在系列文章的前两篇 《图解 Database Bffer Cache 内部原理(一)》、《图解 Database Bffer Cache 内部原理(二)》中,分别对 HASH 链表和检查点队列链表进行了详细介绍,本文将进一步介绍 LRU 队列中的链表。
LRU队列
其实 Buffer Cache 部分,主要就是各种各样的链表,前面已经总结了HASH链表、检查点队列链表。它们一个是用来逻辑读的,一个是用来记录脏块的。另外,还有一个小链表,叫对象链表(OBJ-Q),在写I/O合并算法中有很大作用。
除了这些链表外,还有一个大名鼎鼎的链表,就是 LRU。它又分为 LRU 和 LRUW ,它们分别包含主、辅两个链表。
也就是说,一组 LRU 包含 4 个链表:主 LRU 、辅助 LRU 、主 LRUW 和辅助 LRUW 。
其中主 LRU、辅助 LRU 用于在 Buffer Cache 中寻找可覆盖的 Buffer 块。主 LRUW、辅助 LRUW 的作用和检查点队列有点冲突,因为它们也是 DBWR 用于写脏块的。其实不能说是冲突,而应该说它们和检查点队列相辅相成,共同完成写脏块机制。
1 )主 LRU、辅助 LRU 链表
先来介绍一下 LRU 链表的作用。物理读时,服务器进程要将数据块从数据文件读进 Buffer Cache 中。假设 Buffer Cache 有 10000 个 Buffer ,那么,进程应覆盖哪个 Buffer 呢?简单点说,就是进程将数据块读进 Buffer Cache 的什么地方。
答案是,哪个 Buffer 最不常用,它就会被当作牺牲者,也就是说,会覆盖掉它。
覆盖最不常用的 Buffer,这是所有 LRU 算法的本质。可如何快速找到这个最不常用的 Buffer 呢?这就是 LRU 需要解决的问题了。
LRU 会将 Buffer Cache 中所有的 Buffer 都链接在一起。LRU 又分两条链表,主 LRU 链表和辅助 LRU 链表。其中,主 LRU 又有冷端、热端两部分。同时,每个 Buffer 有一个访问计数 TCH 。TCH 以 3 秒为一个阶段,每个阶段只要有进程访问,它的数值就会加 1 。如果 3 秒之内访问了多次,也只会加 1。 Buffer 是在冷端还是在热端,主要靠这个 TCH 了。

