作者:FYJ
日常的工作中,我们熟悉文本查找替换功能,即按下 Ctrl-F,输入你要查找的词,程序会直接找出你查找词的位置。但如果你需要从庞大的数据中查找并进行处理,这会是十分枯燥且庞大的工作,而且前提是数据比较规则。例如你拥有一个大量的文本数据,需要提取所有的电话号码,人工识别时看到号码就知道: 415-5551234 是电话号码,但 4,155,551,234 不是,虽然工作很简单,但工作量十分庞大。对于有一定编程经验的人会想到“正则表达式”但如果不是程序员,很少可以直接使用它,实际上,FME转换器中有很多支持正则表达式,例如:StringSearcher,StringReplacer等,FME降低了使用难度,“在FME中知道[正则表达式]可能意味着用 3 步解决一个问题,而不是用 300 步。”FME使正则表达式不仅适用于程序员,也适用于无法编程的使用者。
例如我们在文本中提取电话号码,\d 是一个正则表 达式,表示一位数字字符,即任何一位 0 到 9 的数字。 使用\d\d\d-\d\d\d\d\d\d\d,就可匹配所有同样格式文本:3 个数字、一个短横线、7个数字,或者\d{3}-\d{7},如果部分电话号码没有区号,则:(\d\d\d)?-\d{7}

利用括号分组
假定想要将区号从电话号码中分离。添加括号将在正则表达式中创建“分组”:
(\d\d\d)-(\d\d\d-\d\d\d\d)。
用管道匹配多个分组
字符|称为“管道”。希望匹配许多表达式中的一个时,就可以使用它。
用问号实现可选匹配
有时候,想匹配的模式是可选的。就是说,不论这段文本在不在,正则表达式都会认为匹配。字符?表明它前面的分组在这个模式中是可选的。
用星号匹配零次或多次
*(称为星号)意味着“匹配零次或多次”,即星号之前的分组,可以在文本中出现任意次。它可以完全不存在,或一次又一次地重复。
用加号匹配一次或多次
*意味着“匹配零次或多次”,+(加号)则意味着“匹配一次或多次”。星号不要求 分组出现在匹配的字符串中,但加号不同,加号前面的分组必须“至少出现一次”。
