前面一篇博客详细介绍了KMP算法,KMP算法的代码不算繁琐,但是理解起来相对比较困难。
后来Daniel M.Sunday在1990年提出了Sunday算法,其思想是从前往后匹配,在匹配失败时关注的不是失配位而是主串中参加匹配的最末位字符的下一位字符。
- 如果该字符没有在模式串中出现则在下一轮比较时直接跳过,即移动位置 = 模式串长度+ 1
- 如果该字符在模式串中出现过,假设其出现在模式串中的最右位置为P[j], 那么移动位置 = m (模式串长度) - j 。
举个例子说明下Sunday算法
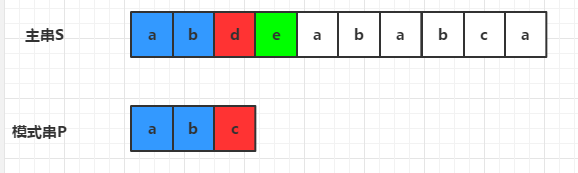
1)第一轮比较,S[2]!=P[2],发生失配,那么就关注主串中参与匹配的最末位字符的下一位,也就是S[3] (图中绿色块),因为e不存在于模式串P中,那么就将模式串移动4位(pLen+1)
因为移动不大于pLen位的时候,在匹配时都需要将S[3]与模式串某个字符进行匹配,肯定是无法匹配上的,毕竟S[3]不存在于模式串P中
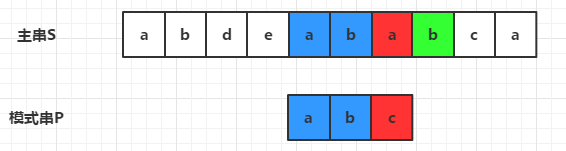
2)第二轮比较,同样的,S[6]!=P[2]发生失配,关注的字符就是S[7] “b”,它存在于模式串P中,移动模式串使得S[7]与该字符在模式串中最右的位置匹配上,即移动2位
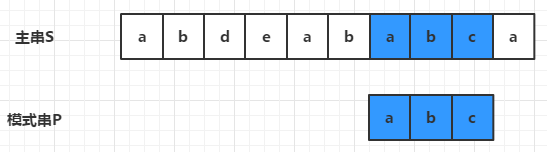
3)第三轮就匹配上了
Sunday的思想比较简单,就直接上代码了
在Sunday算法中,我们关注主串中参与匹配的最末位字符的下一位(假设为X)是否存在于模式串中,根据其不同的结果移动的位数也不一样, 想要算法效率高,那么我们就需要快速地得到某个字符X是否存在于模式串中,以及对应需要位移的长度。
所以X是否存在于P不适合通过contains这样的函数来判断,因为其底层是通过逐步比较的方式,时间复杂度为O(m),效率很差,那么有什么更好的办法呢?
根据字符判断其是否存在于一个字符串中(字符集合), 我们可以想到map,不过其效率也不是很好。考虑到字符都可以用ASCII码来表示,那么我们就可以用一个数组来表示当X为不同字符时对应的位移长度
/**
* 计算位移数组
*/
public static int[] calShiftArray(String p, int pLen) {
int maxNum = 128;//使用ASCII码总个数作为位移数组的长度
int[] shift = new int[maxNum];
for (int i = 0; i < maxNum ; i++) {
shift[i] = pLen + 1;
}
//对于模式串中存在的字符,其位移长度=模式串长度-其在模式串中出现的最右位置下标
//因为shift计算的时候是i是从小到大,如果遇到两个相同的字符,那么较右侧的位移长度会覆盖前面的
for (int i = 0; i < pLen; i++) {
shift[p.charAt(i)] = pLen - i;
}
return shift;
}
/**
* sunday算法匹配
* */
public static int sundayAlogrithm( String s, String p) {
int sLen = s.length();
int pLen = p.length();
int[] shift = calShiftArray(p, pLen);
int i = 0;//表示与模式串第一位匹配的主串字符下标
int j = 0;//表示模式串正在匹配的下标
while (i <= sLen - pLen) {
j = 0;
while (Objects.equals(s.charAt(i+j), p.charAt(j))) {
j++;
if (j == pLen) {
return i;
}
}
//如果遇到P[j]!=S[i+j],说明发生失配,那么就移动模式串,移动长度=shift[x],x为关注的字符下标
i = i + shift[s.charAt(i + pLen)];
}
return -1;
}
Sunday算法的时间复杂度
从上面的分析来看,Sunday算法大大加速了失配时的位移速度,但是在最坏的情形下,其时间复杂度会变为O(m*n)
假设主串是aaabaaabaaabaaab,模式串是aaaa,我们可以知道aaaa不是上述主串的子串;在使用Sunday算法进行匹配的时候, 大部分情形下,关注字符都是在模式串中存在的(模式串只有a一个字符), 也就是说在大部分情形下模式串都只能移动1位,效率一下子降低了
那么最优的情形的,就是每次失配都可以移动 模式串长度+1 位,那么其时间复杂度就是O(n/m)
简单来说,Sunday最差情况的时间复杂度为O(m*n), 最优情况的时间复杂度为O(n/m)
参考: