新的 QUIC 和 HTTP/3 协议即将到来,这是可谓是网络发展的精华所在。 结合过去30年来网络实践中的经验和教训,新一代的协议栈针对性能、隐私、安全和灵活性方面,均有大幅的提升、改进。
当前,关于 QUIC 发展潜力的讨论,大都是基于此前 Google 进行的早期版本 QUIC的实验结果 。然而,其潜在的缺陷却很少有人讨论;此外,对于即将发布的标准版的功能特性,我们依然知之甚少。尽管大家对 QUIC 极其乐观和期待,但是,本文将一反常态,以“唱反调”的观点,探讨 QUIC 和 HTTP/3 在实践中可能失败的种种因素。为了尽可能客观、公正的陈述观点,在我的每一条观点后面,我将列举出若干的反对意见。希望读者能在两方的辩驳中,思考判断,得出自己的一些观点来。
注意:如果你尚不清楚 QUIC 和 HTTP/3 的具体情况,建议花点时间,快速了解下。以下这些资源,对你快速了解,或将有些帮助:
Mattias Geniar 的博客文章
Cloudflare 的文章
Robert Graham 评论
Daniel Stenberg(@bagder) 的 HTTP/3 详解
Patrick McManus 的邮件列表和博客文章
以及今年我本人在 DeltaVConf的探讨
1. 端到端 UDP 加密?
QUIC 的卖点之一,便是其端到端加密。在现有的 TCP 协议中,大部分的传输信息都是公开的,只有数据部分是加密的;而 QUIC 几乎对所有内容进行加密处理,并且应用数据完整性保护(图 1 )。这将极大地提高隐私保护和数据安全性,避免数据被网络中间设备篡改。上述的改进,是 QUIC 采用 UDP 的主要原因之一:改进 TCP 太过困难了,牵一发而动全身。
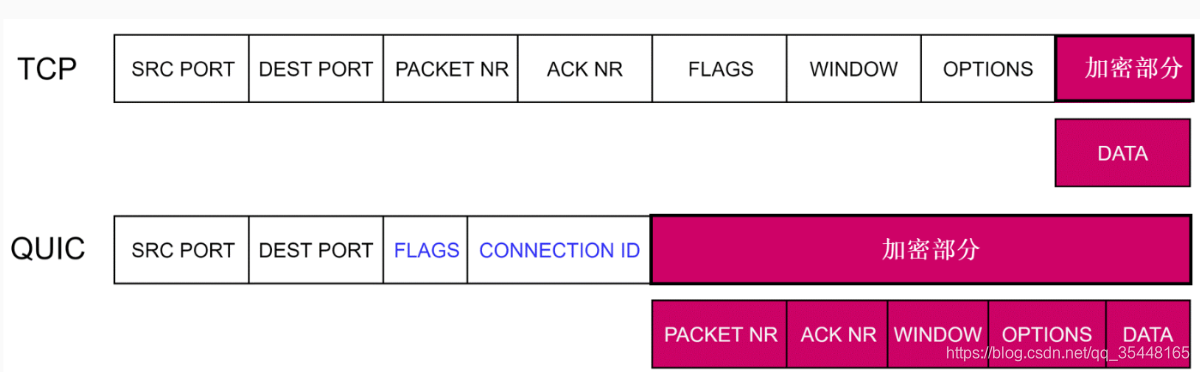
图 1:TCP 和 QUIC 中(加密)字段的简化概念表示
- 网络运营商和 spin bit
现今,网络运营商极少去优化和管理网络。他们无法确认某个数据包是 ACK 包还是重传包;对于拥塞控制/发送速率控制,除了丢包,他们别无它法。所以,对于某个给定的连接,要估算其 RTT(若该时间增大,意味着拥塞或 bufferbloat(缓冲区膨胀)) ,更是困难。
关于将这些标记添加回可见的 QUIC 头部已经有很多讨论,但最终结果是,只有 1 bit 用于 RTT 测算—— spin bit。这个“轮转位”的概念的是这样的:在每次往返时改变一次值,从而使得网络中间设备可以观察到变化并以这种方式估算 RTT,参见 图 2。虽然有点帮助,但是仍然大大地限制了运营商,特别是初始标识是 Chrome 和 Firefox 不支持的“轮转位”。QUIC 唯一支持的其他选项是“显式拥塞提醒”,它采用 IP 级别的标识来表示拥塞。
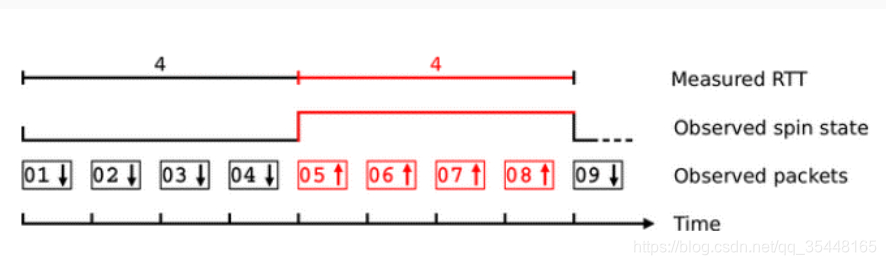
图 2:“轮转位”工作原理简述
- UDP 拦截、alt-svc
不知道你会怎样做?但如果我是一个网络运营商,如果我正在进行 TCP 网络优化或者在应用特殊的安全措施,我会非常想要彻底地封锁 QUIC。对于网页浏览来说,拦截 443 端口上的 UDP 流量,并不会有什么问题。在开发 QUIC 时,Google 也认识到了该问题。为了搞清楚当前网络对 UDP/QUIC 的封锁情况,他们研究得出 3-5% 的网络不允许 QUIC 流量通过。结果看起来还不错,不过该数据并未包含不计其数的企业网络;此外,更重要的问题是,这种状况还会一直延续下去吗?如果 QUIC 应用的更加广泛后,这些网络会停止对 QUIC 的主动拦截吗(至少是在他们更新他们的防火墙和网络管理工具后)?
