无监督学习之自学习与半监督学习
有两种常见的无监督特征学习方式,区别在于有什么样的未标注数据。
自学习( self-taught learning )是其中更为一般的、更强大的学习方式,它不要求未标注数据和已标注数据来自同样的分布。
另外一种带限制性的方式也被称为半监督学习,它要求未标注数据和已标注数据服从同样的分布。
假定有一个任务,目标是区分猫和狗图像;即训练样本里面要么是猫的图像,要么是狗的图像。哪里可以获取大量的未标注数据呢?最简单的方式可能是从互联网上下载一些随机的图像数据集。
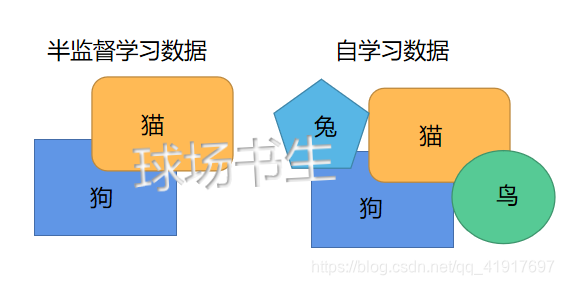
这个例子里,未标注数据完全来自于一个和已标注数据不同的分布(未标注数据集中,或许其中一些图像包含猫或者狗,但是不是所有的图像都如此)。这种情形被称为自学习。
相反,如果有大量的未标注图像数据,要么是猫图像,要么是狗图像,仅仅是缺失了类标号。也可以用这些未标注数据来学习特征。这种方式,即要求未标注样本和带标注样本服从相同的分布,有时候被称为半监督学习。
在实践中,常常无法找到满足这种要求的未标注数据(每张图像不是猫就是狗,只是丢失了类标号的图像数据)因此,自学习在无标注数据集的特征学习中应用更广。