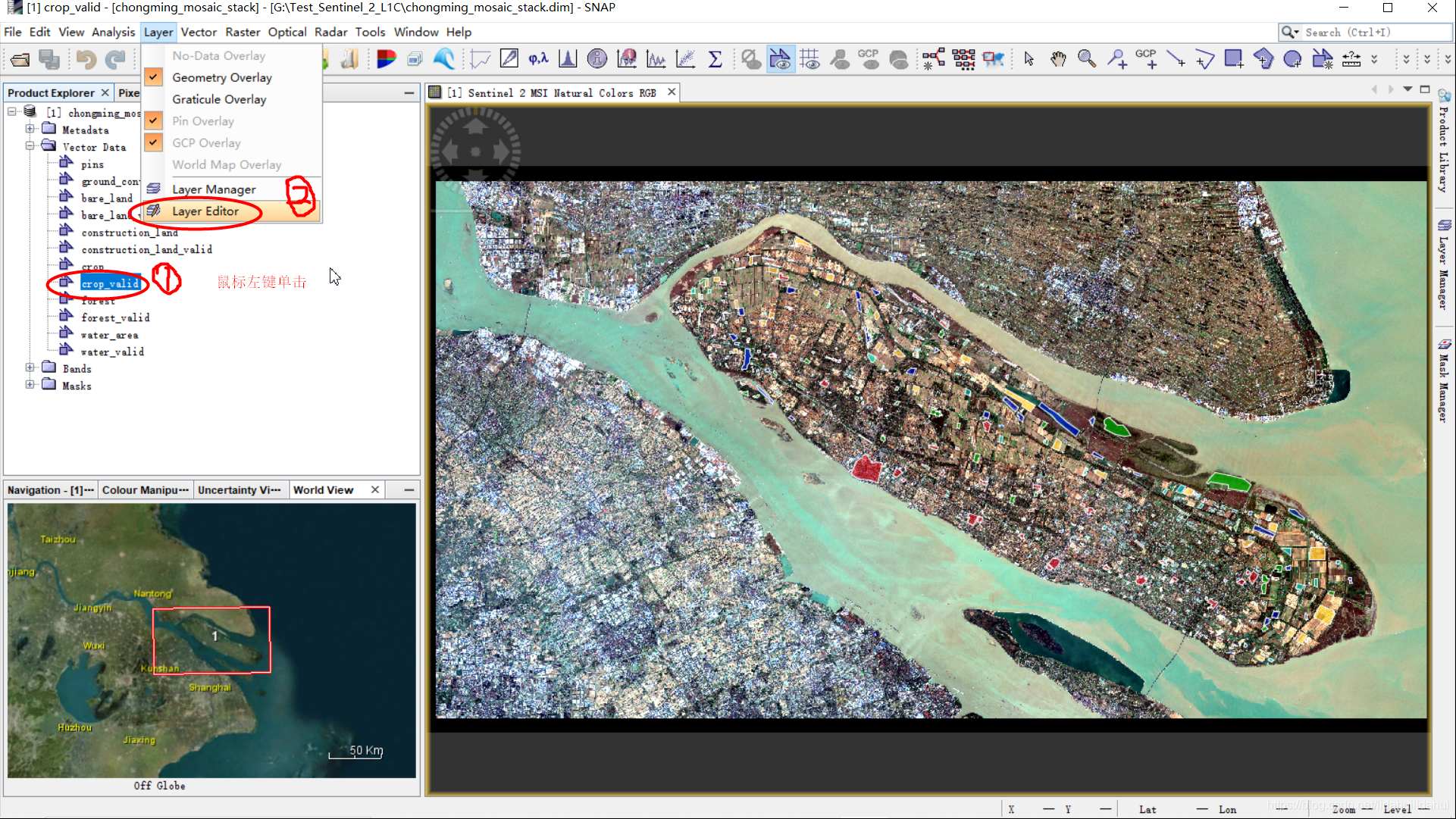
打开的图层的编辑器在左下角。
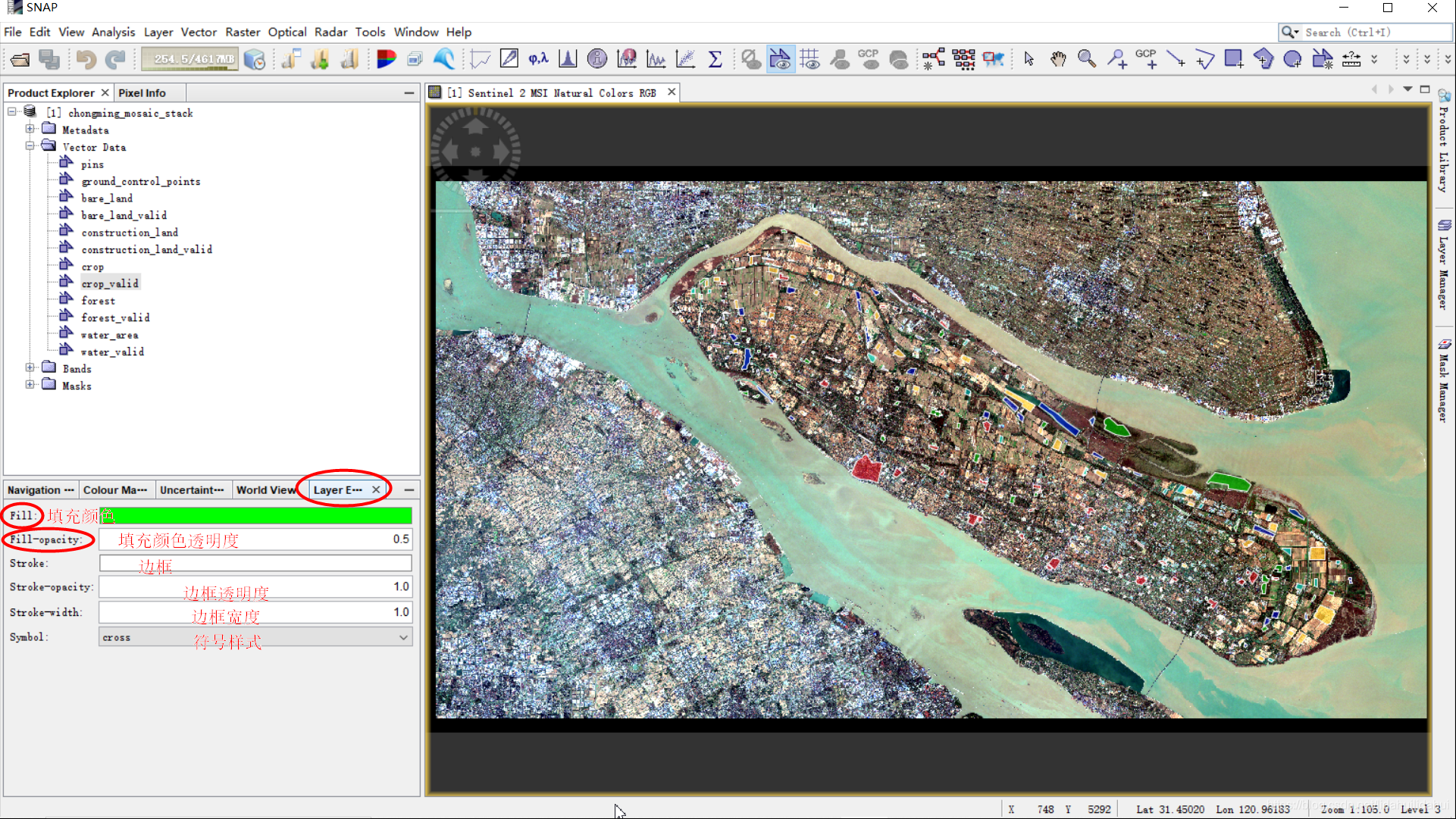
方式二
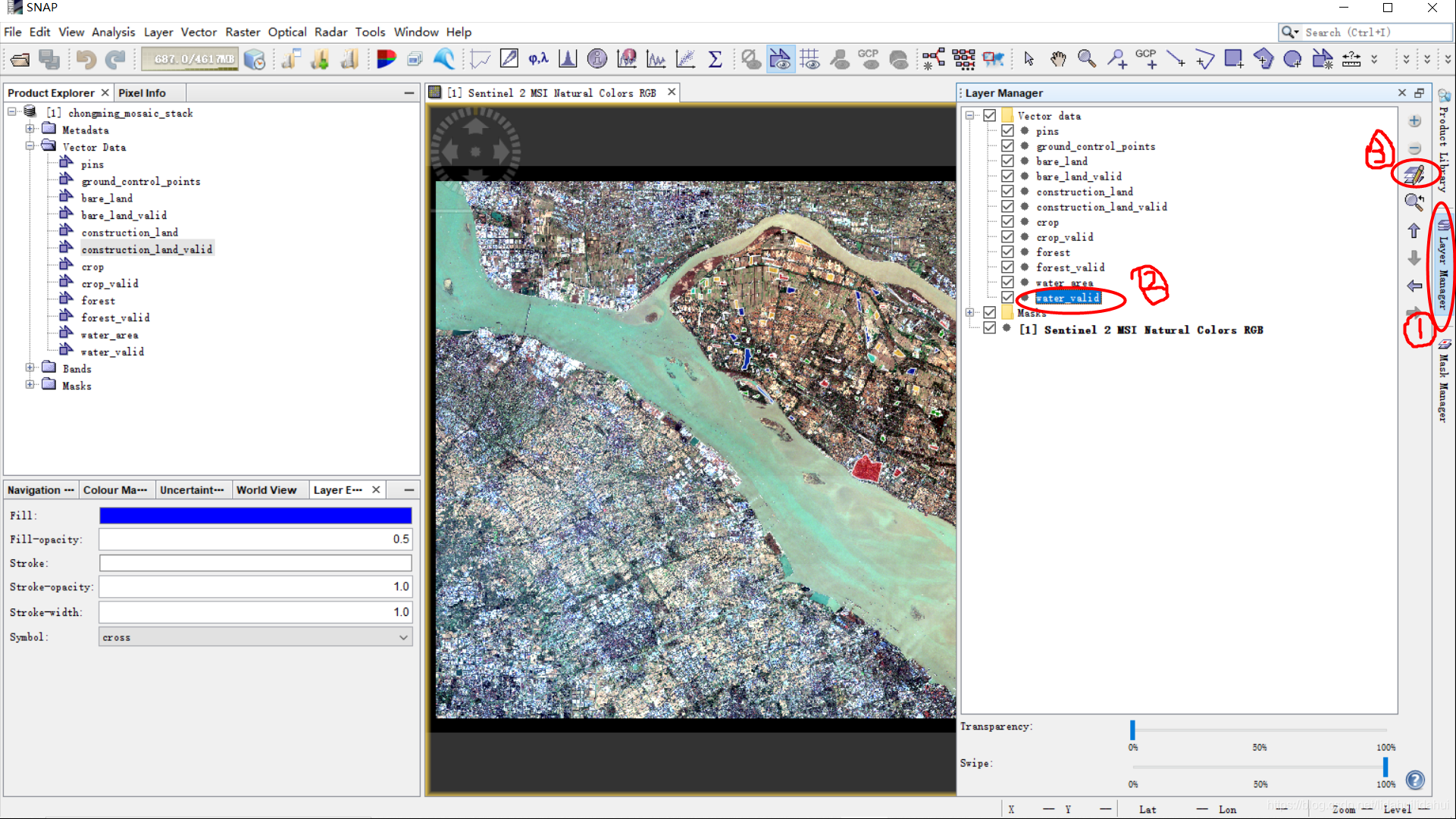
我觉得方式二更方便一些,可以更快地切换矢量数据集。通常,我们只需要修改填充颜色(Fill)即可,某一些情况下也可以需要调整其它选项(例如填充颜色透明度)。
例如修改water_valid(水体验证样本)的颜色(这里选择的是深蓝色,选择More可以选择更多颜色):
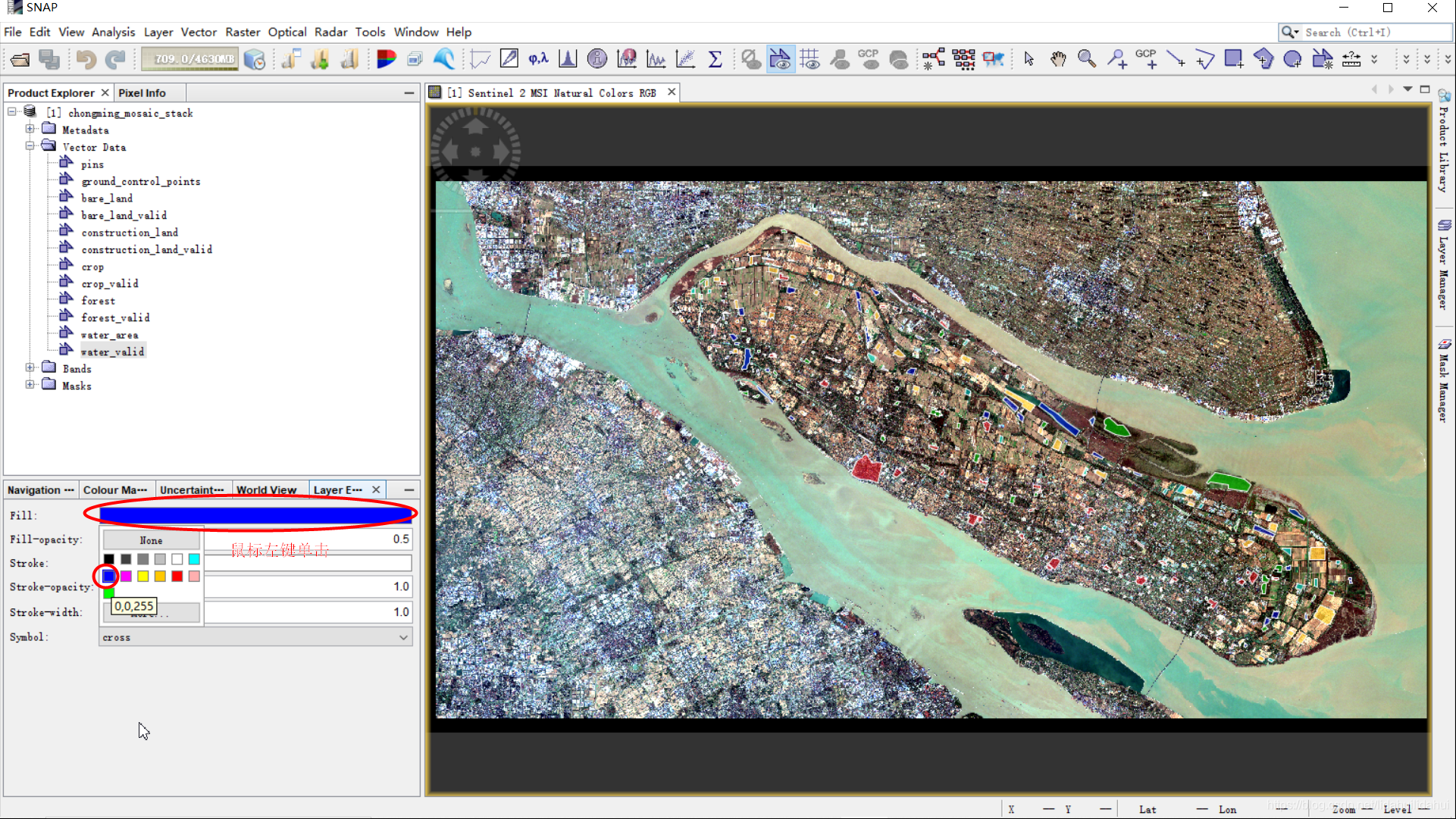
每一个地物的训练样本是相同颜色的,bare_land(裸地)是棕色,construction_land(建设用地)是红色,crop(农用地)是淡蓝色forest(林地)是,water(水体)是深蓝色。
你可以自行调整各个矢量图层(样本集)的属性。
查看矢量图层属性表
如果你将鼠标移动到某个矢量图层上(停留几秒),可以看到其旁边会显示一些提示(如下面water_valid旁的淡黄色提示语)
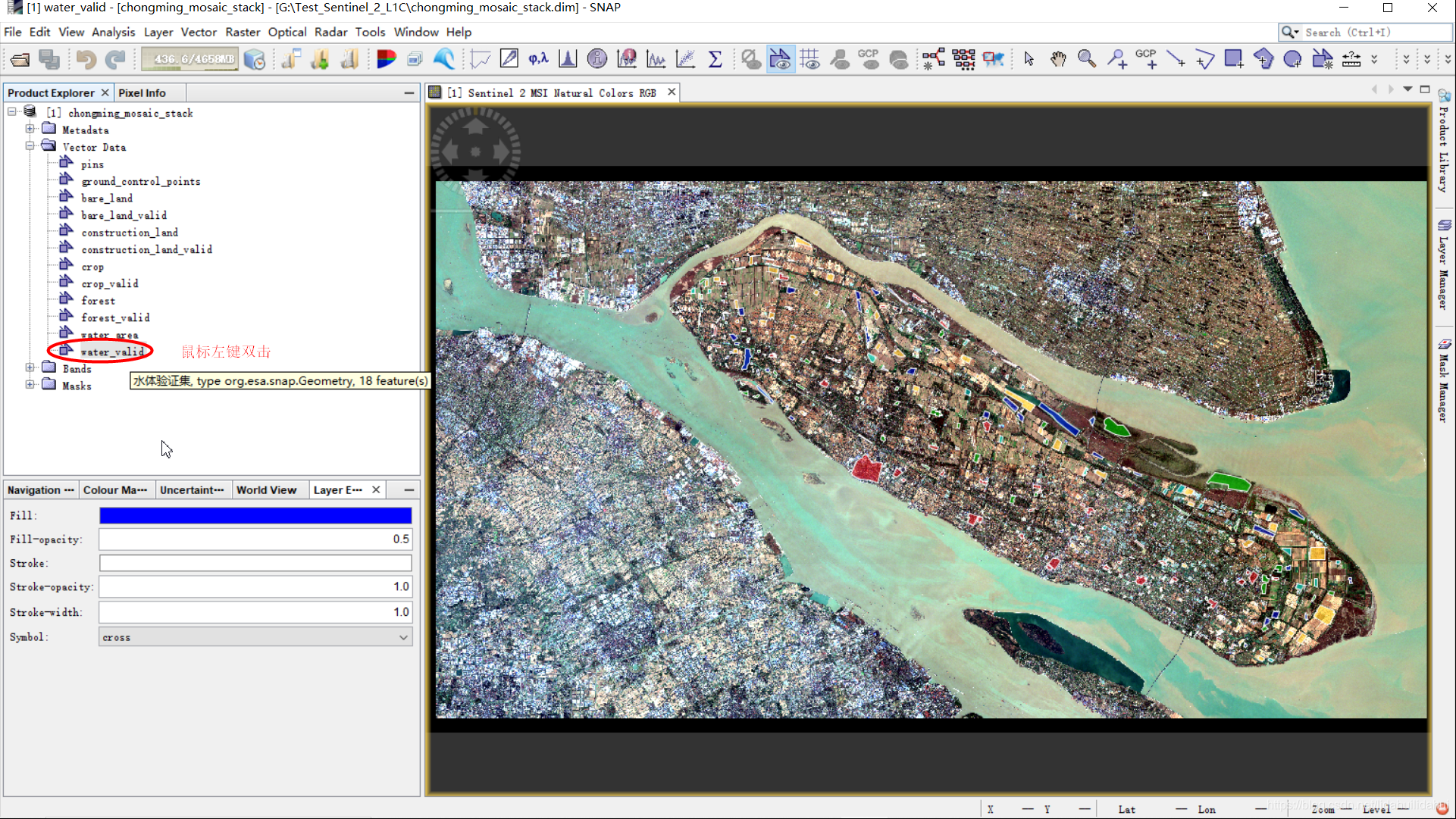
图中geometry存放的是几何属性(多边形端点的坐标),style_css存放的是样式属性(css表示其采用的和Web前端中CSS样式定义相同的样式规则)。

样本的导出与导入
从上面的属性表可以看出,样本(矢量)数据的geometry保存的几何图形格式和ESRI Shapefile(.shp)文件保存的几何图形格式(如果你了解格式的话)是一样的。本质上说,SNAP创建样本的过程和创建ESRI Shapefile文件是一样的,因此,其转换为.shp文件是很容易的事情。这样看来,SNAP的样本数据与GIS软件(QGIS与ArcGIS等)可以很容易进行对接。
样本的导出
以农用地样本数据(crop数据集)导出为例。
方式一
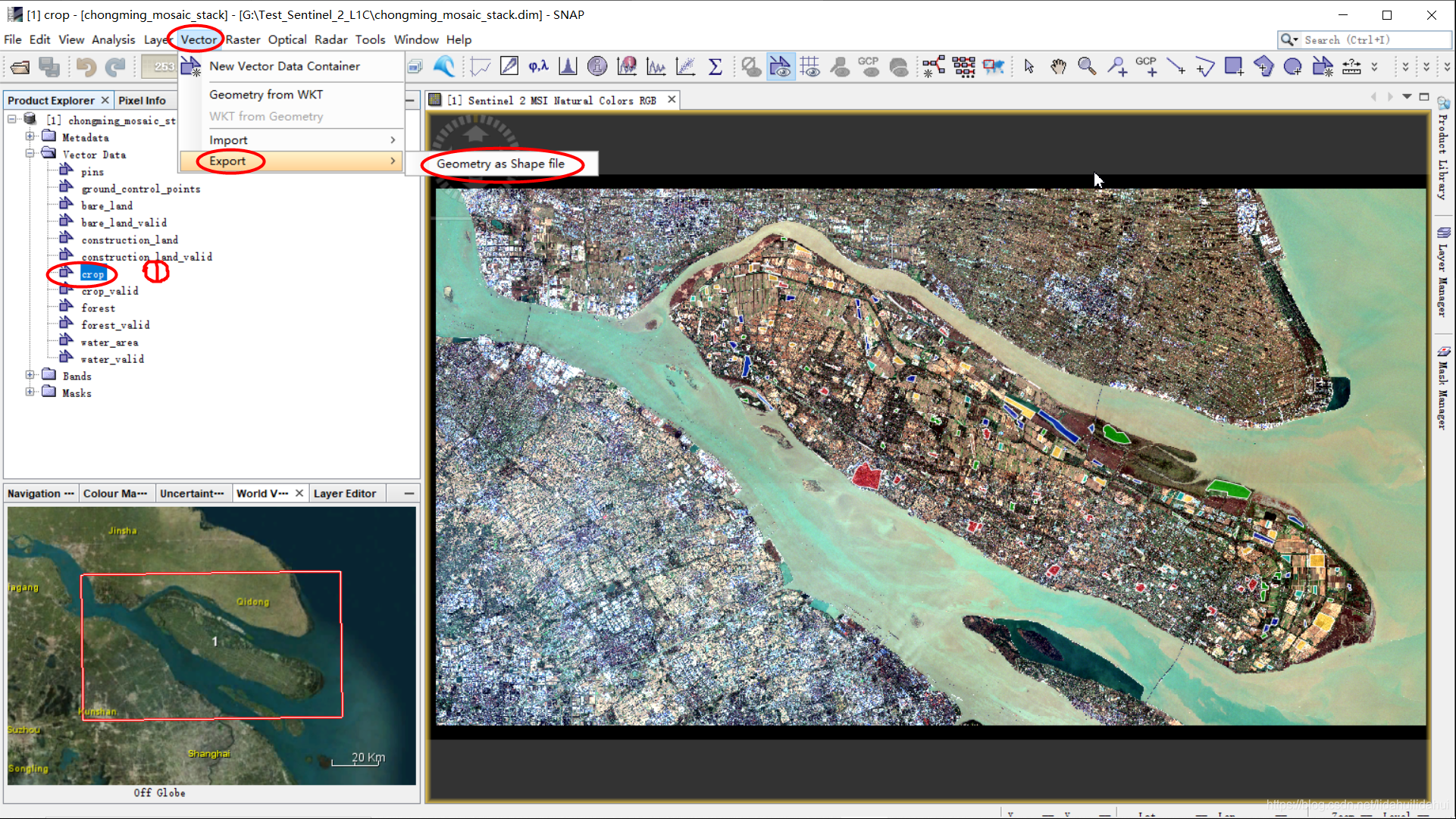
方式二
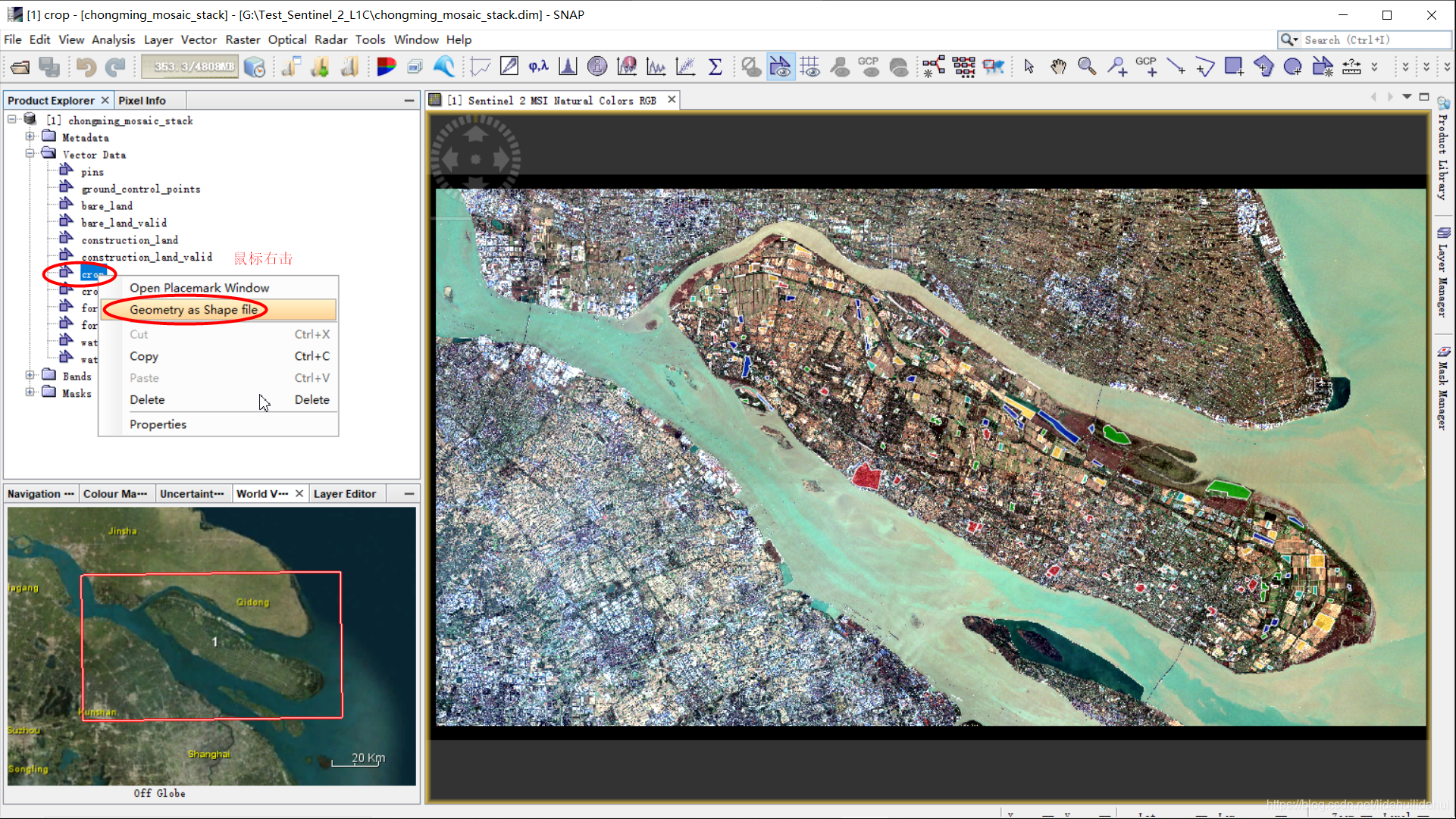
随后可以看到保存为.shp的文件窗口打开,(选择适当的路径,.shp文件名默认即可):
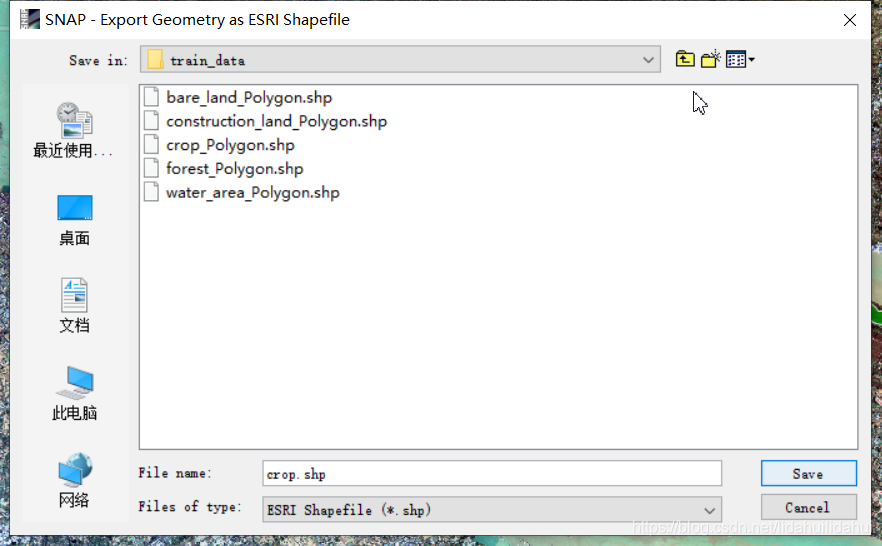
需要注意的是,SNAP导出的.shp文件名,默认会添加后缀"_Polygon"(为何是Polygon,因为我们创建的是不规则的多边形),不过文件名,不过,这不重要,不会影响GIS软件的读入与操作,这里crop_Polygon.shp(默认添加了后缀)是导出的crop.shp。