在使用 quick-tracker conformance 工具测试我们自己的 QUIC 实现时,发生一个“有趣”的小故事:当测试一台在加拿大的服务器时,大部分测试突然失效。更进一步测试发现,一些 IP 段主动阻塞 QUIC 流量,导致了测试的失败。
拦截 QUIC 流量并不会对浏览网页的终端用户带来任何影响–网站照常访问。因为,无论如何浏览器(和服务器)必须要解决 UDP 阻塞问题。为此,他们总是把 TCP 留为备用措施,而不是干等着 QUIC 连接 timeout。
服务器将采用 alt—svc 机制提供对 QUIC 的支持,但浏览器只能在一定程度上信任它;因为快速变化的网络环境意味着 QUIC 随时有可能被拦截。在 QUIC 流量被拦截的企业网络里,网络管理员无需处理用户的各种问题同时还可以维持对网络的有力控制,他们何乐而不为呢?他们还无需为此额外地维护一个独立的 QUIC/HTTP3 协议栈。
最后,有人可能会问了:为什么这些巨头比如 Google 即使是极其不容易的情况下,还要开发部署 QUIC 协议呢?在我看来,像 Google 这样的巨头公司对他们从服务器到各个边缘网络的链路,有着绝对的掌控,同时,还与其他网络运营商有联系。他们或多或少是知道网络上的问题的,并通过调整负载均衡,路由和服务器来缓解这些问题。为了解决这些问题,在开发 QUIC 时,他们可能会做点手脚,比如在 QUIC 的非加密部分编码一些信息 – 连接 ID。该 18 字节长的域可以编码负载均衡信息在里头。他们还可以设想为其数据包添加额外的包头,一旦流量离开企业网络就将其剥离。所以,这样看来,在这个游戏中,这些巨头可能会失去一些,但是那些服务器提供商或是小公司会失去更多。
反对观点
- 由于其优秀的性能,终端用户迫切希望用上 QUIC ;
- 基于其自身的拥塞控制及快速启动配置,QUIC 并不需要性能增强的中间设备;
- 大部分网络并没有阻挡 QUIC 流量,大的变革同时也意味着大的机会;
