(一)doc value正排索引
搜索的时候,要依靠倒排索引,你在搜索的时候就可以通过倒排索引直接给相关的document查找出来,就不需要全index的搜索,不需要扫描全部数据了.
排序的时候,是不能用倒排索引排序的,你通过倒排索引把所有的document都拿出来再进行排序,这样明显是不靠谱的.
所以排序需要依靠正排索引(doc values),看到每个document的每个field,然后进行排序.
在建立索引的时候,一方面会建立倒排索引,以供搜索用;一方面会建立正排索引(doc values),以供排序,聚合,过滤等操作使用
doc values是被保存在磁盘上的,此时如果内存足够,os会自动将其缓存在内存中,性能还是会很高;如果内存不足够,os会将其写入磁盘上.

在数据插入之前就对数据进行初步的分析,假如说存放了三个数据,都存放在document里面去了,然后这三个document都指定了三个id,分别是1,2,3.
(二)倒排索引
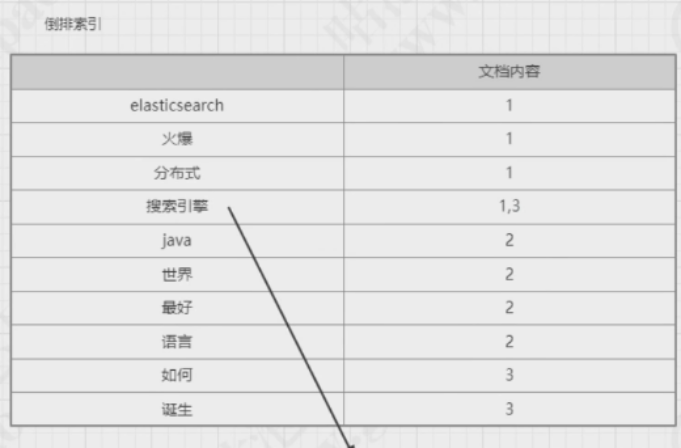
对document进行了语义化的分词,分完词之后,比如说elasticsearch 和 火爆 和分布式 和搜索引擎 这四个词语都在id为1的document里面.
正常情况下正排索引和倒排索引是不能改的,要想改也行,新建一个 type ,然后给数据重新插入一遍.
上面倒排索引的图片是为了方便看的,实际上倒排索引的数据结构是b+tree
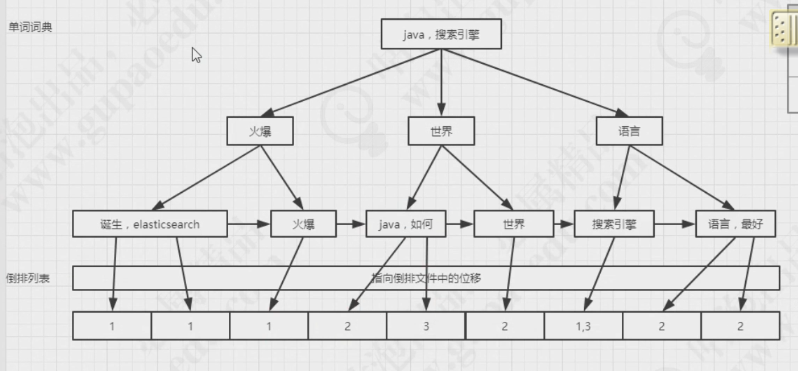
1.倒排索引详细介绍
(三)运行流程
当用户通过ElasticSearch搜索某个关键字的时候, 比如说搜索 “搜索引擎” 这个关键字,会先从倒排索引里面去查找,找到”搜索引擎”关键字所在的索引id为 1和3 ,那么就会去正排索引那里找到索引为1和3的两条数据返回给前端.(索引为1的内容是 ”elasticsearch是最火爆的分布式搜索引擎”, 索引为3 的内容是 “搜索引擎是如何诞生的”)