今天在查询mysql表连接的时候发现一篇对join深度解析的文章感觉很不错,讲解的很到位,放在这里给大家分享一下。
join简介
多表联合查询,有内连接,外连接,右连接,左连接,自然连接。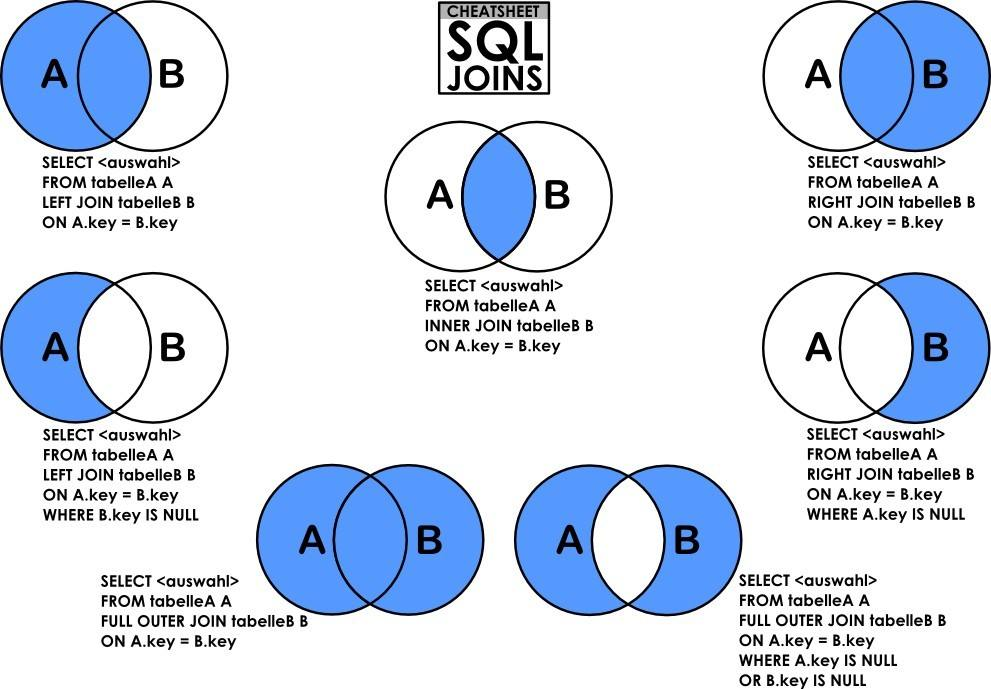
笛卡尔积CROSS JOIN
笛卡尔积就是将A表的每一条记录与B表的每一条记录强行拼在一起。所以,如果A表有n条记录,B表有m条记录,笛卡尔积产生的结果就会产生n*m条记录。
内连接INNER JOIN
有INNER JOIN,WHERE(等值连接),STRAIGHT_JOIN,JOIN(省略INNER)四种写法。
内连接是最常用的连接操作。从数学角度讲就是求两个表的交集,从笛卡尔积的角度将就是从笛卡尔积中挑出ON字句成立的记录。
左连接LEFT JOIN
两个表的交集外加左表剩下的数据。从笛卡尔积角度讲就是先从笛卡尔积挑出ON子句条件成立的记录,然后再加上左表剩余记录。
右连接RIGHT JOIN
两个表的交集外加右表剩下的数据。从笛卡尔积角度讲就是先从笛卡尔积挑出ON子句条件成立的记录,然后再加上右表剩余记录。
外连接OUTER JOIN
外连接就是求两个集合的并集。从笛卡尔积角度讲就是从笛卡尔积中挑出ON子句条件成立的记录,然后加上左表中剩余的记录,最后加上右表中的剩余记录。
MYSQL不支持OUTER JOIN,但是可以对左连接和右连接的结果进行UNION操作来实现。
USING子句
当模式设计对联接表的列采用了相同的命名样式时,就可以使用 USING 语法来简化 ON 语法,格式为:USING(column_name)。
自然连接NATURE JOIN
自然连接就是USING子句的简化版,它找出两个表中相同的列作为连接条件进行连接。有左自然连接,右自然连接和普通自然连接之分。
join原理
NLJ(Nested Loop Join, 嵌套循环算法)
table1驱动表,table2被驱动表。驱动表会驱动被驱动表进行连接操作。
- 加载驱动表,从驱动表找到第一条记录。
- 加载被驱动表,从头扫描被驱动表,逐一查找与驱动表第一条记录匹配的记录然后连接起来形成结果表中的一条记。
- 被驱动表查找完后,从驱动表中取出第二个记录。然后,再次加载被驱动表, 从头扫描被驱动表,逐一查找与驱动表第二条记录匹配的记录,连接起来形成结果表中的一条记录。
- 重复上述操作,直到驱动表的全部记录都处理完毕为止。 这就是嵌套循环连接算法的基本思想。 一次只将一行传入内层循环, 所以外层循环(的结果集)有多少行, 内存循环便要执行多少次。
表t1,t2,t3连接类型:
Table Join Type
t1 range
t2 ref
t3 ALL
实际处理:
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}
BNLJ(Block Nested Loop Join, 块嵌套循环算法)算法
对NLJ的优化。大致思想就是建立一个缓存区,一次从驱动表中取多条记录。
将外层循环的行/结果集存入join buffer, 内层循环的每一行与整个buffer中的记录做比较,从而减少内层循环的次数。
实际处理:
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer
if buffer is full {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
empty join buffer
}
}
}
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
}
外层table100行示例:
外层循环的结果集是100行,使用NLJ 算法需要扫描内部表100次。
如果使用BNL算法,先把对Outer Loop表(外部表)每次读取的10行记录放到join buffer(根据join_buffer_size的大小),然后在InnerLoop表(内部表)中直接匹配这10行数据,内存循环就可以一次与这10行进行比较, 这样只需要比较10次,对内部表的扫描减少了9/10。
所以BNL算法就能够显著减少内层循环表扫描的次数。
MySQL使用Join Buffer有以下要点:
- join_buffer_size变量决定buffer大小。
- 只有在join类型为all, index, range的时候才可以使用join buffer。
- 能够被buffer的每一个join都会分配一个buffer, 也就是说一个query最终可能会使用多个join buffer。
- 第一个nonconst table不会分配join buffer, 即便其扫描类型是all或者index。