- 运行 QUIC + HTTP/3 只需在现有的 TCP + HTTP/2 的服务器配置文件添加若干行配置即可。
2.CPU 问题
到目前为止, QUIC 协议完全是在用户层实现的(而 TCP 协议是典型的运行在操作系统内核空间的)。在用户层实现,可以方便地更新、迭代,而无需升级内核,但同时也带来严重的性能开销(主要是用户层到内核空间的通信)和潜在的安全问题。
在他们发表的研究论文中,Google 表示,相较于同等条件下的 TCP+TLS 协议栈,他们在服务器端的 QUIC 协议栈,需要 2 倍于前者的 CPU 开销。这已经是在经过优化的内核上的较好的结果。换句话来说,为了提供同等质量的网络,至少需要 2 倍性能的硬件。他们也提到 QUIC 协议在移动设备上性能降低的问题,不过并未提供相关数据。还好,我们找到了另外一份关于移动设备上的测试报告。该报告研究显示, Google 的 QUIC 比 TCP 快,只是在不同机型上这一优势并不明显,见图 3。这主要是因为 QUIC 的拥塞控制是基于限制应用程序时间 58%(vs 桌面设备的 7%),这意味着 CPU 不能处理数目过大的接入数据包。
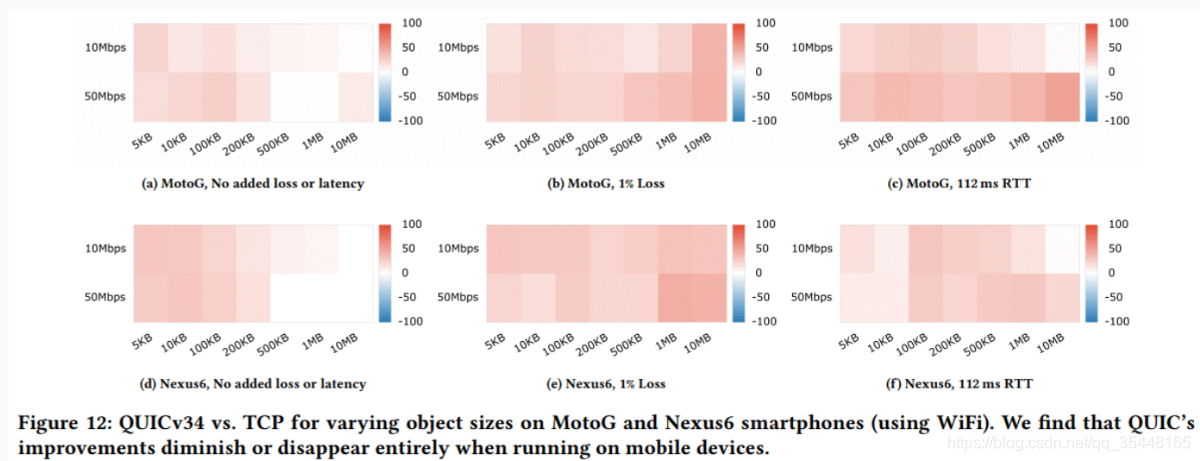
图 3:性能 QUIC vs TCP 。红色 = QUIC 表现较好, 蓝色 = TCP 表现较好。
看来 QUIC 将为 TCP 网络不好的##高端##设备带来改善的机会。不幸的是,不良的网络往往是由于落后的硬件设备。那么,采用 QUIC 协议为网络带来的改进,将被缓慢的硬件抵消。结合现在的网页也越来越消耗 CPU 资源的事实(导致网页的整体性能越来越依赖于 JavaScript 的性能而非网络性能),这确实是个难题。
IoT 和 TypeScript
