Set集合概述
特点:无序、无下标、元素不可重复。
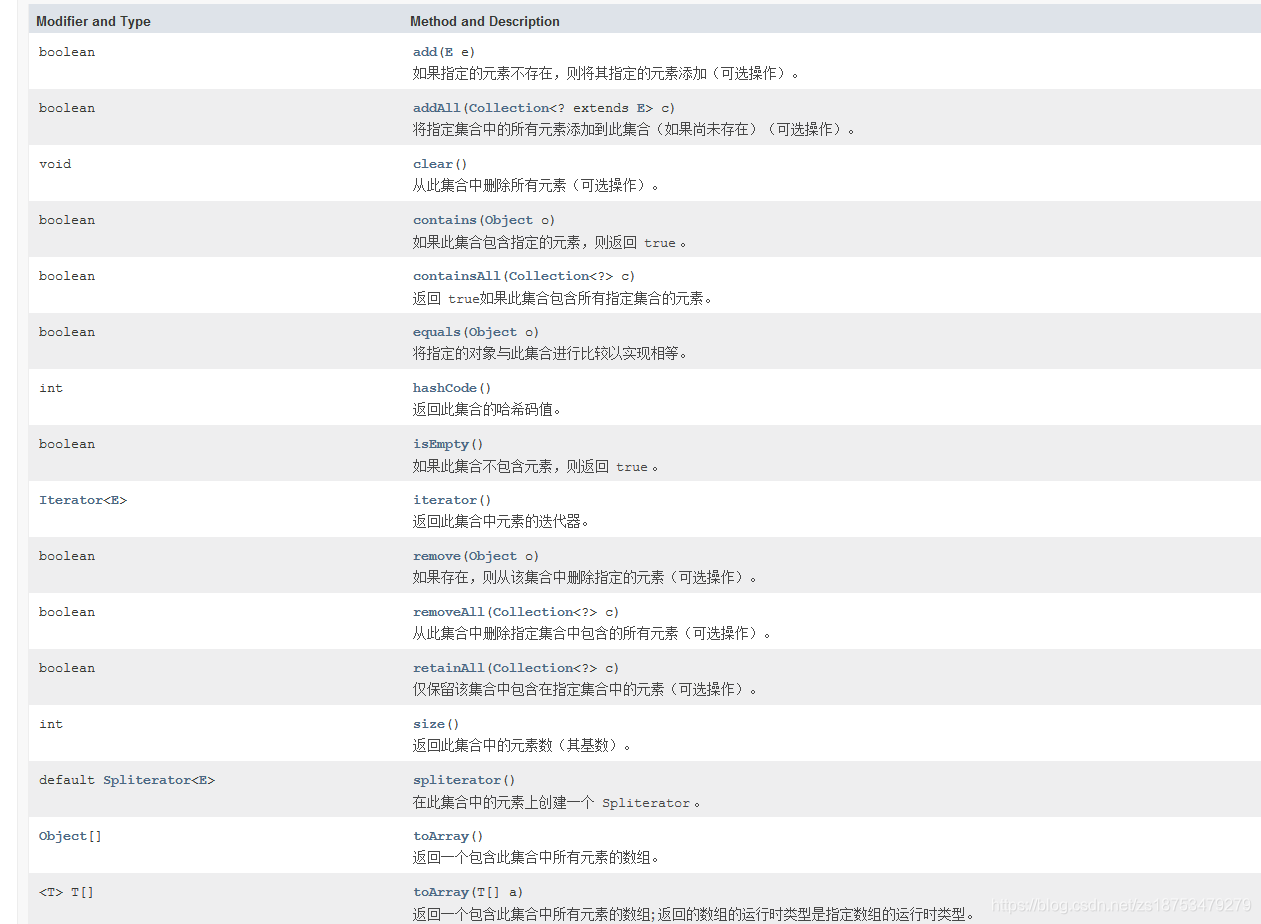
方法:全部继承自Collection中的方法。
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/**
* 测试Set接口的使用
* 特点:1.无序,没有下标;2.重复(不能出现相同的)
* 1.添加数据
* 2.删除数据
* 3.遍历【重点】
* 4.判断
*/
public class Test {
public static void main(String[] args) {
Set<String> set=new HashSet<String>();
//1.添加数据
set.add("tang");
set.add("he");
set.add("yu");
System.out.println("数据个数:"+set.size());
System.out.println(set);//无序输出
//2.删除数据
/*
* set.remove("tang"); System.out.println(set.toString());
*/
//3.遍历【重点】
//3.1 使用增强for
for (String string : set) {
System.out.println(string);
}
//3.2 使用迭代器
Iterator<String> iterator=set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
//4.判断
System.out.println(set.contains("tang"));
System.out.println(set.isEmpty());
}
}
HashSet【重点】
基于HashCode计算元素存放位置。
当存入元素的哈希码相同时,会调用equals进行确认,如结果为true,则拒绝后者存入。
注:hashSet存储过程:
第一步:根据hashCode计算保存的位置,如果位置为空,则直接保存,否则执行第二步。
第二步:执行equals方法,如果方法返回true,则认为是重复,拒绝存储,否则形成链表。
import java.util.HashSet;
import java.util.Iterator;
/**
* HashSet集合的使用
* 存储结构:哈希表(数组+链表+红黑树)
* 1.添加元素
* 2.删除元素
* 3.遍历
* 4.判断
*/
public class Test {
public static void main(String[] args) {
HashSet<Person> hashSet=new HashSet<>();
Person p1=new Person("tang",21);
Person p2=new Person("he", 22);
Person p3=new Person("yu", 21);
//1.添加元素
hashSet.add(p1);
hashSet.add(p2);
hashSet.add(p3);
//重复,添加失败
hashSet.add(p3);
//直接new一个相同属性的对象,依然会被添加,不难理解。
//假如相同属性便认为是同一个对象,怎么修改?