用花括号匹配特定次数
{}如果想要一个分组重复特定次数,就在正则表达式中该分组的后面,跟上花括号包围的数字。
来介绍一下我接触过的案例
从事过空中三角测量的,尤其是从事过徕卡xpro软件空三的,在工程文件和strip文件夹中涉及的很多*.stp文件,session路径中的*.info、*.sup文件,存在着大量的指向文件路径,每当工程文件或源文件在一个业务线转移时,都要进行批量的修改,人工进行工作量巨大且十分容易遗漏。
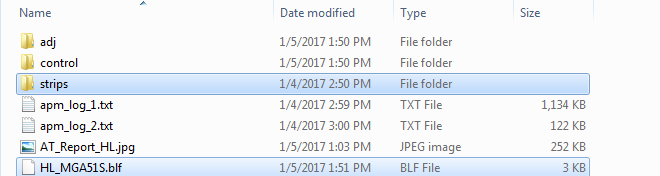


如果通过fme进行实现,流程则十分简单。
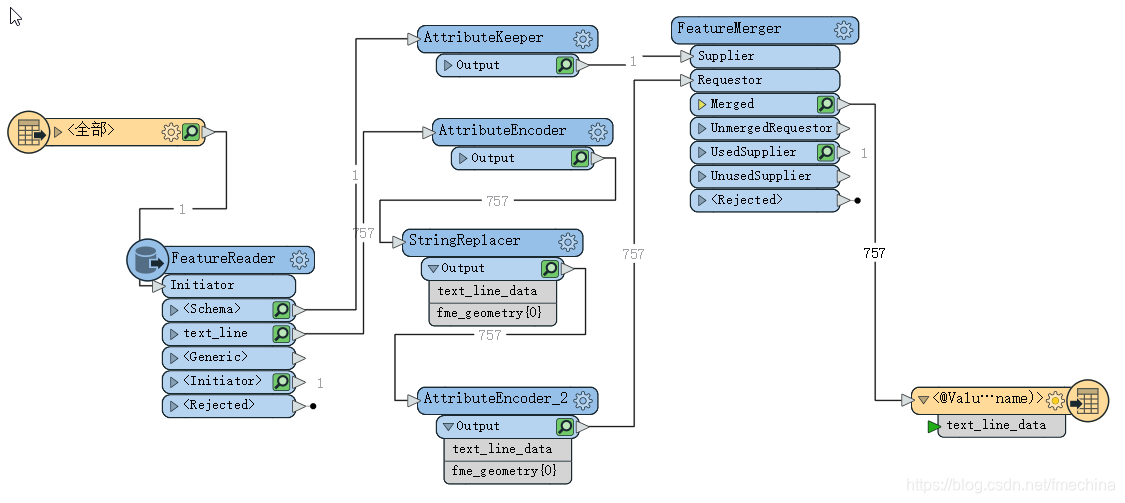
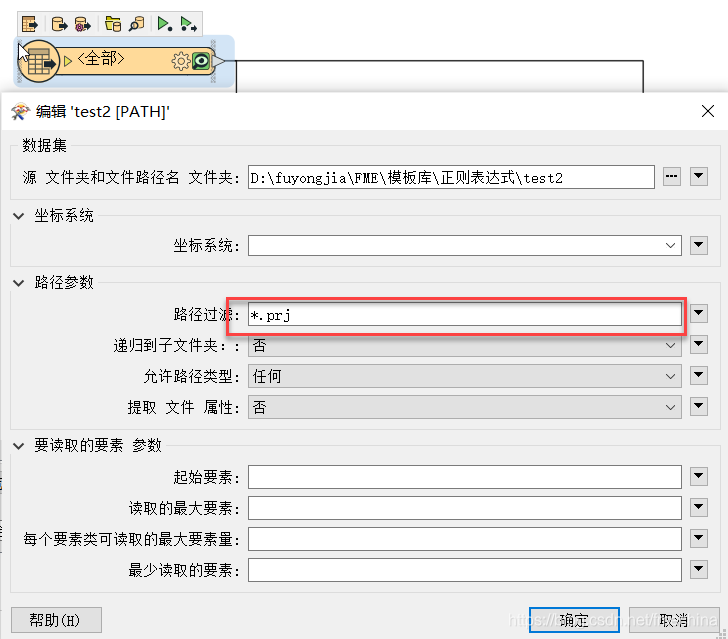
首先我们使用读模块对需要操作的文件进行过滤读取,prj是inpho软件工程文件格式。
然后我们直接使用StringReplacer转换器将需要更改的路径替换就可以了
文件中原影像路径是T:\HK20-0201_FUSAMI_Sint_Marteen_Top\02_Material\02_Images\TIF_TO_AT\20201203_F1\cap_39382.tif
StringReplacer如下设置:
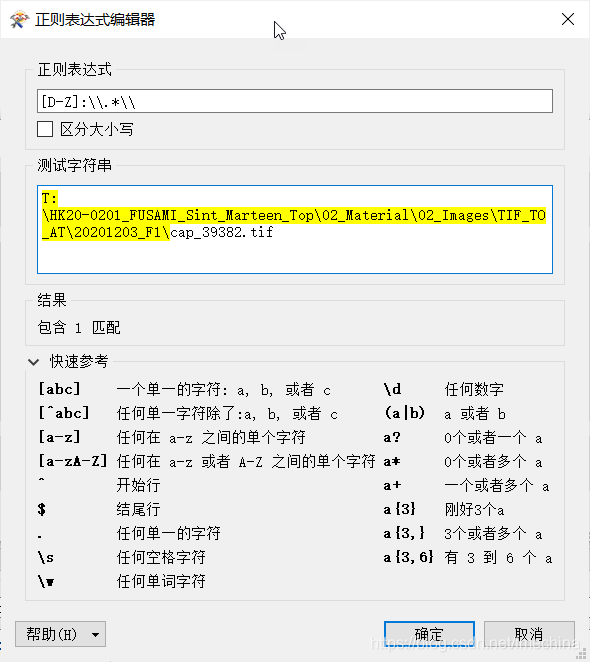
正则表达式:[D-Z]:\\.*\\
一般数据很少在C盘,所以从D盘开始查找:[D-Z],然后匹配“:”字符,再然后匹配路径中任意字符,最后我们不能改变影像文件名称,用“\\”截止到路径的结尾。
当然,上面案例只是一个方面,它对于Excel,csv等等数据格式都适用。同时对于大数据量的文本数据的直接处理,FME也十分方便高效,例如高程Geoid模型文件,网络爬取的大量兴趣点数据等等经常多余百万行,超过了常规办公软件限制,编辑和使用十分不便。FME可以在不打开文件前提下,通过转换器实现高效处理工作。