QUIC 另一个常被吹嘘的应用场景是物联网(IoT)设备,因为这些设备经常需要间歇性的(蜂窝)网络接入,而 QUIC 的低延迟启动、0-RTT和良好的传输可靠性,看起来很适合物联网设备。但是,这些设备的 CPU 通常相当的慢。尽管,据我所知目前尚未有在该类设备上测试的 QUIC 协议栈,但 QUIC 的设计者提到,在物联网应用场景下仍存在很多的问题,任何一个决定都有可能影响到 QUIC 性能表现。类似的,不少人提到了硬件实现 QUIC 的想法,不过,据我的经验来看,这只是某些人一厢情愿的想法罢了。
我是 Quicer(NodeJS QUIC 的 TypeScript 实现)的合著者。对于那些用 C/C++,Rust 或 Go 实现的协议栈来说,这显得相当离奇。我们选择用 TypeScript 主要是为了评估 QUIC 脚本语言实现的开销和可行性。由于我们的进行试验的时间处于 QUIC 的早期,所以测试结果并不是太好,见图 4。 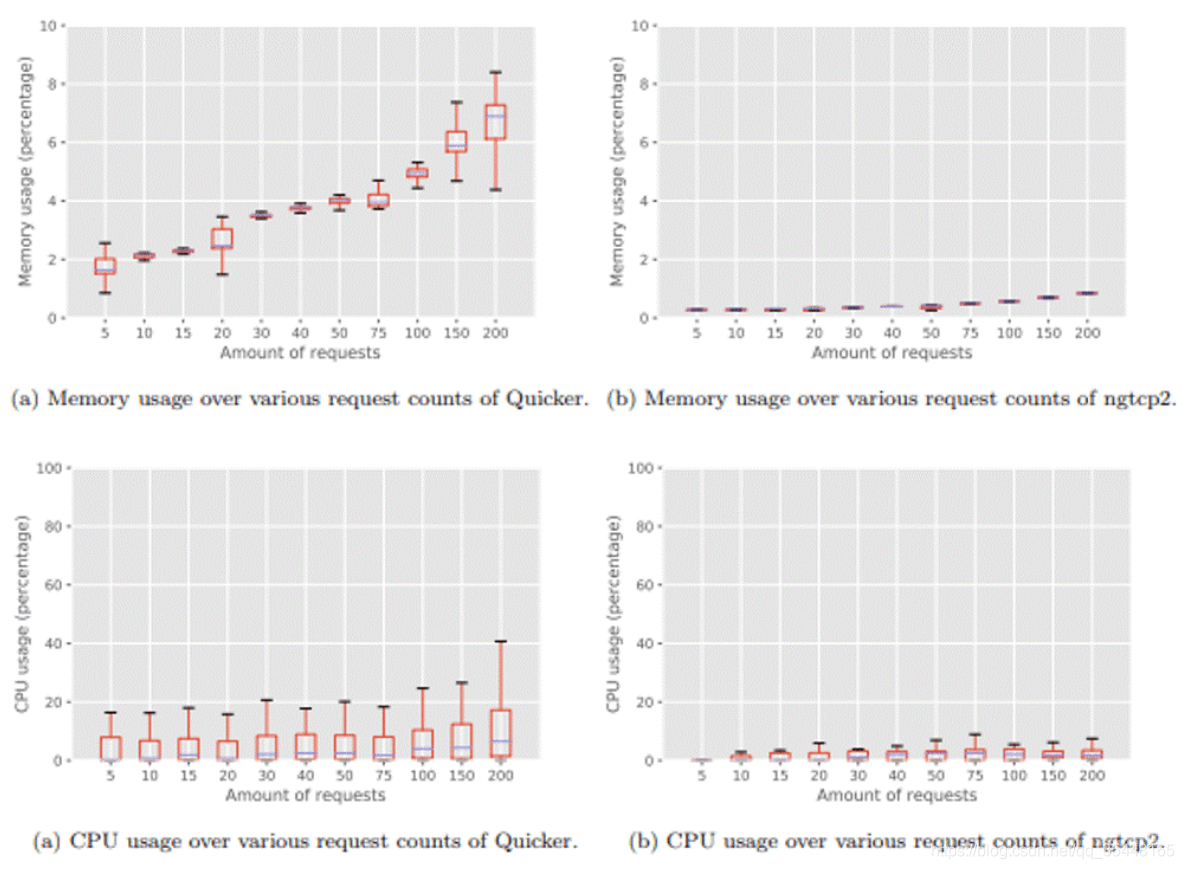
图 4:CPU、内存使用率 Quicker (TypeScript) vs ngtcp2 (C/C++)
反对观点
- QUIC 将在内核/硬件层实现。
- 相较于其他开销,TCP+TLS 连接的开销低得不值一提;即使 QUIC 连接的开销是 TCP+TLS 的 2 倍。
- 现在的测试数据是 Google 版的 QUIC,IETF 版的 QUIC 将与此不同。
- (客户端)硬件将会越来越快。
- QUIC 的开销并没有高到不可控制。
- 即使要花费巨大的投入,Google 仍决定大规模部署 QUIC 。这表明其带来收益大于成本,或许更佳的 web 性能将为其营收带来大幅提升。
- TCP 在物联网领域也占有一席之地。
- “我看过你的 TypeScript 代码,简直就是一团糟。合格的开发者能让 QUIC 运行地更快”
3. 0-RTT 的实际应用
QUIC 的另一主要卖点(实际上是源于 TLS 1.3)是 0-RTT 连接配置:你初始(HTTP)请求可以绑定到第一个握手包上,在第一个回应包就可以得到请求的数据,简直不能再快了!