hashSet.add(new Person("yu", 21));
System.out.println(hashSet.toString());
//2.删除元素
hashSet.remove(p2);
//3.遍历
//3.1 增强for
for (Person person : hashSet) {
System.out.println(person);
}
//3.2 迭代器
Iterator<Person> iterator=hashSet.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
//4.判断
System.out.println(hashSet.isEmpty());
//直接new一个相同属性的对象结果输出是false,不难理解。
//注:假如相同属性便认为是同一个对象,该怎么做?
System.out.println(hashSet.contains(new Person("tang", 21)));
}
}
假如相同属性便认为是同一个对象,怎么修改?
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
hashCode方法里为什么要使用31这个数字大概有两个原因:
31是一个质数,这样的数字在计算时可以尽量减少散列冲突。
可以提高执行效率,因为31*i=(i<<5)-i,31乘以一个数可以转换成移位操作,这样能快一点;但是也有网上一些人对这两点提出质疑。
TreeSet(红黑树)
基于排序顺序实现不重复。
实现了SortedSet接口,对集合元素自动排序。
元素对象的类型必须实现Comparable接口,指定排序规则。
通过CompareTo方法确定是否为重复元素。
import java.util.TreeSet;
/**
* 使用TreeSet保存数据
* 存储结构:红黑树
* 要求:元素类必须实现Comparable接口,compareTo方法返回0,认为是重复元素
*/
public class Test {
public static void main(String[] args) {
TreeSet<Person> persons=new TreeSet<Person>();
Person p1=new Person("tang",21);
Person p2=new Person("he", 22);
Person p3=new Person("yu", 21);
//1.添加元素
persons.add(p1);
persons.add(p2);
persons.add(p3);
//注:直接添加会报类型转换错误,需要实现Comparable接口
System.out.println(persons.toString());
//2.删除元素
persons.remove(p1);
persons.remove(new Person("he", 22));
System.out.println(persons.toString());
//3.遍历(略)
//4.判断
System.out.println(persons.contains(new Person("yu", 21)));
}
}
查看Comparable接口的源码,发现只有一个compareTo抽象方法,在人类中实现它:
public class Person implements Comparable<Person>{
@Override
//1.先按姓名比
//2.再按年龄比
public int compareTo(Person o) {
int n1=this.getName().compareTo(o.getName()); // 字符串本身就具有comparaTo方法
int n2=this.age-o.getAge();
return n1==0?n2:n1;
}
}
除了实现Comparable接口里的比较方法,TreeSet也提供了一个带比较器Comparator的构造方法,使用匿名内部类来实现它:
/**
* TreeSet的使用
* Comparator:实现定制比较(比较器)
*/
public class Demo5 {
public static void main(String[] args) {
TreeSet<Person> persons=new TreeSet<Person>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
// 先按年龄比较
// 再按姓名比较
int n1=o1.getAge()-o2.getAge();
int n2=o1.getName().compareTo(o2.getName());
return n1==0?n2:n1;
}
});
Person p1=new Person("tang",21);
Person p2=new Person("he", 22);
Person p3=new Person("yu", 21);
persons.add(p1);
persons.add(p2);
persons.add(p3);
System.out.println(persons.toString());
}
}
/**
* 要求:使用TreeSet集合实现字符串按照长度进行排序
* helloworld tangrui hechengyang wangzixu yuguoming
* Comparator接口实现定制比较
*/
public class Demo6 {
public static void main(String[] args) {
TreeSet<String> treeSet=new TreeSet<String>(new Comparator<String>() {
@Override
//先比较字符串长度
//再比较字符串
public int compare(String o1, String o2) {
int n1=o1.length()-o2.length();
int n2=o1.compareTo(o2);
return n1==0?n2:n1;
}
});
treeSet.add("helloworld");
treeSet.add("tangrui");
treeSet.add("hechenyang");
treeSet.add("yuguoming");
treeSet.add("wangzixu");
System.out.println(treeSet.toString());
//输出[tangrui, wangzixu, yuguoming, hechenyang, helloworld]
}
}