参考:
介绍
join 用于多表中字段之间的联系。
... FROM table1 INNER|LEFT|RIGHT JOIN table2 ON conditiontable1:左表;table2:右表;
JOIN 按照功能大致分为如下三类:
- INNER JOIN(内连接,或等值连接):取得两个表中存在连接匹配关系的记录。
- LEFT JOIN(左连接):取得左表(table1)完全记录,即是右表(table2)并无对应匹配记录。
- RIGHT JOIN(右连接):与 LEFT JOIN 相反,取得右表(table2)完全记录,即是左表(table1)并无匹配对应记录。
注意
MySQL 不支持Full join,不过可以通过UNION 关键字来合并 LEFT JOIN 与 RIGHT JOIN来模拟FULL join。
原理
5.5 版本及以前,MySQL 本身只支持一种表间关联方式,就是嵌套循环(Nested Loop)。如果关联表的数据量很大,则join关联的执行时间会非常长。
5.6 版本及以后,MySQL 通过引入 BNL(Block Nested-Loop Join) 算法来优化嵌套执行。
Nested Loop Join - NLJ 算法
NLJ 算法:将驱动表/外部表的结果集作为循环基础数据,然后循环从该结果集每次一条获取数据作为下一个表的过滤条件查询数据,然后合并结果。如果有多表join,则将前面的表的结果集作为循环数据,取到每行再到联接的下一个表中循环匹配,获取结果集返回给客户端。
Nested-Loop 的伪算法如下:
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions,
send to client
}
}
}点评
因为普通 Nested-Loop 一次只将一行传入内层循环,所以外层循环(的结果集)有多少行, 内存循环便要执行多少次。在内部表的连接上有索引的情况下,其扫描成本为O(Rn),若没有索引,则扫描成本为O(Rn*Sn)。如果内部表S有很多记录,则 SimpleNested-Loops Join 会扫描内部表很多次,执行效率非常差。
Block Nested-Loop Join - BNL 算法
BNL 算法:将外层循环的行/结果集存入join buffer,内层循环的每一行与整个 buffer 中的记录做比较,从而减少内层循环的次数。
举例来说,外层循环的结果集是 100 行,使用 NLJ 算法需要扫描内部表 100 次,如果使用 BNL 算法,先把对 Outer Loop 表(外部表)每次读取的 10 行记录放到 join buffer,然后在 InnerLoop 表(内部表)中直接匹配这 10 行数据,内存循环就可以一次与这 10 行进行比较, 这样只需要比较 10 次,对内部表的扫描减少了 9/10。所以 BNL 算法就能够显著减少内层循环表扫描的次数。
前面描述的 query,如果使用 join buffer,那么实际join示意如下:
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer
if buffer is full {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions,
send to client
}
}
empty buffer
}
}
}
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions,
send to client
}
}
}如果 t1,t2 参与 join 的列长度和为 s,c 为二者组合数,那么 t3 表被扫描的次数为 (S * C)/join_buffer_size + 1,扫描 t3 的次数随着 join_buffer_size 的增大而减少,直到 join buffer 能够容纳所有的 t1,t2 组合, 再增大 join buffer size,query 的速度就不会再变快了。
使用 Join Buffer 的要点
- 若应用中 join 语句应用少的话,则无需太在乎 join_buffer_size 大小;若应用中 join 语句多的话,可适当增大 join_buffer_size 到 1MB 左右,如果内存充足可以设置为 2MB … 当然,如果内存充足却并发量不是特别大的时候,也可以继续增大sort buffer size的设置;