然而,这有个前提条件:服务器必须是之前通过正常的 1-RTT 连接过的。二次连接的 0-RTT 数据是用首次连接得到的“预共享密钥(pre-shared secret)”加密的。服务器也需要知道该密钥,所以 0-RTT 只能连接同一台服务器,而不是同一个服务器集群。这意味着,负载均衡器要足够智能地将请求路由到正确的服务器。在最初的 QUIC 开发中,Google 测试的正确率是 87%(桌面端)- 67%(移动端)。这一结果相当令人印象深刻,因为他们要求用户保持他们的 IP 地址不变。
此外,还有其他的缺陷:0-RTT 数据包容易受到“重放攻击”,攻击者重复多次发送最初的数据包。由于完整性保护,数据包的内容不会被更改,但是依据数据包内请求的内容不同,重复多次的请求可能会导致一些不希望的行为(e.g., POSTbank.com?addToAccount=1000)。因此,只有叫做“幂等”的数据可以通过 0-RTT 发送。根据应用场景,这将会严重限制 0-RTT 发挥作用(例如,IoT 传感器使用 0-RTT POST 数据,这可不是个好主意)。
最后还存在的问题是 IP 地址欺骗和 UDP 放大攻击。在该场景下,攻击者伪装成受害者的 IP a.b.c.d 然后发送一个 UDP 包给服务器。如果服务器响应返回一个相当大的 UDP 包给 a.b.c.d ,这样,攻击者就以一个相当小的带宽产生了大流量的攻击,见 图 5。为了防止该类攻击,QUIC 加入了两条缓解措施:客户端的第一个数据包必须至少为 1200 字节(实践中最大为 1460);同时,在未收到客户端响应时,服务器响应包不得超过 3 倍的请求包大小。所以只有 3600 - 4380 字节,包括 TLS 握手和 QUIC 开销,只有少量空间留给 HTTP 响应(如果有)。你会发送HTML 吗?header, push 一些东西?这有关系吗?这个确切的问题是我期待深入研究的事情之一。
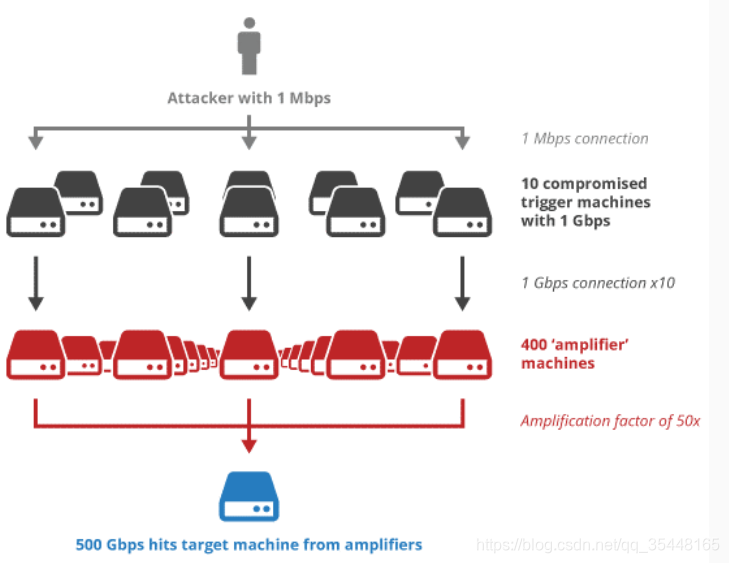
图 5:UDP 放大攻击
对 QUIC 最后致命一击的是 TCP+TLS 1.3 的“Fast Open”选项(不过也存在上述的缺陷)也可以使用 0-RTT 功能。所以 0-RTT 这个功能并不足以让人采用 QUIC 。
反对观点
- HTTP 服务器应该能免疫重放攻击了。
- 阻止重放攻击很容易,只需添加一些内容如时间戳或序列号,因为攻击者无法修改数据包内容。
- 1-RTT 仍比 TCP+TLS 1.2 的 3-4 RTT 好不少。
- 服务端为了性能考虑可以忽略 RFC 中规定的 3600 字节的限制。
- 有证据显示更大的初始拥塞窗口(initial congestion window)并未给 TCP 的 HTTP/2 整体连接带来大提升,所以 QUIC 终端限制或许不会对 HTTP/3 实际应用带来影响
- TCP 的“Fast Open”尚不可用,Mozilla 甚至不打算在 Firefox 支持它。(反对观点:久而久之,对 TCP Fast Open 的支持也会增多)
4.QUIC v3.5.66.6.8.55-Facebook
与 TCP 相对的是,QUIC 集成有完整的版本协商配置,主要是为了在不破坏现有部署的前提下进行版本演进。客户端使用其最支持的版本发送第一握手包。如果服务端不支持该版本,则返还一个协议版本协商包,列出服务端支持的版本。客户端选择其一版本,尝试重新连接。该过程是必要的,因为各版本的编码实现必然会有些差异的。
每一个 RTT 都是多余的
