最近看了论文《Point Set Registration: Coherent Point Drift》,来记录一下对这个算法的理解。
CPD算法使用的数学模型为高斯混合模型(GMM),关于高斯混合模型的理解可以参考下面这篇博客
https://www.jianshu.com/p/928d48afcd9a
论文首先定义了一系列变量:

其中点集X和点集Y是两个需要配准的点云,T为变换矩阵。其中点集Y解释为GMM模型的型心,点集X为由GMM模型生成的数据点,这就可以理解为,现在我已将点集Y当成一个正确标准的点集,点集X呢,则是有许多散落在标准点集周围的点构成的点云,因为点集Y中的每个点都代表了一个高斯分布,则点集Y就是由这M个高斯分布混合而成,而点集X就是这个高斯混合分布生成的点集。
上文中提到的高斯模型用下式表示:
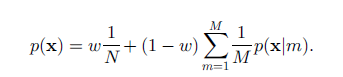
其中,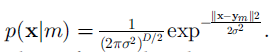 ,w是权值,N和M是常数。
,w是权值,N和M是常数。
从上面这个p(x)式子的第二项可以知道,点集X中一个点存在的概率:就是求它与每个高斯模型形心(即Y中的每个点)的距离和,只不过这里的"距离和"用"概率和"进行表示。
可以想像,假如点集X和点集Y完全相同,并且点集X和点集Y之间的正确变换矩阵T我们已经找到,这样,在我们利用变换矩阵T将点集Y变换后,两点集应当完全重合,则总有一个点与
相重合,也就是两点之间的距离为0,那么上面式子中的exp部分就等于1了。然而从上面式子我们也可以看到,第二项算的是
与Y中所有点的距离和,我们现在只算了重合的那个y点,其他y点对这个距离和贡献有多少呢?可以说基本为0,这是由y=exp(-x)这个函数的图像决定的,毕竟exp(-3)就等于0.05了,而在大规模点云中,哪两个点之间间距不得2米以上(式中还有个平方),所以,可以认为点集Y中其他点对
存在的概率贡献基本为0。因此,可以想到,当点集X和点集Y真的一模一样的时候,什么情况下p(x)最大呢,当然是我们在计算每个
的存在概率时,让它的累加项中出现1,也就是每个
都能get到它的对应点。
那么当点集X和点集Y不一样呢,比如点集X有些部分和点集Y完全相同,有些则不同(但差别也不算大),那么在不同的部分,和最靠近的那个y点对
存在的概率贡献最大。
我们将所有存在的可能性全部加起来得到的累加和,就是这个变换矩阵T的得分,累加和越大,得分越高,说明这个变换矩阵T越准确,累加和如下式:
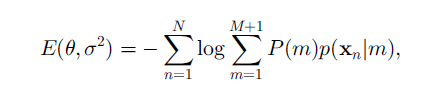
E这个式子其实就是上面p(x)取对数,前面多的N项累加和相当于把每个的存在可能性累加,这样看来,也就是我们关于这个算法的所有目标都转变为对上式求最小值(前面相对于p(x)多个负号),当我们找到最小值了,最佳变换矩阵T也就得到了,当然如果是局部最小就跪了。怎样求上面这个式子最小值呢?用EM算法,关于EM算法就推荐大家看另一篇博客了,这里,就不再细说了:EM算法
以上就是我关于这个算法的理解,欢迎各位大佬批评指正!!!QQ:1826380364