HashSet与TreeSet
一、HashSet特点以及存储自定义对象保证元素唯一性
1,HashSet存储字符串并遍历
Java Code
|
1
2 3 4 5 6 7 8 9 |
HashSet<
String
> hs =
new
HashSet<>(); boolean b1 = hs.add( "a" ); boolean b2 = hs.add( "a" ); //当存储不成功的时候,返回false System.out.println(b1); System.out.println(b2); for ( String s : hs) { System.out.println(s); } |
2,存储自定义对象保证唯一性
需要重写hashCode()和equals()方法。因为存入一个元素时,HashSet首先会查看hashCode是否一样,如果不一样就会直接存入,不调用equals()方法。如果一样就会调用equals()方法,如果返回true则不存,否则就存储。
假设定义一个Person类有name、age属性。
Java Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
@Override
public int hashCode() { final int prime = 31 ; int result = 1 ; result = prime * result + age; result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; } @Override public boolean equals(Object obj) { if ( this == obj) //调用的对象和传入的对象是同一个对象 return true; //直接返回true if (obj == null) //传入的对象为null return false; //返回false if (getClass() != obj.getClass()) //判断两个对象对应的字节码文件是否是同一个字节码 return false; //如果不是直接返回false Person other = (Person) obj; //向下转型 if (age != other.age) //调用对象的年龄不等于传入对象的年龄 return false; //返回false if (name == null) { //调用对象的姓名为null if (other.name != null) //传入对象的姓名不为null return false; //返回false } else if (!name.equals(other.name)) //调用对象的姓名不等于传入对象的姓名 return false; //返回false return true; //返回true } |
* equals(): 属性相同返回true, 属性不同返回false,返回false的时候存储
二、LinkedHashSet概述
* 底层是链表实现的,是set集合中唯一一个能保证怎么存就怎么取的集合对象
* 因为是HashSet的子类,所以也是保证元素唯一的,与HashSet的原理一样
三、TreeSet
* TreeSet集合是用来对象元素进行排序的,同样他也可以保证元素的唯一
* 当compareTo方法返回0的时候集合中只有一个元素
* 当compareTo方法返回正数的时候集合会怎么存就怎么取
* 当compareTo方法返回负数的时候集合会倒序存储
TreeSet自然排序:
1.要排序的类中实现 Comparable<T>接口
2.重写Comparable接口中的Compareto方法,具体的排序规则在Compareto方法中规定
图解:

例子:
Java Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 |
@Override
//按照年龄排序 public int compareTo(Person o) { int num = this .age - o.age; //年龄是比较的主要条件 return num == 0 ? this .name.compareTo(o.name) : num; //姓名是比较的次要条件 } ----------------------------------------------------------------------------- @Override //按照姓名排序 public int compareTo(Person o) { int num = this .name.compareTo(o.name); //姓名是主要条件 return num == 0 ? this .age - o.age : num; //年龄是次要条件 } |
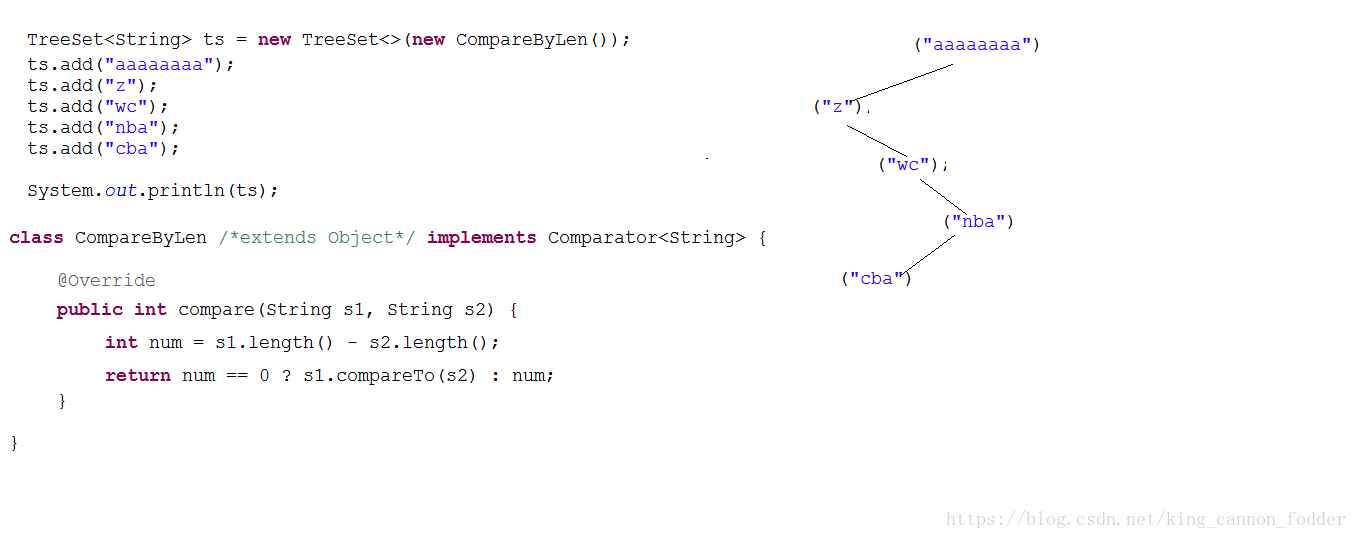
TreeSet比较器排序:
1.单独创建一个比较类,并且要让其继承Comparator<T>接口
2.重写Comparator接口中的Compare方法,具体的比较规则在Compare方法中规定
图解:
四、自然顺序与比较器顺序比较
* a.自然顺序(Comparable)
* TreeSet类的add()方法中会把存入的对象提升为Comparable类型* 调用对象的compareTo()方法和集合中的对象比较
* 根据compareTo()方法返回的结果进行存储
* b.比较器顺序(Comparator)
* 创建TreeSet的时候可以制定 一个Comparator* 如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
* add()方法内部会自动调用Comparator接口中compare()方法排序
* 调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数
* c.两种方式的区别
* TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序(没有就报错ClassCastException)* TreeSet如果传入Comparator, 就优先按照Comparator