承上所述,每一次版本协商需要额外的 1 RTT 。在有限数量的版本的情况下,这并不存在什么问题。只是,实际情况可能是每年有不止一个正式版本,而是一大批不同的版本。一种可能的情况是,甚至因为某个单一的功能而发布一个新版本(比如前面提到的 轮转位(spin bit))。另外一种情况是,为了让用户体验不同的,非标准化的功能特性。这些都将导致“狂野西部(wild-wild-west)” ,不同部分的人运行略微有点区别的 QUIC ,最终使得版本协商(意味着 1 RTT 开销)的可能性增加。考虑地更全面深入一点,可能一部分人觉得他们自己的 QUIC 版本更好而不愿意更新到新的标准版本.最终,导致了 drop-and-forget 的情况,例如,物联网应用场景里,软件更新频率极低并且严重滞后。
我们可以从参数传输的过程中找到部分的解决思路。这些参数被用来作为握手认证的一部分,同时用来启用/关闭某些功能。例如,QUIC 中有 1 个参数用于表示切换连接迁移支持。然而,目前尚不清楚 QUIC 实际实现是倾向于版本标记还是参数控制。
对于一个以 0-RTT 标榜的传输协议来说,竟然还需要为了 1 个 RTT 的版本协商而大费脑筋,实在是有点自相矛盾。
反对观点
- 浏览器只支持主流的版本,只要服务端也支持,那么就没什么问题。
- 运行他们自己版本的人需要确保客户端和服务端都支持其功能,或者是通过版本协商确定。
- 客户端将会把服务端支持的版本列表缓存下来用于接下来的连接。
- 用于支持独立功能特性的版本可以放在单独的数据库中。如果不支持某个版本,服务端将会智能的不进行版本协商;如果主线功能一致,那么服务端将安全地忽略其他不一致的功能。
- 即使没有版本协商,服务端也总是会将他们支持的版本列表完整的回传。这样,在二次连接时,客户端可以选择其最支持的版本来建立连接。
5.拥塞控制的公平性
QUIC 的端到端加密,版本协商和用户空间实现,为用户提供了前所未见的灵活性。到目前为止,拥塞控制算法(congestion control algorithms (CCAs))都是在内核实现的。你可以选择选择不同的算法,但是,该算法将应用到整个服务器。由此,大多数拥塞控制算法都是通用算法,因为它们需要处理的是各种接入链路。在 QUIC 中,你可以根据某个连接的具体情况选择合适的算法或者至少可以很容易地试用不同的(新的)算法。比如,我想用 NetInfo API 来确定接入链路的类型,并以此来调整拥塞控制算法的参数。
Calimero
上一例子也明确地表明了潜在的危险:如果任何人都可以决定和修改拥塞控制算法(无需重新编译内核),这将会为滥用行为大开方便之门。毕竟,拥塞控制的很重要一部分是使每个连接得到或多或少尽量公平的带宽,这一原则称为“公平性”。如果一些 QUIC 服务器使用更极端的拥塞控制算法,使其连接获得超过公平原则下的带宽,这将会拉低其他非 QUIC 连接和使用不同拥塞控制算法的 QUIC 连接的带宽。
这是极其不合情理的!Google 的 QUIC 支持两种拥塞控制算法:基于 TCP 的 CUBIC 和 BBR。尽管有一些矛盾的信息,但是至少一些信息表明,他们的拥塞算法对普通的“TCP”连接很不公平。一篇研究指出, QUIC+CUBIC 占用 2 倍于 4 条 TCP+CUBIC 连接的带宽。另一篇博客文章显示 TCP+BBR 占用 2/3 的可用带宽,见图 6。这并不是说 Google 恶意降低其他(竞争)连接,却很好地展示了随意修改拥塞控制算法的风险。最糟糕的情况是,这可能导致相互间的“军备竞赛”:大家争相部署实施更加极端的拥塞控制算法或是眼看着自己的网络链路“沉溺”在 QUIC 包的海洋里。
