原文发布时间:2015-01-28 09:34:07
作者:一峰
如何评估读模块性能
要想提高读模块的性能必须了解转换开始时它是怎么工作的,但是这有很难与转换器分开。我们知道读取数据所花的时间,关键信息来源于日志的Emptying Factory Pipeline消息,但是,往往我们等待的时间比日志显示的时间会更长,因为FME要等待数据库或者文件系统的反应。例如,日志显示数据读取了1.6秒,但是实际我们等待的时间更长。
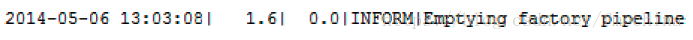
又例如上面面工作空间,日志文件显示,读取数据消耗了27.5秒。
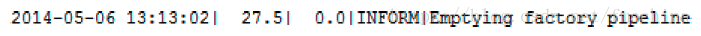
但是整个转换过程消耗了27.6秒

这似乎不大可能,怎么数据读取用了27.5秒,而处理过程只用了0.1秒?
实际上FME读取数据和处理数据是同时进行的,并不是等数据读取完后在处理,那样效率太低。
当27.5秒数据读取完后,实际上已经将大部分数据已经处理了,剩下0.1秒处理最后一点数据。
那么,我们如何来评价读取数据的真实性能呢,答案是禁用所有的转换器,只运行读模块。
当禁用转换器后我们可以看到,记录读取数据的时间是5.4秒。
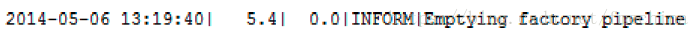
因此,我们可以评估数据读取的时间是5.4秒,而不是27.5秒。
例如,如果你的处理是非常复杂的,消耗了几个小时,Reading source feature的信息一直存在,然后你可能会误解一直在读取数据。但实际是大部分数据已经在处理了。

如何改善读模块性能
提高读取数据性能最好的方法是从系统底层升级减少FME等待响应的时间。
如下,等待系统响应时间是0.4秒,大约占总耗时的12%

当然,这里的时间没什么大问题,但是当读取大数据量或者远程访问数据库时,这里消费的时间就非常重要。
提高性能第二个方法就是尽量减少大数据量的读取,如下例子,读取了将近14000个要素,却立马丢弃很多,只保留3个要素。

在这种情况下,我们只读取需要的3个要素可能更有效。
如果你读取了整个数据集的内容,但只需要数据集的一部分,那么你就是在浪费资源,给CPU施加压力。
所有格式都有不同的参数设置用来过滤数据的读取量。
首先,空间查询区域search envelope,定义读取的要素必须在几何范围内。

