文章目录
文章标题:
Compiler Optimization of Accelerator Data Transfers
加速器数据传输的编译器优化
作者:
Matthew B. Ashcraft
Alexander Lemon
David A. Penry
Quinn Snell
Introduction (一个愉快的小例子)
神经网络目前广泛应用于人工智能的应用当中,如语音助手、图像识别和自然语言处理等。随着神经网络愈加复杂,计算量也急剧上升,传统的通用芯片在处理复杂神经网络时受到了带宽和能耗的限制,人们开始改进通用芯片的结构以支持神经网络的有效处理(使用 FPGA、GPU代替CPU)。此外,研发专用加速芯片(ASIC)也成为另一条加速神经网络处理的途径,与通用芯片相比,它能耗更低,性能更高,我们可以将其称之为——加速器。然而不是程序的所有部分都应该调用这些加速器进行有效处理,所以导致了程序员们应该有选择性地将程序中从加速器受益最多的一段代码直接写入到加速器内核中。

在这些程序员的工作里面,一个十分困难的方面是,需要决定什么时候,把哪些数据传输给加速器以及再从里面传送出来。比如说 FPGA 更适合做需要低延迟的流式处理,GPU 更适合做大批量同构数据的处理,程序的另外一些地方使用传统的CPU就可以了,那么除非一个程序员优秀到具有管理其复杂架构的技能,否则数据传输位置不佳几乎是无可避免的。数据传输位置如果设置不佳会导致开销过大,这会让之前通过使用加速器而获得的那么一点点好处立即就相形见绌了。