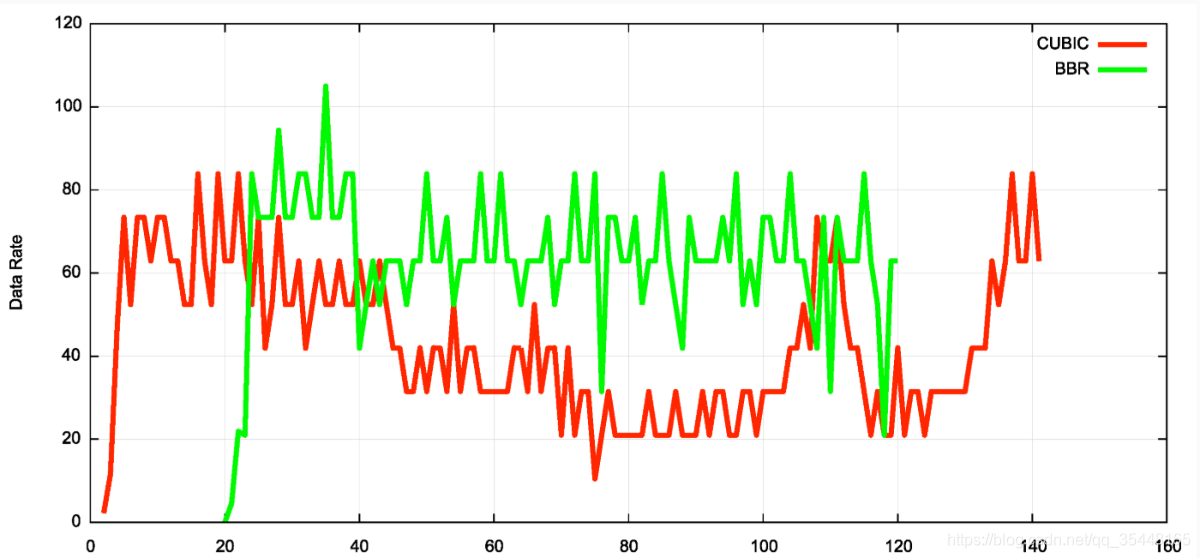
图 6:公平性 BBR vs CUBIC (均为 TCP 网络)
另外一个原因是拥塞算法实现上的(小)错误将会使你的算法表现不理想,拉低你的网络性能。因为所有的东西都得从头开始,我保证类似的问题一定会出现。因为拥塞控制算法调试极其困难,可能要好一段时间才能发现其中的问题。举例来说,Google 在 QUIC 最初的开发中发现了 TCP CUBIC 中一个古老的 bug,修复该 bug 后,TCP 和 QUIC 的性能都得到了大幅提升。
反对观点
- 网络有缓解措施和速率限制等来避免该类滥用。
- 自 TCP 伊始,拥塞控制就存在,这在实际应用中,并没有什么问题。
- 并没有证据表明巨头公司(如 Youtube,Netflix)用该策略来使他们的网络获得优先。
6.“为时过早”也“为时过晚”
QUIC 存在了相当长一段时间了:2012 年起始于 Google 的实验(gQUIC),经过相当正式的部署试验后,于 2015 年通过 IETF 标准(iQUIC),证明它确实是有发展潜力的。尽管经过长达 6 年的设计和开发,QUIC 仍远未达到完备。IETF v1 的最后期限推迟到 2018年11月,现在又推迟到 2019年7月。虽然大多数主要的功能特性已经定下来了,但是实现上的更新迭代却仍在进行。目前,有超过 15 个独立的实现版本,不过传输层的功能特性总共也就那些。由于 gQUIC 与 iQUIC 在底层实现上存在较大差异,目前尚不清楚前者的测试结果是否适用于后者。这也意味着理论上的设计已趋于完结,但是工程实现上仍有未证实的(尽管 Facebook 宣传,他们已在内部网络测试 QUIC+HTTP/3)。这也并不仅仅是一个基于浏览器的实现,虽然 Apple,Microsoft,Google 和 Mozilla 都在进行 IETF QUIC 的实现工作;我们也有一个基于 Chromium 的 POC 项目。
为时过早
这会成为问题,是因为人们对于 QUIC 的兴趣在不断增强,尤其是最近热门的 HTTP-over-QUIC 更名为 HTTP/3 后。人们会希望尽快尝试,有可能使用尚不完善的版本,从而导致低于标准的性能,不完善的安全特性和意料之外的情况等等。他们可能会尝试去调试这些问题,却发现几乎没有什么工具或框架用来调试。大多数现有的工具都是为 TCP 设计的或是压根就未涉及传输层。此外,QUIC 跨越层级的特性使得调试必须跨层(例如,0-RTT 与 HTTP/3 服务器推送结合)和一些复杂的问题(例如,多路传输,前向纠错,新的拥塞控制等等)。在我看来,这是一个广泛的问题,以至于我专门写了一篇文章,请见:文章链接。文章里面,我主张采用一个通用日志格式,以允许创建一组可重用的调试和可视化工具,见图 7。
![07 一个针对 QUIC stream 的可视化工具,用于帮助查看跨资源的带宽分配和流量控制]
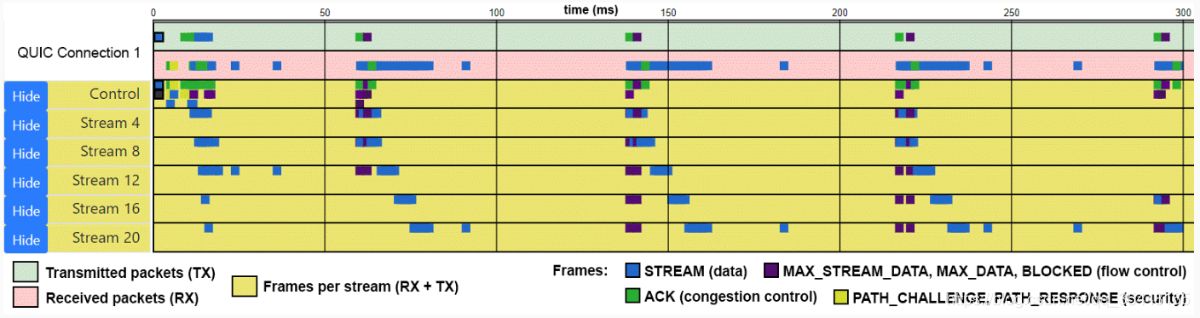
图 7:一个针对 QUIC stream 的可视化工具,用于帮助查看跨资源的带宽分配和流量控制
因此,当人们想开始使用它时,存在 QUIC 尚不完善的风险,使得“幻灭的低谷”提前到来,导致大范围的部署将延迟数年。在我看来,这也可以从 CDN 厂商如何处理 QUIC 中看出:例如,Akamai 决定不再等待 iQUIC,而是在一段时间内测试和部署 gQUIC。LiteSpeed 则对 gQUIC 和 iQUIC 都支持。另一方面,Fastly 和 Cloudflare 只关注 iQUIC。
为时过晚