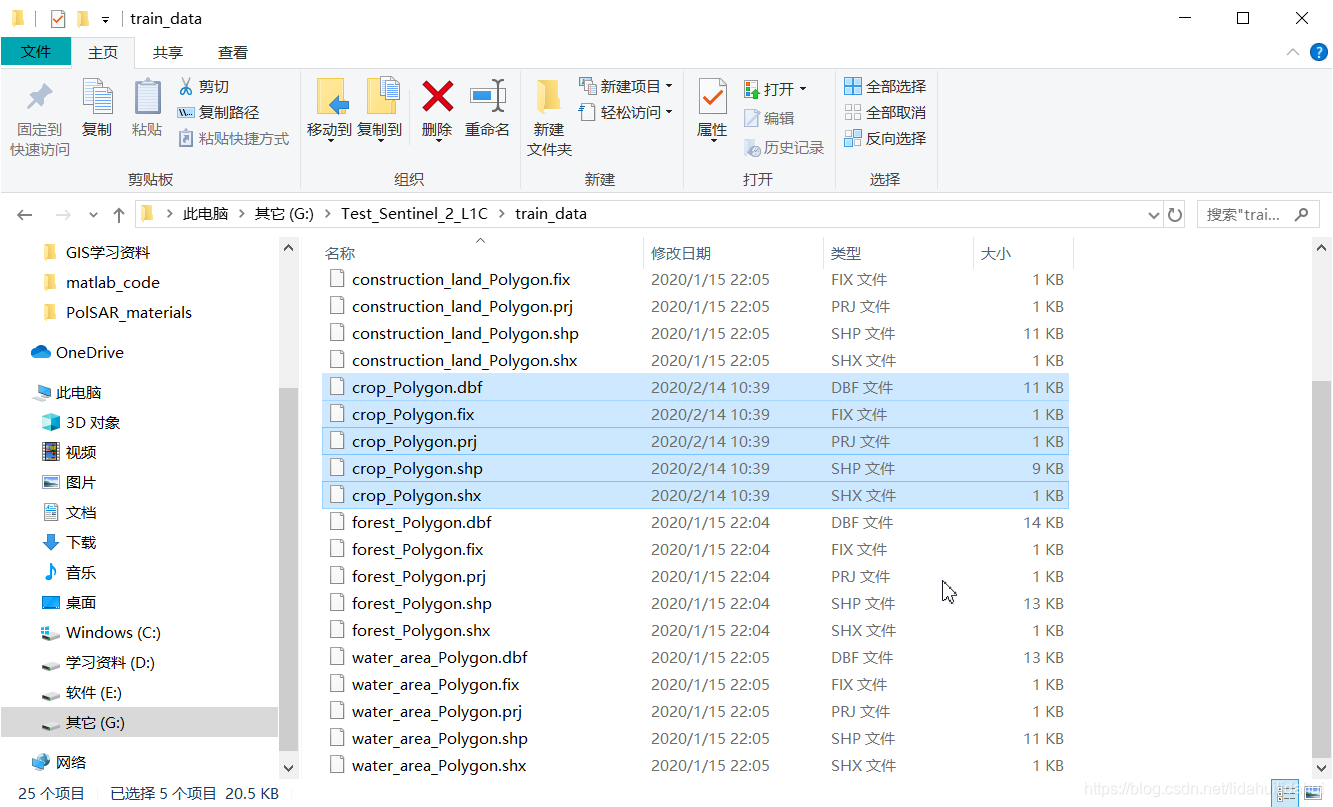
将所有的训练样本导出后,再导入到QGIS(图中增加了OpenStreetMap标准图层)中看看效果:
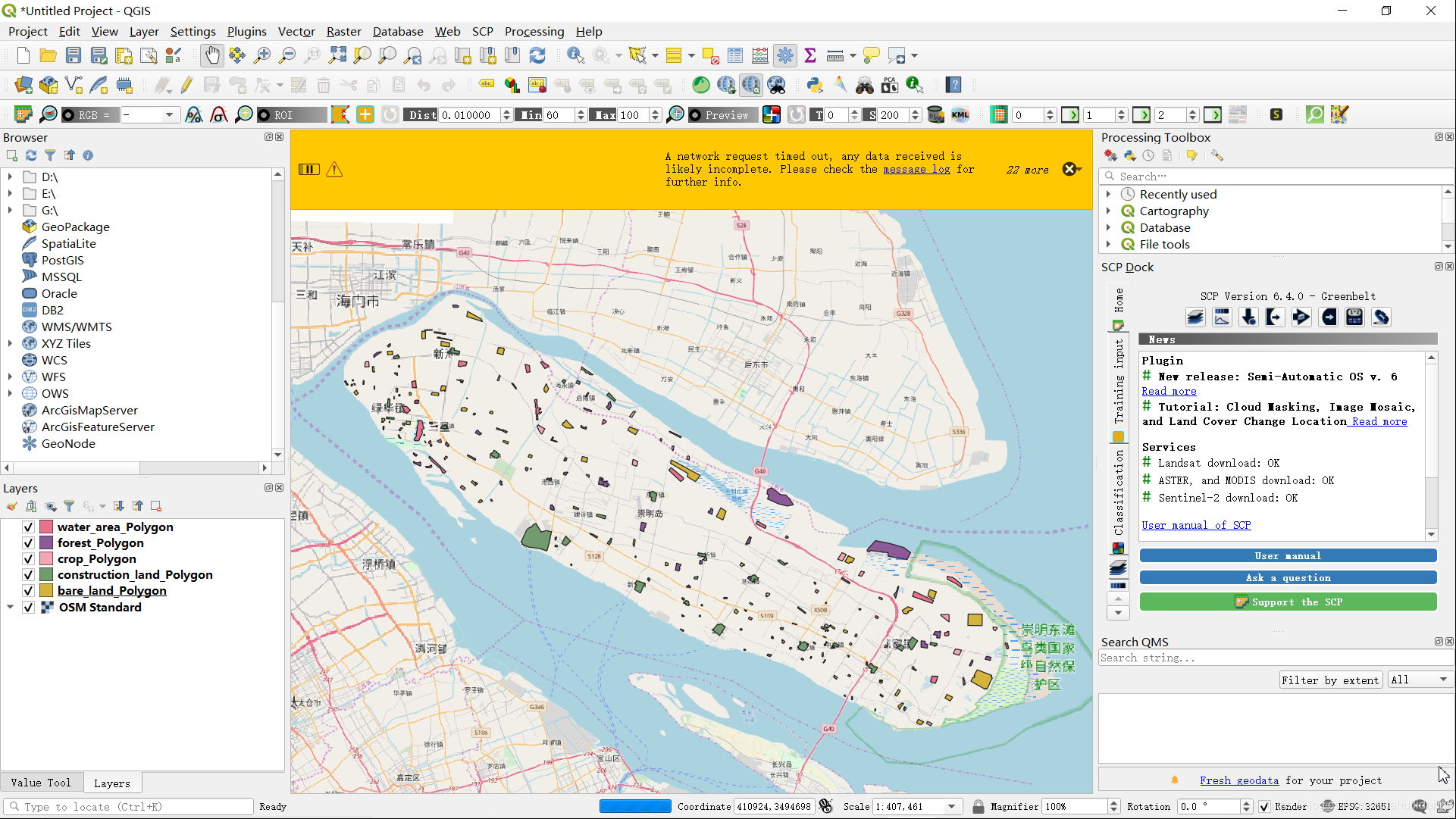
可以看到导出的样本数据和崇明岛实际分布的范围完全一致。
样本的导入
导入.shp文件是比较简单的。可以在Vector—>Import下找到该导入方式:
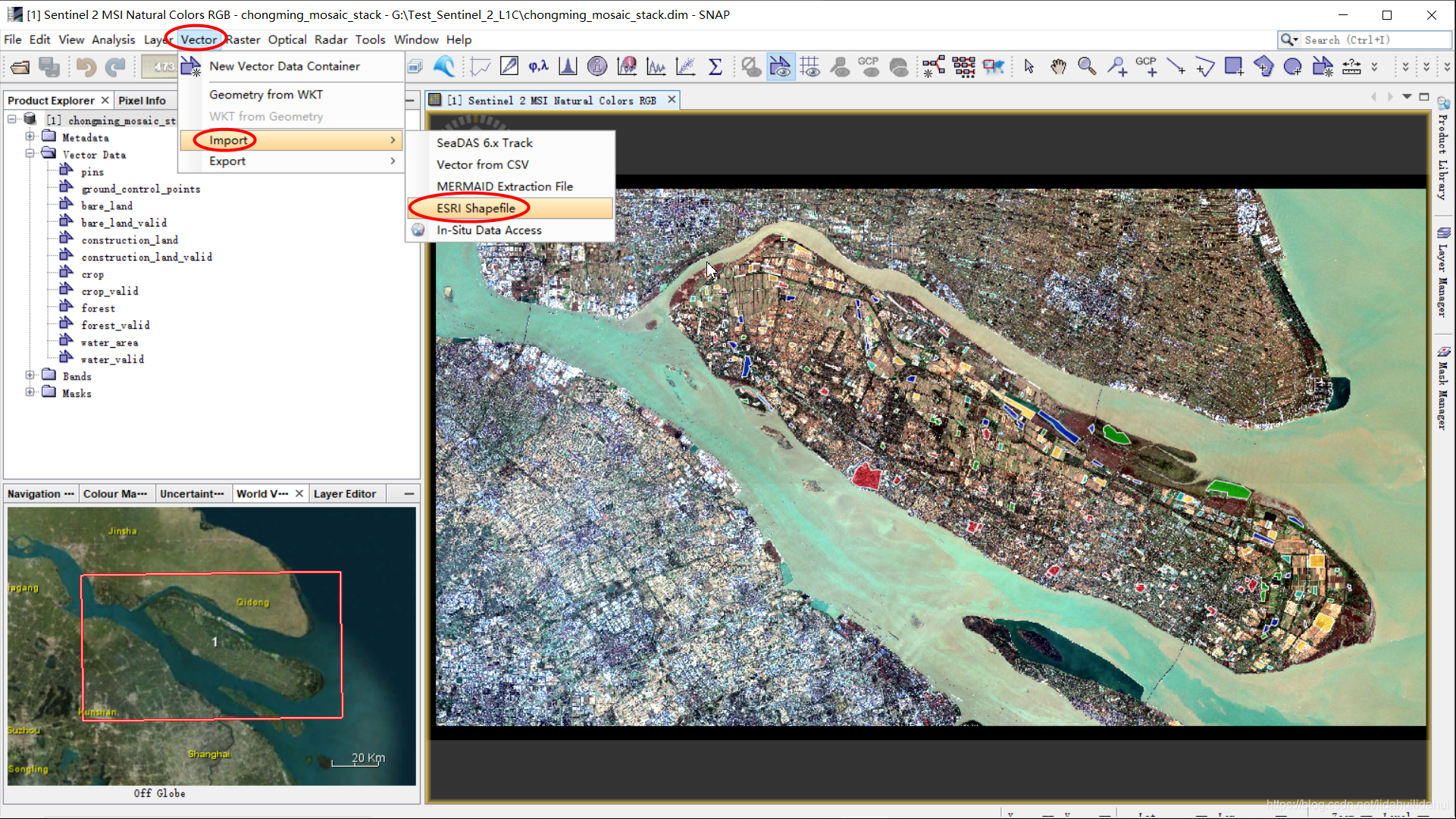
选择相应的路径下的.shp文件即可:
接下来是一个提示,提示我们是否允许其每一个polygon作为掩膜图层用途,还有就是图层的属性字段(style_css),点击no即可(不要选择yes,否则.shp中每一个图形都是一个图形)。

导入成功后,可以在导入的数据集下Vector文件夹(Mask文件夹下也有)找到该矢量图层:
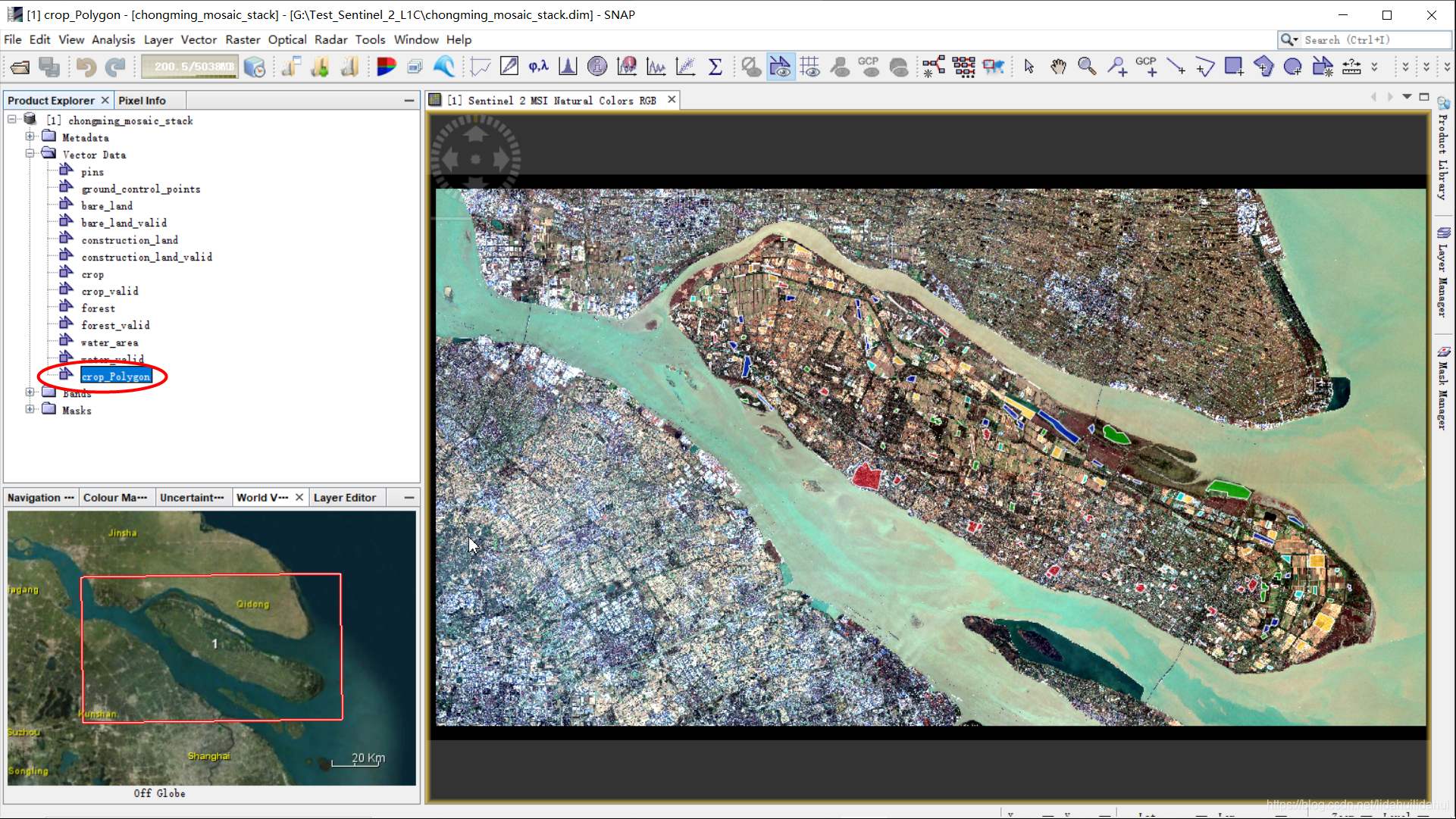
(导入后,记得删掉它,以免造成混乱,在该图层上右击,点Delete即可)
随机森林算法分类
经过前面的步骤,训练样本和验证样本已经准备好了。接下来,我们利用随机森林分类器来进行监督分类。SNAP中的监督分类器不是很全,但是一些比较重用的机器学习分类器是有的,但是这里没有支持向量机这个重要的分类器(可能的原因是这个分类器通常比较慢,相当于其它分类器而言)。我不会介绍随机森林算法的具体原理,如果你想深入了解该分类算法的原理,请找本介绍机器学习算法的书来看下,网上也有很多关于这个分类算法的博客介绍,不再过多赘述。
本分类算法用到的样本数据以及分类结果(原始特征集数据见博客前面的百度云盘链接),见下面的百度云盘链接:
链接:https://pan.baidu.com/s/1Nt4hUZdORdNHvjFxnTiN8Q
提取码:qls7
数据说明该百度云盘链接下文件夹中的说明.txt文件
随机森林分类器
选择Raster—>Classification—>Supervised Classification—>Random Forest Classier,启动随机森林分类器:
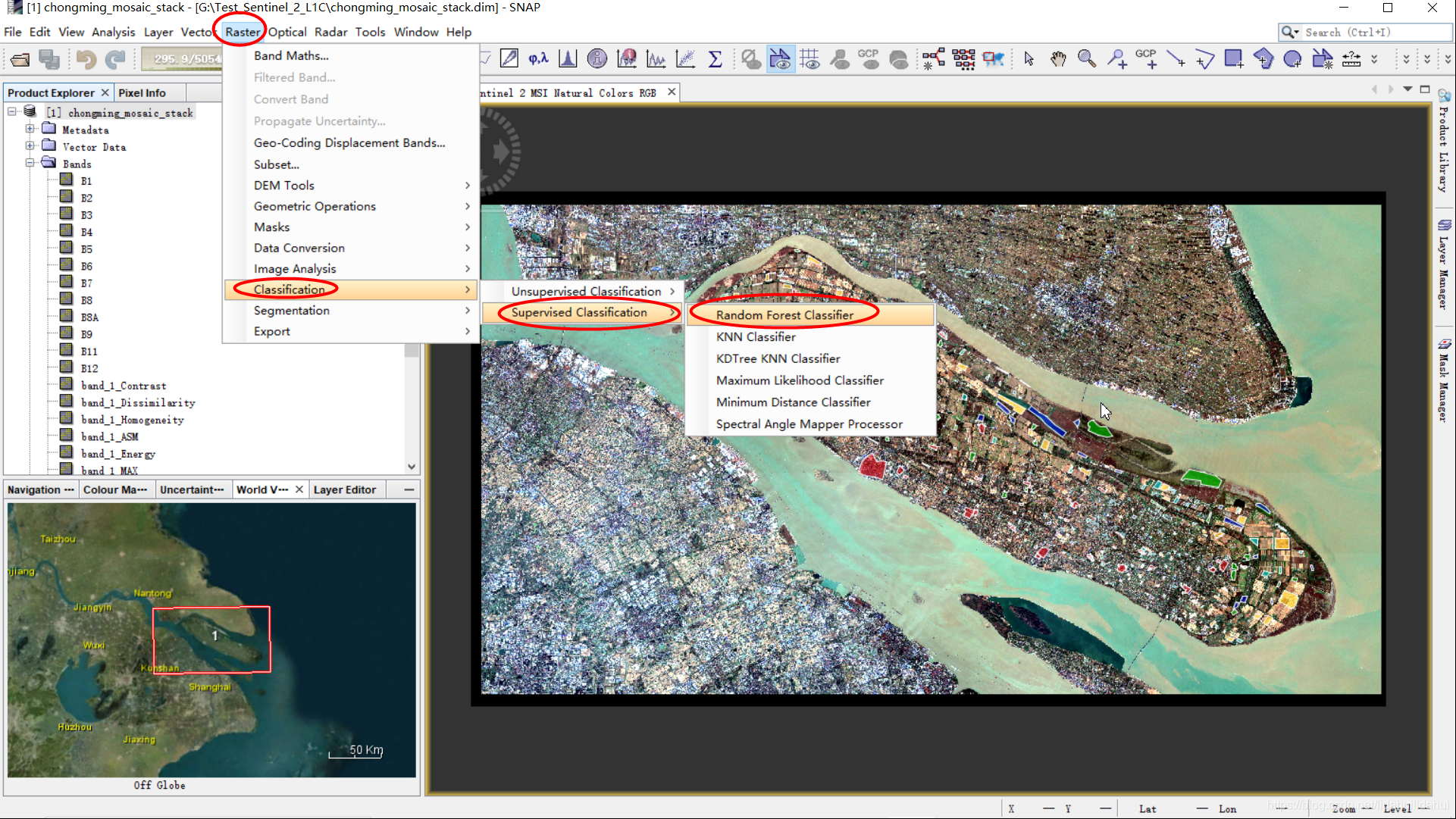
选择数据集
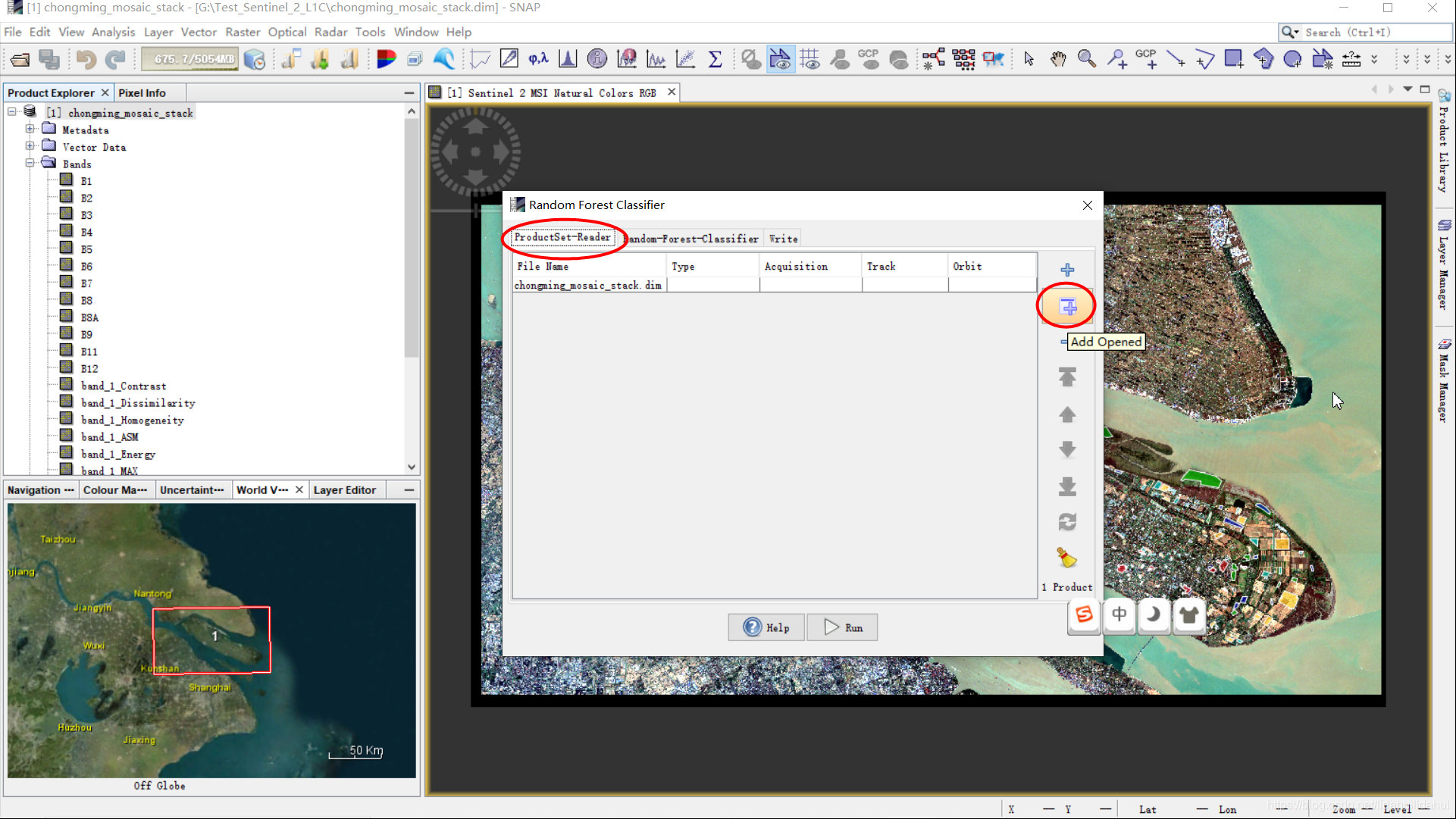
创建随机森林分类训练器
如果你接触过随机森林算法或者决策树等算法,你会知道其实该分类器有很多影像分类精度的超参数。不过,实际上SNAP随机森林分类训练器只需要设置很少的参数,这里比较重要的是Number of training samples(应该是划分的最大样本集数量,这个不是很确定,没看到官方的详细说明,这里保持默认就好)和Number of trees(树的数量)两个参数,随机森林分类算法涉及到其它的参数,算法有默认值。
