畅购商城文章系列
畅购商城:分布式文件系统FastDFS
畅购商城:商品的SPU和SKU概念
畅购商城:Lua、OpenResty、Canal实现广告缓存
畅购商城:微服务网关和JWT令牌(上)
畅购商城:微服务网关和JWT令牌(下)
畅购商城:Spring Security Oauth2 JWT(上)
畅购商城:Spring Security Oauth2 JWT(下)
畅购商城:购物车
畅购商城:订单
畅购商城:微信支付
1.首页广告
1.1 分析
首页门户系统需要展示各种各样的广告数据,很多时候这些广告内容都是固定的。通常情况下,首页(门户系统的流量一般非常的高)不适合直接通过MySQL数据库直接访问的方式来获取展示。我们可以采用Redis和OpenResty做多级缓存。
1.2 缓存架构
缓存流程:
- 查询Nginx缓存,如果有缓存,则直接将缓存中的广告返回。
- 如果Nginx缓存中没有广告数据,则通过Lua脚本查询Redis,如果Redis中有数据,则会将数据存入到Nginx的缓存,并返回查询到的数据。
- 如果Redis中也没有缓存,则此时会通过Lua脚本查询MySQL,如果MySQL中有数据,则将数据存入到Redis中并返回查询到的数据。

2. Lua
2.1 Lua 是什么
【太长不看版】:
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
【详细版】:
Lua 是一个小巧的脚本语言。它是巴西里约热内卢天主教大学(Pontifical Catholic University of Rio de Janeiro)里的一个由Roberto Ierusalimschy、Waldemar Celes 和 Luiz Henrique de Figueiredo三人所组成的研究小组于1993年开发的。其设计目的是为了通过灵活嵌入应用程序中从而为应用程序提供灵活的扩展和定制功能。Lua由标准C编写而成,几乎在所有操作系统和平台上都可以编译,运行。Lua并没有提供强大的库,这是由它的定位决定的。所以Lua不适合作为开发独立应用程序的语言。Lua 有一个同时进行的JIT项目,提供在特定平台上的即时编译功能。
2.2 Lua 语言具有以下特性
- 支持面向过程(procedure-oriented)编程和函数式编程(functional programming);
- 自动内存管理;只提供了一种通用类型的表(table),用它可以实现数组,哈希表,集合,对象;
- 语言内置模式匹配;闭包(closure);函数也可以看做一个值;提供多线程(协同进程,并非操作系统所支持的线程)支持;
- 通过闭包和table可以很方便地支持面向对象编程所需要的一些关键机制,比如数据抽象,虚函数,继承和重载等。
2.3 Lua 应用场景
- 游戏开发
- 独立应用脚本
- Web 应用脚本
- 扩展和数据库插件如:MySQL Proxy 和 MySQL WorkBench
- 安全系统,如入侵检测系统
- redis中嵌套调用实现类似事务的功能
- web容器中应用处理一些过滤 缓存等等的逻辑,例如nginx。
2.4 Lua 的安装
有linux版本的安装也有mac版本的安装。我们采用linux版本的安装,首先我们准备一个linux虚拟机。
安装步骤,在linux系统中执行下面的命令。
yum install -y gcc
yum install libtermcap-devel ncurses-devel libevent-devel readline-devel
curl -R -O http://www.lua.org/ftp/lua-5.3.5.tar.gz
tar -zxf lua-5.3.5.tar.gz
cd lua-5.3.5
make linux test
make install
2.5 快速入门
创建hello.lua文件,内容为
print("hello");
保存。执行命令
lua helloworld.lua
输出为:
Hello
2.6 Lua 的基本语法
- lua有交互式编程和脚本式编程。
- 交互式编程就是直接输入语法,就能执行。
- 脚本式编程需要编写脚本,然后再执行命令 执行脚本才可以。
一般采用脚本式编程。(例如:编写一个hello.lua的文件,输入文件内容,并执行lua hell.lua即可)
基本语法参考:Lua教程|菜鸟教程
3. OpenResty
3.1 OpenResty介绍