QUIC v1 来的过早,而 QUIC v2 来的过晚。众多高级功能(一些为 gQUIC 里的),比如前向纠错,多路传输和部分重传等因降低整体复杂度的需要而不纳入该版本。类似的,HTTP/3 的主要更新并没有把 cookie 部分考虑进来。我认为,HTTP/3 只是谨慎地将 HTTP/2 映射到 QUIC 上而已,只有少量的改进。
将 QUIC 和 HTTP/3 这两个概念分开来,是因为 QUIC 是一个通用传输协议,可以承载其他应用层数据。但是,我总是很难为此提出具体的例子… WebRTC 经常被提及,还有一个是 DNS-over-QUIC提案 ,但还有其他项目在进行吗?我想,如果 v1 如果有更多的高级功能,或许会有更多的应用。DNS 提案被推迟到 v2 似乎印证了这一点。
我认为,如果没有这些新型的功能,很难将 QUIC 推销给外行。0-RTT 看起来不错,但可能影响不大,并且也可以用 TCP 实现。低“队头阻塞”只有当你的网络存在大量丢包的情况下才有用。增加安全性和隐私听起来对用户很好,但除了主要原则之外,几乎没有任何附加价值。Google 搜索速度提高了 3-8%:这足以证明额外的服务器和投入的成本得到了回报吗?
反对观点
- 只有当 QUIC 足够稳定,用户使用无明显 bug 时,浏览器才会对它进行支持。
- QUIC 调试工作将由那些自己有工具的专业人士进行。
- HTTP/2 存在不少大问题和漏洞,但是依然广泛应用。
- 即使 QUIC 在头两年未得到大范围应用,但是其价值还在,未来的 30 年我们都将使用 QUIC。
- QUIC v2 很快就会到来,很多工作组在对其各方面特性进行开发。
- QUIC 的灵活性保证了我们可以在应用和传输层快速迭代新功能。
- 外行人会随巨头公司而动。
- A wizard is never late。
结论
如果你看完前面的内容,到这个结论部分,那么恭喜你!坐下,喝一杯!
我想在此刻,读者肯定会有有很多不同的感受(除了疲惫和脱水)以及一些 QUIC 合作者可能会感到愤怒。但是,请记住我在开头所说的内容:这是我以“唱反调”的角度,试图消除当前关于 QUIC 争论中的逻辑错误。大多数(全部?)这些问题都是标准化 QUIC 的人所熟知的,所有的决定都是在(非常)详细的讨论和论证之后做出的。本文中可能有一些错误和不恰当的内容,因为我不是所有子主题的专家(如果你发现了问题,请一定要告诉我)。这也是为什么,QUIC 工作组是由来自不同背景和公司的一群人建立起来的:尽可能多的考虑到各个方面。
话虽如此,我仍然认为 QUIC 可能会失败。但是,几率不会很高,不过确实存在。相反的是,我不认为它一开始就可能取得成功,并立即在大公司之外获得广泛的受众。我认为在一开始未能得到大范围普及的可能性更高,相反,它需要在几年内缓慢地获得广泛的部署份额。这可能会比我们在 HTTP/2 上看到的要慢,但(希望)比 IPv6 的部署更快。
我个人仍然坚信 QUIC(我以我的博士学位打赌)。这是最有可能实际应用的针对传输层的首个建设性的改进方案。我非常感激有机会近距离见证 QUIC 标准化和部署。随着它的发展,我认为它有可能在缓慢的开拓中存活下来,并在接下来的数十年一直保持相当的发展势头。那些大公司将部署、调试、改进、开源 QUIC,并在未来的 5年内,QUIC 的占有率将会逐渐超过 TCP。
转载自:https://bbs.pediy.com/thread-249300.htm
译文作者:看雪翻译小组 StrokMitream
原文链接:https://calendar.perfplanet.com/2018/quic-and-http-3-too-big-to-fail/