1.读取网页(俩种方式,按行读与全部读)
import urllib.request #请求
#一次全部读取网页源码
#mystr = urllib.request.urlopen("http://www.baidu.com").read()
#print(mystr.decode("utf-8"))
#按行读取
for line in urllib.request.urlopen("http://www.baidu.com"):
print(line.decode("utf-8"))
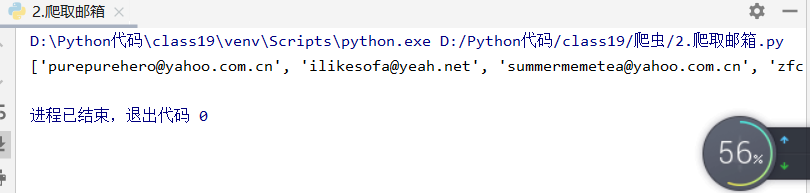
2.爬取邮箱
import urllib.request
import re
mailregex=re.compile(R"([A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4})",re.IGNORECASE)
'''
#按行读取
for line in urllib.request.urlopen("http://bbs.tianya.cn/post-140-393974-1.shtml"):
mylist = mailregex.findall(line.decode("utf-8"))
if mylist: #找到才输出
print(mylist)
'''
#一次全部读取网页源码
mystr = urllib.request.urlopen("http://bbs.tianya.cn/post-140-393974-1.shtml").read()
mylist = mailregex.findall(mystr.decode("utf-8"))
print(mylist)
3.爬取QQ
import urllib.request
import re
QQregex=re.compile(r"[1-9]\d{4,10}",re.IGNORECASE)
#按行读取
for line in urllib.request.urlopen("http://bbs.tianya.cn/post-140-393974-1.shtml"):
line=line.decode("utf-8")
if line.find("QQ")!=-1 or line.find("Qq")!=-1 or line.find("qq")!=-1:
mylist = QQregex.findall(line)
if mylist: #找到才输出
print(mylist)

4.爬取链接
import urllib.request
import re
#(http://\S*?)[\"] 提取以"终止,不带"
#http://\S*?[\"] 提取以"终止,带"
#\S非空字符 ,*0个或多个,?非贪婪 \"|>|)三个字符之一结束
httpregex=re.compile(r"(http://\S*?)[\"|>|)]",re.IGNORECASE)
#按行读取
for line in urllib.request.urlopen("http://www.baidu.com"):
line=line.decode("utf-8")
mylist = httpregex.findall(line)
if mylist: #找到才输出
print(mylist)

5.爬取相对路径
import urllib.request
import urllib
import re
def getallyurl(data):
alllist=[]
mylist1=[]
mylist2=[]
mylist1=gethttp(data)
if len(mylist1)>0:
mylist2=getabsyurl(mylist1[0],data)
alllist.extend(mylist1)
alllist.extend(mylist2)
return alllist
def getabsyurl(url,data):
try:
regex=re.compile("href=\"(.*?)\"",re.IGNORECASE)
httplist=regex.findall(data)
newhttplist=httplist.copy() #深拷贝
for data in newhttplist:
if data.find("http://")!=-1:
httplist.remove(data)
if data.find("javascript")!=-1:
httplist.remove(data)
hostname=gethostname(url)
if hostname!=None:
for i in range(len(httplist)):
httplist[i]=hostname+httplist[i]
return httplist
except:
return ""
def gethostname(httpstr): #抓取主机名称
try:
mailregex = re.compile(r"(http://\S*?)/", re.IGNORECASE)
mylist = mailregex.findall(httpstr)
if len(mylist)==0:
return None
else:
return mylist[0]
except:
return None
def gethttp(data):
try:
mailregex = re.compile(r"(http://\S*?)[\"|>|)]", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getallemail(data):
try:
mailregex = re.compile(r"([A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4})", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getdata(url):
try:
data = urllib.request.urlopen(url).read().decode("utf-8")
return data
except:
return "" #发生异常返回空
#print(gethttp(getdata("http://bbs.tianya.cn/post-140-393974-1.shtml")))
pagedata=getdata("http://bbs.tianya.cn/post-140-393974-1.shtml")
print(getallyurl(pagedata))
'''
mylist=gethttp(pagedata)
hostname=gethostname(mylist[0])
print(hostname)
print(getabsyurl(mylist[0],pagedata))
'''
6.深度遍历网页打印邮箱地址(DFS)使用堆栈实现
import urllib.request
import urllib
import re
def getallyurl(data):
alllist=[]
mylist1=[]
mylist2=[]
mylist1=gethttp(data)
if len(mylist1)>0:
mylist2=getabsyurl(mylist1[0],data)
alllist.extend(mylist1)
alllist.extend(mylist2)
return alllist
def getabsyurl(url,data):
try:
regex=re.compile("href=\"(.*?)\"",re.IGNORECASE)
httplist=regex.findall(data)
newhttplist=httplist.copy() #深拷贝
for data in newhttplist:
if data.find("http://")!=-1:
httplist.remove(data)
if data.find("javascript")!=-1:
httplist.remove(data)
hostname=gethostname(url)
if hostname!=None:
for i in range(len(httplist)):
httplist[i]=hostname+httplist[i]
return httplist
except:
return ""
def gethostname(httpstr): #抓取主机名称
try:
mailregex = re.compile(r"(http://\S*?)/", re.IGNORECASE)
mylist = mailregex.findall(httpstr)
if len(mylist)==0:
return None
else:
return mylist[0]
except:
return None
def gethttp(data):
