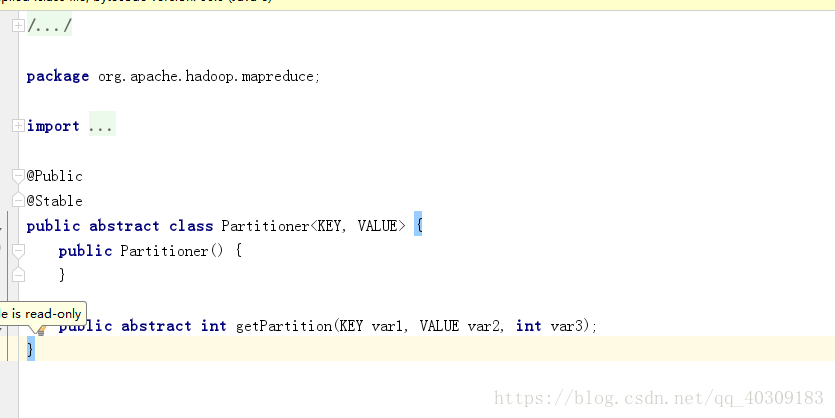
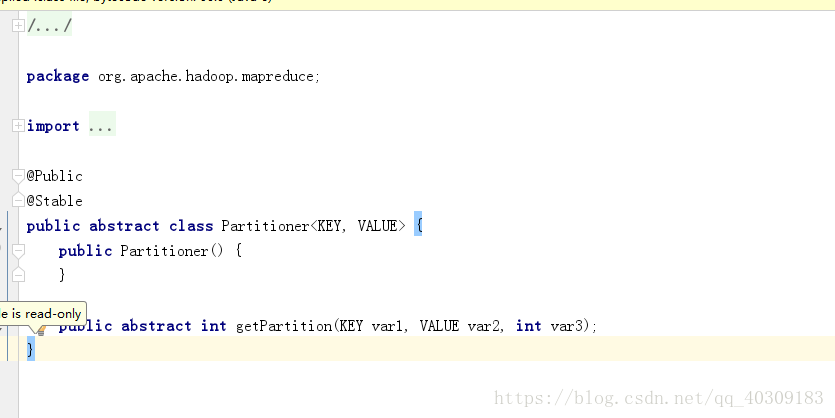
在(一)的基础上,写一个自己的partitioner就好了。
分区的默认实现HashPartitioner,它根据key的hashcode和Interger.
在Reduce过程中,可以根据实际需求(比如按某个维度进行归档,类似于数据库的分组),把Map完的数据Reduce到不同的文件中。分区的设置需要与ReduceTaskNum配合使用。比如想要得到5个分区的数据结果。那么就得设置5个ReduceTask。
在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,按照手机号码段划分的话,需要把同一手机号码段的数据放到一个文件中;按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。
我们这里设置了四个数字,所以在后面设置的时候,要设置4个。
code:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @Decription: 通过号码某个部分数字的区分,输出到不同的文件
*/
import java.util.HashMap;
public class ProvincePartitioner extends Partitioner<FlowBean, Text> {
//HashMap 集合
public static HashMap<String, Integer> provinceMap = new HashMap<String, Integer>();
static {
provinceMap.put("3", 0);
provinceMap.put("4", 1);
provinceMap.put("5", 2);
provinceMap.put("8", 3);
}
public int getPartition (FlowBean key, Text value,int numPartitions) throws IndexOutOfBoundsException {
String st = value.toString().substring(1, 2);
int num = provinceMap.get(st);
return num;
}
}
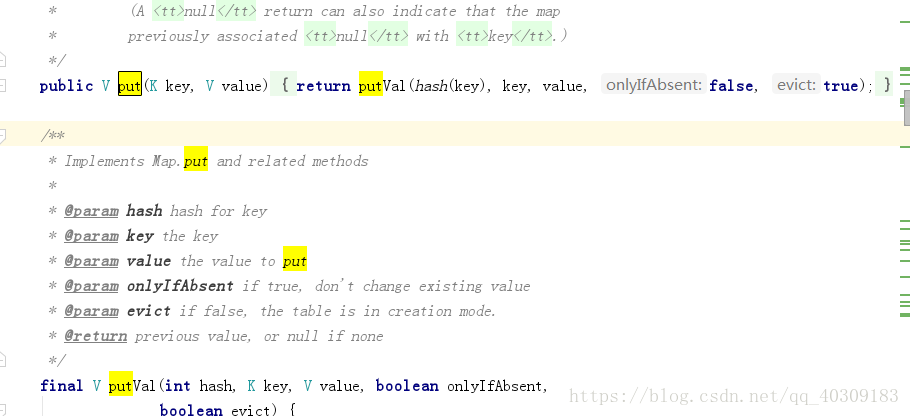
HashMap put方法
Partitoner源码