【简洁版】:
OpenResty 封装了 Nginx ,并为 Nginx 提供了高性能的可扩展程序,使 Nginx 抗压能力得到了大大的提升,并且提供了 Lua 脚本的扩展支持,能使 Nginx 抗压能力达到 10K - 1000K。
- OpenResty 是一个基于 Nginx 的可伸缩的 Web平台,由中国人章亦春发起,提供了很多高质量的第三方模块。
- OpenResty 是一个强大的 Web 应用服务器,Web 开发人员可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,更主要的是在性能方面,OpenResty可以快速构造出足以胜任 10K 以上并发连接响应的超高性能 Web 应用系统。
- 360,UPYUN,阿里云,新浪,腾讯网,去哪儿网,酷狗音乐等都是 OpenResty 的深度用户。
- 简单理解为:相当于封装了 Nginx,并且集成了 Lua 脚本,开发人员只需要简单的提供了模块就可以实现相关的逻辑,而不再像之前,还需要在 Nginx 中自己编写 Lua 的脚本,再进行调用。
3.1 OpenResty 安装
Linux安装OpenResty:
- 添加仓库执行命令
yum install yum-utils
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
- 执行安装
yum install openresty
- 安装成功后 会在默认的目录如下:
/usr/local/openresty
3.2 安装 Nginx
默认已经安装好了nginx,在目录:/usr/local/openresty/nginx 下。
修改/usr/local/openresty/nginx/conf/nginx.conf ,将配置文件使用的根设置为root,目的就是将来要使用lua脚本的时候 ,直接可以加载在root下的lua脚本。
#user nobody; 配置文件第一行原来为这样, 现改为下面的配置
user root root;
3.3 测试访问
测试访问 http://192.168.211.132/
到欢迎界面
4. 广告缓存的载入与读取
本节的任务:
Nginx拦截 http://192.168.31.200/read_content?id=1,执行Lua脚本,先从Nginx缓存中加载,没有的话就从Redis中加载,再没有的话就从MySQL中加载,然后MySQL——>Redis——>Nginx——>浏览器。

4.1 查询数据放入 Redis 中(缓存预热)
实现思路:
定义请求:用于查询数据库中的数据更新到Redis中。
a. 连接MySQL ,按照广告分类ID读取广告列表,转换为json字符串。
b. 连接Redis,将广告列表json字符串存入Redis。
定义请求:
请求:
/update_content
参数:
id --指定广告分类的id
返回值:
json
创建/root/lua目录,在该目录下创建update_content.lua: 目的就是连接MySQL查询数据 并存储到Redis中。
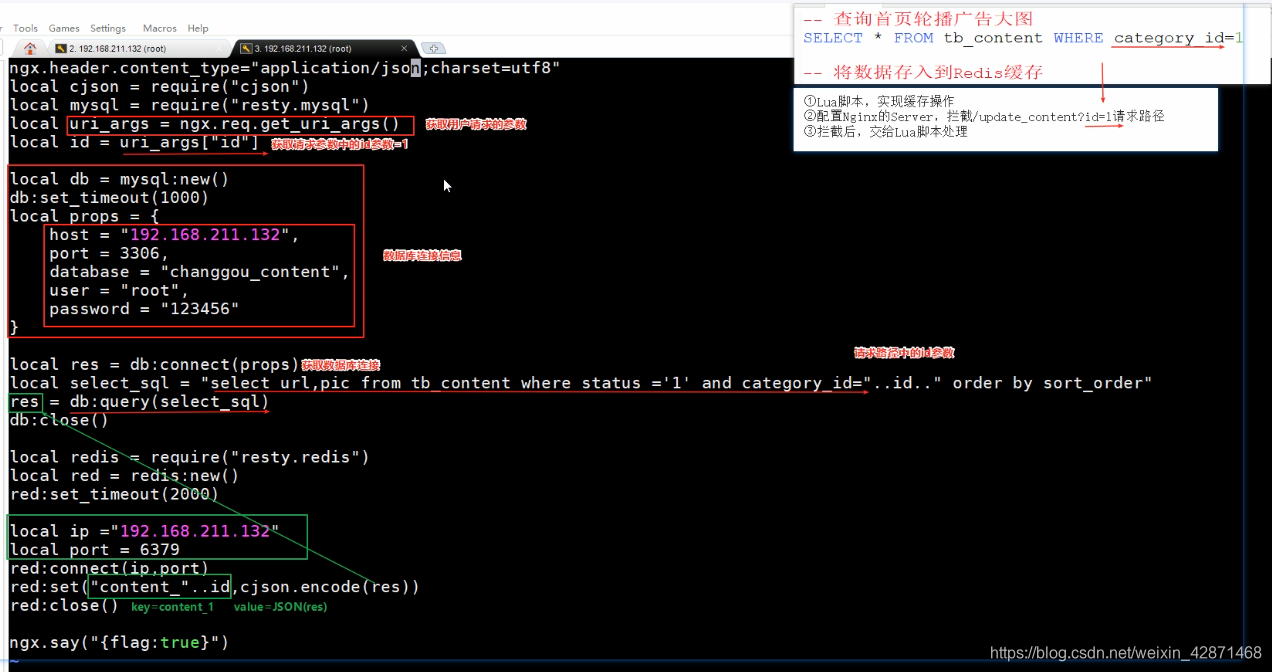
ngx.header.content_type="application/json;charset=utf8"
local cjson = require("cjson")
local mysql = require("resty.mysql")
local uri_args = ngx.req.get_uri_args()
local id = uri_args["id"]
local db = mysql:new()
db:set_timeout(1000)
local props = {
host = "192.168.211.132",
port = 3306,
database = "changgou_content",
user = "root",
password = "123456"
}
local res = db:connect(props)
local select_sql = "select url,pic from tb_content where status ='1' and category_id="..id.." order by sort_order"
res = db:query(select_sql)
db:close()
