仅作为记录,大佬请跳过。安装相应包后,代码 可直接运行
1 爬虫源代码
参考博主文章传送门中的步进版代码
1.1 爬取猫图
import requests
header={
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
url='https://image.baidu.com/search/acjson?'
param={
'tn': 'resultjson_com',
'logid': '11766533100624926023',
'ipn': 'rj',
'ct': '201326592',
'is':'',
'fp': 'result',
'queryWord': '猫',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid':'',
'st': '',
'z':'',
'ic':'',
'hd':'',
'latest':'',
'copyright':'',
'word': '猫',
's':'',
'se':'',
'tab':'',
'width':'',
'height':'',
'face': '',
'istype': '',
'qc':'',
'nc': '1',
'fr':'',
'expermode':'',
'force':'',
'pn': '1', # 1,1+29,60,90,120,...270
'rn': '30',
'gsm': '96',
}
page_text=requests.get(url=url,headers=header,params=param)
page_text.encoding='utf-8'
# page_text=page_text.text
page_text=page_text.json()
info_list=page_text['data']
del info_list[-1]
img_path_list=[]
for info in info_list:
img_path_list.append(info['thumbURL'])
n=0 # 0,0+30,60,90,120,...,270
for img_path in img_path_list:
img=requests.get(url=img_path,headers=header).content
img_save_path=r'E:\a7imgscatanddog\train\cat\ '+str(n)+'.jpg'
with open(img_save_path,'wb') as f:
f.write(img)
n+=1
仅需修改pn和n的值,每运行一次后修改一次:
(由于百度图库的”ajax请求模式“默认一次只显示30张,运行上述代码一次也只能爬取30张猫图)


其中pn代表从图库的第几张图开始爬,n表示对图片的命名-存入本地
1.2 爬取狗图
import requests
header={
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
url='https://image.baidu.com/search/acjson?'
param={
'tn': 'resultjson_com',
'logid': '11766533100624926023',
'ipn': 'rj',
'ct': '201326592',
'is':'',
'fp': 'result',
'queryWord': '狗',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid':'',
'st': '',
'z':'',
'ic':'',
'hd':'',
'latest':'',
'copyright':'',
'word': '狗',
's':'',
'se':'',
'tab':'',
'width':'',
'height':'',
'face': '',
'istype': '',
'qc':'',
'nc': '1',
'fr':'',
'expermode':'',
'force':'',
'pn': '1', # 1,1+29,60,90,120,...270
'rn': '30',
'gsm': '96',
}
page_text=requests.get(url=url,headers=header,params=param)
page_text.encoding='utf-8'
# page_text=page_text.text
page_text=page_text.json()
info_list=page_text['data']
del info_list[-1]
img_path_list=[]
for info in info_list:
img_path_list.append(info['thumbURL'])
n=0 # 0,0+30,60,90,120,...,270
for img_path in img_path_list:
img=requests.get(url=img_path,headers=header).content
img_save_path=r'E:\a7imgscatanddog\train\dog\ '+str(n)+'.jpg'
with open(img_save_path,'wb') as f:
f.write(img)
n+=1
也是运行多次,每次运行后修改pn和n的值,每次运行爬取30张,与爬取猫图一样
1.3 爬虫展示
文件夹train里,包括cat和dog子文件夹:
—————————————————————————————
为作分类使用,再在train文件夹同一路径,新建val文件夹,存放测试集图片:
val文件夹里也是包含cat和dog子文件夹,猫图和狗图从下载到train文件夹里的图片中—猫狗各剪切80张左右
2 迁移学习源代码
博主使用pytorch的gpu版本,安装pytorch之后的代码可直接运行
(安装pytorch的gpu版本的方法可参考博主文章传送门)
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
# plt.ion() # interactive mode
'''
2 加载数据
'''
# 训练集数据扩充和归一化
# 在验证集上仅需要归一化
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224), #随机裁剪一个area然后再resize
transforms.RandomHorizontalFlip(), #随机水平翻转
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
} # 制作图像大小尺寸处理的步骤
data_dir = 'a7imgscatanddog' # a6hymenoptera_data
image_datasets = {
x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']} # 对图片进行大小尺寸的处理
dataloaders = {
x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=0)
for x in ['train', 'val']} # 生成图像抽取器
dataset_sizes = {
x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
'''
3 可视化部分图像
'''
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# 获取一批训练数据
inputs, classes = next(iter(dataloaders['train']))
# 批量制作网格
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
plt.show()
'''
4 训练模型
'''
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 每个epoch都有一个训练和验证阶段
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# 迭代数据.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 零参数梯度
optimizer.zero_grad()
# 前向
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 后向+仅在训练阶段进行优化
if phase == 'train':
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# 深度复制mo
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 加载最佳模型权重
model.load_state_dict(best_model_wts)
return model
'''
5 可视化模型的预测
'''
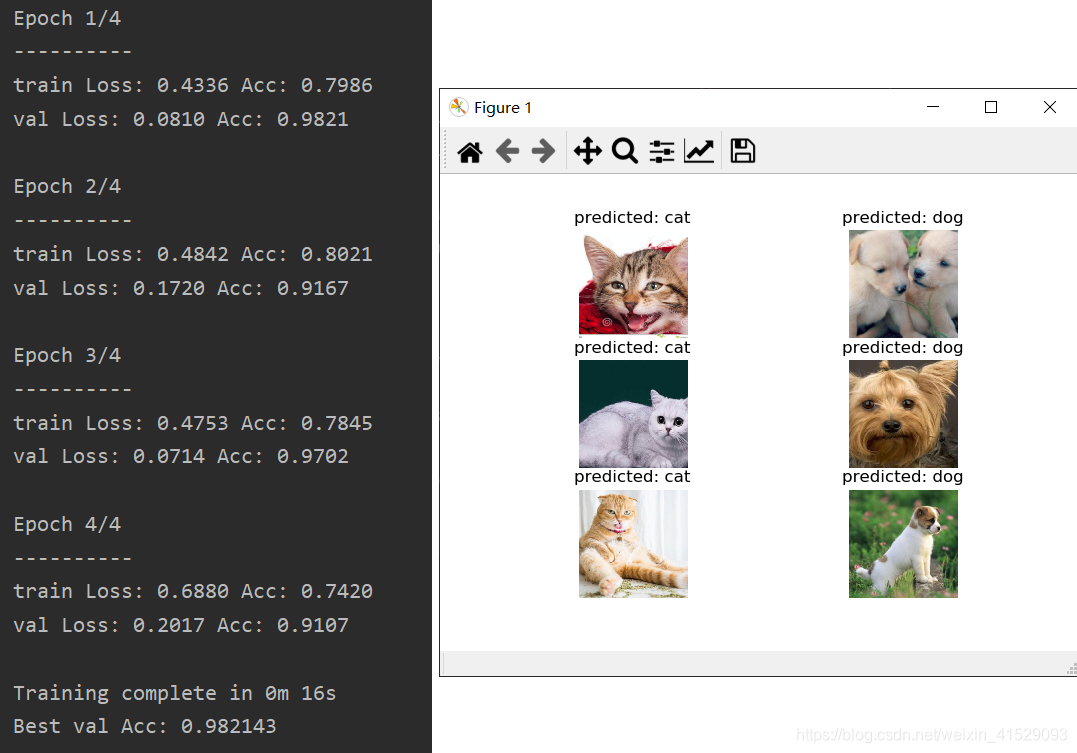
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
'''
6.场景1:微调ConvNet
'''
# model_ft = models.resnet18(pretrained=True)
# num_ftrs = model_ft.fc.in_features
# model_ft.fc = nn.Linear(num_ftrs, 2)
#
# model_ft = model_ft.to(device)
#
# criterion = nn.CrossEntropyLoss()
#
# # 观察所有参数都正在优化
# optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
#
# # 每7个epochs衰减LR通过设置gamma=0.1
# exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
#
#
# '''
# 训练和评估模型
# '''
# model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
# num_epochs=5)
#
# '''
# 模型评估效果可视化
# '''
# visualize_model(model_ft)
#
# plt.show()
'''
7.场景2:ConvNet作为固定特征提取器
'''
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False # 梯度只作为提取,不作为更新
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1) # 调整学习率
'''
训练和评估
'''
model_conv = train_model(model_conv, criterion, optimizer_conv,
exp_lr_scheduler, num_epochs=5)
'''
模型评估效果可视化
'''
visualize_model(model_conv)
plt.show()
只需根据情况修改此处——存放猫狗图片的文件夹的名字
(且保证该文件夹与python程序文件在同一个文件夹里)

3 展示