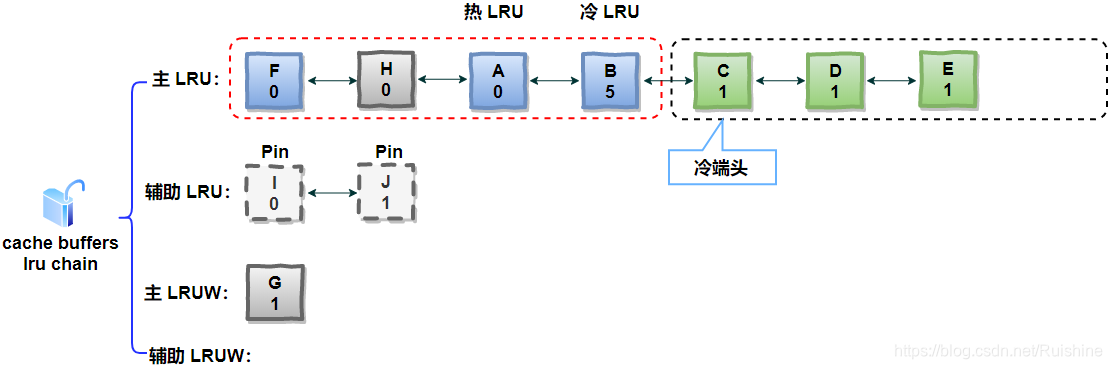
下面仍用图来逐渐揭开 LRU 的面纱,如图 47 所示。

Oracle 内存中的任何链表,都会有专门的 Latch 保护它。一组 LRU 链表,包括主 LRU、辅助 LRU,还有主 LRUW、辅助 LRUW,它们称为一个 WorkSet(工作组),用一个 Latch保护:cache buffers lru chain 。
在图 47 中字母下面的数字即为 TCH 。可以看到,图中的 LRU 链里,每个 Node 都指向 Buffer Cache 中的某个 Buffer 。为了不至于让图看起来太乱,链表指向 Buffer 的箭头只画了 3 个。
在图 47 中有 6 个 Buffer 的为主 LRU 链表,有两个 Buffer 的是辅助 LRU 。一般情况下,辅助 LRU 会占 LRU 中 Buffer 总数量的 5%,剩下的 75% 会在主 LRU 中。
另外,还有一点需要注意,主 LRU 又分成两部分,冷端、热端。在图 47 中,Buffer Cache 一共有 9 个 Buffer,主、辅 LRU 链表中共有 8 个Node。关于这点再额外说明下,Buffer Cache 中所有的 Buffer 都会在 LRU 中,但不一定都在主、辅 LRU 中,因为还有 LRUW 。
下面,再来看看物理读时访问 LRU 链表的情况,如图 48 所示。

在图 48 中,服务器进程要物理读 5 号文件 80 号块。当然,进程会先搜索 HASH 表,假设搜索结果没有找到,5 号文件 80 号块不在 Buffer Cache 中,进程就要发起物理读了,将其读进 Buffer Cache 。
物理读的第一步,先获得 cache buffers lru chain latch,然后进程从辅助 LRU 的尾端搜索可以覆盖的 Buffer 。
可以覆盖的标准就是:一不是脏块,二 TCH 值小于 2 。在图 48 中,服务器进程找到的 Buffer 是 H 。它的 TCH 是1。TCH 为 1 说明它曾在某个 3 秒中有若干次访问。接下来看图 49 。

在图 49 中,辅助 LRU 尾端的 H 可以覆盖,它会被从辅助链表移到主 LRU 的冷端头。最终的图形如图 50 所示。

现在,辅助 LRU 中只剩一个块了。H 被移到了冷端头。然后,cache buffers lruchain latch 被释放。LRU 链相关操作完成后,进程将实际地发起一次物理读,从而将 5 号文件 80 号块读进 Buffer Cache 中。
从图 49 和图 50 中,可以得到以下 3 点信息:
- 进程从辅助链表尾开始搜索 LRU。
- 找到可覆盖的 Buffer 后,会将它移到主 LRU 的冷端头。
- 主辅 LRU 链长度的比例,并不一定是主 LRU 占75%、辅助 LRU 占25%。
辅助 LRU 也有可能为空,如果再发生一次物理读,G 对应的 Buffer 会被覆盖,G 也会被移到主 LRU 上。LRU 链表可能会变成,如图 51 所示形式。

可以看到,G 也被移到了主 LRU 的冷端头,辅助 LRU 为空了。当物理读繁忙时,这种情况是有可能出现的。由于辅助 LRU 已经没有 Buffer 了,如果这个时候再发生物理读,将从哪里开始搜索可用块呢?答案是主 LRU 冷端尾,也就是图 51 中的 F 处。但前文提到过,有两种块是不能覆盖的,脏块和 TCH 大于等 2 的。在该图中,F 的 TCH 值为 3,也就是说,它不能被覆盖,它会被移到 LRU 热端头,如图 52 所示。

同时,F 的 TCH 值会被清零。这样一来,原来热端尾最后一个 Buffer 是 C ,现在它被挤到冷端头了。然后,继续从冷端尾向头部扫描。F 已经被移到了热端头,冷端尾最后一个块是 E 了。假设它是个脏块,脏块也是不能被覆盖的,如图 53 所示。

E 不可覆盖,进程会跳过 E(其实 E 会被放入 LRUW 链表,关于这块内容,后面有详细描述,此处可以先简单地理解为跳过),继续向头的方向扫描。下一个就是 D 块,它将是本次的“牺牲者”,如图 54 所示。

D 会被移到冷端头,插在 C 之前。最终结果如图 55 所示。

D 对应的 Buffer 会被新的物理读覆盖,因此 D 又被称为“牺牲者”。LRU 的规则就是选择牺牲者的规则。
如果再有物理读,被覆盖的 Buffer 将依次是 H、G、C、D,然后又是 H、G、C、D……循环往复。但是 LRU 热端的 F、A、B 不会被使用,只会循环使用冷端的 Buffer,如图 56 所示。

