一、需求
根据数据日志统计每一个手机号耗费的总上行流量、下行流量、总流量
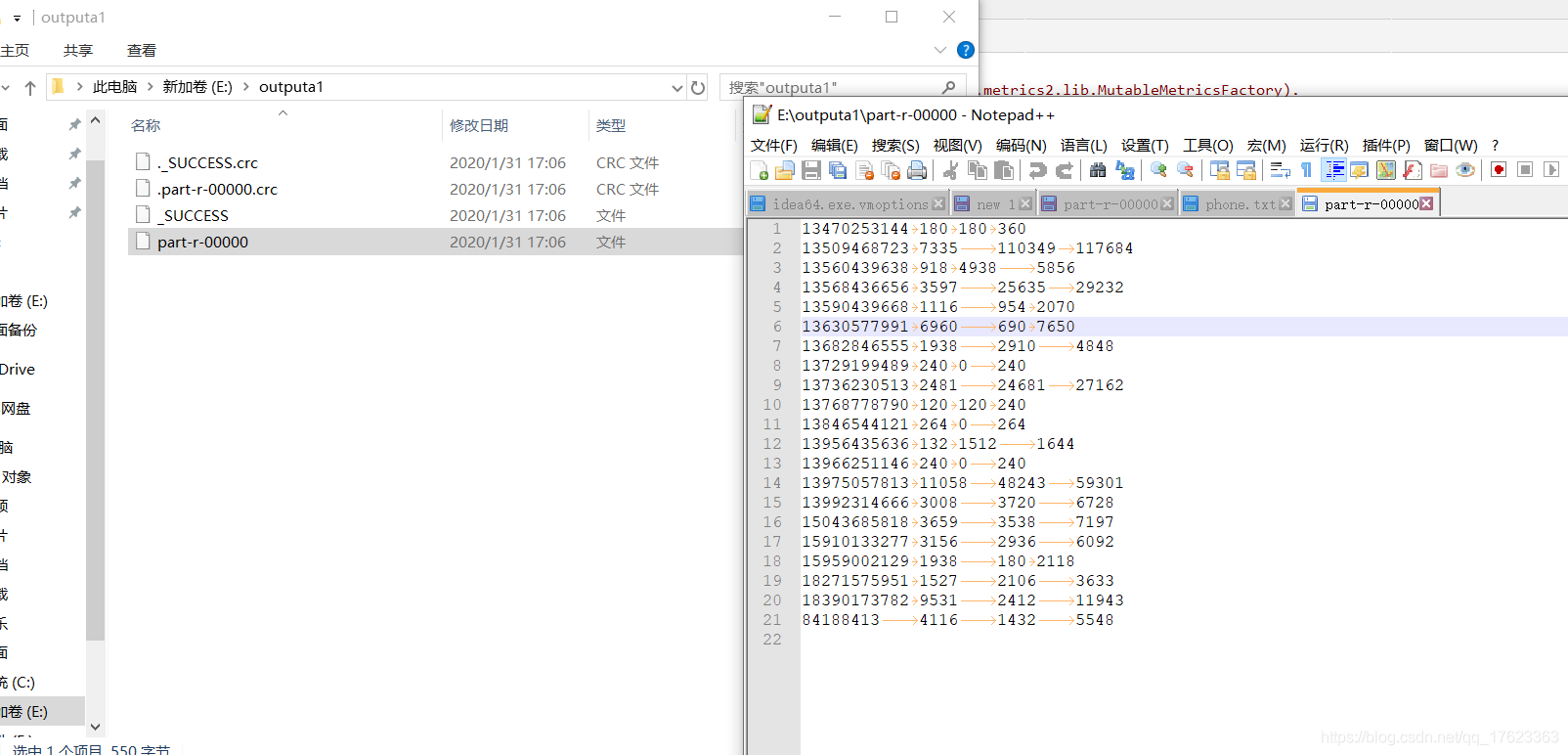
二、数据准备
1、输入数据
1,13736230513,192.196.100.1,www.atguigu.com,2481,24681,200
2,13846544121,192.196.100.2,,264,0,200
3,13956435636,192.196.100.3,,132,1512,200
4,13966251146,192.168.100.1,,240,0,404
5,18271575951,192.168.100.2,www.atguigu.com,1527,2106,200
6,84188413,192.168.100.3,www.atguigu.com,4116,1432,200
7,13590439668,192.168.100.4,,1116,954,200
8,15910133277,192.168.100.5,www.hao123.com,3156,2936,200
9,13729199489,192.168.100.6,,240,0,200
10,13630577991,192.168.100.7,www.shouhu.com,6960,690,200
11,15043685818,192.168.100.8,www.baidu.com,3659,3538,200
12,15959002129,192.168.100.9,www.atguigu.com,1938,180,500
13,13560439638,192.168.100.10,,918,4938,200
14,13470253144,192.168.100.11,,180,180,200
15,13682846555,192.168.100.12,www.qq.com,1938,2910,200
16,13992314666,192.168.100.13,www.gaga.com,3008,3720,200
17,13509468723,192.168.100.14,www.qinghua.com,7335,110349,404
18,18390173782,192.168.100.15,www.sogou.com,9531,2412,200
19,13975057813,192.168.100.16,www.baidu.com,11058,48243,200
20,13768778790,192.168.100.17,,120,120,200
21,13568436656,192.168.100.18,www.alibaba.com,2481,24681,200
22,13568436656,192.168.100.19,,1116,954,200
2、数据格式