local redis = require("resty.redis")
local red = redis:new()
red:set_timeout(2000)
local ip ="192.168.211.132"
local port = 6379
red:connect(ip,port)
red:set("content_"..id,cjson.encode(res))
red:close()
ngx.say("{flag:true}")
修改/usr/local/openresty/nginx/conf/nginx.conf文件: 添加头信息,和 location信息
server {
listen 80;
server_name localhost;
location /update_content {
content_by_lua_file /root/lua/update_content.lua;
}
}
定义lua缓存命名空间,修改nginx.conf,添加如下代码即可:
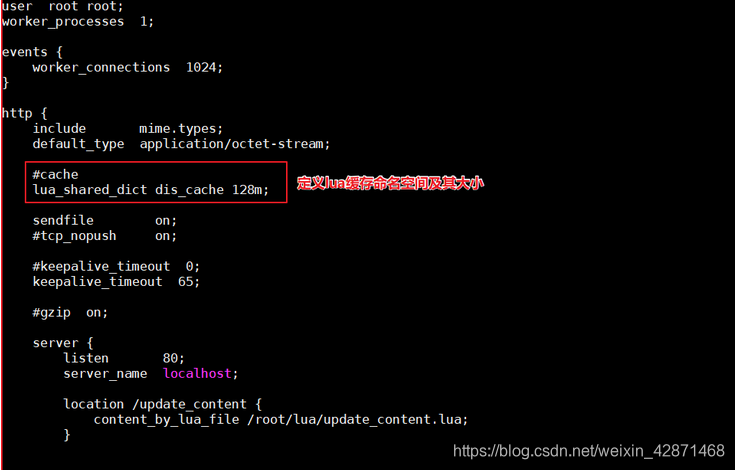
重新启动nginx
请求<http://192.168.211.132/update_content?id=1>可以实现缓存的添加
4.2 从Redis中获取数据(广告缓存读取)
实现思路:
定义请求,用户根据广告分类的 ID 获取广告的列表。通过Lua脚本直接从Redis中获取数据即可。
定义请求:
请求:/read_content
参数:id
返回值:json
在/root/lua目录下创建read_content.lua:
--设置响应头类型
ngx.header.content_type="application/json;charset=utf8"
--获取请求中的参数ID
local uri_args = ngx.req.get_uri_args();
local id = uri_args["id"];
--引入redis库
local redis = require("resty.redis");
--创建redis对象
local red = redis:new()
--设置超时时间
red:set_timeout(2000)
--连接
local ok, err = red:connect("192.168.211.132", 6379)
--获取key的值
local rescontent=red:get("content_"..id)
--输出到返回响应中
ngx.say(rescontent)
--关闭连接
red:close()
在/usr/local/openresty/nginx/conf/nginx.conf中配置如下:
location /read_content {
content_by_lua_file /root/lua/read_content.lua;
}
4.3 加入OpenResty本地缓存
如上的方式没有问题,但是如果请求都到Redis,Redis压力也很大,所以我们一般采用多级缓存的方式来减少下游系统的服务压力。
先查询OpenResty本地缓存,如果没有再查询Redis中的数据,如果没有再查询MySQL中的数据,但凡有数据返回即可。

修改read_content.lua文件,代码如下:

ngx.header.content_type="application/json;charset=utf8"
local uri_args = ngx.req.get_uri_args();
local id = uri_args["id"];
--获取本地缓存
local cache_ngx = ngx.shared.dis_cache;
--根据ID 获取本地缓存数据
local contentCache = cache_ngx:get('content_cache_'..id);
if contentCache == "" or contentCache == nil then
local redis = require("resty.redis");
local red = redis:new()
red:set_timeout(2000)
red:connect("192.168.211.132", 6379)
local rescontent=red:get("content_"..id);
if ngx.null == rescontent then