通常树的数量越大,精度越高,但是越往后,越难提高(而且提高多少也很难确定),但代价是耗费的时间也多。Number of trees树的数量不宜超过300。
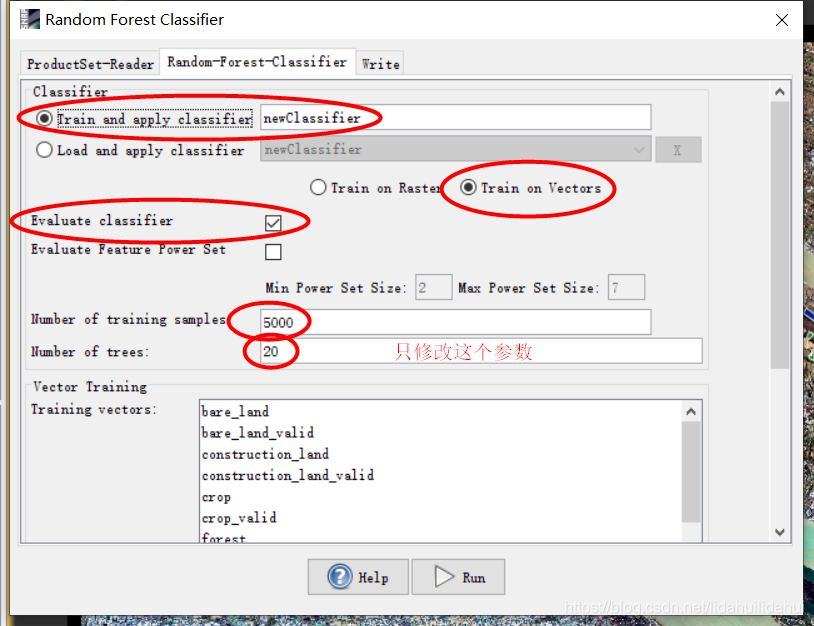
选择用于分类的训练样本(矢量数据)集(不要选带_valid后缀的样本验证集)以及所使用的特征波段:
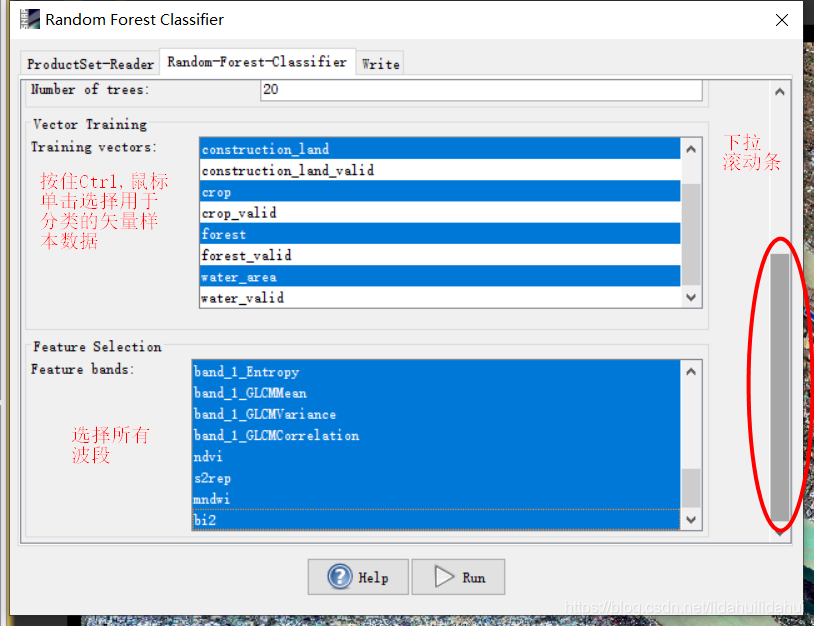
输出数据集
保存默认即可。
上述三个参数面板均设置完毕后,点击Run即可。即可进行随机森林分类。大概一小时多些后可以看到分类的结果(具体时间视数据量,电脑配置,分类参数设置等有关)。
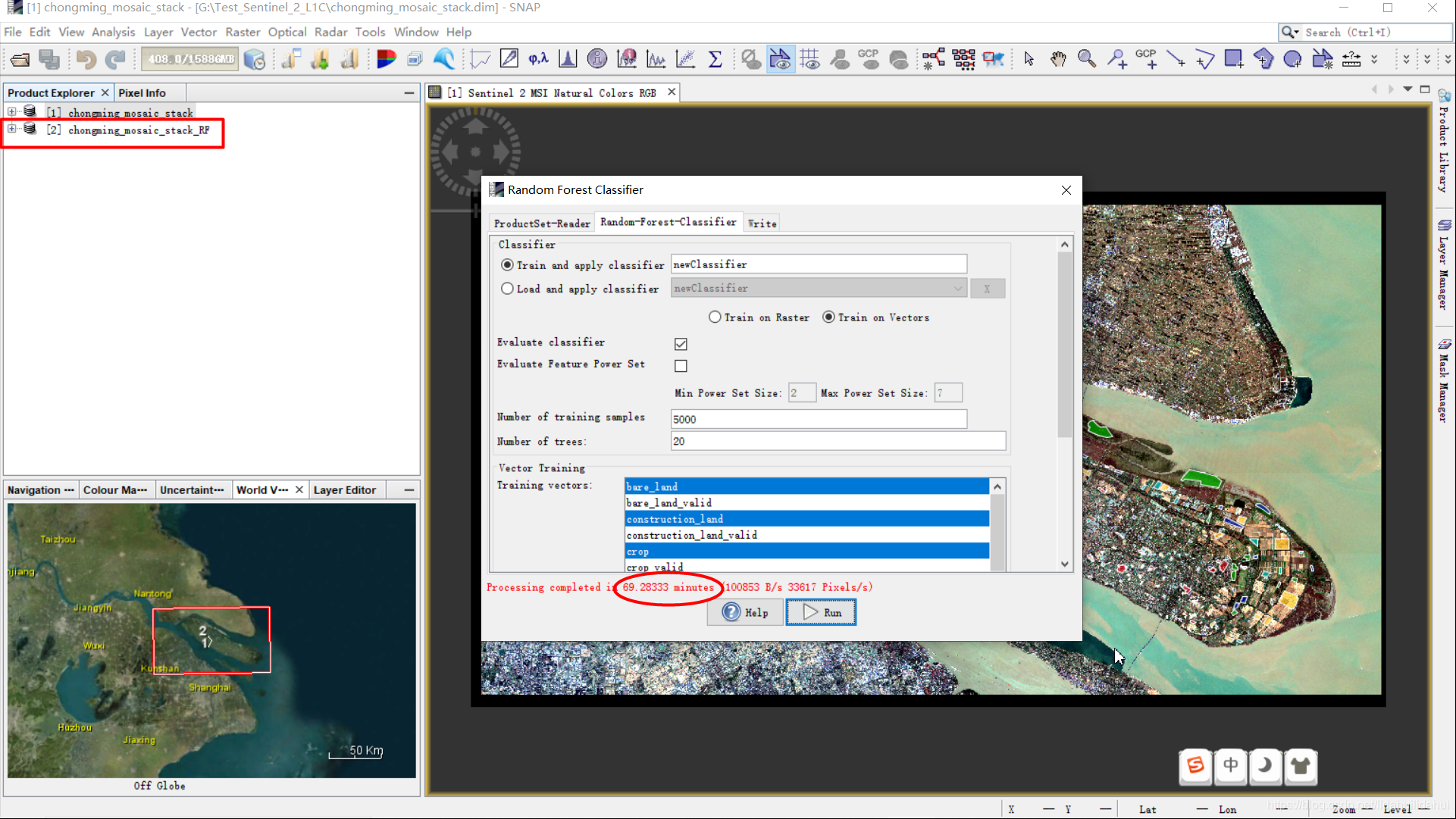
分类结束后,还会自动打开一个newClassifier.txt文本文件,可以看到分类器的训练情况:
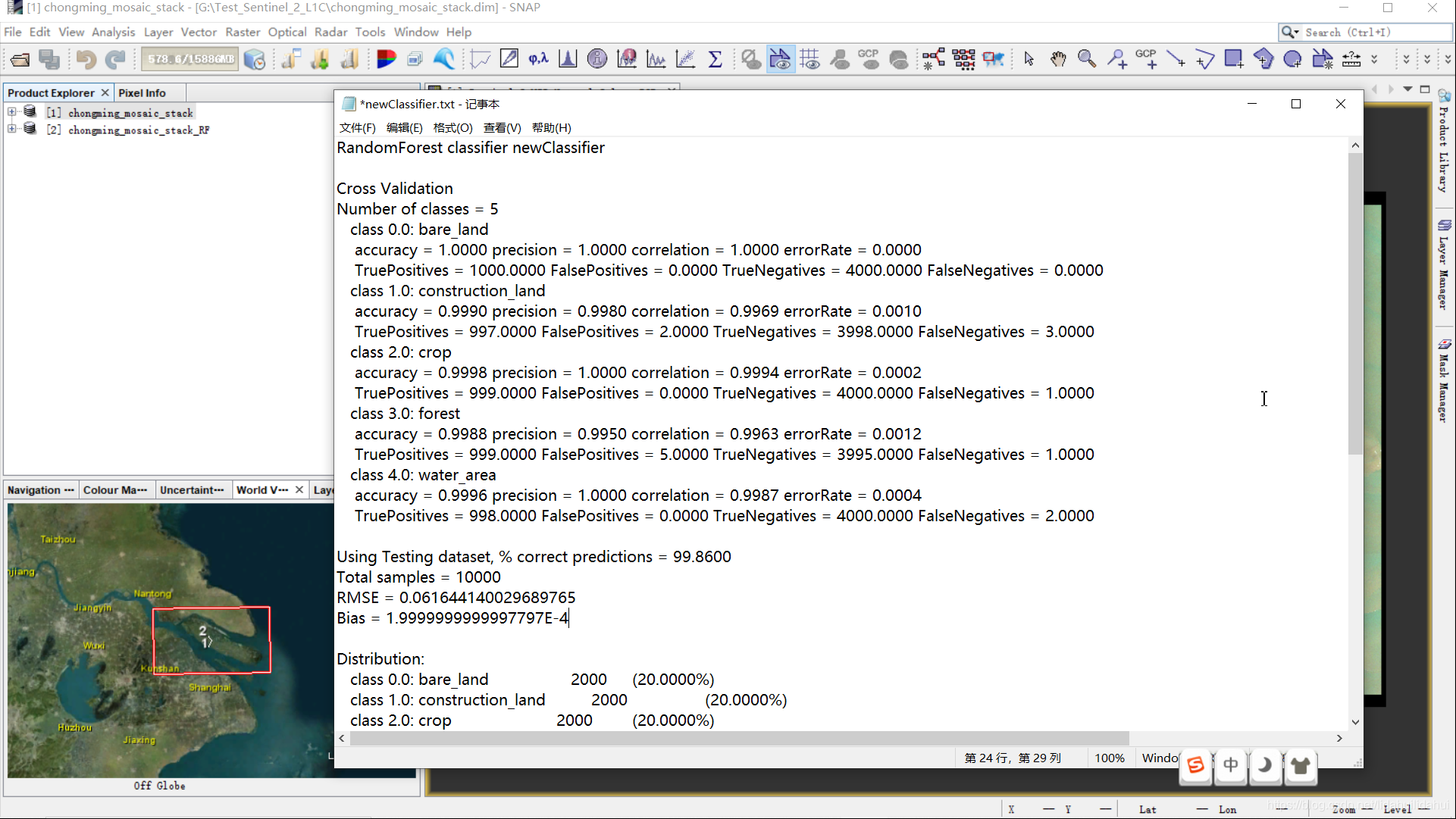
该分类器文档文件newClassifier.txt含有一些重要的指标,例如论文中常见的特征重要性得分以及排序。
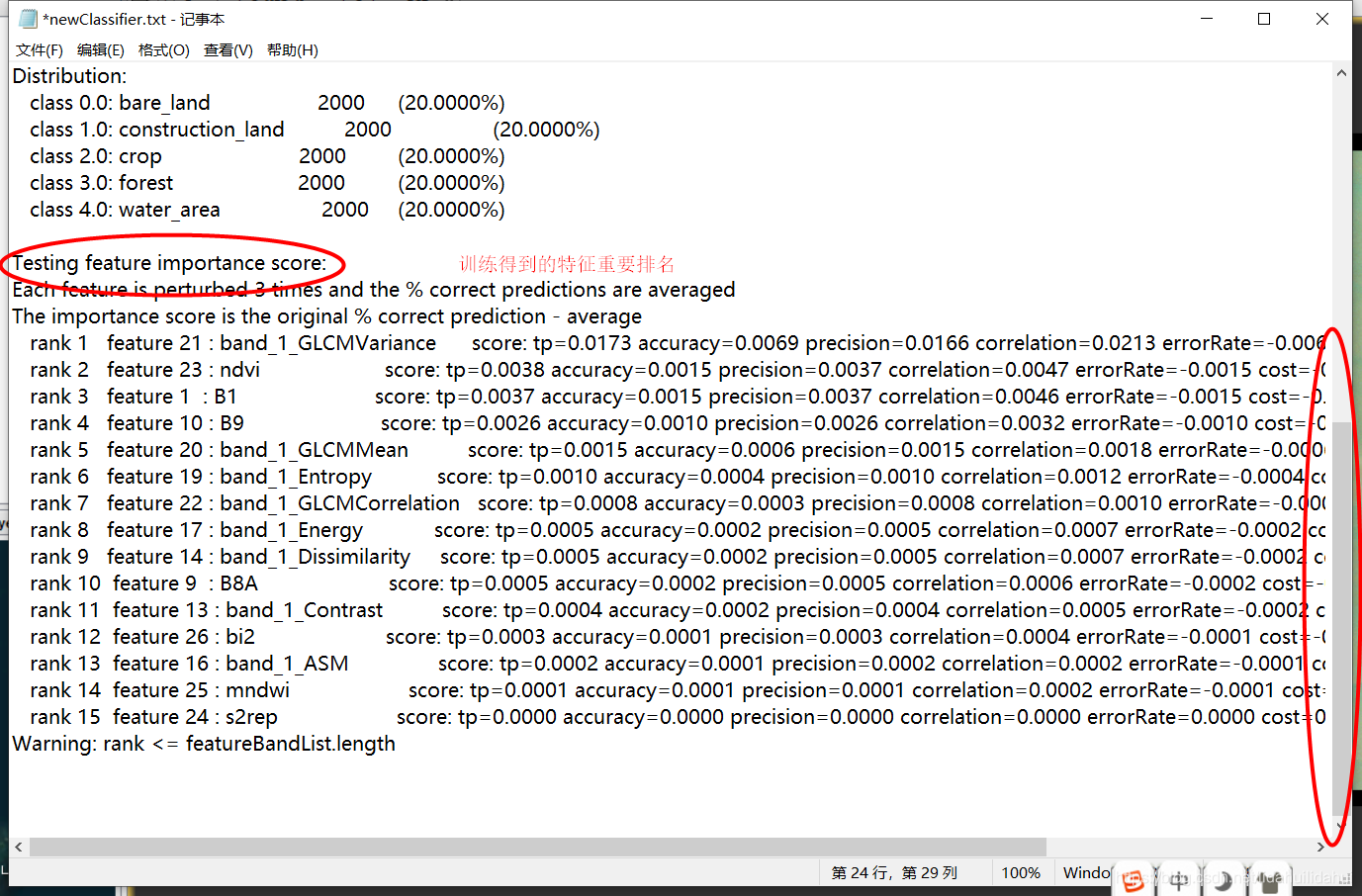
该newClassifier.txt文间默认存放在下图所示的路径:
分类结果
关闭随机森林分类器窗口以及其对应的分类器.txt文件。在数据集2下Band文件夹下可以找到LabeledClasses这个波段。
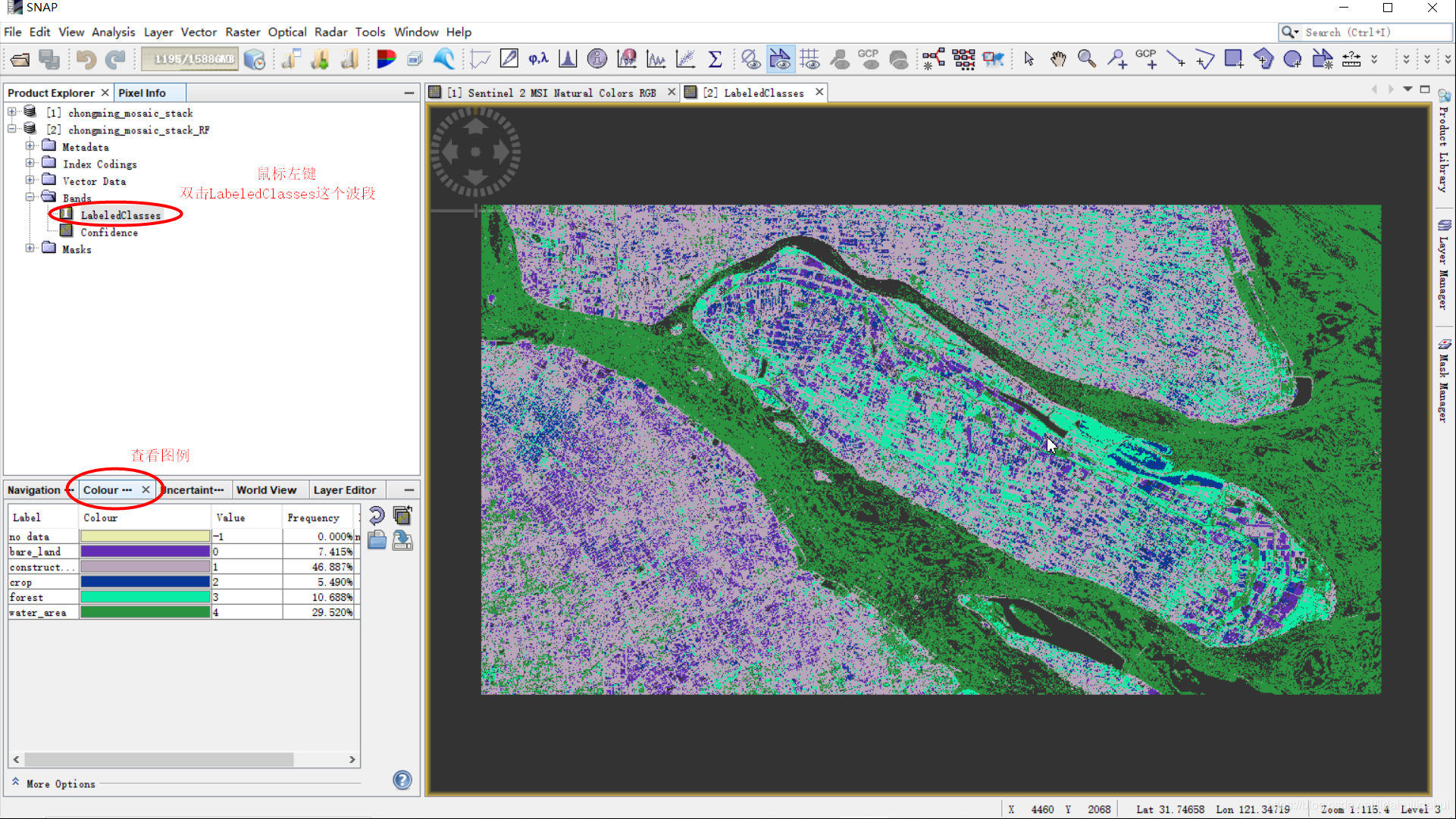
在Colour Manipulation(颜色操作面板),设置地物类别的颜色,与训练(验证)样本对应。
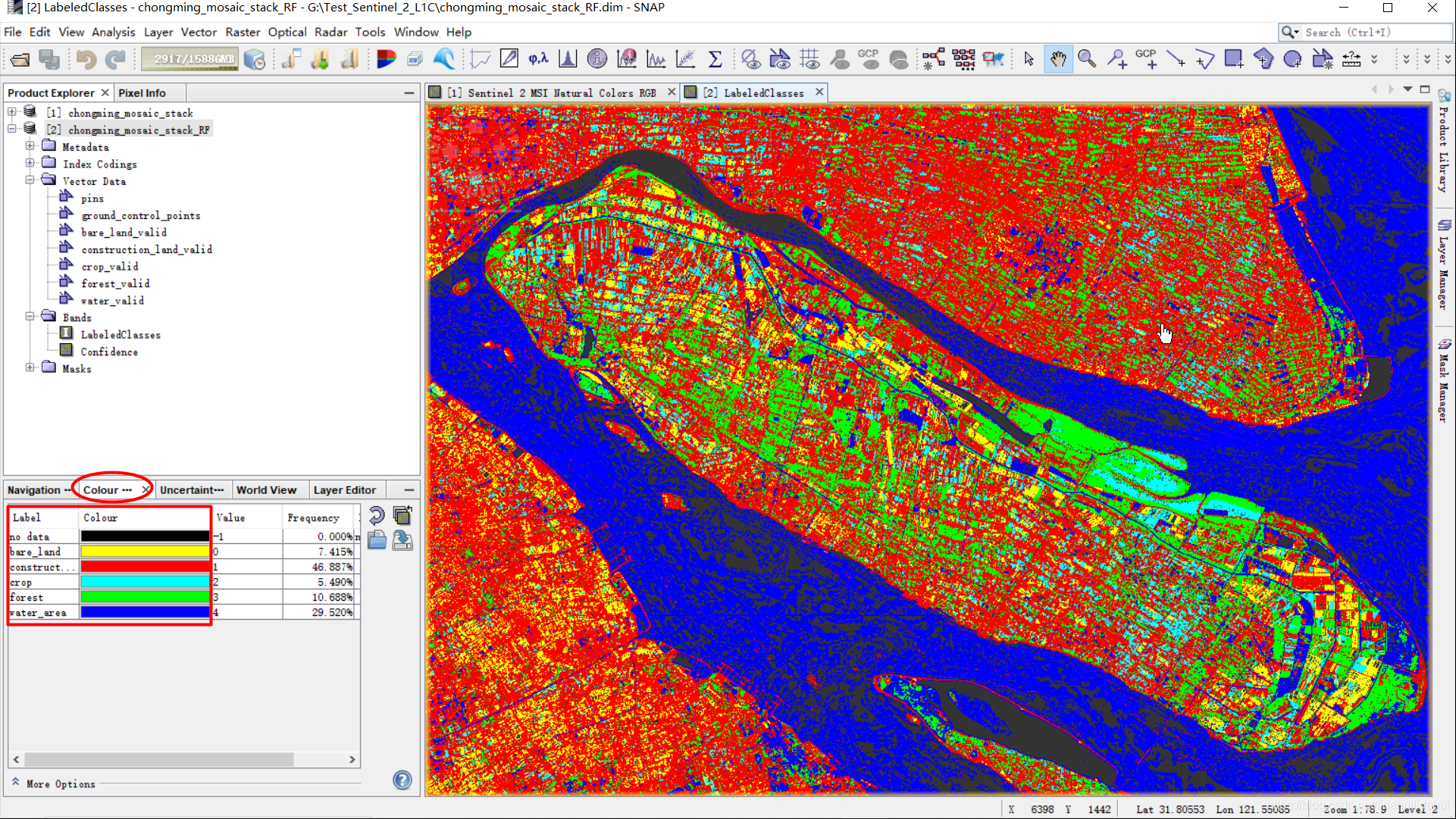
定性比较
和真彩色合成图对比
先取消训练样本在真彩色合成图上的显示。
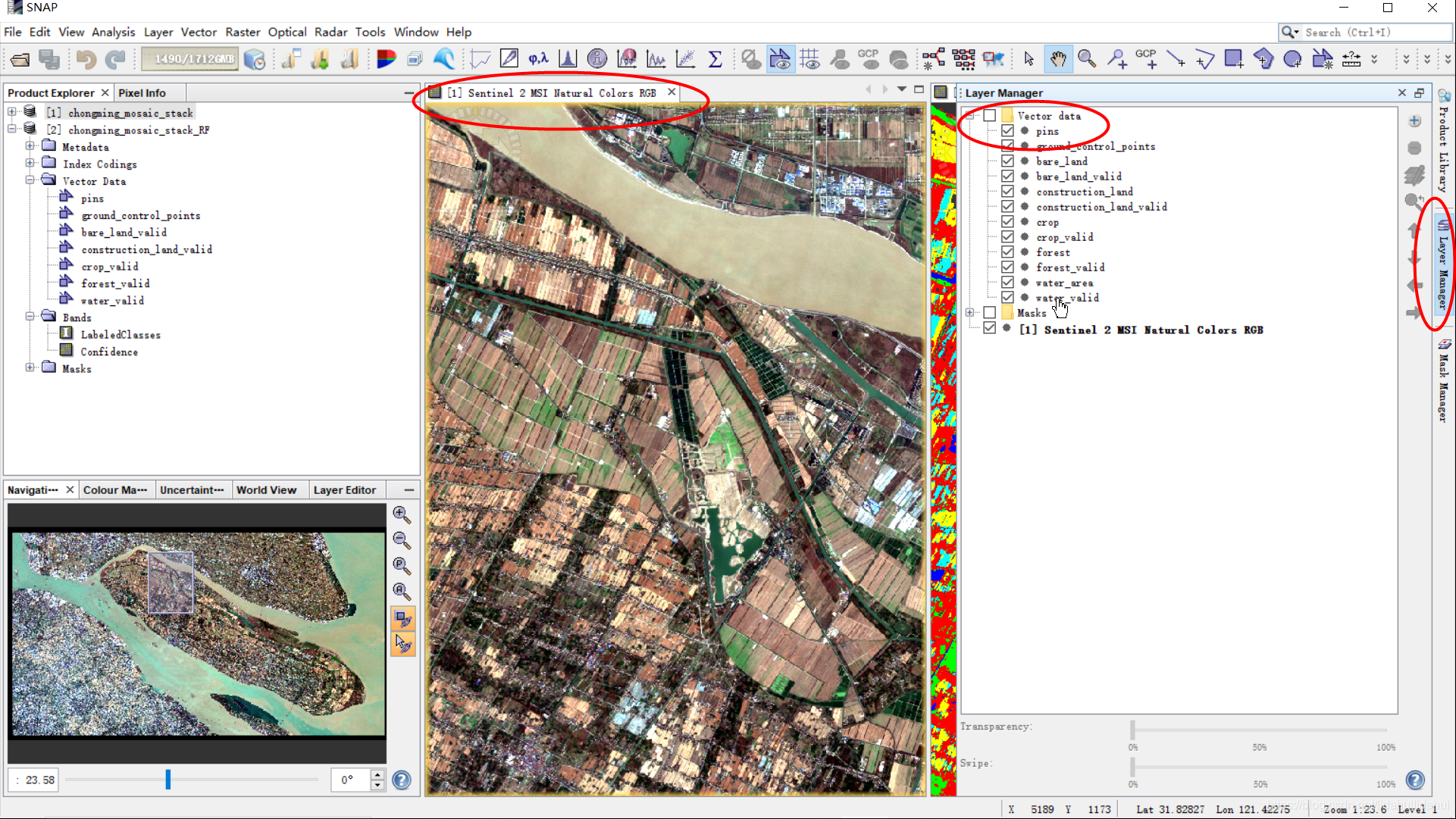
将两个数据集水平分屏显示(Windows—>Tile Horizontally),随后关闭矢量图层的显示:
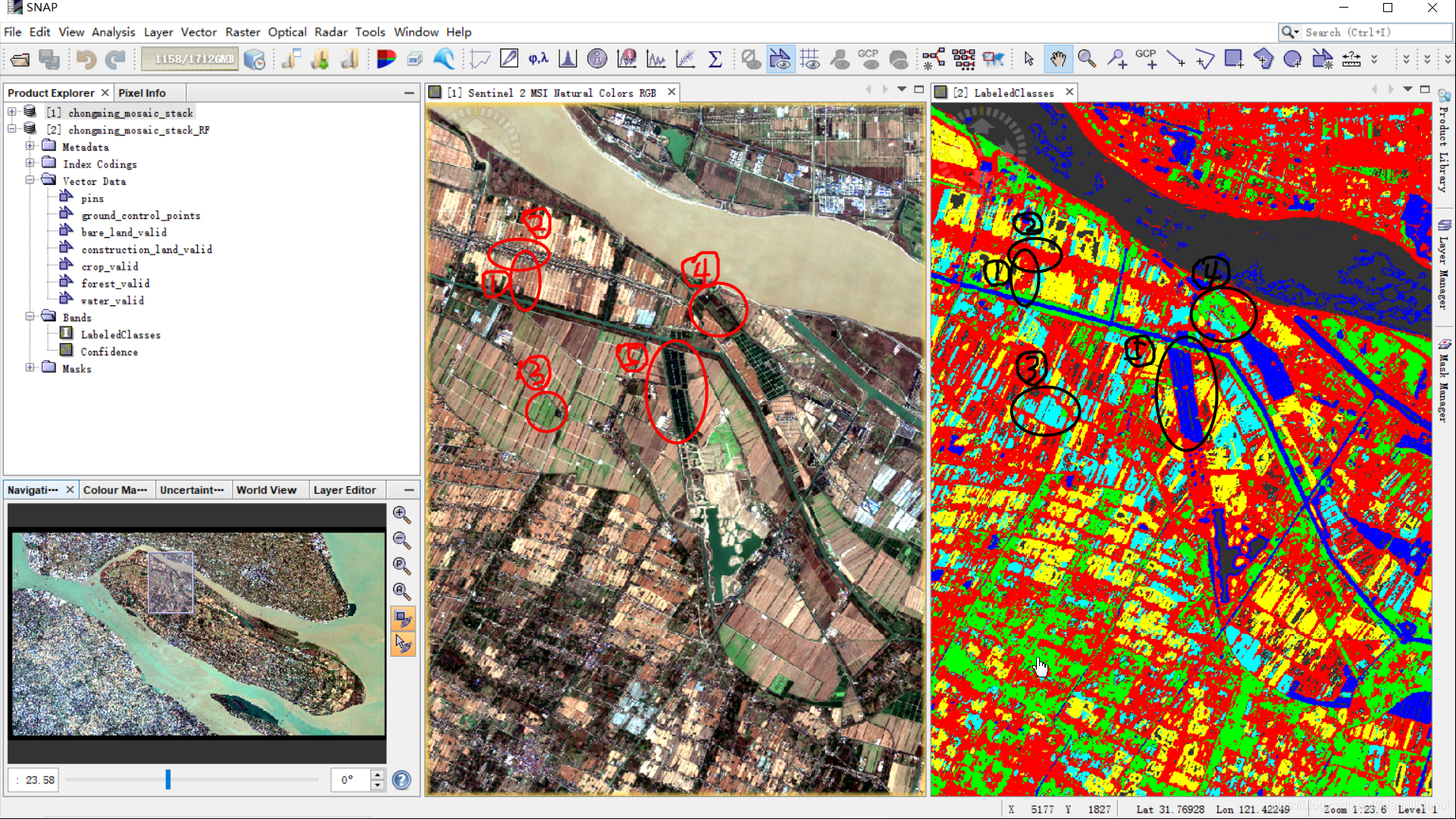
崇明岛局部对比。可以看到裸地(bare_land,圈1)中有一部分被错分为建设用地,建设用地分类基本准确(圈2),农用地基本分类准确(圈3),林地分类基本准确(圈4),鱼塘、河道等水体(圈5)基本准确(右图LabeledClasses水体中的灰色部分是NaN值,原因是部分特征可能存在一些缺失值或者异常值)。
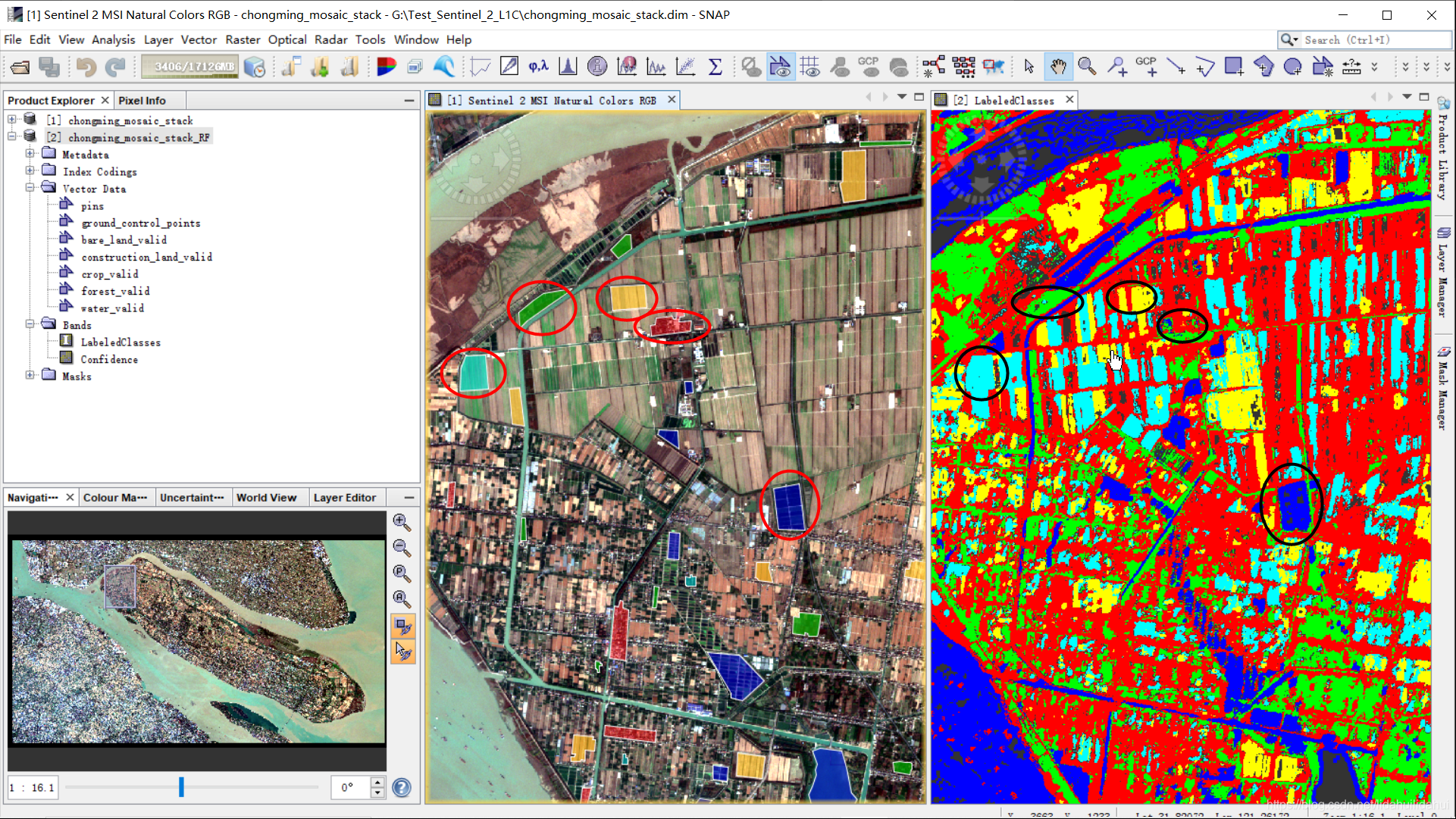
