文章目录
1、正排索引和倒排索引
1.1 正排索引
从广义来说,doc values 本质上是一个序列化的 列式存储 。列式存储 适用于聚合、排序、脚本等操作,所有的数字、地理坐标、日期、IP 和不分词( not_analyzed )字符类型都会默认开启,不支持text和annotated_text类型
1.2 倒排&正排
- 倒排:即
词项=>包含当前词项的doc_id的列表的映射。倒排索引的优势是可以快速查找包含某个词项的文档有哪些。如果用倒排来确定哪些文档中是否包含某个词项就很鸡肋。 - 正排:即
doc_id=>当前文档包含的所有词项的映射。正排索引的优势在于可以快速的查找某个文档里包含哪些词项。同理,正排不适用于查找包含某个词项的文档有哪些。
2、一张图看懂正排&倒排
2.1 图解
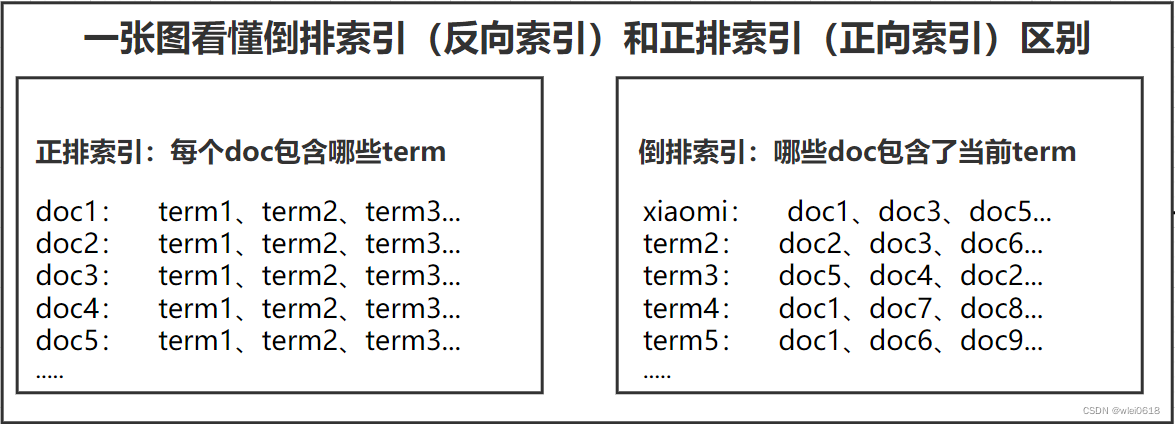
2.2 区别
-
倒排索引的优势 在于查找包含某个项的文档,即用于搜索查询;相反,正排索引的优势是确定哪些项是否存在单个文档里。
-
倒排索引和正排索引均是在 index-time 时创建,保存在 Lucene 文件中(序列化到磁盘)。
-
doc value 使用非 jvm 内存,gc友好。
-
不分词的 field 会在 index-time 时生成正排索引,聚合时直接使用正排索引,而分词的field在创建索引时是没有正排索引的,如果没有创建doc value的字段需要做聚合查询,name需要将fielddata打开,设置为true。
3、一个通俗易懂的比喻
举个通俗易懂的例子
有二十个学生报名学习辅导班,每个学生可以报多个班 每个班都有一个班主任
正排索引:相当于班主任,也就是 班主任知道TA所在班级有多少学生
倒排索引:相当于学生,每个学生知道自己都报了哪些班
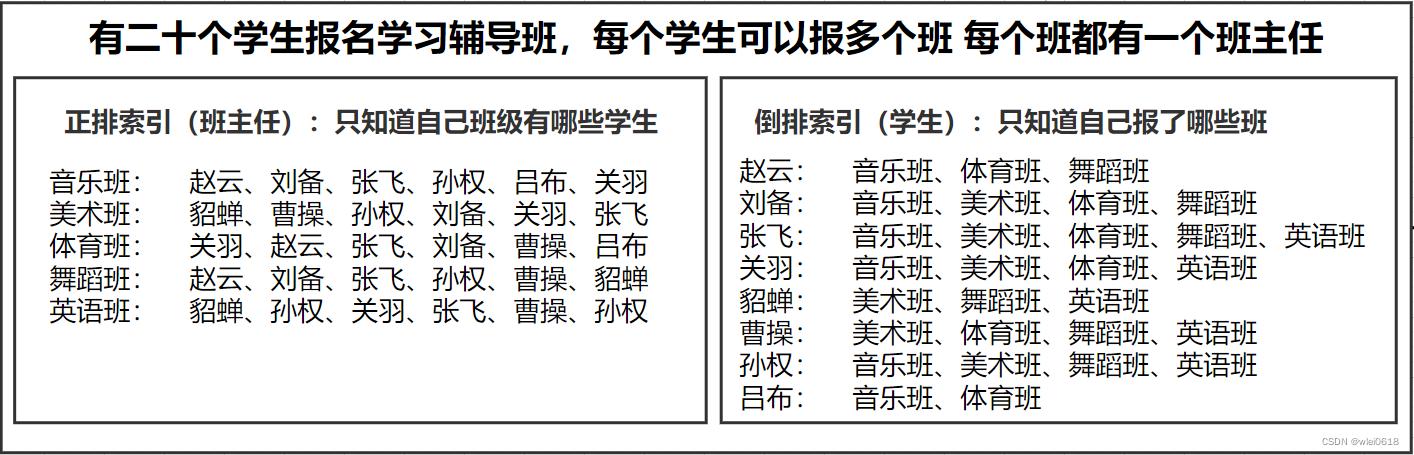
现在我们要查询音乐辅导班 和 美术辅导班都包含了哪些学生,问班主任问两次就行,如果我们问学生,就要每个学生都问一遍,问他你是否报了音乐和美术辅导班,如果你不问到最后一个学生,你永远不知道你没有问到的学生 是不是在音乐班和美术班里,也就没办法统计音乐或者美术班的总人数,所以必须问完每个学生,相当于全表扫描。这就是为什么倒排不适合做聚合。
在这个例子里,班主任相当于正排索引,每个doc就是一个班级,每个doc中包含若干词项,每个词项就好比是一个学生。
班主任知道每个班级有哪些学生 也就是每个doc包含哪些词项。学生只知道自己属于哪些班,相当于哪些班级(doc)包含了这个词项。
4、正排索引的数据结构
4.1 doc values
doc values 是正排索引的基本数据结构之一,其存在是为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc values值以节省磁盘空间。
4.2 fielddata:
概念:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中。与 doc value 不同,当没有doc value的字段需要聚合时,需要打开fielddata,然后临时在内存中建立正排索引,fielddata 的构建和管理发生在 JVM Heap中。Fielddata默认是不启用的,因为text字段比较长,一般只做关键字分词和搜索,很少拿它来进行全文匹配和聚合还有排序。