local cjson = require("cjson");
local mysql = require("resty.mysql");
local db = mysql:new();
db:set_timeout(2000)
local props = {
host = "192.168.211.132",
port = 3306,
database = "changgou_content",
user = "root",
password = "123456"
}
local res = db:connect(props);
local select_sql = "select url,pic from tb_content where status ='1' and category_id="..id.." order by sort_order";
res = db:query(select_sql);
local responsejson = cjson.encode(res);
red:set("content_"..id,responsejson);
ngx.say(responsejson);
db:close()
else
cache_ngx:set('content_cache_'..id, rescontent, 10*60);
ngx.say(rescontent)
end
red:close()
else
ngx.say(contentCache)
end
5. 限流
一般情况下,首页的并发量是比较大的,即使有了多级缓存,如果有大量恶意的请求,也会对系统造成影响。而限流就是保护措施之一。
5.1 Nginx 限流
Nginx 提供两种限流的方式:
- 一是控制速率
- 二是控制并发连接数
限流是解决雪崩的有效手段之一。
5.1.1 控制速率
控制速率的方式之一就是采用漏桶算法。
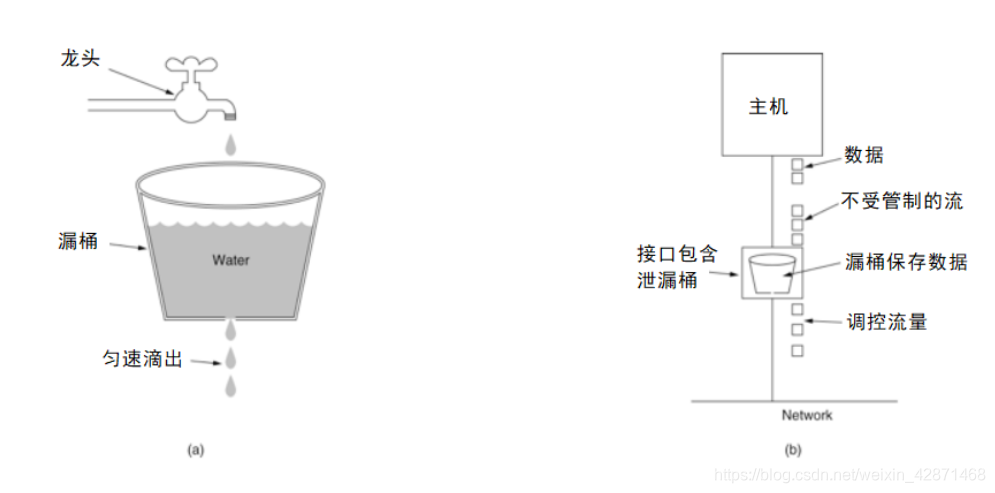
(1)漏桶算法实现控制速率限流
漏桶(Leaky Bucket)算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。示意图如下:
(2) Nginx的配置
修改/usr/local/openresty/nginx/conf/nginx.conf:
user root root;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#cache
lua_shared_dict dis_cache 128m;
#限流设置(重点在这里)binary_remote_addr:根据请求IP进行限流 contentRateLimit:缓存空间名称 10m:缓存空间 rate=2r/s:每秒允许2个请求
limit_req_zone $binary_remote_addr zone=contentRateLimit:10m rate=2r/s;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
location /update_content {
content_by_lua_file /root/lua/update_content.lua;
}
location /read_content {
#使用限流配置
limit_req zone=contentRateLimit;
content_by_lua_file /root/lua/read_content.lua;
}
}
}
说明:
binary_remote_addr 是一种key,表示基于 remote_addr(客户端IP) 来做限流,binary_ 的目的是压缩内存占用量。
zone:定义共享内存区来存储访问信息, contentRateLimit:10m 表示一个大小为10M,名字为contentRateLimit的内存区域。1M能存储16000 IP地址的访问信息,10M可以存储16W IP地址访问信息。
rate 用于设置最大访问速率,rate=10r/s 表示每秒最多处理10个请求。Nginx 实际上以毫秒为粒度来跟踪请求信息,因此 10r/s 实际上是限制:每100毫秒处理一个请求。这意味着,自上一个请求处理完后,若后续100毫秒内又有请求到达,将拒绝处理该请求.我们这里设置成2 方便测试。
(3)处理突发流量
上面例子限制 2r/s,如果有时正常流量突然增大,超出的请求将被拒绝,无法处理突发流量,可以结合 burst 参数使用来解决该问题。
