题目:Modularized Transfomer-based Ranking Framework
代码: https://github.com/luyug/MORES
贡献:
在这项工作中作者们将 Transformer ranker 模块化为单独的模块,以进行文本表示和交互。作者将展示该设计如何使用离线预计算表示和轻量级在线交互来显着加快排名。模块化设计也更易于解释,并为 Transformer 排名中的排名过程提供了启示。作者在大型监督排名数据集上的实验证明了 MORES 的有效性和效率。它与最先进的 BERT 排名器一样有效,并且排名速度最高可提高 120 倍。–paperweekly
INTRODUCTION
当用于排序时,Transformer Ranker采用查询和文档的连接,应用一系列self-attention操作,并从其最后一层输出相关性预测。(可解释性较差)
Proposed Method(MORES)

对于文档和查询,采用Transformer的encoder编码:

表示层
Document Representation Module(M层encoder)
Query Representation Module(N层encoder)
取最后一层的隐藏状态作为表示模型的输出(hidde_size=n):
1.文档(token长度为d):
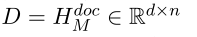
2.查询(token长度为q):
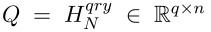
交互层
使用表示层的输出Q和D,做相关性判别(cross-attention :(Attend(Q,D))multi-head attention:(Attend(Q,Q)。LN:层归一化(layer norm))。具体的:
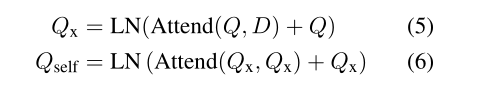
公式(5)对从查询token到文档token的交互进行建模。然后将结果做self-attention收集和交换查询token之间的信号。接着做LN,第一层交互的输出(FFN:前馈神经网络):
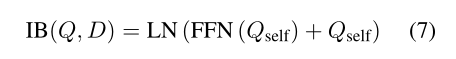
使用多个交互层来迭代地重复这个过程并细化查询token表示,对多轮交互进行建模,产生一系列隐藏状态,同时保持文档表示D不变,
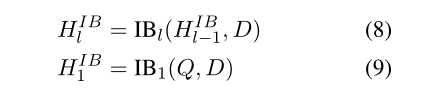
取最后一个交互层的[CLS]嵌入表示做一个线性变换得到排名分数:
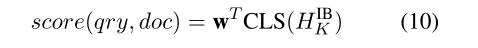
MORES Training and Initialization
1.pointwise loss function
2.引入BERT权重辅助初始化,使用BERT权重初始化文档表示模块(24layer bert)。分割另一份权重为查询表示模块(前12层)和交互模块(后12层)。
Setup
1.训练 :MS MARCO
data:ClueWeb09-B 和Robust04
2.任务:re-rank BM25检索的1000文档
train MORES on a 2M subset of Marco’s training set.
3.SGD
4.batch_size :128
5.AdamW优化
6.learningrate :3e-5
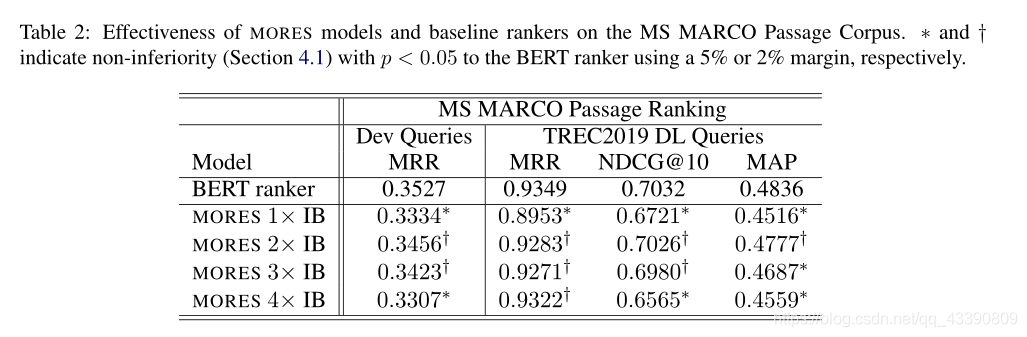
结果
和BERT差不多,效率更快