**
31.爬虫
**
1.urllib

URL请求:
使用urllib.request 模块
打开网址 response = urllib.request.open(“网址”)
读取内容 html = response.read()
打印内容 print(html)
进行解码 html = html.decode(“编码类型(一般为utf-8,可在网页查看源码查看)”)
获取地址 response.geturl()
获取信息 response.info() ---是个对象,具体内容可用print打印出来

2.实战
#对翻译网址的爬取
#小甲鱼P55
#可使用time.sleep(5) 减缓访问间隔 或 使用代理
import urllib.request
import urllib.parse
import json
#添加浏览器标识(一种为该方式,另一种在后追加,见图1)
head = {}
head[‘user-agent’]=’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36’
url='http://rlogs.youdao.com/rlog.php?_npid=dictweb&_ncat=pageview&_ncoo=588639594.4354843&_nssn=NULL&_nver=1.2.0&_ntms=1585799026538&_nref=http%3A%2F%2Fwww.youdao.com%2Fw%2F%25E6%2588%2591%25E7%2588%25B1%2520changjunfu%2F&_nurl=http%3A%2F%2Fwww.youdao.com%2Fw%2F%25E6%2588%2591%25E7%2588%25B1%2520changjun%2F%23keyfrom%3Ddict2.top&_nres=1536x864&_nlmf=1585799026&_njve=0&_nchr=utf-8&_nfrg=keyfrom%3Ddict2.top&keyfrom=dict2.top&page=search&q=%E6%88%91%E7%88%B1%20changjun'
date = {}
date['pid']='dictweb'
date['_ncat']='pageview'
date['_ncoo'] ='588639594.4354843'
date['_nssn'] ='NULL'
date['_nver'] ='1.2.0'
date['_ntms'] ='1585799026538'
date['_nref'] ='http://www.youdao.com/w/%E6%88%91%E7%88%B1%20changjunfu/'
date['_nurl']='http://www.youdao.com/w/%E6%88%91%E7%88%B1%20changjun/#keyfrom=dict2.top'
date['_nres']='1536x864'
date['_nlmf'] ='1585799026'
date['_njve'] ='0'
date['_nchr'] ='utf-8'
date['_nfrg'] ='keyfrom=dict2.top'
date['keyfrom'] ='dict2.top'
date['page'] ='search'
date['q'] ='我爱 changjun'
#将数据进行编码
date = urllib.parse.urlencode(date).encode('utf-8')
#获取、解码、输出
response = urllib.request.urlopen(url,date,head)
html = response.read().decode('utf-8')
print(html)
#用于格式转换
temp = json.loads(html)
#temp 应该是个字典,然后再操作
代理事例:
import urllib.request
url = 'https://www.baidu.com/'
#ip可用列表随机使用,见图2
proxy_support = urllib.request.ProxyHandler({"HTTP":"61.135.186.243:80"})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url)
html = response.read().decode("utf-8")
print(html)
图1:另一种浏览器标识(在后追加)

图2:p可用列表随机使用


下载:
1.urllib.request.urlretrieve(‘网址’,‘文件名’,none)
2.
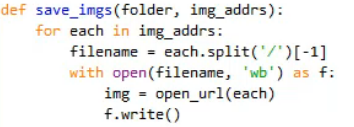
3.
from selenium import webdriver
import requests
driver = webdriver.Chrome()
driver.implicitly_wait(30)
driver.get('http://baidu.com')
# 使用get_attribute()方法获取对应属性的属性值,src属性值就是图片地址。
url = driver.find_element_by_css_selector('#lg>img').get_attribute('src')
driver.quit()
# 通过requests发送一个get请求到图片地址,返回的响应就是图片内容
r = requests.get(url)
# 将获取到的图片二进制流写入本地文件
with open('baidu.png', 'wb') as f:
# 对于图片类型的通过r.content方式访问响应内容,将响应内容写入baidu.png中
f.write(r.content)
3.scrapy

步骤1:创建scrapy项目

步骤二:定义item容器

在item.py中编写需要储存的内容

步骤三:编写爬虫
https://blog.csdn.net/lwgkzl/article/details/89237060
运行scrapy shell “网址”
进入命令模式,出现>>>行
可进行xpath等操作(见小甲鱼P64 22分)

如:response.xpath('//title/text()').extract()
//title 表示目标
//text() 表示转换成文本
.extract() 表示转化成字符串类型
获得内容 sel.xpath(‘//ul/li/@herp’.extract()

对源码进行筛选,使用自带的selector选择器

XPath的使用
https://cloud.tencent.com/developer/article/1571528



步骤四:储存内容
scrapy crawl 爬虫名 -o 文件名.json -t 文件类型(json)
4.selenium
详见:https://cuiqingcai.com/5630.html
from selenium import webdriver
#设置浏览器驱动举例:
#browser = webdriver.Chrome()
#browser = webdriver.Firefox()
#browser = webdriver.Edge()
#browser = webdriver.PhantomJS()
#browser = webdriver.Safari()
browser = webdriver.chrome()
#请求网页
browser.get(‘https://www.taobao.com’)
#打印网页源码
#print(browser.page_source)
查找方法举例:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
成功实战(爬图片):
from selenium import webdriver
import requests
import time
#下载图片
def download_img(url,temp):
filename = 'img_crawler_'+str(temp)+'.jpg'
with open(filename,'wb') as f:
f.write(url.content)
print(str(temp)+" finish")
time.sleep(.5)
#获取地址
browser = webdriver.Chrome()
browser.get('https://www.meitulu.com/item/21036.html')
web_href = browser.find_elements_by_xpath('/html/body/div[4]/center/img')
#web_href = browser.find_elements_by_css_selector('#lg>img')
print('获取')
print(web_href)
print('结束')
temp = 1
for item in web_href:
href =item.get_attribute('src')
print(temp, href, sep="---")
url_img = requests.get(href)
download_img(url_img,temp)
temp += 1
time.sleep(2)
browser.close()