burst 译为突发、爆发,表示在超过设定的处理速率后能额外处理的请求数,当 rate=10r/s 时,将1s拆成10份,即每100ms可处理1个请求。
不过,单独使用 burst 参数并不实用。假设 burst=50 ,rate依然为10r/s,排队中的50个请求虽然每100ms会处理一个,但第50个请求却需要等待 50 * 100ms即 5s,这么长的处理时间自然难以接受。
因此,burst 往往结合 nodelay 一起使用。
两种配置结合就达到了速率稳定,但突然流量也能正常处理的效果。完整配置代码如下:
user root root;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#cache
lua_shared_dict dis_cache 128m;
#限流设置
limit_req_zone $binary_remote_addr zone=contentRateLimit:10m rate=2r/s;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
location /update_content {
content_by_lua_file /root/lua/update_content.lua;
}
location /read_content {
limit_req zone=contentRateLimit burst=4 nodelay;
content_by_lua_file /root/lua/read_content.lua;
}
}
}
5.1.2 控制并发量(连接数)
ngx_http_limit_conn_module 提供了限制连接数的能力。主要是利用limit_conn_zone和limit_conn两个指令。
利用连接数限制 某一个用户的ip连接的数量来控制流量。
注意:并非所有连接都被计算在内 只有当服务器正在处理请求并且已经读取了整个请求头时,才会计算有效连接。此处忽略测试。
配置语法:
Syntax: limit_conn zone number;
Default: —;
Context: http, server, location;
(1) 配置限制固定连接数
http {
include mime.types;
default_type application/octet-stream;
#cache
lua_shared_dict dis_cache 128m;
#限流设置 表示限制根据用户的IP地址来显示,设置存储地址为的内存大小10M
limit_req_zone $binary_remote_addr zone=contentRateLimit:10m rate=2r/s;
#根据IP地址来限制,存储内存大小10M
limit_conn_zone $binary_remote_addr zone=addr:1m;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
#所有以brand开始的请求,访问本地changgou-service-goods微服务
location /brand {
# it_conn addr 2; 表示 同一个地址只允许连接2次。
limit_conn addr 2;
proxy_pass http://192.168.211.1:18081;
}
location /update_content {
content_by_lua_file /root/lua/update_content.lua;
}
location /read_content {
limit_req zone=contentRateLimit burst=4 nodelay;
content_by_lua_file /root/lua/read_content.lua;
}
}
}
(2) 限制每个客户端IP与服务器的连接数,同时限制与虚拟服务器的连接总数。
如下配置:
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server {
listen 80;
server_name localhost;
charset utf-8;
location / {
limit_conn perip 10;#单个客户端ip与服务器的连接数.