和训练样本对比
再看看加上训练样本,看下效果(崇明岛局部):
分类结果评价
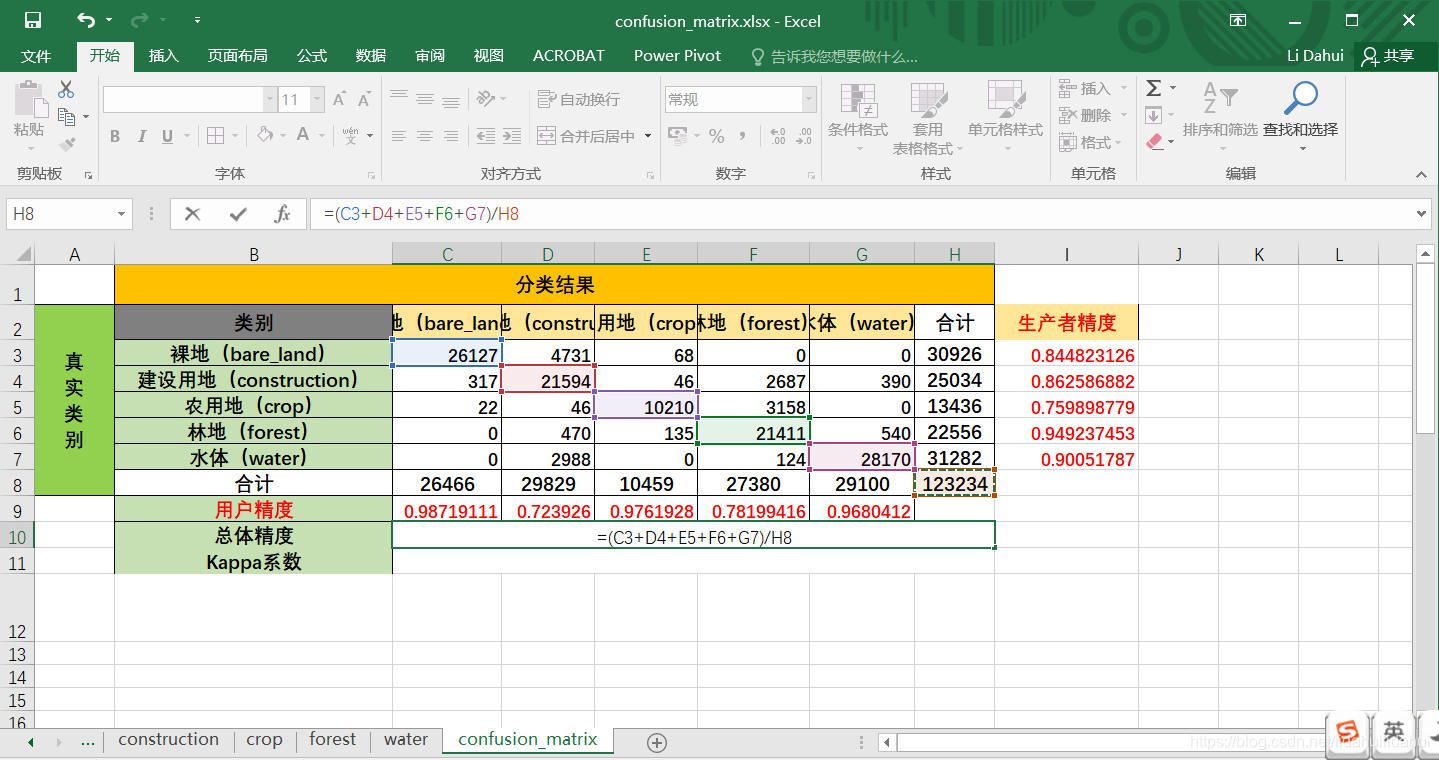
前面的结果展示仅仅是定性的比较,更严谨的话,需要用到定量评价,这里最常用的混淆矩阵方式进行评价。
很遗憾地告诉你,SNAP并没有直接的分类精度评价功能,这个,有用户向SNAP官方反映过,可能迟点官方会增加这个功能。不过,确实有一些方法可以间接获取建立监督分类的混淆矩阵,用于评价该监督分类结果。接下来,我们利用SNAP的掩膜图层统计(或者说是ROI统计)功能(有点类似GIS软件的栅格图像的区域统计)创建混淆矩阵。
思路:因为SNAP中创建的样本数据(矢量容器数据集)是以文件名区分,而分类后的LabeledClasses是一个索引值栅格值(栅格值是整数值,每个整数代表一类地物)。并且SNAP允许我们通过一个矢量图层(掩膜)来构建直方图。这样,我们将每一个地物验证样本数据作为一个掩膜图层,在分类后的LabeledClasses栅格影像对该验证样本覆盖范围的像元值执行直方图统计,即可以得到该类地物在LabeledClasses的分类结果(监督算法得到的预测值)。只要对每类地物进行一次这样的直方图统计,即组合成混淆矩阵,进而计算总体精度和Kappa系数等指标。
创建混淆矩阵
先关闭数据集1。如果你认真观察随机森林分类得到的数据集2,会发现其Vector Data(和Mask)文件夹相比数据集1少了训练样本矢量图层,仅有检验样本图层保留下。
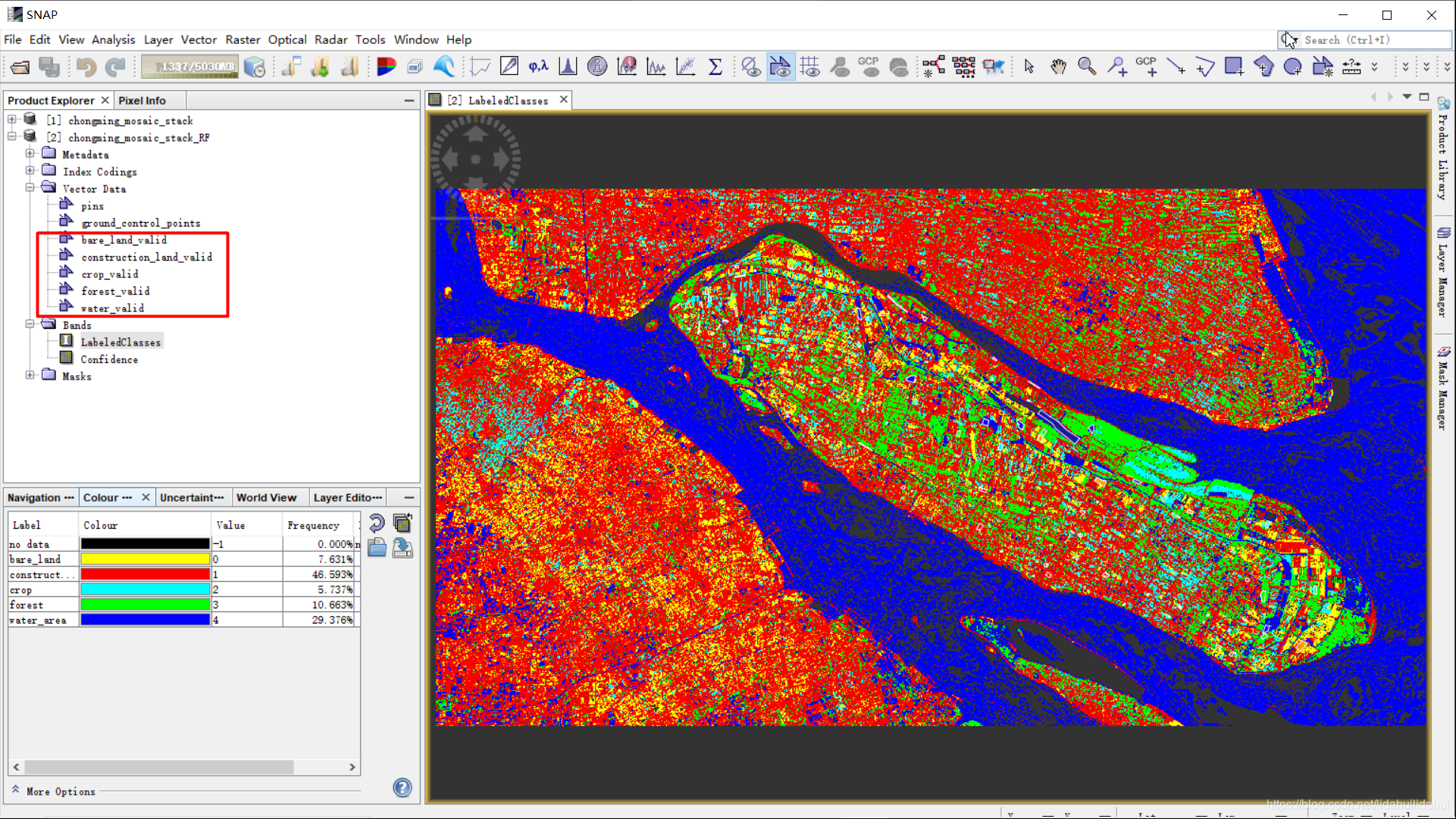
在分类时创建的检验样本已经保留下来,不用我们再次导入,这很好!我们已经有了ROI掩膜图层数据。
掩膜图层直方图统计
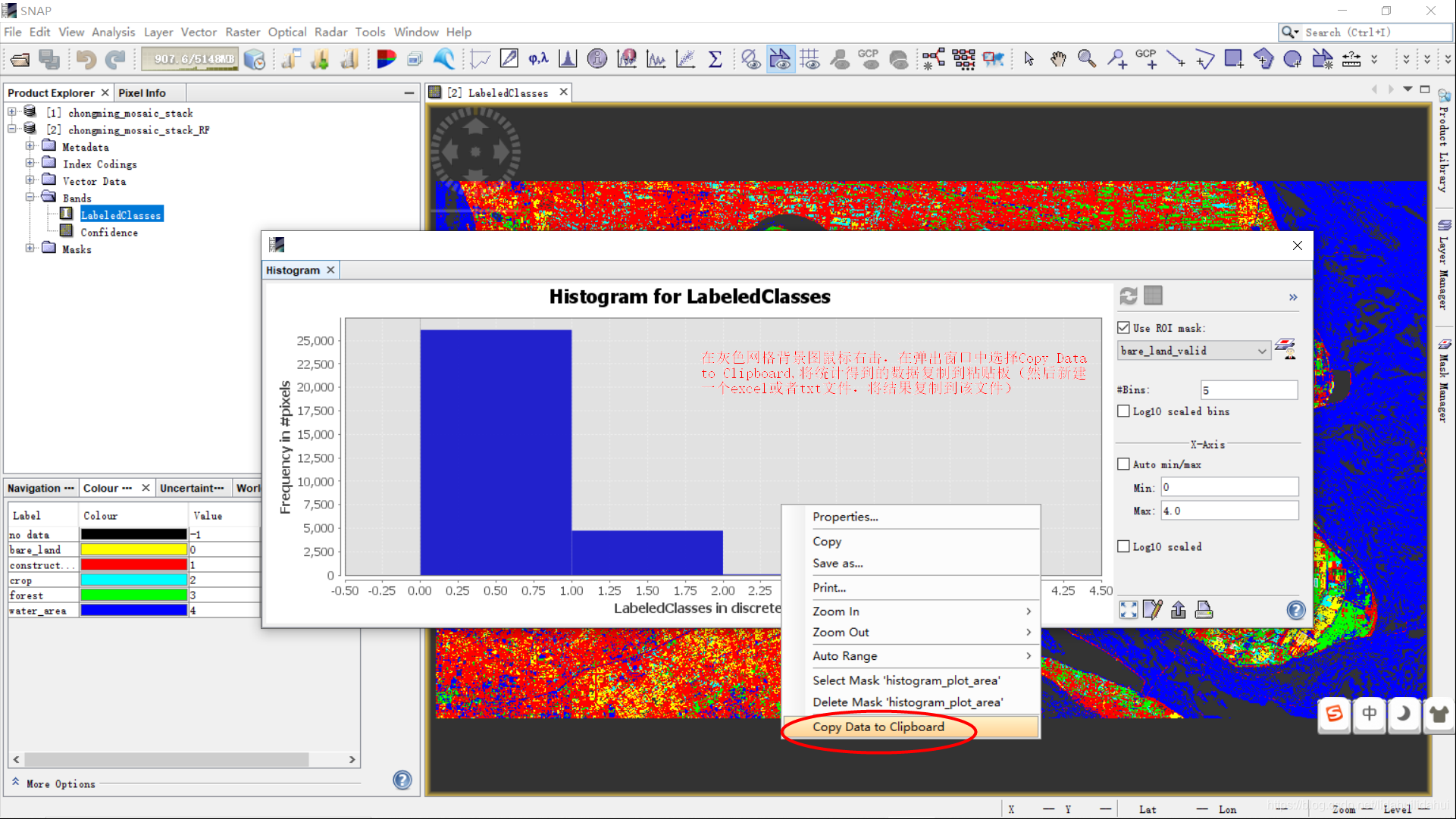
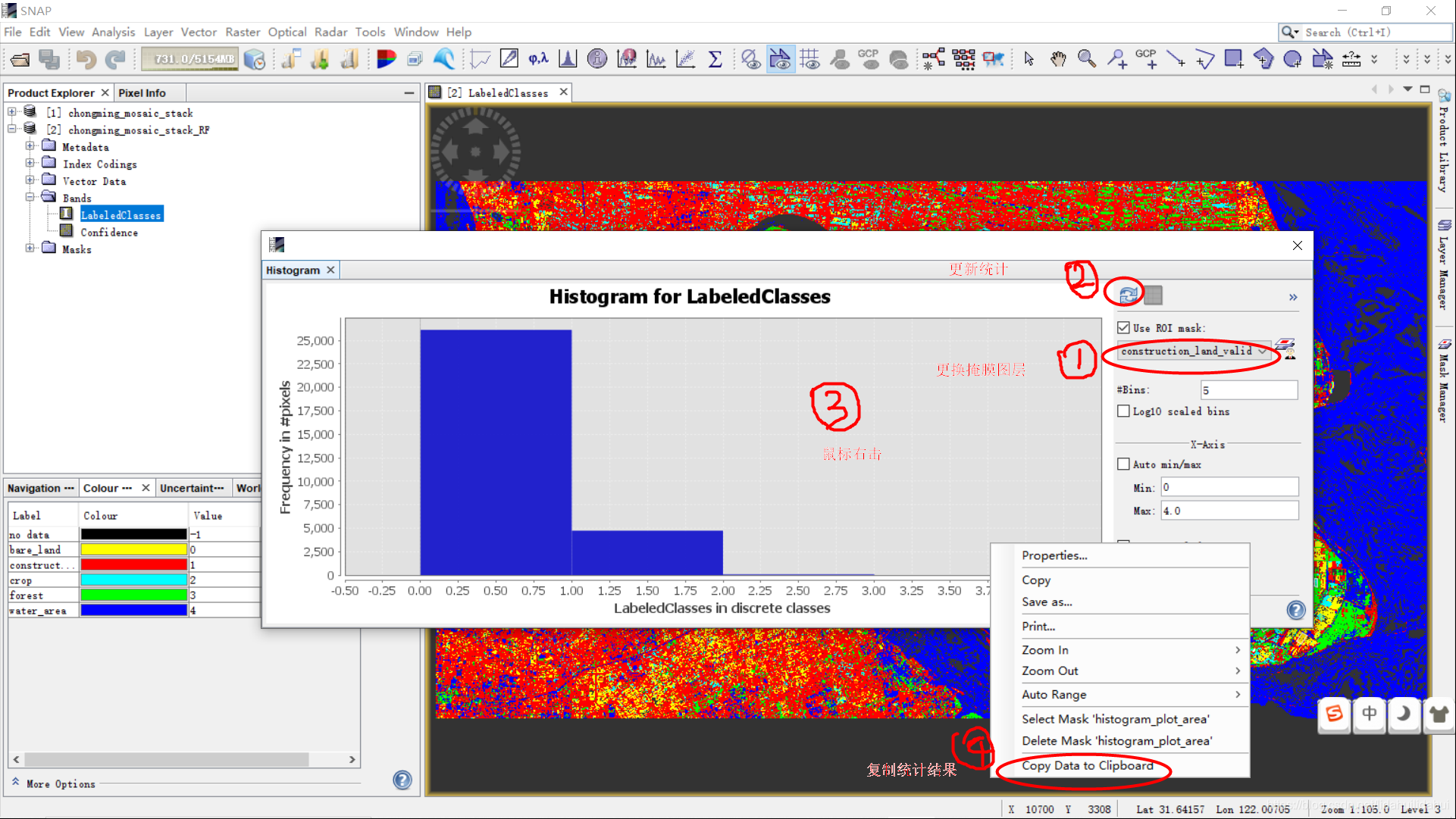
在菜单栏下Analysis—>Histogram下,可以打开栅格直方图统计功能(你可以看下灰色网格背景的提示语):
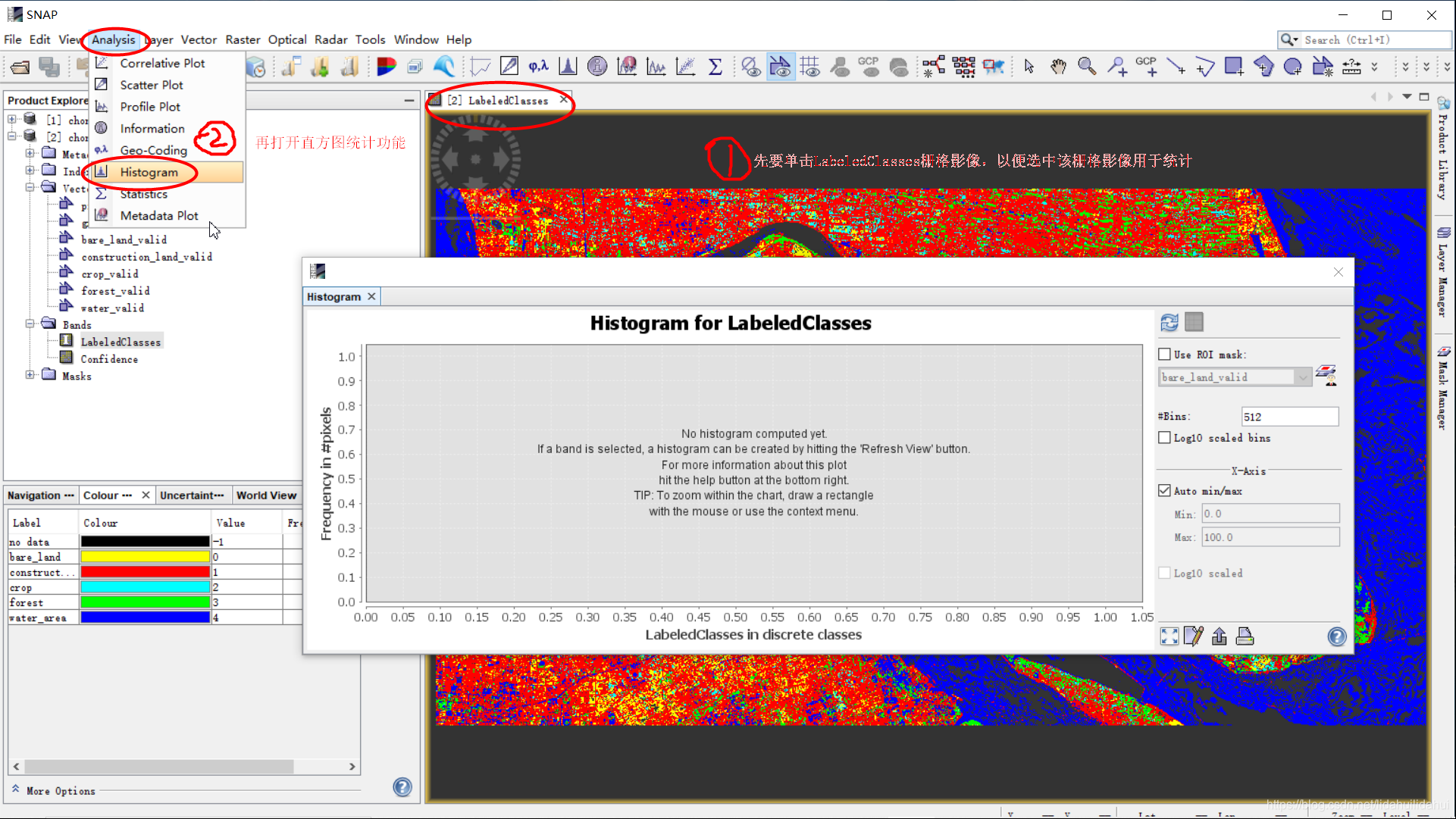
因为默认的直方图统计统计索引,画出的图以及导出的数据都不是很好。所以我们需要修改一下直方图统计作图属性,见下图:
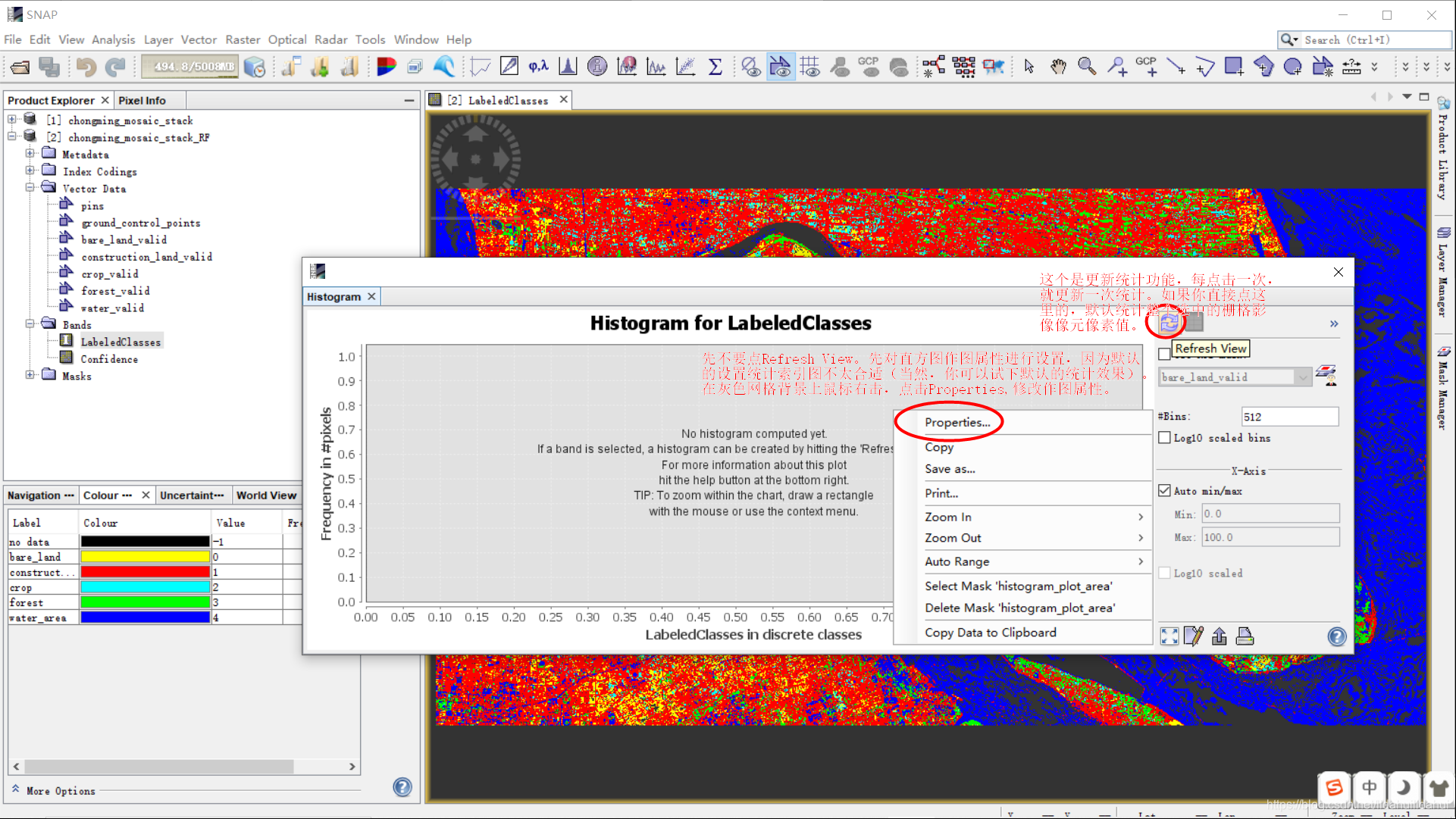
我们需要根据分类得到的LabeledClasses索引图像元值范围调整,后来我发现,掩膜图层范围里没有-1(缺失值的情况),其值范围为[0, 4]。我们略微调大一点调整直方图的显示的x坐标轴范围为[-0.5, 4.5]。按下图修改后,点击OK!
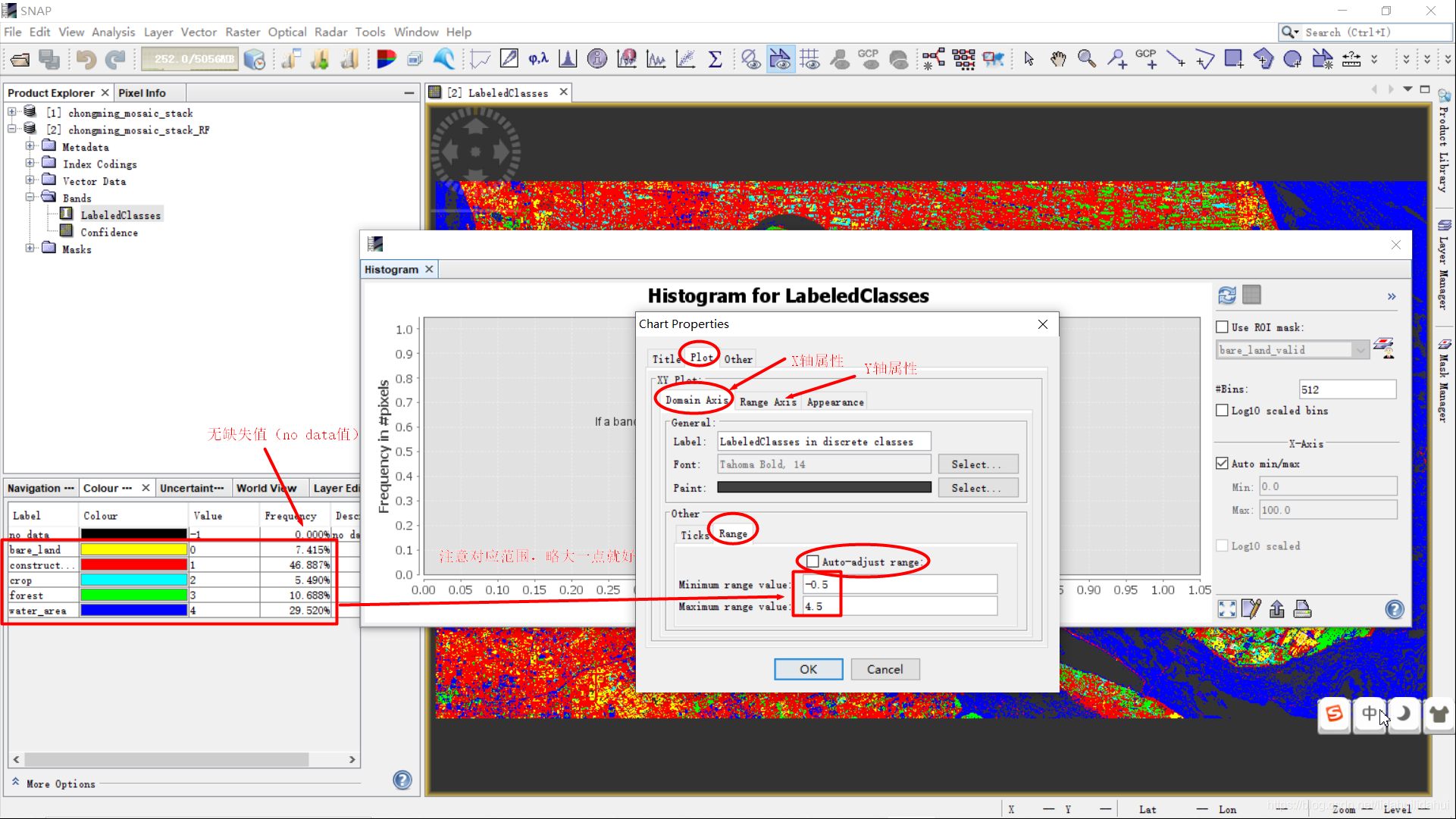