语法:
PUT /<index>/_mapping
{
"properties": {
"tags": {
"type": "text",
"fielddata": true //true:开启fielddata; false:关闭fielddata
}
}
}
独家深层解读: doc values 是文档到词项的映射 inverted 是词项到文档id的映射从原理上讲 先说倒排索引为什么不适合聚合,你无法通过倒排索引确定doc的总数量,并且因为倒排索引默认会执行analysis,即使聚合,结果也可能不准确,所以你还要创建not_analyzed字段,徒增磁盘占用,举个最简单的例子:假如有一张商品表,每个商品都有若干标签,我们执行了以下查询
GET product/_search
{
"query": {
"match": {
"tags": "性价比"
}
},
"aggs": {
"tag_terms": {
"terms": {
"field": "tags.keyword"
}
}
}
}
这段聚合查询的意思 查询包含“性价比”这个标签商品的所有标签,在执行agg的时候 我们使用倒排索引,那么语义将是这样的:在倒排索引中扫描逐个term,看看这个term对用的倒排表中对应的doc的标签 是否包含“性价比”,如果包含,则记录,由于我们不确定下面一个term是否符合条件,所以我们就要一个一个的判断,所以就造成了扫表。如果使用正排索引,而正排索引的指的是,doc中包含了哪些词项,也就是当前doc_id=>当前字段所包含的所有词项的映射,我们要查找的是符合条件的doc中所有的标签,那么我们直接根据key(doc_id)去拿values(all terms)就可以了,所以就不用扫表。所以聚合查询使用正排索引效率高本质是两种数据结构的区别 和结不结合倒排索引没有关系,结合倒排索引只是预先进行了数据筛选。以上是正排索引在原理上对聚合查询友好的原因 下面我说一下关于两种数据结构在数据压缩上的不同,doc values是一种序列化的列式存储结构,其values其中也包含了词频数据。而这种结构是非常有利于数据压缩的,参考第二版VIP课程中的FOR和RBM压缩算法,因为Lucene底层读取文件的方式是基于mmap的,原理是上是从磁盘读取到OS cache里面进行解码的,使用正排索引的数据结构,由于其列式存储的数据和posting list一样可以被高效压缩,所以这种方式极大的增加了从磁盘中读取的速度,因为体积小了,然后把数据在OS Cache中进行解码
5、总结
-
与 doc value 不同,当没有doc value的字段需要聚合时,需要打开 fielddata,然后临时在内存中建立正排索引,fielddata 的构建和管理发生在 JVM Heap中。
-
Fielddata 默认是不启用的,因为 text 字段比较长,一般只做关键字分词和搜索,很少拿它来进行全文匹配和聚合还有排序。
-
ES 采用了 Circuit Breaker(熔断)机制避免 field data 一次性超过物理内存大小而导致内存溢出,如果触发熔断,查询会被终止并返回异常。
-
fielddata 使用的是 jvm 内存,doc value 在内存不足时会静静的待在磁盘中,而当内存充足时,会蹦到内存里提升性能。