limit_conn perserver 100; #限制与服务器的总连接数
root html;
index index.html index.htm;
}
}
6. Canal 同步广告
6.1 Canal 介绍
Canal可以用来监控数据库数据的变化,从而获得新增数据,或者修改的数据。
当数据库发生增删改的时候,会产生一个日志文件,Canal通过读取日志文件,知道哪些数据发生了变化。我们将更新的数据给到Canal微服务中,然后微服务把数据写到Redis里。
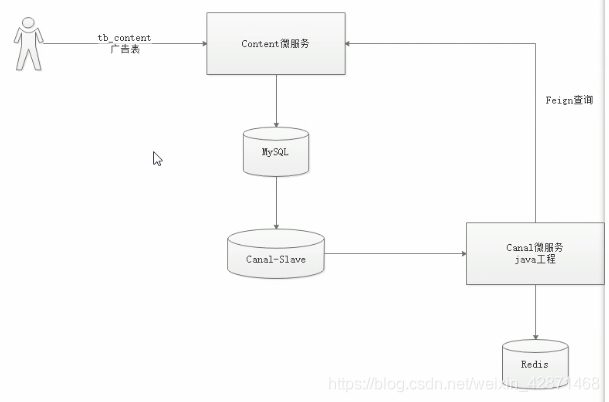
6.2 Canal 工作原理
注意:
- 只能监听 MySQL 变化,主要为 MySQL 服务。
- Canal是基于 MySQL 的主从模式实现的,所以必须先开启binlog模式。
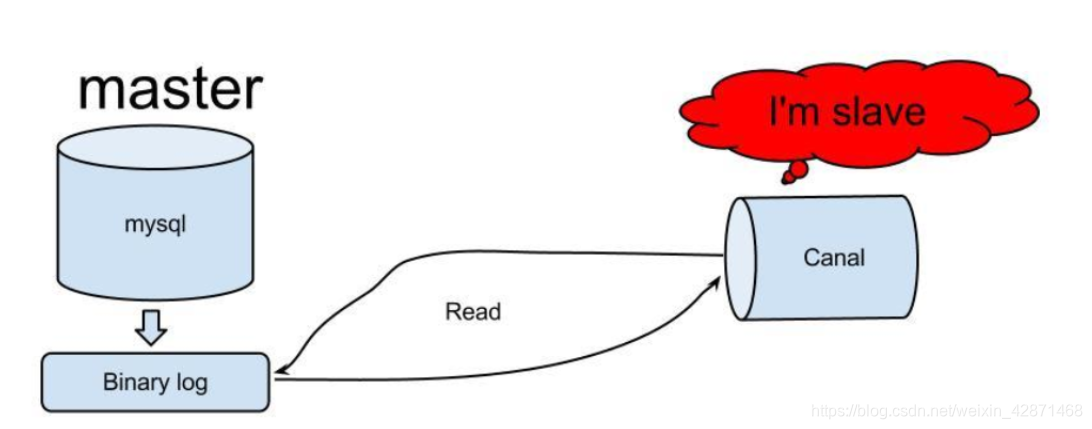
原理:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议;
- mysql master收到dump请求,开始推送binary log给slave(也就是canal);
- canal解析binary log对象(原始为byte流)。
6.3 开启 binlog 模式
先使用docker 创建MySQL容器。
(1) 连接到mysql中,并修改/etc/mysql/mysql.conf.d/mysqld.cnf 需要开启主从模式,开启binlog模式。
执行如下命令,编辑mysql配置文件
docker exec -it mysql /bin/bash
cd /etc/mysql/mysql.conf.d
vi mysqld.cnf
修改mysqld.cnf配置文件,添加如下配置:
log-bin/var/lib/mysql/mysql-bin
server-id=12345
(2) 创建账号 用于测试使用
使用root账号创建用户并授予权限
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
(3)重启mysql容器
docker restart mysql
6.4 Canal 容器安装
下载镜像:
docker pull docker.io/canal/canal-server
容器安装
docker run -p 11111:11111 --name canal -d docker.io/canal/canal-server
进入容器,修改核心配置canal.properties 和instance.properties,canal.properties 是canal自身的配置,instance.properties是需要同步数据的数据库连接配置。
执行代码如下:
docker exec -it canal /bin/bash
cd canal-server/conf/
vi canal.properties
cd example/
vi instance.properties
修改canal.properties的id,不能和mysql的server-id重复,

修改instance.properties,配置数据库连接地址:
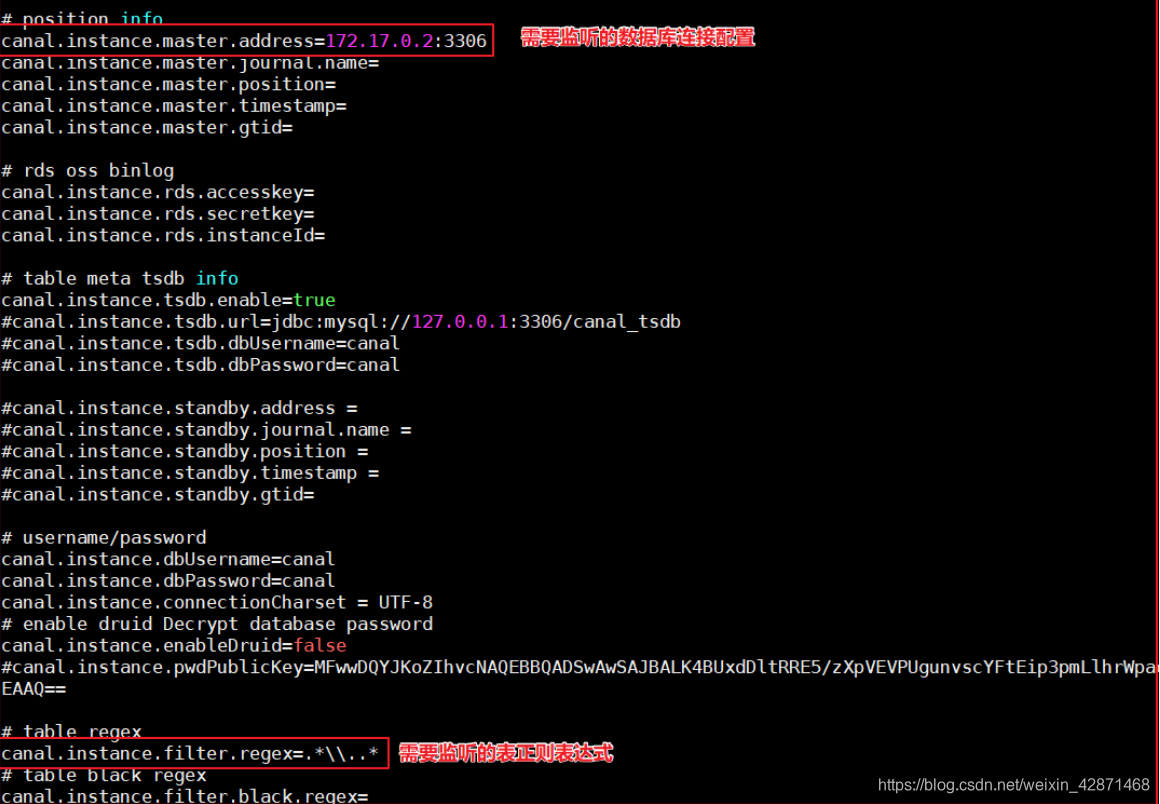
这里的canal.instance.filter.regex有多种配置
注意:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* :表示所有数据库 .\\..*: 表示所有表 .*\\..*:表示所有数据库中所有表的变化都进行监听操作
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