还需要选择ROI掩膜图层,修改统计的区间个数,这里应该为5(因为只有索引值0,1,2,3,4 ,共种情况)。你需要结合你的实际分类类别数目情况自己修改一下。下图中的Bins,Min和Max需要和索引图地物类别数目,最小值和最大值对应,否则会得到错误的统计结果。
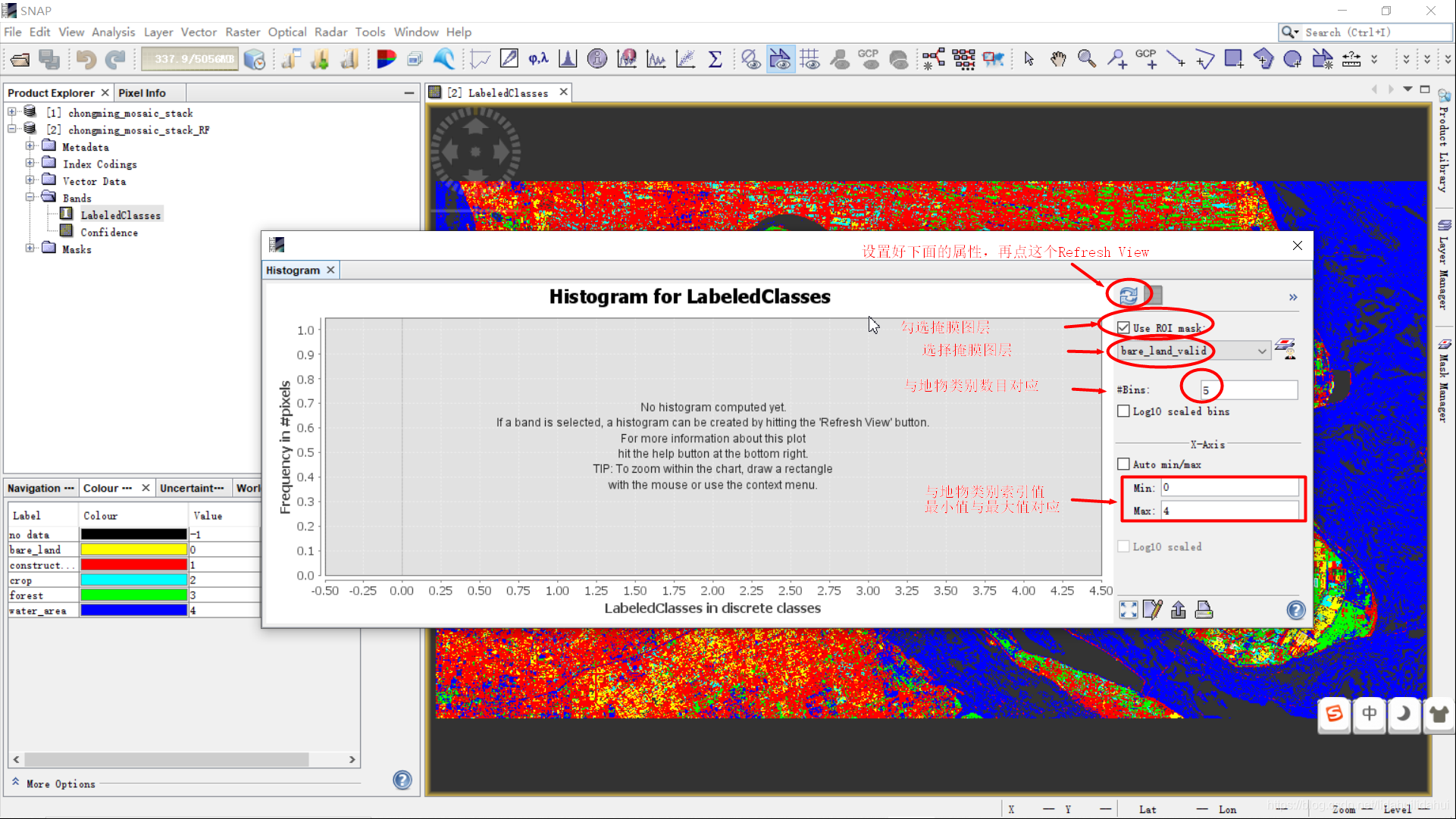
点击Refresh View即可得到该掩膜图层(ROI区域)范围的直方图统计(上图是bare_land_valid图层)。
我们新建一个excel文件,命名为confusion_matrix.xlsx,将上述的粘贴板的数据粘贴表bare_land。可以看到该结果。
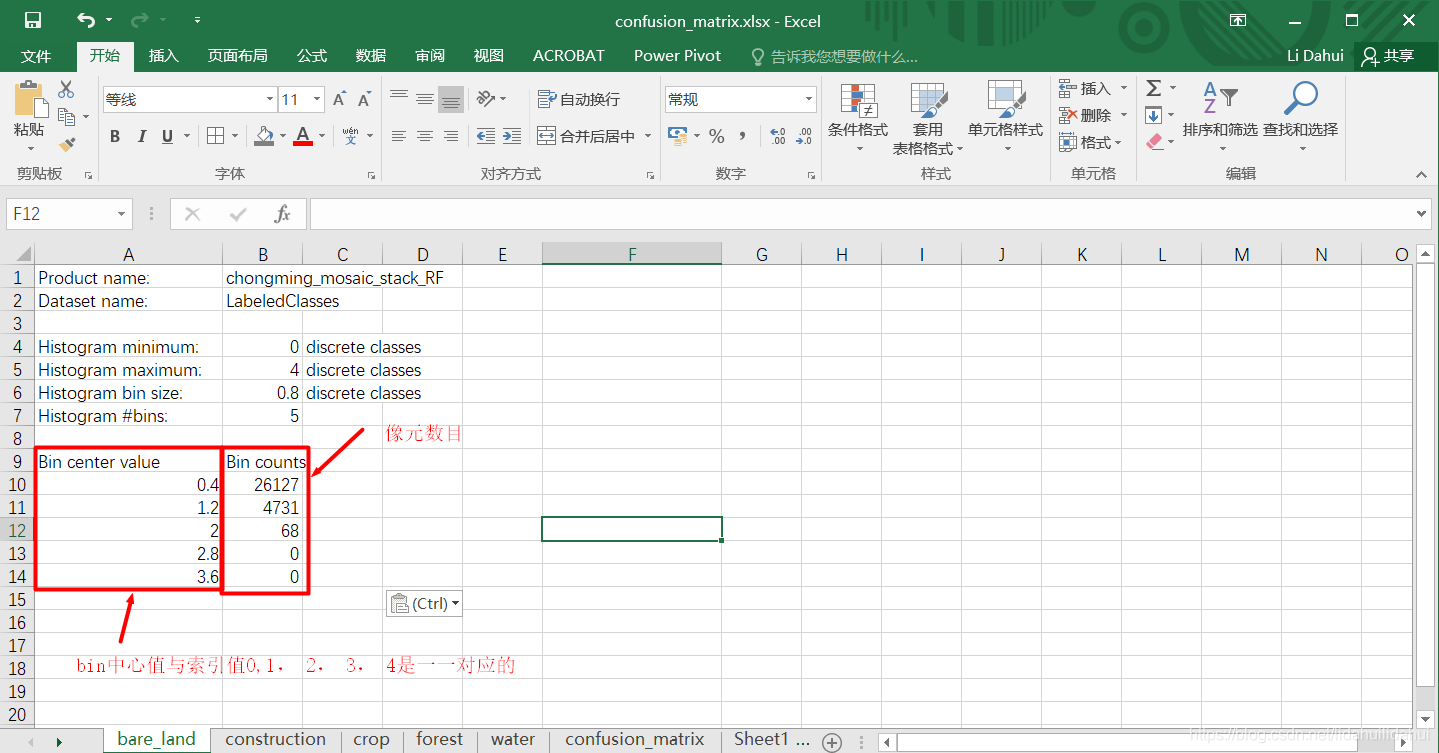
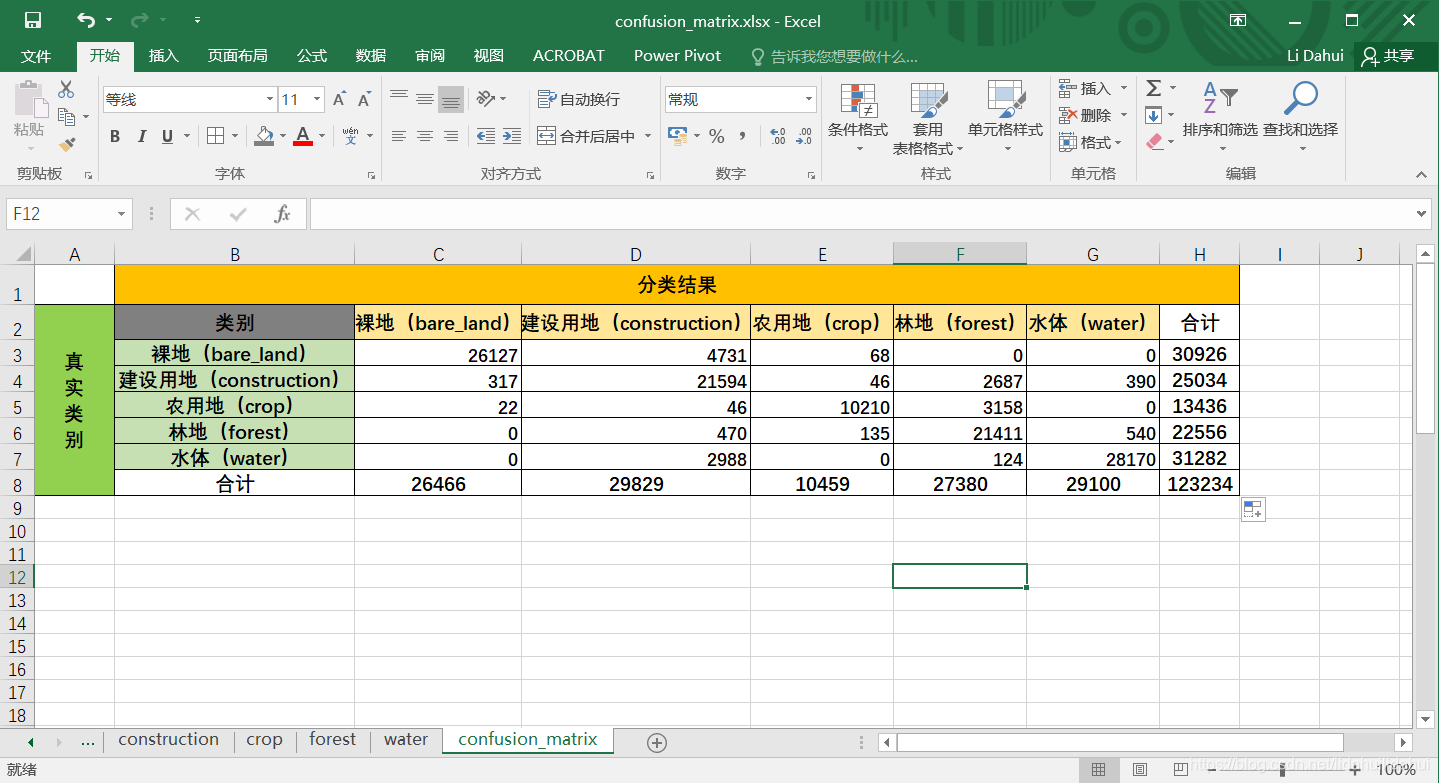
该统计表的结果显示,表示真实地物为裸土(bare_land)的像元中,26127个被分为裸土(bare_land),4731个被分为建设用地(construction),68个被分为农用地(crop),0个被分为林地(forest),0个被分为水体。将Bins counts列(后5个值)复制以转置复制到混淆矩阵的第一行上(图中红色框部分)。
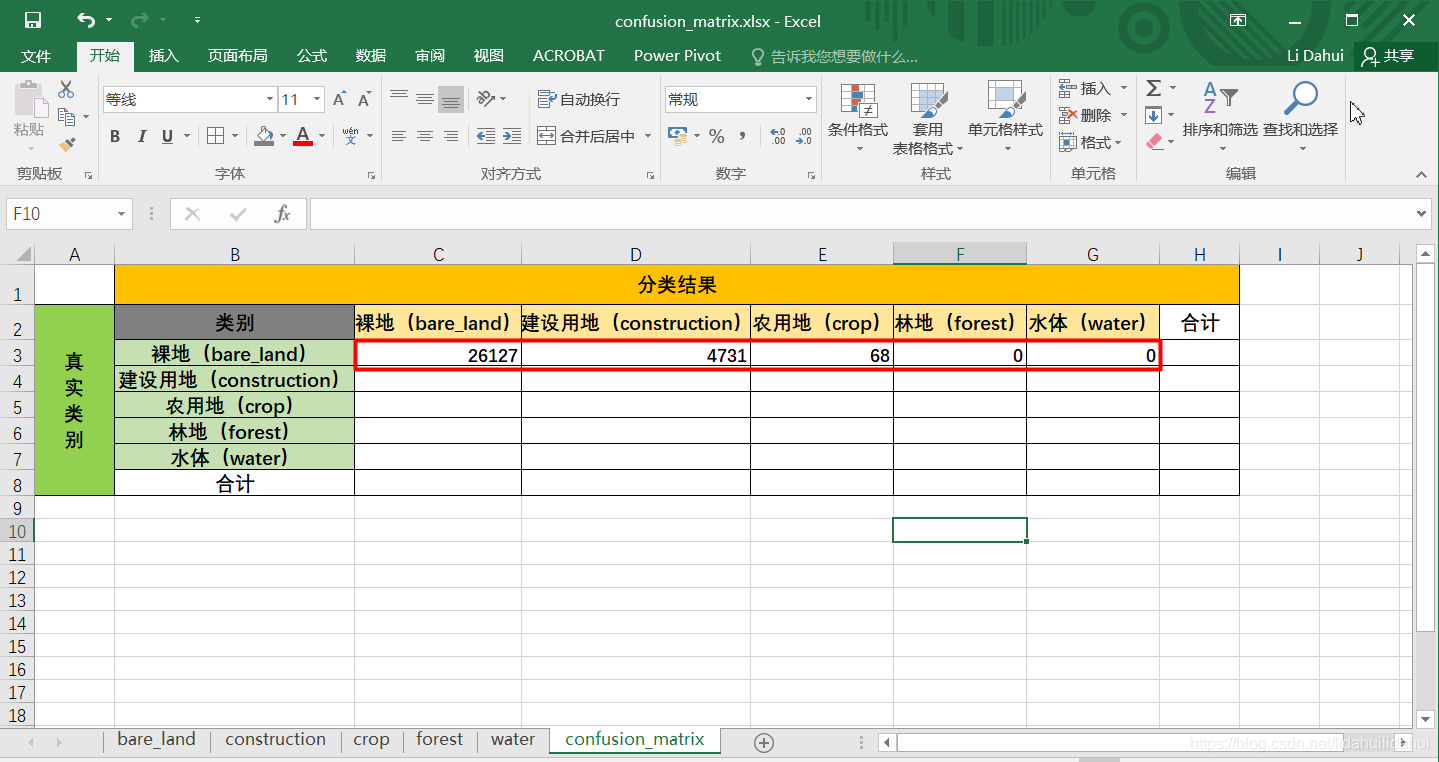
对其它四个验证样本执行同样的掩膜图层统计。
即可以利用这些直方图统计结果建立起我们的混淆矩阵,最终可以得到以下的混淆矩阵:
总体精度与Kappa系数计算
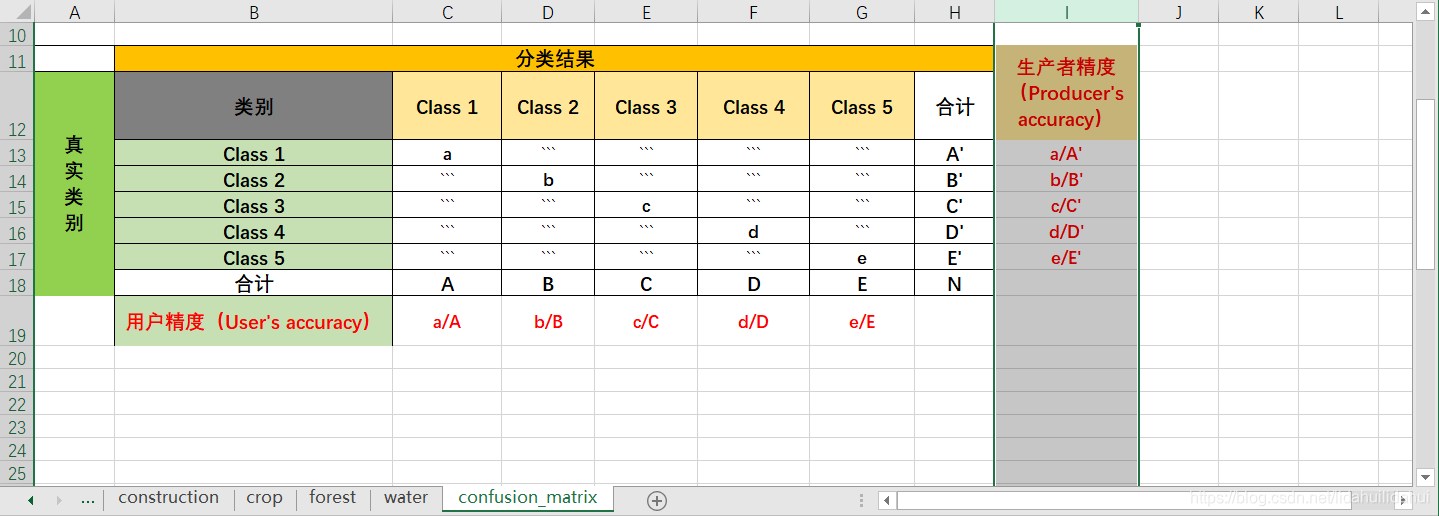
为了说明总体精度与Kappa系数是如何计算,下图建立一个虚拟的混淆矩阵,如下:
总体精度
其中,N=A+B+C+D+E=A’+B’+C’+D’+E’。
Kappa系数
其中,
上面的两个指标在得到混淆矩阵都可以计算得到,最终可以利用Excel可以得到下表:
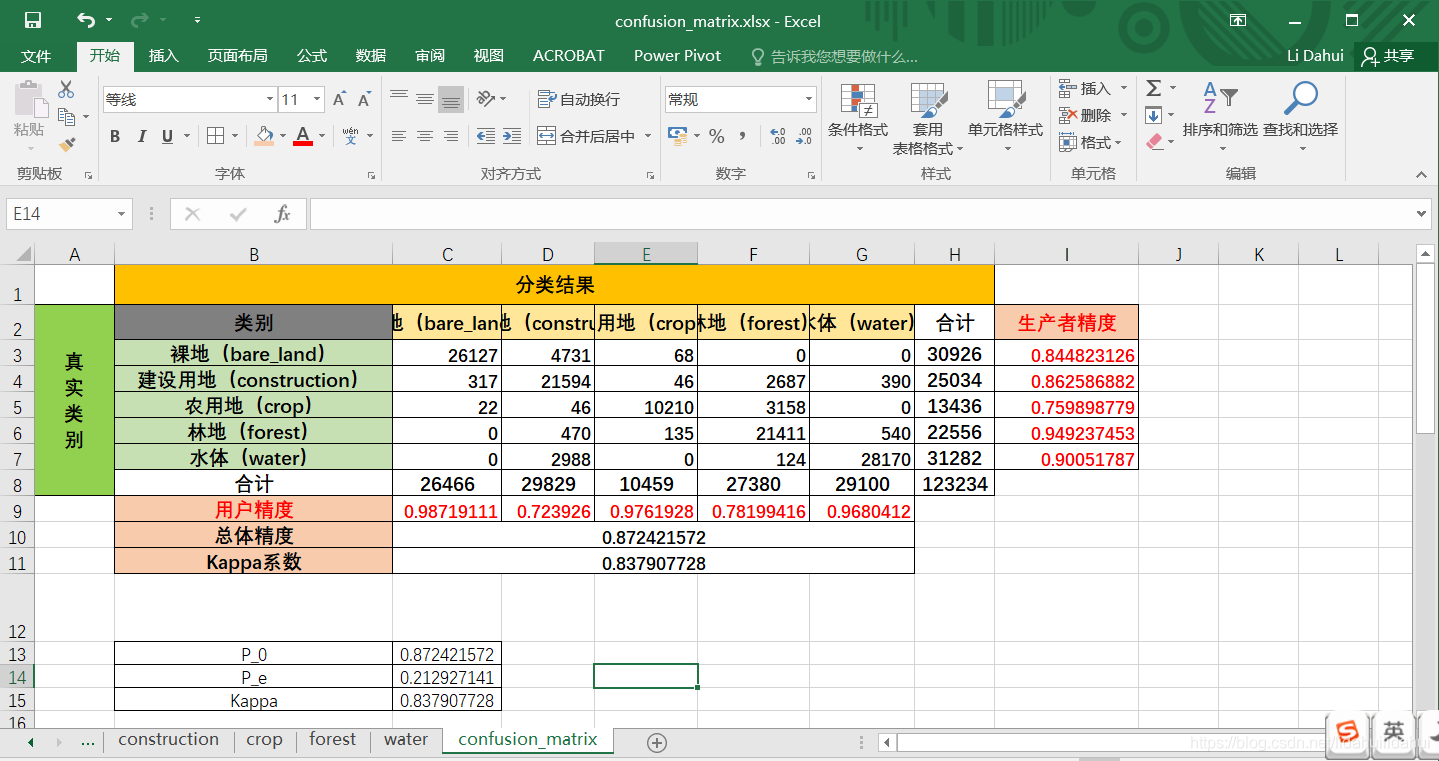
看来分类结果很可以。尽管我所选的地物类别有些少,并且,我在勾选样本时是凭经验选的,这不是很正确的,更可靠的办法是实际测量。
如果你将混淆矩阵保存为以下格式的csv文件,也可以使用我用numpy编写的Python程序(需要numpy库支持)来计算用户精度,生产者精度,总体精度,Kappa系数。confusion_matrix_py.csv的元素和上面的excel文件矩阵元素是一一对应的。列表示真实地物,行表示分类结果。confusion_matrix_py.csv文件内容如下:
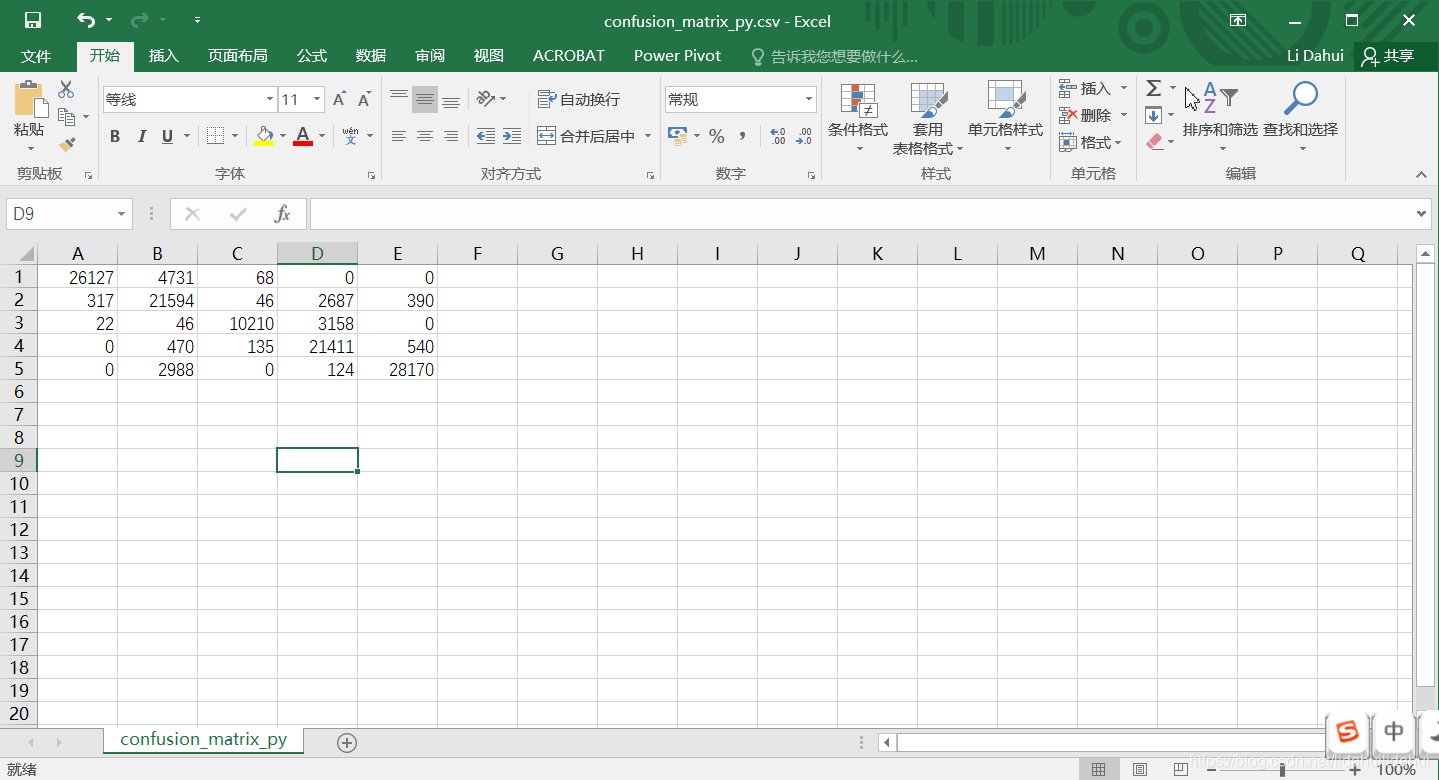