对上述内容总结如下:
- 进程从辅助 LRU 链表尾开始搜索牺牲者。
- 如果辅助 LRU 链表为空,或者辅助 LRU 链上没有可用块(都是脏块),将从主 LRU 冷端尾开始搜索牺牲者。
- 找到可覆盖的牺牲者后,将它移到主 LRU 的冷端头。它对应的 Buffer 被新的物理读覆盖。
- 脏块会被跳过。
- 在进程搜索 LRU 时,遇到 TCH 大于等于 2 的 Buffer,则将其移到热端头。
现在,还有两个问题需要找到答案:辅助 LRU 一直为空吗?脏块 E 如何处理?
先来回答第一个问题,辅助 LRU 一直为空吗?答案是:当然不会了。
SMON 进程和 CKPT、DBWR、LGWR、PMON 一样,都是 3 秒醒来一次。SMON 每次醒来都会申请获得 cache buffers lru chain latch,然后检查主、辅 LRU 链表的长度,如果辅助 LRU 中 Buffer 数量少于 25%,SMON 会从主 LRU 冷端尾搜索 TCH 小于 2 的非脏块,将其移动到辅助 LRU 中,保持辅助 LRU Buffer 数 25% 的比例。
所以,在大部分系统中,辅助 LRU Buffer 数都可以保持在 25% 左右,对于一个物理读特别繁忙的系统,此百分比可能会低些。但像图中所画的辅助 LRU 链为空的情况,还是很少出现的。
Oracle 中 LRU 链分为主、辅两条的目的,是为了加快搜索 LRU 链表的速度。在主 LRU 中,鱼龙混杂,什么 Buffer 都有,脏的、TCH 大于等于 2 的。而 SMON进程每 3 秒一次,将主 LRU 中非脏、TCH 小于 2 的可覆盖 Buffer,移到辅助 LRU。进程从辅助 LRU 开始寻找牺牲者,无疑会加快查找速度。
说点题外话。曾看到过一篇文章,写的是在一条街上,有两家卖早餐的,都卖油条、豆浆。其中一家每天总能比另一家多几十名顾客。其实原因很简单,早餐是有很强时间限制的生意,在上班前后的一段时间里,人会很多,而店里的位置有限,老的顾客没吃完,新的顾客一看没位置就不会来了。而豆浆比较热,顾客喝得比较慢,离开得自然也比较慢。但是卖得好的那一家总是抽空盛好几碗放在那里凉着,顾客一来,马上端上。由于温度不是太烫,客人喝得比较快,离开得自然也较快。所以,同样是在早餐繁忙的时刻,该店总能比另一家多接待几十名顾客。
Oracle 也采用了相同的策略,SMON 会抽空在辅助 LRU 上准备好一些可以覆盖的牺牲者,以便让服务器进程可以更快地在 LRU 中找到牺牲者,缩短进程搜索 LRU 的时间,减少 cache buffers lru chain latch 的持有时间。
另外,数据库刚启动的时候,或是刚刚 Flush 过 Buffer Cache,所有的 Buffer 都会在辅助 LRU 中。
大家知道,物理读时服务器进程会先扫描辅助 LRU,将找到的可牺牲 Buffer 移到主 LRU 冷端头再覆盖。因此,当数据库正常运转时,辅助 LRU 中的 Buffer 数将不断减少,因为不断有物理读,所以 Buffer 会不断地被移到主 LRU 上,主 LRU 的长度会不断增长。而 SMON 进程会在辅助 LRU 的 Buffer 数少于总 Buffer 数的 25% 时,将主 LRU 中的 Buffer 移到辅助 LRU。
但并不是所有的物理读都按先辅助 LRU、再主 LRU 这样的顺序查找牺牲者,比如,大表全表扫描操作就是例外。
Oracle 将全表扫描分为大表扫描和小表扫描,有一个隐藏参数可用来设置区分是大表扫描还是小表扫描,即_small_table_threshold,其单位是块数。表的块数低于此参数的值,就算小表,否则就是大表。该参数的默认值是 Buffer Cache 总 Buffer 数的 2%。
如果是小表,全扫描与索引扫描等普通扫描是一样的。如果是大表,全表扫描时 Oracle 会额外处理。在这个过程中,有以下两点需要注意:
- 物理读的块,不会进入主 LRU,只会使用辅助 LRU 的空间。
- 块的 TCH 值为 0。
另外还需注意,大表的全表扫描在 11gR2 后将自动使用直接路径读,不再进入 Buffer Cache 。
2 )脏链表 LRUW
LRUW 也是存放脏块的,从作用上说,它和检查点队列有点重复,它们都是放脏块的。但实际上,它们两个相辅相成,共同构成了 Oracle 的脏块刷新机制。
之前已经详细描述了检查点队列,了解了检查点队列,但那还只能算是对写脏块机制有了一半的认识,另一半是 LRUW 。
与检查点队列不同,块在变脏时,并不会立即进入 LRUW 链表,而是要等到进程搜索到可覆盖的牺牲者(发现 TCH 值小于 2 的脏块)时,这些脏块才会被移到 LRUW 中。如图 57 所示。