配置完成后,设置开机启动,并记得重启Canal。
docker update --restart=always canal
docker restart canal
6.5 Canal 微服务搭建
当用户执行 数据库的操作的时候,binlog 日志会被Canal捕获到,并解析出数据。我们就可以将解析出来的数据进行同步到Redis中即可。
思路:创建一个独立的程序,并监控Canal服务器,获取binlog日志,解析数据,将数据更新到Redis中。这样广告的数据就更新了。
(1)安装辅助jar包
在canal\spring-boot-starter-canal-master中有一个工程starter-canal,它主要提供了SpringBoot环境下canal的支持,我们需要先安装该工程,在starter-canal目录下执行mvn install
(2)Canal微服务工程搭建
在changgou-service下创建changgou-service-canal工程,并引入相关配置。
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>changgou-service</artifactId>
<groupId>com.changgou</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>changgou-service-canal</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!--canal依赖-->
<dependency>
<groupId>com.xpand</groupId>
<artifactId>starter-canal</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
</project>
application.yml配置
server:
port: 18082
spring:
application:
name: canal
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:7001/eureka
instance:
prefer-ip-address: true
feign:
hystrix:
enabled: true
#hystrix 配置
hystrix:
command:
default:
execution:
timeout:
#如果enabled设置为false,则请求超时交给ribbon控制
enabled: true
isolation:
strategy: SEMAPHORE
#canal配置
canal:
client:
instances:
example:
host: 192.168.211.132
port: 11111
(3)监听创建
创建一个CanalDataEventListener类,实现对表增删改操作的监听,代码如下:
package com.changgou.canal.listener;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.xpand.starter.canal.annotation.*;
@CanalEventListener
public class CanalDataEventListener {
/***
* 增加数据监听
* @param eventType
* @param rowData
*/
@InsertListenPoint