这些参数在所有的读模块中都有效,但是在存在空间索引的数据中效果更好。
同样的,还有很多的参数能够让用户定义读取多少数据。
这些参数包括,最大读取要素个数以及从什么时候开始读取要素,以及定义只读取哪些图层或者表。
通过这些设置,可以减少读取大量数据。
另外一些格式,特别是数据库,提供条件查询,可以帮助减少读取数据。
例如,SQL Server格式的读模块,可以通过WHERE Clause参数进行条件过滤。
使用这个参数比从数据库中读取整张表数据后添加Tester转换器提高了更高的性能。
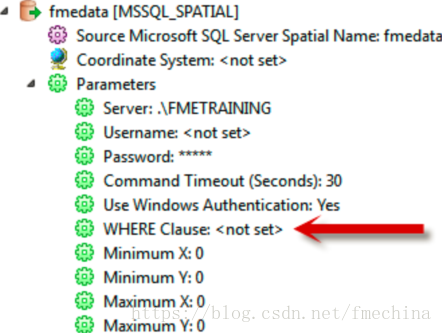
总的来说,当你想过滤数据源,可以设置这些参数,这样做比读取整个数据源在添加转换器过滤来的更加有效。
尽量避免两个读模块,因为这样会降低性能。
首先,通过表列表来指定读取你需要的要素类。
例如,右图添加了整个PostGIS数据库的所有表。
但是,工作空间中只有几张表连接了转换器,也就是读取的大部分数据并没有被使用,这样极大地降低读取效率。
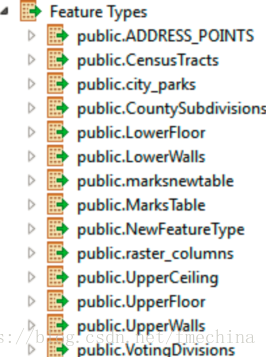
如果你不需要些数据,那么将没有使用的要素类删掉。
这样就会减少数据的读取量提高性能。
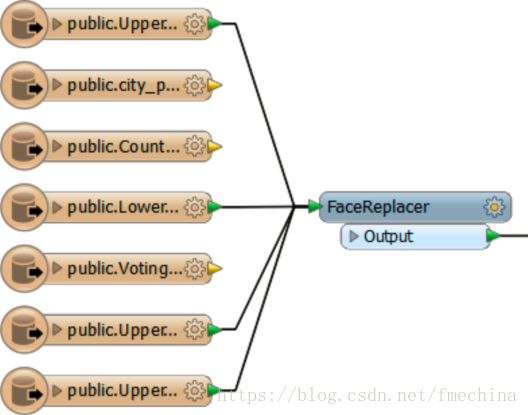
第二种情况,特别是文件数据集,当你删掉了所有要素类,但没有删除读模块,读模块还是会在底层读取数据。
例如,下图读取了3个Shape文件,工作空间中要
素类全部被删除,但是读模块任然会读取数据
当工作空间运行时,所有的数据源都会被读取
但是会提示无效的输入:“unexpected input”。
如何评估写模块性能
评估写模块的性能与评估读模块性能一样困难,道理一样,当FME开始写数据,一旦可以写,并不需要等前面的数据处理完成。
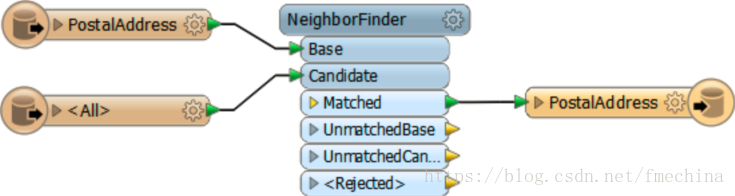
利用前面的工作空间,只是添加了一个写模块。
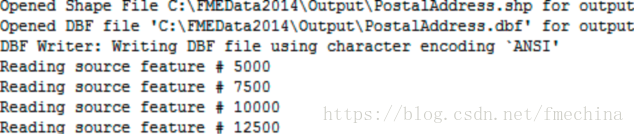
通过日志我们可以看到,输出数据集的文件在数据源读取完之前就已经创建。
显然,很难将写模块分离来检查到底写数据消费了多少时间,你不能禁用工作空间的其他所有东西,那样的话就没有任何东西输出。
然而,我们可以通过两个步骤来检查写模块的性能,首先添加一个Recorder转换器,将数据转换为FFS进行保存。
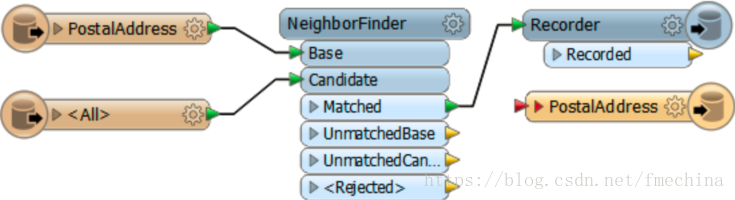
然后,添加一个Player转换器代替Recorder,重新读取保存的FFS数据,并连接到写模块,同时禁用其他的转换器和读模块。
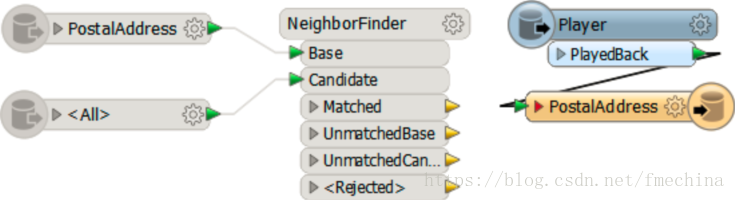
现在数据被重新加入到工作空间中,并且随后通过写模块输出。
当Player读取完数据之前,写模块就已经开始工作了。为了防止这个情况发生,我们有必要添加一个FeatureHolder转换器。
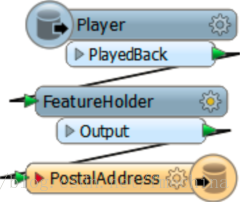
在这个例子中,Emptying Factory Pipeline记录时间是7.2秒,而全部完成转换的时间是8.9秒,因此写模块的时间是1.2秒。
注意:扇出会将输出变得复杂,因此不能降低写模块的性能。
例如,我在上面的工作空间中设置数据集扇出,那么FME会为每一个扇出创建一个写模块。
这会降低写模块的性能,因为FME不得不缓存所有输出的数据以及创建多个写模块,并且为每个输出数据集创建日志。
如何改善写模块性能
提高写模块性能最明显的方法是升级底层系统以减少FME等待响应的时间。
如果你正在写入文件系统,请确保磁盘的反应速度很快(使用固态硬盘),并且操作系统并不繁忙,如果系统太忙会导致瓶颈,并且尽量减少写模块,因为这回导致性能下降。
如果你正在写数据库,那么创建索引会导致比预期的要慢,在很多情况,我们写数据库为了获得更快的速度可以删除索引,更多的关于数据库提高性能的信息将在后面的部分详细介绍。
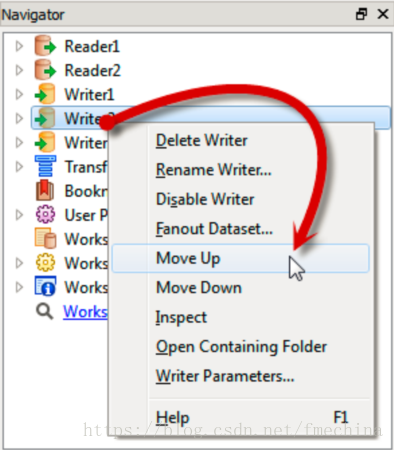
然而,提高写模块性能最主要的方法是当存在多个写模块的时候调整写模块的顺序为最佳。
每个写模块都按顺序列在导航窗口中,这里的关键是确保最大数据量的写模块排在列表的最上方。(可以在导航窗口中移动每个写模块的顺序,通过右击、选择向上或者向下移动,或者你也可以通过鼠标的拖拽来移动写模块)。
这样做的原因是首先写入排在第一个的写模块,其他的写模块缓存他们的数据,直到允许写入。因此,如果大数据量的数据立即被写入,而小数据量的数据存储到缓存中,这样可以巨大的提高性能,特别是在转换不平衡的情况下,(比如有1百万个要素写入一个写模块,另外有10各要素写入另一个写模块)。
以上介绍了读写模块性能的评估与改善方法,后续将继续介绍如何优化转换过程以及如何优化数据库读写。
若对文章有疑问,可发送邮件至[email protected]提问或讨论。