7 13560436666 120.196.100.99 1116 954 200
id 手机号码 网络ip 上行流量 下行流量 网络状态码
3、期望输出数据格式
13560436666 1116 954 2070
手机号码 上行流量 下行流量 总流量
三、使用idea创建一个Maven项目
如果大家还不知道怎么创建一个Maven项目,可以自行百度以下,这里不在过多叙述。
下面这是我的一个普通的Maven项目
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zhenghui</groupId>
<artifactId>hdfs</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.8.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.7</version>
</dependency>
</dependencies>
</project>
创建如下文件
FlowBean.java文件
package com.zhenghui.flow;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean() {
}
public void set(long upFlow, long downFlow){
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
/**
* 序列化方法
* @param out 框架给我们提供的数据出口
* @throws IOException
*/
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
/**
* 反序列化方法
* @param in 框架提供的数据来源
* @throws IOException
*/
public void readFields(DataInput in) throws IOException {
//顺序:怎么序列化的顺序就应该怎么反序列化的顺序
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
}
FlowDriver.java文件
package com.zhenghui.flow;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1、获取一个Job实例
Job job = Job.getInstance(new Configuration());
//2、设置我们的类路径CLasspath
job.setJarByClass(FlowDriver.class);
//3、设置Mapper和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4、设置Mapper和Reducer的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//5、设置输入输出数据
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//6、提交我们的Job
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
FlowMapper.java文件
package com.zhenghui.flow;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
private Text phone = new Text();
private FlowBean flow = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String data = value.toString();
System.out.println("line="+data);
//1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200
String[] s = data.split(",");
System.out.println("手机号:"+s[1]);
phone.set(s[1]);
long upFlow = Long.parseLong(s[s.length - 3]);
long downFlow = Long.parseLong(s[s.length - 2]);
flow.set(upFlow,downFlow);
context.write(phone,flow);
}
}
FlowReducer.java文件
package com.zhenghui.flow;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
private FlowBean sumFlow = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long sumUpFlow = 0;
long sumDownFlow = 0;
for (FlowBean value : values) {
sumUpFlow += value.getUpFlow();
sumDownFlow += value.getDownFlow();
}
sumFlow.set(sumUpFlow,sumDownFlow);
context.write(key,sumFlow);
}
}
设置数据源
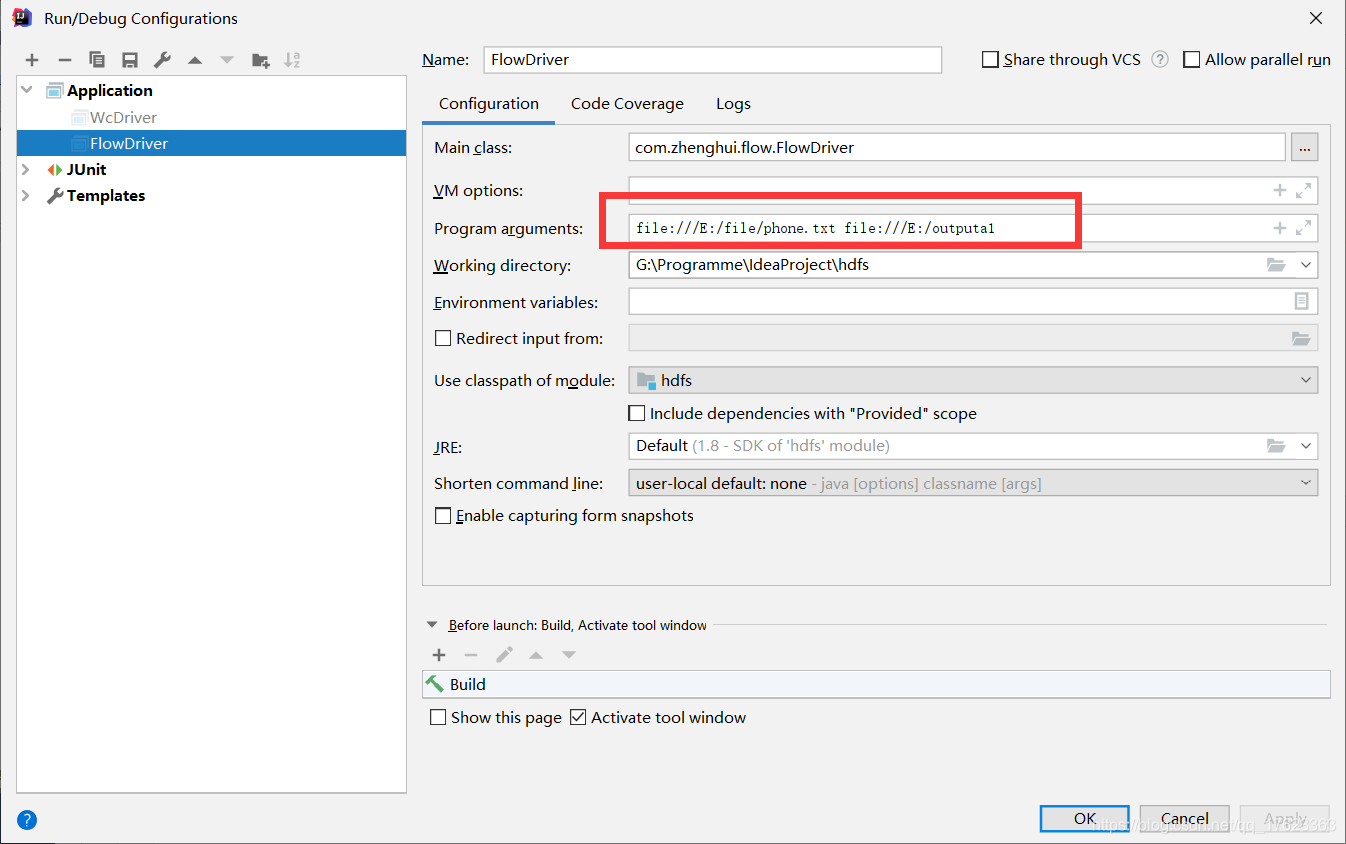
windows10 中idea中的运行结果