用人话举个例子就是:你正在做科创,东区实验楼有台机子能够加速你的预处理过程,仙林大学城有位老师对你的课题很有研究,咨询他能加速几个项目关键点的速度,同时呢,你在宿舍舒适的氛围中思路敏捷,写代码的效率是最高的,但你不知道整个科创项目哪部分用到这三个地点中具体的哪一个,但你想起了看过的《三体》中的话:“加速,不择手段的加速”,于是你每天都背着个大电脑在三个点之间跑来跑去,来回十几趟,一个月下来人累的半死不说,项目甚至都不能如期结题了,原来虽然每个地方都优化了你的科创处理过程,但是你路上通勤的时间已经远远超过了你节约下来的时间,这部分就是数据传输时间。

为了知道应该传输什么数据以及何时传输数据,程序员必须了解在整个程序中传输内存位置的数据流,以及加速器区域如何作为一个整体融入程序。
我们认为编译器应该承担起调度数据传输的责任,从而减少程序员肩上的担子,并通过减少传输的字节数来提高程序性能和程序效率。本文的研究表明,通过在加速器数据传输上执行整个程序传输调度,与在内核执行之前以及之后为所有设计的数据传输所有的数据相比,我们能够自动地消除传输到加速器和从加速器传输出来的高达99%的字节。
本文研究出来的编译器技术可以自动调度进出内核的数据并对其进行批注,分析和优化是和语言以及加速器无关的,但是在本文中,对于所用到的例子和测试来说,它们已经被实现为一个工作流,从OpenMP 到 LLVM -IR 再到 CUDA 。
Motivating Example (一个专业一点的例子)