在图 57 中,假设辅助 LRU 中的两个 Buffer 都正在被其他进程 Pin 着,被 Pin 的 Buffer 是不会被覆盖的。某个进程扫描 LRU 寻找可覆盖 Buffer 的时候,只能从主 LRU 的冷端尾开始了。现在主 LRU 冷端尾有两个脏块:G、H,G 的 TCH 为 1,H 的 TCH 为 2。TCH 超过 2 的脏块,和 TCH 超过 2 的普通块一样,会被扫描 LRU 的进程移到主 LRU 的热端头,TCH 值清零。TCH 小于 2 的脏块,会被移到主 LRUW 链表。
在图 58 中,脏块 H 会被移到主 LRU 热端头,同时 TCH 值清零,但它还是脏块。对于这些 TCH 值比较高的热脏块,Oracle 并不急于写它们,因为既然它们比较热,说不定很快又要被修改。所以先不写,还是按照增量检查点的机制,按检查点队列的顺序写它们。

脏块 G 的 TCH 值为 1,不是热块,它被移到了 LRUW 处。
另外,为了避免和前面的内容混淆,接着把“某进程搜索可牺牲 Buffer ”的过程图画完。在上面那幅图中,进程将两个脏块移到了其他地方。继续搜索,Buffer F 的 TCH 值为 3,会被移到热端头。Buffer C 会被从热端尾最后一个 Buffer,挤到冷端头。Buffer E 的值 TCH 值为 1,小于 2,它将是这次的牺牲者,最终的图如图 59 所示。
当有脏块进入主 LRUW 链表时,并不会马上被写磁盘,DBWR 进程每 3 秒会醒来。下次当 DBWR 醒来后,它会将脏块移到辅助 LRUW 处,从辅助 LRUW 写磁盘。
假设如图 59 中的情况出现了,LRUW 中只有一个脏块,DBWR 会写脏块吗?是不是必须等到 LRUW 中的脏块数积累到一定数量才会写?答案是,有一个脏块就会写。当 DBWR 醒来后,不管 LRUW 中有多少脏块,都会把它们写到磁盘。
继续描述脏块的写过程,如图 60 所示。

脏块 G 从主 LRUW 中移到辅助 LRUW 中,然后写磁盘。
当要写的脏块有多个时,在被移到辅助 LRUW 后,DBWR 当然也会对它们进行合并—将相邻的脏块合并为一个大脏块,然后写磁盘。这样虽然没有减少写的 I/O 块数,但可以减少 I/O 次数。这里的合并算法和前文所述的从检查点写脏块时的合并算法一样,不再重述。
还要说明一点,由于所有的脏块都在检查点队列中,从 LRUW 写的脏块,当写完成时,要从检查点队列中去掉。最终的效果如图 61 所示。

脏块 G 现在已经不是脏块了,注意,它并不会从 Buffer Cache 中清除。写脏块并不是清除操作。如果脏块是从 LRUW 中写的,在其写完后,会被移到辅助 LRU 的尾端,等待被覆盖。所以,上图还不是写完成后的最终效果,真正最终效果如图 62 所示。

脏块G被处理的流程总结如下:
- 第 1 步:它被前台进程(服务器进程)从主 LRU 链表移到主 LRUW 链表。
- 第 2 步:一旦 LRUW 有脏块,DBWR 3 秒后醒来,发现 LRUW 中有脏块,它会将脏块从主 LRUW 移到辅助 LRUW。
- 第 3 步:脏块被写磁盘。
- 第 4 步:写磁盘完成后,脏块被从检查点队列中去除。
- 第 5 步:写完成的脏块已经不脏了,它被放入辅助 LRU 链表尾端,等待被下次物理读或 CR 块相关操作覆盖。
摘自:书籍《Oracle 内核技术揭密》