public void onEventInsert(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
rowData.getAfterColumnsList().forEach((c) -> System.out.println("By--Annotation: " + c.getName() + " :: " + c.getValue()));
}
/***
* 修改数据监听
* @param rowData
*/
@UpdateListenPoint
public void onEventUpdate(CanalEntry.RowData rowData) {
System.out.println("UpdateListenPoint");
rowData.getAfterColumnsList().forEach((c) -> System.out.println("By--Annotation: " + c.getName() + " :: " + c.getValue()));
}
/***
* 删除数据监听
* @param eventType
*/
@DeleteListenPoint
public void onEventDelete(CanalEntry.EventType eventType) {
System.out.println("DeleteListenPoint");
}
/***
* 自定义数据修改监听
* @param eventType
* @param rowData
*/
@ListenPoint(destination = "example", schema = "changgou_content", table = {
"tb_content_category", "tb_content"}, eventType = CanalEntry.EventType.UPDATE)
public void onEventCustomUpdate(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
System.err.println("DeleteListenPoint");
rowData.getAfterColumnsList().forEach((c) -> System.out.println("By--Annotation: " + c.getName() + " :: " + c.getValue()));
}
}
(4)启动类创建
在com.changgou中创建启动类,代码如下:
@SpringBootApplication(exclude={
DataSourceAutoConfiguration.class})
@EnableEurekaClient
@EnableCanalClient
public class CanalApplication {
public static void main(String[] args) {
SpringApplication.run(CanalApplication.class,args);
}
}
(5)测试
启动canal微服务,然后修改任意数据库的表数据。
6.6 广告同步
每次执行广告操作的时候,会记录操作日志到,然后将操作日志发送给Canal,Canal将操作记录发送给Canal微服务,Canal微服务根据修改的分类ID调用content微服务查询分类对应的所有广告,Canal微服务再将所有广告存入到Redis缓存。
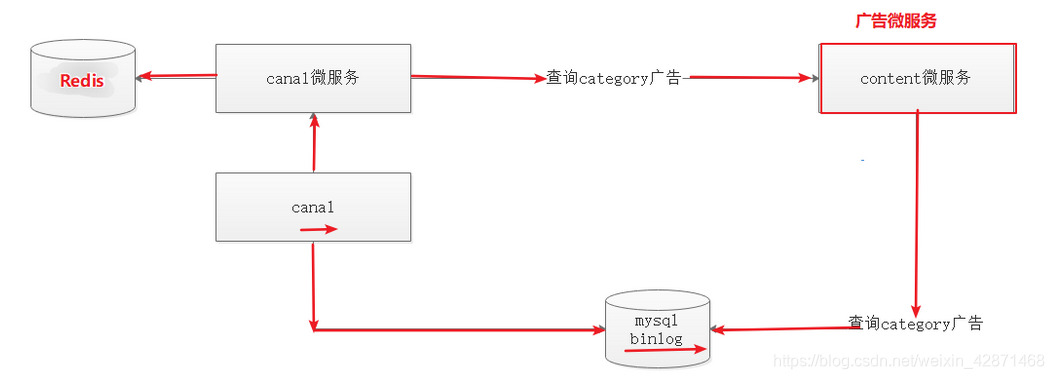
这一块的微服务搭建以及实现过程就不讲了。
总结
本文介绍了Lua、OpenResty以及Canal,并实现了广告的缓存与同步功能。