虽然使用加速器来提高程序性能是一个空前强大的工具,但是其有效性在很大程度上取决于数据传输开销,在论文"Data transfer matters for GPU computing"描述的研究里,它们测量了在GPU之间来回传输不同数据大小的开销,对于几MB的数据传输会导致毫秒级的开销。如果在每次循环迭代中在主机和设备之间来回传输数据,那么此开销将乘以循环迭代次数,这很可能导致性能不如在主机上顺序执行。
为了解决这个问题,我们正在研究开销较低的位置(例如循环外部)安排传输。
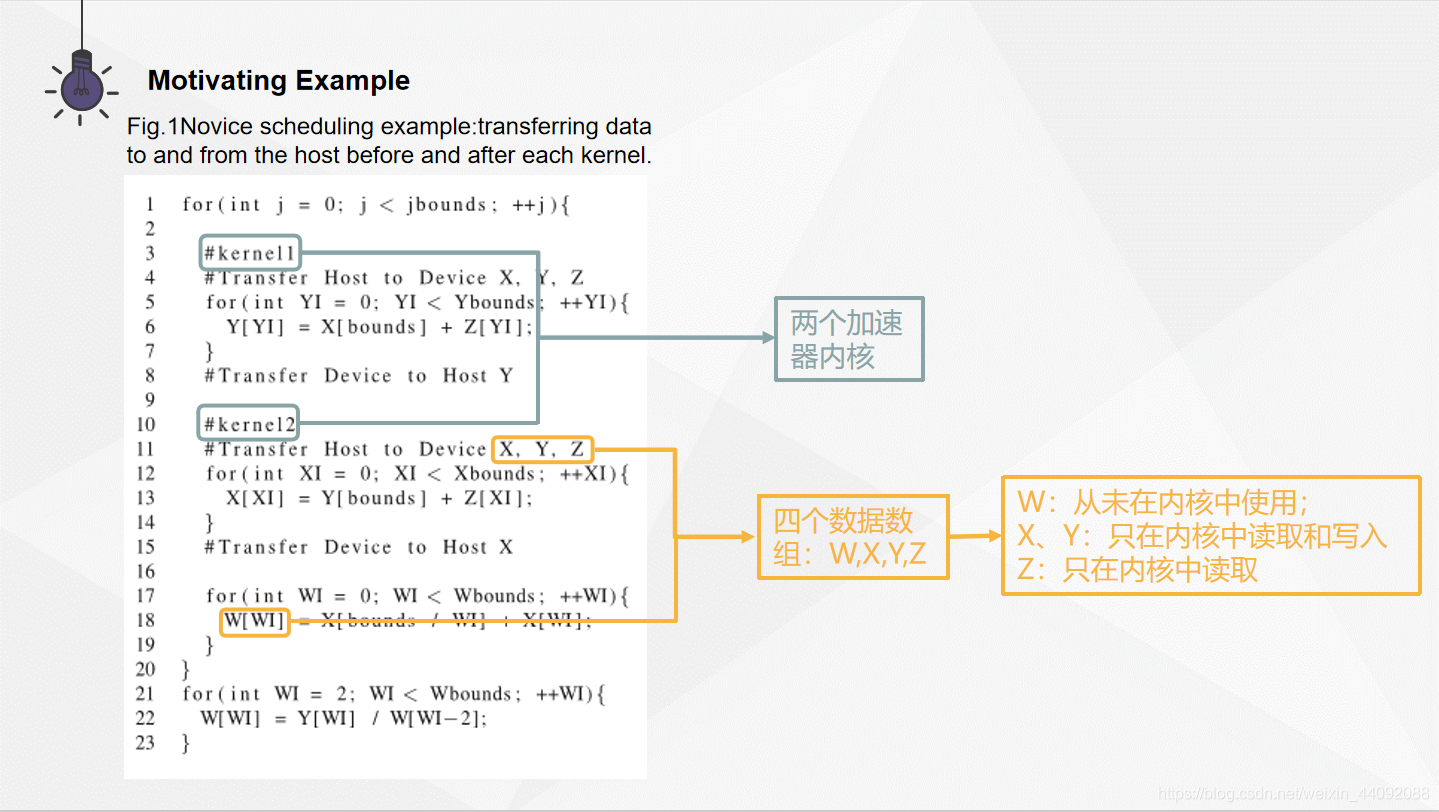
数据传输调度的价值在上图中可以轻松的看到。在比较循环里边的设备内部以及外部均使用了一些数据数组。可以发现,在 kernel 1 之前需要把 X, Y, Z 传给加速器设备,运行完之后再把 Y 传回主机,因为他里面的数据已经被修改了。对于 kernel 2 也是如此,X 需要在完成进程之后被送回主机。
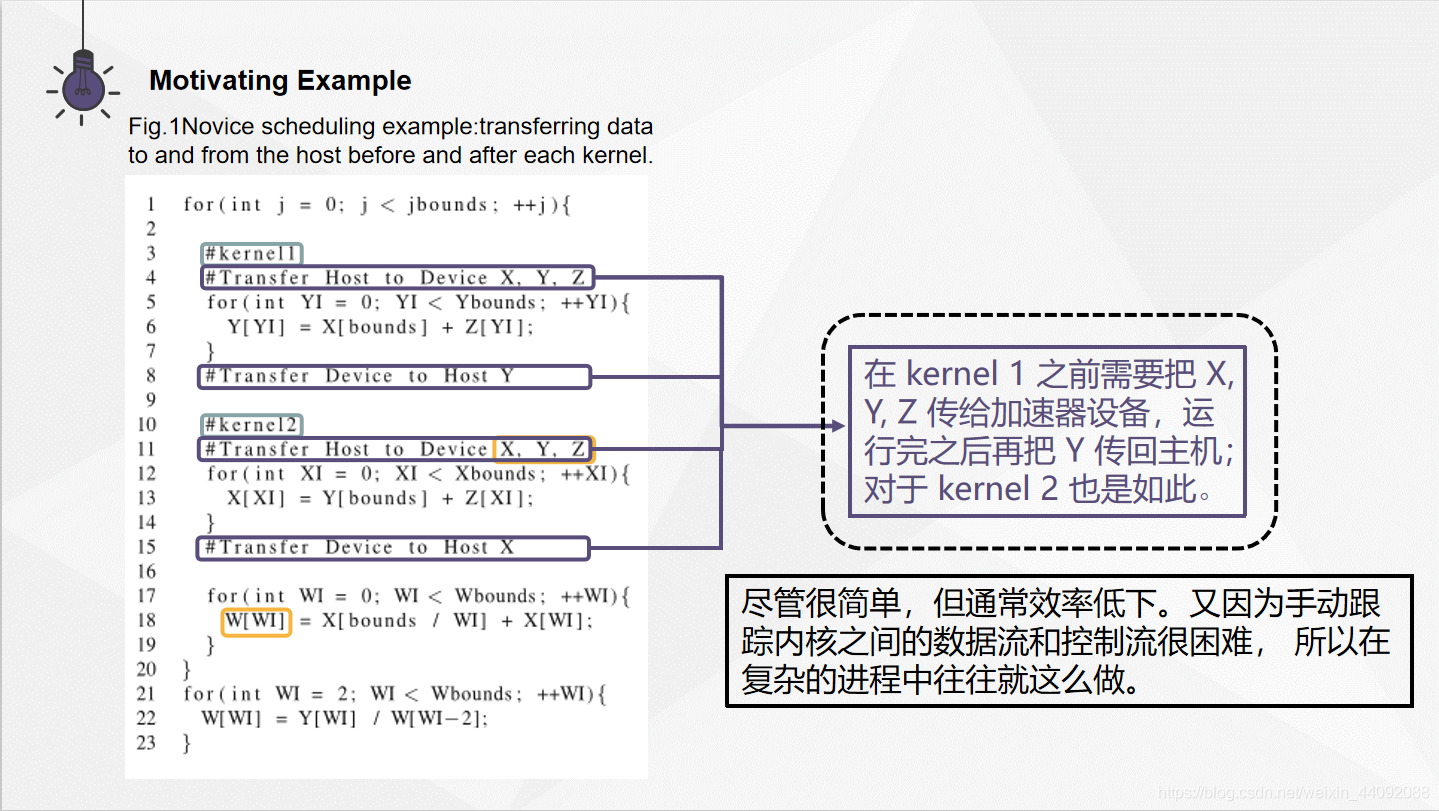
这里的加速做法是简单而粗暴的,在每一个内核运行的前后,把数据传输给内核或者返回给主机,这样做通常是低效率的。但是经常会看到在过程复杂的例子里看到这样的用法,因为这时使用人工对数据流和控制流进行分析反而得不偿失。

为了抛弃这种简单粗暴的低效方法,用户可以想办法知道同时被几个内核使用的变量,并估计将数据在 CPU 和 GPU 之间的传输代价。这样做会导致:X, Y, Z 被传输给 kernel 1, X, Y 在 kernel 2 运行完之后被传送出去。现在假设这些数组的大小相近,那么现在会将每次(for 大循环)迭代中数据传输次数由8次下降为5次,减少了37.5% .