- 每一个线程都会创建自己独立的 buffer 而不是整个系统共享,所以设置的值过大可能会造成系统内存不足;
- join_buffer_size 变量决定 buffer 大小;
查看方式:SELECT @@join_buffer_size;
系统默认是 128KB。
join buffer 在 MySQL 5.1.23 版本之前最大为 4G,5.1.23版本及以后,在 windows x64 上可以超出 4GB 的限制。 - 只有在 join 类型为 all,index,range 的时候才可以使用 join buffer;
- 能够被 buffer 的每一个 join 都会分配一个 buffer,也就是说一个query最终可能会使用多个 join buffer;
- 第一个 nonconst table 不会分配 join buffer,即便其扫描类型是 all 或 index;
- 在 join 之前就会分配 join buffer,在 query 执行完毕即释放;
- join buffer 中只会保存参与 join 的列, 并非整个数据行;
应用
5.6 版本及以后,优化器管理参数 optimizer_switch 中的 block_nested_loop 参数控制着 BNL 是否被用于优化器。默认条件下是开启,若设置为 off,优化器在选择 join 方式的时候会选择 NLJ 算法。
inner join
内连接,也叫等值连接,inner join 产生同时符合A和B的一组数据。
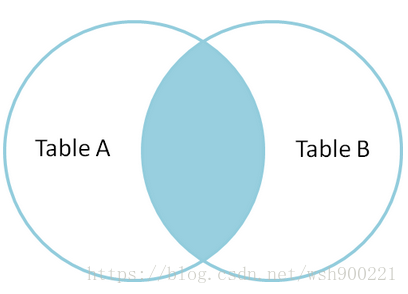
根据内连接,还可以求出除内连接外的所有部分。
SELECT * FROM A LEFT JOIN B ON A.name = B.name
WHERE B.id IS NULL
union
SELECT * FROM A right JOIN B ON A.name = B.name
WHERE A.id IS NULL;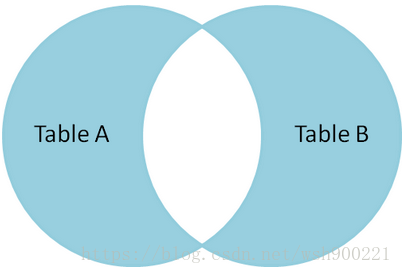
left join
left join(或 left outer join,在Mysql中两者等价,推荐使用 left join)左连接从左表(A)产生一套完整的记录,与匹配的记录(右表(B)) 。如果没有匹配,右侧将包含null。
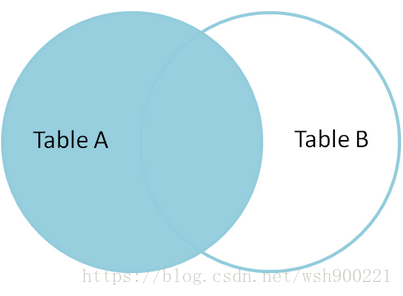
如果想只从左表(A)中产生一套记录,但不包含右表(B)的记录,可以通过设置where语句来执行
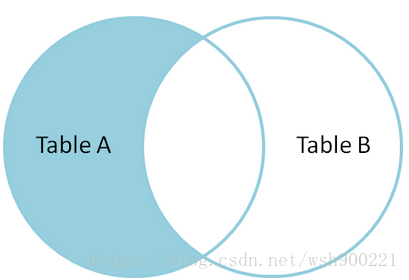
同理,还可以模拟出 inner join。
right join
同 left join。
Cross join
交叉连接,得到的结果是两个表的乘积,即笛卡尔积。
实际上,在 MySQL 中(仅限于 MySQL) CROSS JOIN 与 INNER JOIN 的表现是一样的,在不指定 ON 条件得到的结果都是笛卡尔积,反之取得两个表完全匹配的结果。
INNER JOIN 与 CROSS JOIN 可以省略 INNER 或 CROSS 关键字,因此下面的 SQL 效果是一样的:
... FROM table1 INNER JOIN table2
... FROM table1 CROSS JOIN table2
... FROM table1 JOIN table2Full join (MySQL 没有 Full join,用 union 代替)
straight_join
A straight_join BMySQL 对多表连接的处理方式:
MySQL优化器要确定以谁为驱动表,也就是说以哪个表为基准,在处理此类问题时,MySQL优化器采用了简单粗暴的解决方法:哪个表的结果集小,就以哪个表为驱动表,当然MySQL优化器实际的处理方式会复杂许多,具体可以参考:MySQL 优化器如何选择索引和 JOIN 顺序。
使用 straight_join 则不管 A 表大还是 B 表大,强制使 A 表做为驱动表。
对于 STRAIGHT_JOIN,我总觉得这种非标准的语法属于奇技淫巧的范畴,能不用尽量不用,毕竟多数情况下,MySQL优化器都能做出正确的选择。