- 在join之前就会分配join buffer, 在query执行完毕即释放。
- join buffer中只会保存参与join的列, 并非整个数据行。
使用
5.6版本及以后,优化器管理参数optimizer_switch中中的block_nested_loop参数控制着BNL是否被用于优化器。默认条件下是开启,若果设置为off,优化器在选择 join方式的时候会选择NLJ算法。
设置开启或关闭:SET SESSION optimizer_switch ='block_nested_loop=off';
影响性能因素
内循环次数
假设table1有100条记录,table2有10000条记录。
指令执行次数都是100*10000次。
table1驱动table2 : table1 加载 1次,table2加载100次。
table2驱动table1 : table1 加载10000次, table2加载1次。
所以,table1驱动table2效率要高。
小表驱动大表能够减少内循环次数,从而提高连接效率。
快速匹配
扫描被驱动表寻找合适的记录可以看作一个查询操作。在被驱动表建索引可以提高查询效率。
排序
对驱动表排序将先对驱动表排序后执行表连接算法。对被驱动表排序,是执行表连接后对结果集进行排序。
所以,优先选择驱动表的属性进行排序。
JOIN优化内循环次数
内循环的次数受驱动表的记录数所影响,驱动表记录数越多,内循环就越多,连接效率就越低,所以尽量用小表驱动大表。
左连接中,左表是驱动表,右表是被驱动表。
右连接中,右表是驱动表,左表是被驱动表。
但是内连接是不同,根据嵌套循环算法的思想,table1内连接table2和table2内连接table1所得结果集是相同的。
STRAIGHT_JOIN强制左表连接右表。
MYSQL自带的Optimizer会优化内连接,优化策略就是上面讲的小表驱动大表。
JOIN优化快速匹配
两张表的JOIN操作就是不断从驱动表中取出记录,然后查找出被驱动表中与之匹配的记录并连接。这个过程的实质就是查询操作,想要优化查询操作,建索引是最常用的方式。
左连接LEFT JOIN
左连接中,左表是驱动表,右表是被驱动表。想要快速查找被驱动表中匹配的记录,所以我们在右表建索引,从而提高连接性能。
右连接RIGHT JOIN
右连接中,右表是驱动表,左表是被驱动表。想要快速查找被驱动表中匹配的记录,所以我们在左 表建索引,从而提高连接性能。
内连接INNER JOIN
MySQL Optimizer会对内连接做优化,不管谁内连接谁,都是用小表驱动大表,所以如果要优化内连接,可以在大表上建立索引,以提高连接性能。
另外注意一点,在小表上建立索引时,MySQL Optimizer会认为用大表驱动小表效率更快,转而用大表驱动小表。
多表连接
上面都是两表连接,多表连接也是一样的,找出驱动表和被驱动表,在被驱动表上建立索引,即可提高连接性能。
总之,想要从快速匹配的角度优化JOIN,首先就是找出谁是驱动表,谁是被驱动表,然后在被驱动表上建立索引即可。
JOIN优化排序
排序分为:对连接属性排序和对非连接属性排序
对连接属性排序
当对连接属性进行排序时,应当选择驱动表的属性作为排序表中的条件。
实例:table1是大表,table2是小表,table1和table2内连接,连接条件table1.id = table2.id,对连接属性id进行排序。
table1是大表,table2是小表。所以,table2是驱动表,table1是被驱动表。
方式一:ORDER BY table1.id
执行表连接算法后,对结果集进行排序,效率低下。
方式二:ORDER BY table2.id
先对table2进行排序,然后执行表连接算法。效率高。
对非连接属性排序
因为MySQL Optimizer会按照“小表驱动大表的策略”进行优化。当对大表非连接属性排序时,考虑用STRAIGHT_JOIN,使大表驱动小表。
实例:table1是大表,table2是小表,table1和table2内连接,连接条件table1.id = table2.id,对非连接属性table1的字段type进行排序。
实际运行结果:MySQL Optimizer会用table2驱动table1。现在我们要对table1的type属性进行排序,table1是被驱动表,必然导致对连接后结果集进行排序Using temporary(比Using filesort更严重)。 所以我们用STRAIGHT_JOIN,使大表table1驱动小表table2。
这篇文章的作者其他的文章写的也很好,值得借鉴,大家有兴趣的可以访问他的博客,在文章的最下面是mysql的其他方面的教程。
本篇博客是转载于http://www.apeit.cn/mysql-join-x167q,再次感谢博主的分享