try:
mailregex = re.compile(r"(http://\S*?)[\"|>|)]", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getallemail(data):
try:
mailregex = re.compile(r"([A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4})", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getdata(url):
try:
data = urllib.request.urlopen(url).read().decode("utf-8")
return data
except:
return "" #发生异常返回空
def DFS(urlstr):
visitlist=[] #代表已经访问过的 因为深度遍历容易陷入死循环
urlstack=[] #新建栈
urlstack.append(urlstr)
while len(urlstack)!=0:
url=urlstack.pop() #堆栈弹出数据
print(url) #打印url连接
if url not in visitlist:
pagedata=getdata(url) #获取网页源码
emaillist=getallemail(pagedata) #提取邮箱到列表
if len(emaillist)!=0: #邮箱不为空
for email in emaillist: #打印所有邮箱
print(email)
newurllist=getallyurl(pagedata) #抓取所有的url
if len(newurllist)!=0: #p判断长度
for urlstr in newurllist: #循环处理所有url
if urlstr not in urlstack: #判断存在或者不存在
urlstack.append(urlstr) #插入
visitlist.append(url)
DFS("http://bbs.tianya.cn/post-140-393974-5.shtml")
#DFS("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&srcqid=4974407339122272475&tn=48020221_29_hao_pg&wd=%E5%B2%9B%E5%9B%BD%E5%A4%A7%E7%89%87%20%E7%95%99%E4%B8%8B%E9%82%AE%E7%AE%B1&oq=%25E5%25A4%25A9%25E6%25B6%25AF%25E5%25A4%25A7%25E5%25AD%25A6%25E8%2580%2581%25E5%25B8%2588%25E9%2582%25AE%25E7%25AE%25B1&rsv_pq=e1e17d5400093975&rsv_t=83fc1KipT0e6dU2l8G8651PAihzqMxhN1tT8Ue1JiKtvBGgKILwuquM4g7%2BKNKKKp6AkBxK7opGg&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=40&rsv_sug1=4&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=11395&rsv_sug4=11395")
7.广度遍历网页打印邮箱地址(BFS)使用队列
import urllib.request
import urllib
import re
from collections import deque
def getallyurl(data):
alllist=[]
mylist1=[]
mylist2=[]
mylist1=gethttp(data)
if len(mylist1)>0:
mylist2=getabsyurl(mylist1[0],data)
alllist.extend(mylist1)
alllist.extend(mylist2)
return alllist
def getabsyurl(url,data):
try:
regex=re.compile("href=\"(.*?)\"",re.IGNORECASE)
httplist=regex.findall(data)
newhttplist=httplist.copy() #深拷贝
for data in newhttplist:
if data.find("http://")!=-1:
httplist.remove(data)
if data.find("javascript")!=-1:
httplist.remove(data)
hostname=gethostname(url)
if hostname!=None:
for i in range(len(httplist)):
httplist[i]=hostname+httplist[i]
return httplist
except:
return ""
def gethostname(httpstr): #抓取主机名称
try:
mailregex = re.compile(r"(http://\S*?)/", re.IGNORECASE)
mylist = mailregex.findall(httpstr)
if len(mylist)==0:
return None
else:
return mylist[0]
except:
return None
def gethttp(data):
try:
mailregex = re.compile(r"(http://\S*?)[\"|>|)]", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getallemail(data):
try:
mailregex = re.compile(r"([A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4})", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getdata(url):
try:
data = urllib.request.urlopen(url).read().decode("utf-8")
return data
except:
return "" #发生异常返回空
def BFS(urlstr):
urlque=deque([]) #新建队列
urlque.append(urlstr)
while len(urlque)!=0:
url=urlque.popleft() #队列弹出数据
print(url) #打印url连接
pagedata=getdata(url) #获取网页源码
emaillist=getallemail(pagedata) #提取邮箱到列表
if len(emaillist)!=0: #邮箱不为空
for email in emaillist: #打印所有邮箱
print(email)
newurllist=getallyurl(pagedata) #抓取所有的url
if len(newurllist)!=0: #p判断长度
for urlstr in newurllist: #循环处理所有url
if urlstr not in urlque: #判断存在或者不存在
urlque.append(urlstr) #插入
#BFS("http://bbs.tianya.cn/post-140-393974-5.shtml")
BFS("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&srcqid=4974407339122272475&tn=48020221_29_hao_pg&wd=%E5%B2%9B%E5%9B%BD%E5%A4%A7%E7%89%87%20%E7%95%99%E4%B8%8B%E9%82%AE%E7%AE%B1&oq=%25E5%25A4%25A9%25E6%25B6%25AF%25E5%25A4%25A7%25E5%25AD%25A6%25E8%2580%2581%25E5%25B8%2588%25E9%2582%25AE%25E7%25AE%25B1&rsv_pq=e1e17d5400093975&rsv_t=83fc1KipT0e6dU2l8G8651PAihzqMxhN1tT8Ue1JiKtvBGgKILwuquM4g7%2BKNKKKp6AkBxK7opGg&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=40&rsv_sug1=4&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=11395&rsv_sug4=11395")