
Learning to Match Using Local and Distributed Representations of Text for Web Search
摘要
DUET由两个独立的深度神经网络组成,一个使用局部表示匹配查询和文档,另一个使用学习的分布式表示匹配查询和文档。这两个网络作为单个神经网络的一部分被联合训练。
Motivation

local 模型进行精确匹配,分布式模型进行 同义词,相关术语或者语义匹配。
讨论
作者提出三个高效IR的属性
- exact match :这是IR的基础
- match positions :相关文档中的查询词匹配比非相关文档中的匹配更具聚类性。

- inexact term matches:解决词汇不匹配问题,exact match 的致命问题是忽略了query的相关词,比如对于query :Australia , 会忽略Sydney’ and ‘koala’ 。这对于IR来说绝对不是一个好的策略
DUET将上述三个高效的IR属性结合:
3.DUET
分布式模型在匹配之前将查询和文档文本投影到嵌入空间中,而本地模型在交互矩阵上操作,将每个查询项与每个文档项进行比较。最终分数是来自本地和分布式网络的分数之和
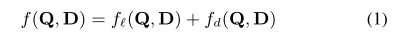
其中查询和文档都被认为是术语的有序列表
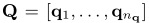
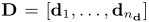
input的fixed:quert:10 ,doc:1000
3.1 Local Model
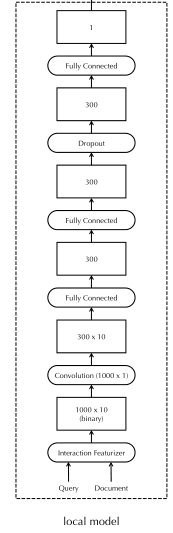
query 和 document 的term用one-hot表示,然后计算exact match矩阵:
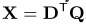
X X X ∈ ∈ ∈ R R R n ^n n d ^d d × ^× × n ^n n q ^q q (1000×10), 捕获查询和文档的每一个exact match
和 match positions。其中:

然后将矩阵 X X X经过一个kenel为 n d n_d nd×1(1000×1),步长为1的300个feature maps 的卷积活得3000×10的一个矩阵,然后经过两个全连接层,一个dropout层,再经过最后一个全连接层产生一个单独的实值输出,这些层的所有激活函数都为tanh。
3.2 Distributed Model


这里的输入不再是one-hot计算match矩阵,而是和DSSM一样的n-graph嵌入(现在选择Glove或者EMLo会更好),维度为2000,即对于query:2000×10,文档:2000×1000
然后经过300个kenel大小为2000×3,步长为1的卷积,query生成300×8的features,document生成300×998的features。
接着进行max-pooling,query(1×8):输出维度300,document(1×100):输出维度300×899.注意:doc的max-pooling选择的是窗口max-pooling而不是CDSSM中的全局max-pooling,是因为基于窗口的方法允许模型区分文档不同部分中的匹配项。当处理长文档,尤其是包含许多不同主题的混合文档时,知道匹配位置的模型可能更适合。
query的max-pooling输出经过一个全连接层(维度:300),对于doc的max-pooling的输出(300×899)仍然经过一个卷积处理(滤波器大小为300,kenel为300×1,步长为1,输出为300×899)。这些卷积层和最大池层的结合使分布式模型能够学习合适的文本表示,以实现有效的不精确匹配。
为了执行匹配,对query和doc的输出执行Hadamard积(输出维度:300×899):
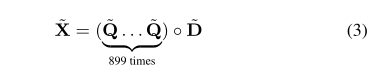
3.3 Optimization
每一组训练样本由一个查询 Q Q Q,一个相关文档 D ∗ D^* D∗和一组不相关文档 N N N ={
D 1 D_1 D1,…, D N D_N DN} 组成。使用softmax函数根据分数计算给定查询的肯定文档的后验概率,然后最大化 l l l o o o g g g p p p即可:

实验
dataset:

结果


3 The updated Duet model(用于MS MARCO PASSAGES RANKING)
word embeddings
用GloVe取代n-graph嵌入
Inverse document frequency weighting
将查询和文档的exact match 矩阵改变为TF-IDF:
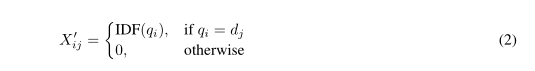

其中, N N N是集合中的总passgaes数, n t n_t nt是术语 t t t至少出现一次的passgae数。
Non-linear combination of local and distributed models
与DUET不同(将local 和 分布式模型的得分简单相加),这里采用的是用一个MLP去组合local 和 分布式模型的得分生成相关性估计。
Rectifier Linear Units (ReLU)
用ReLU代替DUET中的tanh
Bagging
使用bagging通过组合多个Duet模型——用不同的随机种子和不同的随机样本训练数据。得到了一些改进。
4 Experiments
与DUET同样的三元组训练,loss为交叉熵
结果
