链接:https://arxiv.org/abs/1802.00124
background
pruning是一种广泛使用的模型压缩方法,它不仅有利于减少计算消耗,也可能有助于避免模型训练过拟合。
related work and the limit
目前,很大一部分剪枝的工作基于“smaller-norm-less-informative”的假设来实现。但该假设在有的时候并不一定成立(“regularization-based pruning techniques potentially hurting them being widely applicable, especially for those that regularize high-dimensional tensor parameters or use magnitude-based pruning methods”)。
有一些类似的工作,如Huang & Wang (2017) 使用一个额外的缩放因子来进行实现。Slimming和我们一样借助BN层的scale因子实现模型的稀疏化,但它并未证明其方法在大的预训练模型上的有效性。不同于这两种方法,我们基于ISTA和一种rescale trick提出了一种新的方法。
novel points
本文首先对于“smaller-norm-less-informative”进行了研究,该假设认为,删除那些系数较小的feature不会产生较大的误差。因此使用易处理的范数对模型优化中的参数进行正则化,并通过比较训练后的范数大小挑选那些“重要”的参数。但该假设的成立是有条件限制的。首先,使用Lasso回归或岭回归来选择线性回归中的重要预测变量,首先需要将每个变量进行标准化,否则结果将无法解释。对于非凸优化,通常很难满足正则化操作的归一化条件。文中举出了种情况证明了正则化的失败或使用受限:
1、 对于不同层之间进行细粒度的正则化操作,很难实现统一的归一化。一般需要实现复杂的层间统一惩罚项或着采用重参数化的方法。
2、 卷积权重正则化有时与BN不兼容。
因此本文提出,不再使用简单的权重参数正则化,而是借用BN的γ参数来实现,有两个重要原因:
1、 γ都是与归一化的输入相乘,因此通过测量γ的大小,整个网络的通道重要性在不同层之间可以实现比较;
2、 连续的卷积层都进行BN操作,则可以避免不同层的重参数化效果,或者说,γ参数比例变化的影响在不同层之间是独立的。(???有没有证明)
methodology
该部分受限证明了输出为constant的通道,裁剪其并不会带来误差,文中提出了一种使用ISTA的限制来驱使网络训练,使得部分γ向着0的方向学习。具体的算法操作比Slimming中较复杂,未进行详细地研究。



evaluation(benchmark, experiments design)
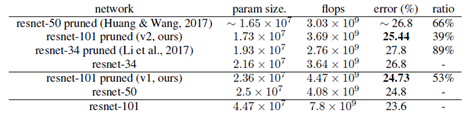
基于Cifar-10,ImageNet和实例分割的数据集上进行了实验,文章是早期的工作,因此效果在目前来看已经不属于第一梯队,主要关注ImageNet上的结果如下:
Thoughts:
1、 is this problem very meaningful? is the idea interesting and inspired?
smaller-norm-less-information是很多剪枝工作中的一个公认假设,本文对其进行研究,是很有意义的。提出的基于ISTA的方法,目前看来使用频率其实低于Slimming中提出的直接对γ的L1-Norm进行衡量及稀疏化的方法。
2、 does the paper clearly explained the considerations and implement?
算法部分还需要对照代码来理解
3、 what’s the tradeoff?
只能对带BN的网络进行,不过BN基本已经广泛使用。
4、 other consideration.
a. 文中提到“连续的卷积层都进行BN操作,则可以避免不同层的重参数化效果,或者说,γ参数比例变化的影响在不同层之间是独立的”,如何证明?
按照本文中的论证,如何来证明Slimming中方法的普适性