Python代码如下:
import numpy as np
# 导入混淆矩阵文件,该混淆矩阵列表示真实地物类别,行表示分类地物类别
# 需要修改对应的路径名
confusion_matrix = np.loadtxt('G:\Test_Sentinel_2_L1C\confusion_matrix\confusion_matrix_py.csv', delimiter=',')
# 'bare_land','construction','crop','forest','water'
# 分别代表地物裸土,建设用地,农用地,林地,水体
label=['bare_land','construction','crop','forest','water']
#计算用户精度函数
def get_user_accuracy(confusion_matrix:np.ndarray)->np.ndarray:
# 获取混淆矩阵对角线元素
(M, N) = confusion_matrix.shape
# 混淆矩阵是方阵M和N应该相等
if M!=N:
return None
diag = np.diag(confusion_matrix)
# 获取每一列和
col_sum = np.sum(confusion_matrix,axis=0)
return diag/col_sum
# 计算生产者精度
def get_producer_accuracy(confusion_matrix:np.ndarray)->np.ndarray:
# 获取混淆矩阵对角线元素
(M, N) = confusion_matrix.shape
# 混淆矩阵是方阵M和N应该相等
if M!=N:
return None
diag = np.diag(confusion_matrix)
# 获取每一行和
row_sum = np.sum(confusion_matrix,axis=1)
return diag/row_sum
# 计算总体精度
def get_overall_accuracy(confusion_matrix:np.ndarray)->np.float:
# 获取混淆矩阵对角线元素
(M, N) = confusion_matrix.shape
# 混淆矩阵是方阵M和N应该相等
if M!=N:
return None
# 对角线元素和
diag_sum = np.sum(np.diag(confusion_matrix))
# 所有元素和
matrix_sum = np.sum(confusion_matrix)
return diag_sum/matrix_sum
# 计算kappa系数
def get_kappa(confusion_matrix:np.ndarray)->np.float:
# 获取总体精度
P_0 = get_overall_accuracy(confusion_matrix)
# 列和与行和乘积和除以所有元素和的平方
P_e = np.sum(np.sum(confusion_matrix, axis=0) * np.sum(confusion_matrix, axis=1)) / np.square(np.sum(confusion_matrix))
return (P_0 - P_e) / (1 - P_e)
# 输出各类地物的用户精度
print("(地物类别,用户精度)")
print(list(zip(label, get_user_accuracy(confusion_matrix))))
# 输出各类地物的生产者精度
print("(地物类别,生产者精度)")
print(list(zip(label, get_producer_accuracy(confusion_matrix))))
# 输出混淆矩阵总体精度,保留5位小数
print("总体精度: {0:.5f}".format(get_overall_accuracy(confusion_matrix)))
# 输出kappa系数
print("kappa系数: {0:.5f}".format(get_kappa(confusion_matrix)))
分类后处理
分类后处理,可能涉及下面三个操作。区域掩膜可以在SNAP中直接完成,后两个可以利用QGIS(ArcGIS等GIS软件)或者OTB(ENVI等遥感处理软件)。我只介绍第一个操作。
区域掩膜(裁剪)
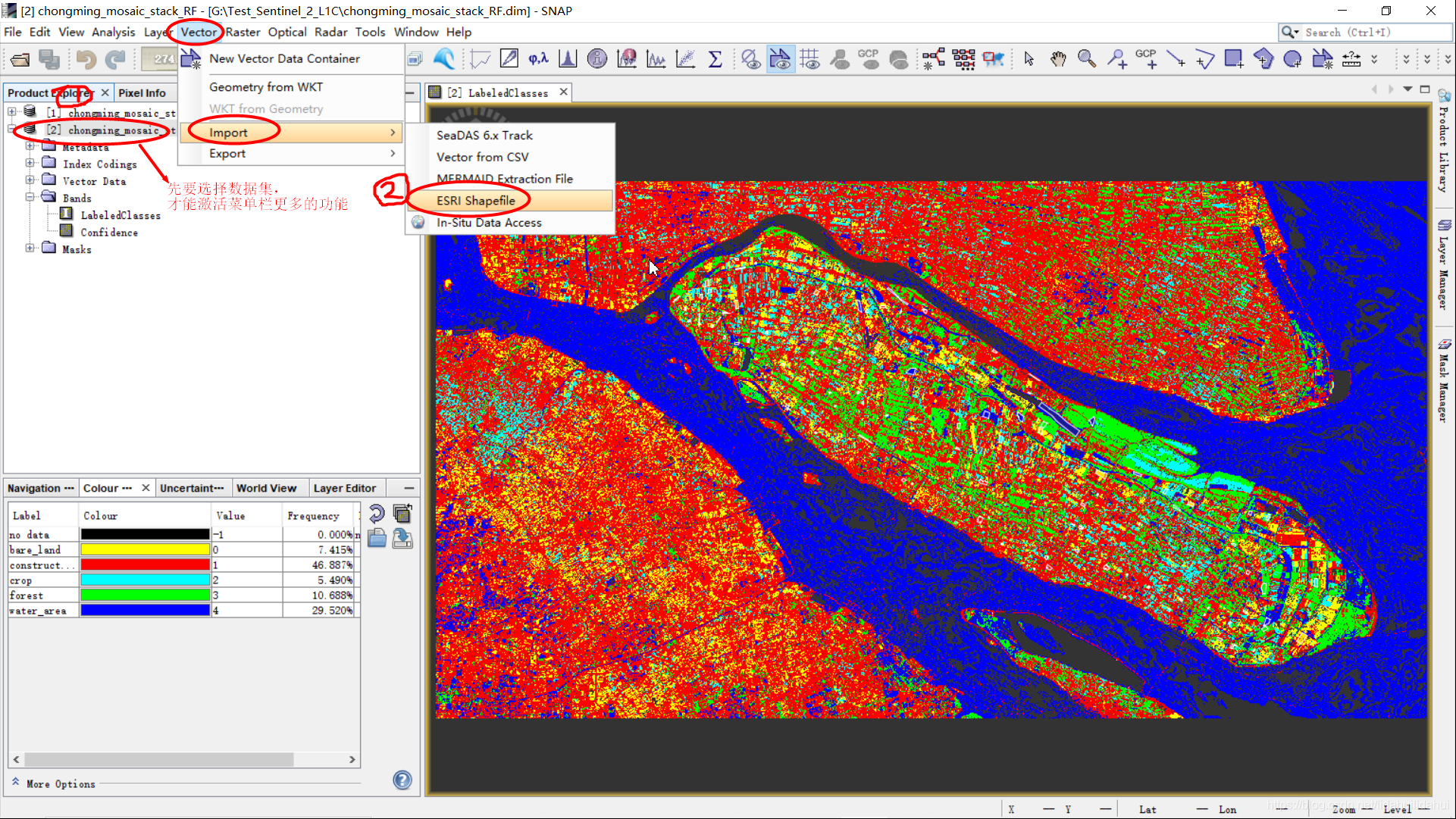
有时候,我们需要的区域不是规则的矩形区域,而是像行政边界等不规则的矩形。这里,我需要的是崇明岛范围的分类图,所以,我需要对得到分类图利用崇明岛边界(.shp文件)对其进行掩膜裁剪。这里,我利用的是SNAP的容器集手动勾绘的崇明岛边界文件chongming_island_mask_Polygon.shp对其进行裁剪。
矢量掩膜文件导入
其导入方式同样本(矢量)数据相同。见下面两图:
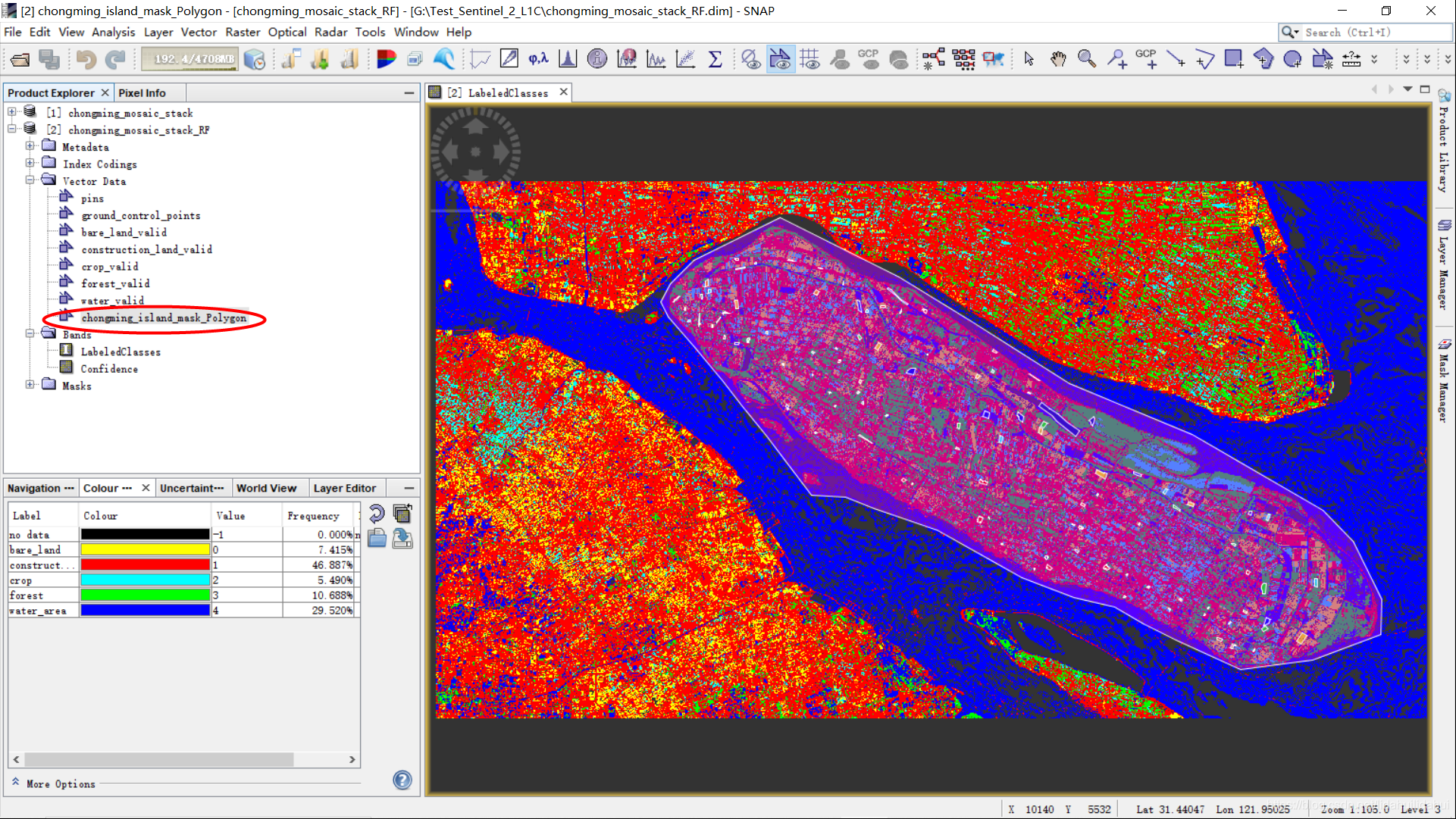
导入成功后数据集2中可以看到其子文件夹Vector Data下,看到导入的shp图层名。
掩膜裁剪
可以在Raster—>Masks—>Land/Sea Mask,打开陆地/海洋掩膜功能:
Land/Sea Mask操作,输出输入参数面板:
Land/Sea Masks操作处理参数,确认正确的矢量数据,点击OK:
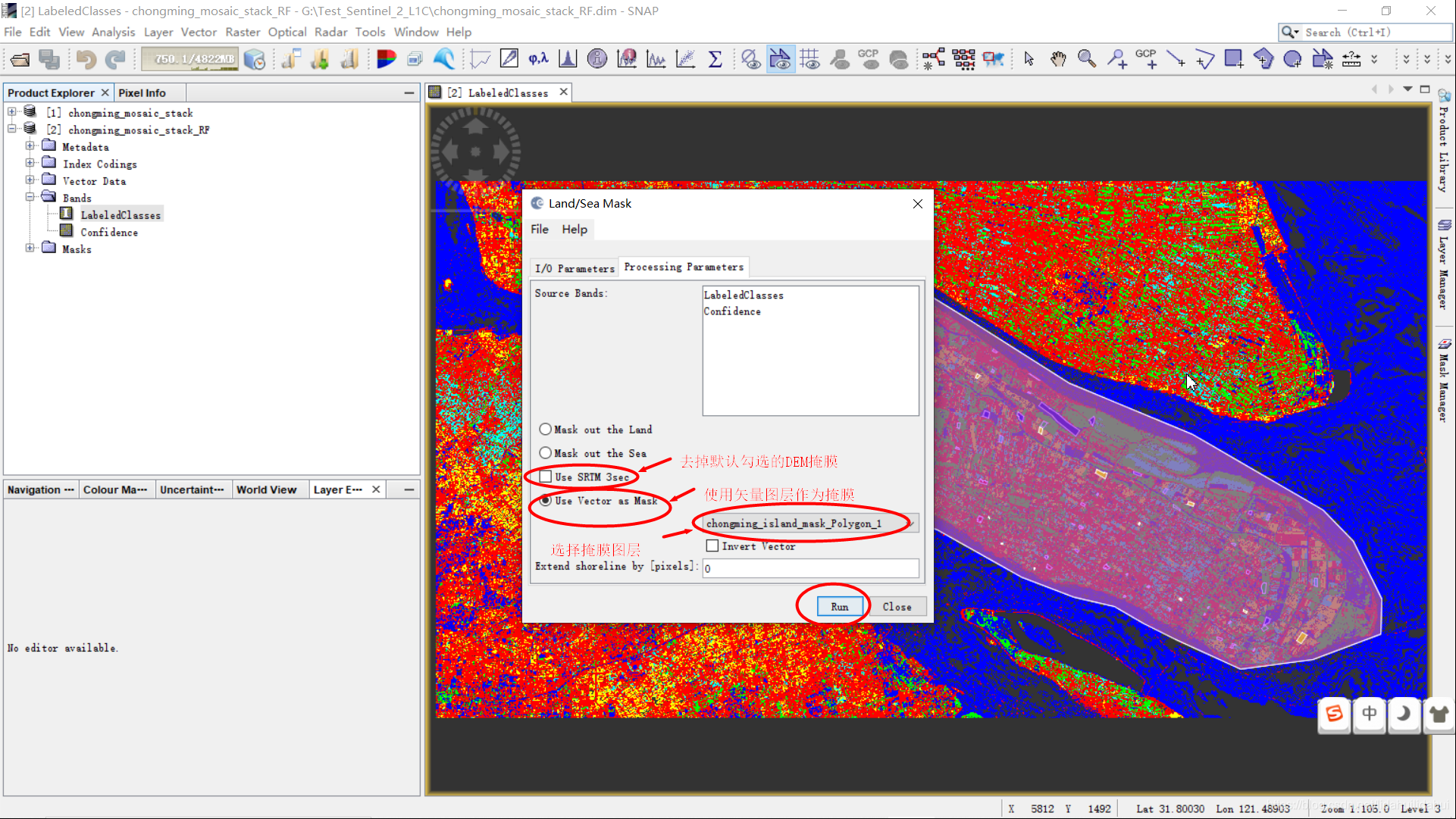 掩膜成功后的结果:
掩膜成功后的结果:
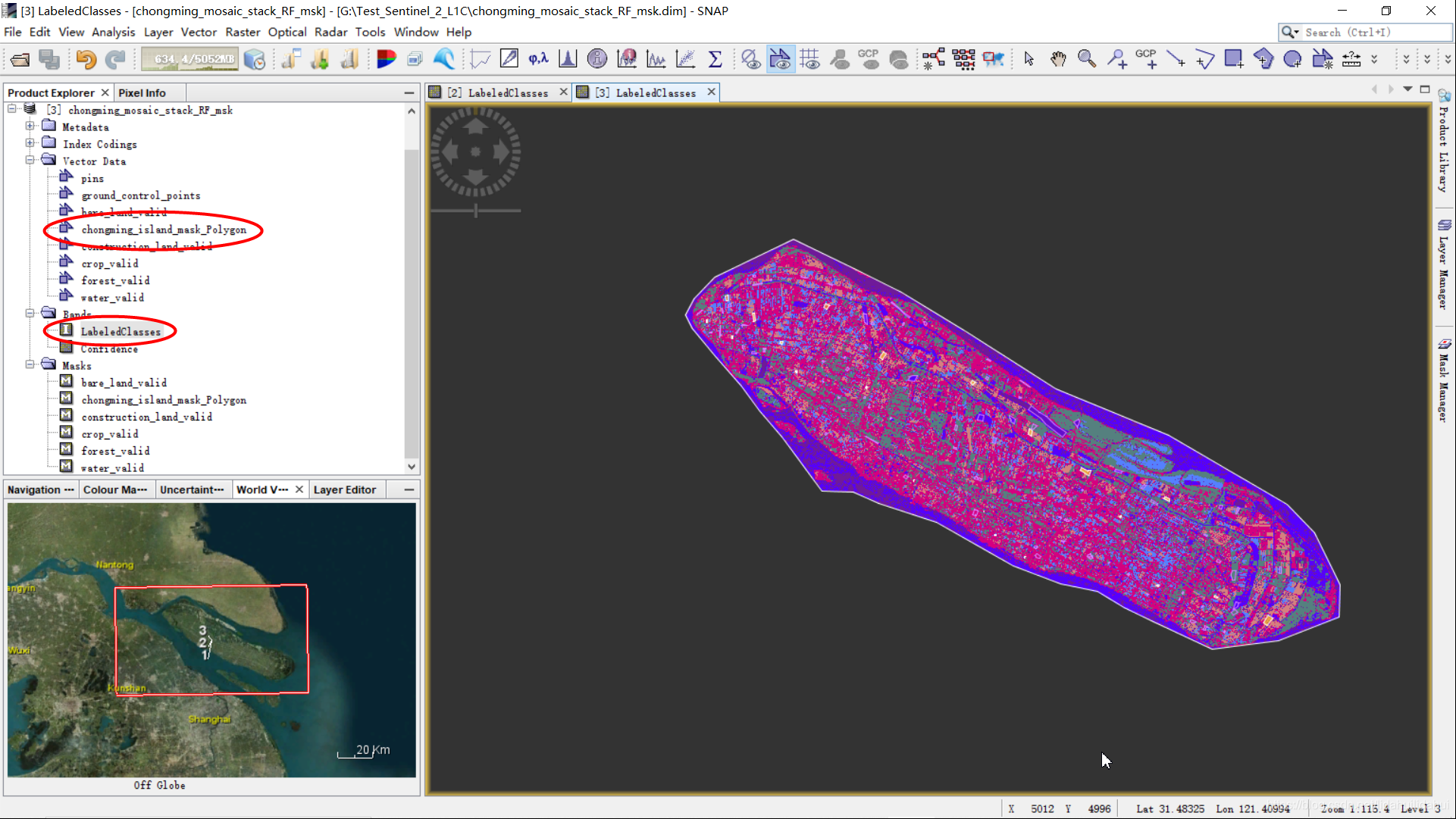
导出为geotiff格式后,导入到QGIS中看下(可以看到的确成功地进行了掩膜):
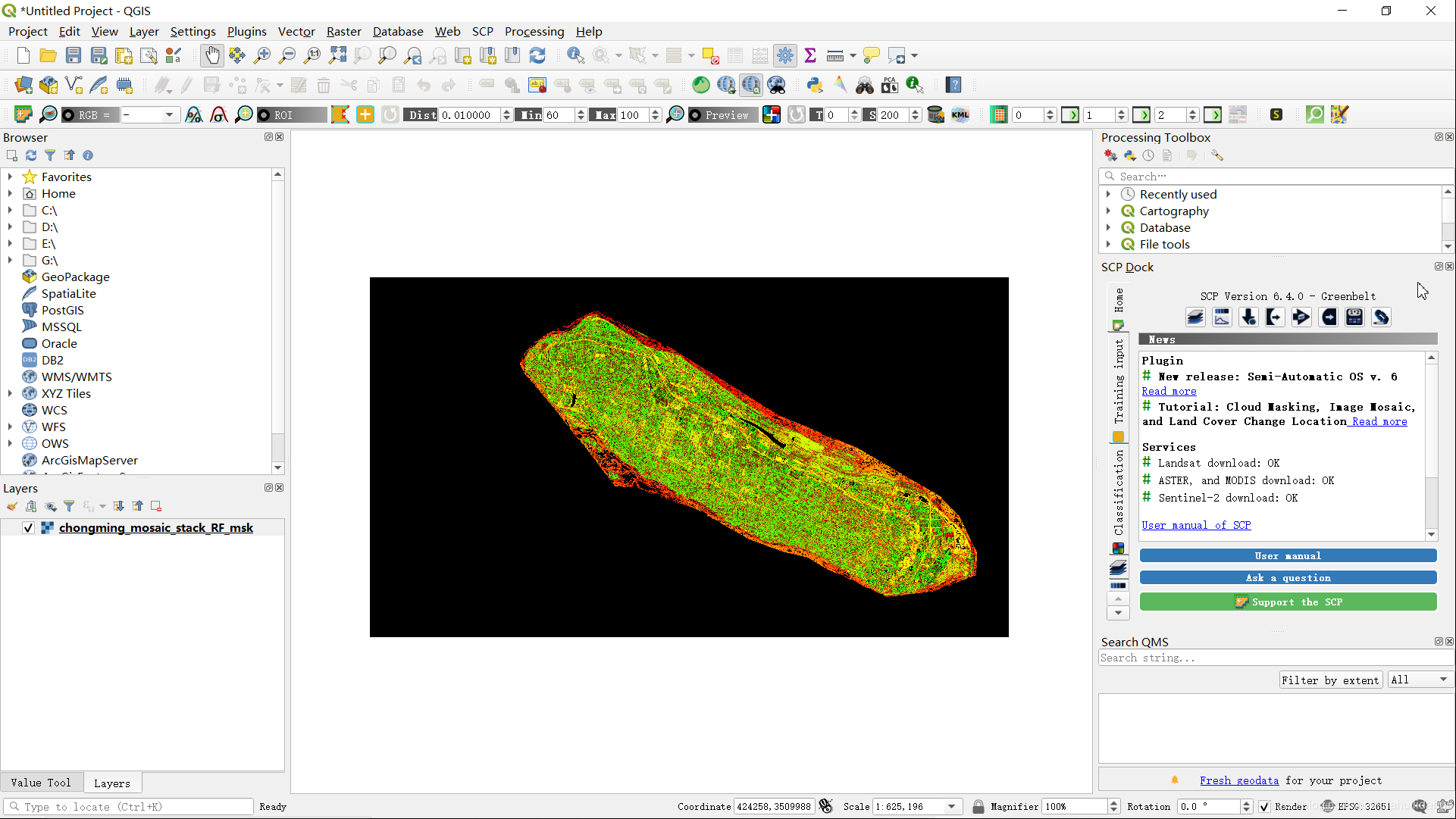
处理碎斑
面向像素分类得到的分类结果图,一般会含有较多的碎斑,这时可以通过众数滤波器得到减少或消除。
栅格图矢量化
经过上述两个步骤后,可以将分类得到的栅格图结果矢量化,这样,后续可以用于更多的GIS处理。
延伸
如果你想获取更好的随机森林分类体验,QGIS中有两个插件可以帮助你,分别是EnMap-Box,dzetsaka后者还含有支持向量机分类算法。当然OTB(Orfeo Toolbox)也可以,并且其支持面向对象分类。要介绍其分类过程,需要写很长的教程,这里不再展开了,也许日后有时间再来展开。如果你感兴趣的话,可以看下其官网的帮助文档。两者均可以很方便地创建
当然,如果你编程比较厉害的话,你可以自己实现该算法的分类(Python、matlab、R等都可以)。Python中利用scikit-learn和gdal库(或者snappy)是可以实现的。
结语
关于SNAP处理Sentinel-2数据的教程暂时告一段落先,地物分类只是其中的一个小应用。制作一幅高质量的地物分类图是有许多要求的,并不是像我们想象中那么简单,许多细节都会影响到其分类精度,其中过程,只有自己实践过才知道。不过,这几篇教程中涵盖一些SNAP基本操作,在,往后利用snappy和gpt(SNAP的命令行工具)处理数据,肯定有所帮助。需要学习的仍然有很多,不过,接下来要将精力转向SAR数据(Sentinel-1)的处理和应用。但愿,本篇博客能让你有所收获。
最近,新冠病毒比较严重,许多人的生活都受到了影响。这篇博客是在家里完成了,效率比在学校低很多,也不知道什么时候能回校。希望这次疫情尽快结束吧。
如果你对SNAP感兴趣的话,可以加入欧空局SNAP处理交流群(QQ群:665903216)。最后,祝身体健康,生活愉快,事业进步!
参考文献
[1] 马明睿, 韩华, 王昊彬, 等. 基于RS和GIS的崇明县生态系统健康评价[J]. 生态科学, 2014, 33(4):788-796.
[2] 孙家抦. 遥感原理与应用[M]. 武汉: 武汉大学出版社,2009.
[3] Jake VanderPlas(陶俊杰,陈小莉译). Python数据科学手册[M]. 北京:人民邮电出版社,2018.
[4] 李航. 统计学习方法[M].北京:清华大学出版社,2012.
[5] 朱文泉,林文鹏. 遥感数字图像处理----原理与方法[M]. 北京:高等教育出版社,2016.