现在仍然有进一步改进空间,数据传输调度可以被进一步应用,以发挥最大作用。还是上面的例子,在大循环里面 Z 仅仅是被读取了,所以对它的数据传送应该被安排在循环开头,并且直到循环结束之后再被送回主机。另外,在大循环里面 Y 并没有被主机使用(只是被内核使用),这意味着在循环开头前面就应该被主机传送给内核,并且直到循环结束才被送回主机。这些更深入的优化使得每次(for 大循环)迭代中数据传输次数由5次下降为2次,同时有3次传输只需要在大循环外部执行 1 次就好。(图2)

这些优化在此示例中非常简单,但是要在全局程序级别实现它们则要困难得多。当内核被嵌套的函数调用分隔开,并且各个循环分散在各处时,用户手动执行数据流和控制流分析可能非常困难且耗时。
Data Transfer Analysis and Scheduling
传统上,这些类型的全局分析是由编译器执行的,因此,我们认为编译器应负责执行这些分析。
数据传输分析和调度算法:
- 发现内核访问的内存位置;
- 发现冲突的内存访问;
- 生成调度图;
- 放置数据传输;(活跃分析、调度数据传输)
- 插入标记;
作者当前的实现使用 LLVM 编译器框架,并且与所使用的源语言和目标加速器无关。此外,分析不是路径敏感的,这意味着嵌套循环和条件结构对其影响最小。
3.1 发现加速器访问的内存位置
使用“过程间指向分析”来确定内核中的指令可以访问的所有内存位置,基于堆克隆使上下文相关的指向分析成为现实。这种分析是过程间的,上下文相关的和领域敏感的。
过程间指向分析的结果是内核中每个内存访问指令和指针到代表一组分配的内存位置的节点的映射,然后调度程序可以生成初始的保守传输。
内核中读取的所有内存位置都被标记为传输到加速器内核,而内核中修改的所有内存位置都标记为在传输到加速器之后还要返回传输。这些传输是根据未在内核中分配的内存位置的使用和修改生成的,因为指向内核中分配的位置的指针不会逃脱内核。
3.2 发现冲突的内存访问
在已知基本传输的情况下,搜索整个程序的数据结构分析结果,以查找映射到要传输的存储器位置的存储器访问指令。发现的任何此类指令或有冲突的指令以及它们所位于的功能均会记录下来。
一条有冲突的指令表示对CPU上内存位置的使用,该内存位置同时也被加速器使用。
如果此指令位于访问相同内存位置的内核之前,则只有在指令执行完毕后才能将数据传输到加速器;如果此指令是在内核访问相同的内存位置之后执行的,则在执行该指令之前,必须将数据从加速器传输回CPU。
此分析过程还发现了内存位置上的内存分配指令(堆和堆栈分配),这些指令被转移到内核中或从内核中移出,将他们存储在分配标记列表(allocmarker)中,以便之后加速器端对内存的分配和映射。
3.3 生成调度图
为了从整体上分析程序,创建一个简单的调度图可以帮助从整体上分析程序,该图是调用图与函数的各个控制流图的合并。右图为一个示例 (图3)
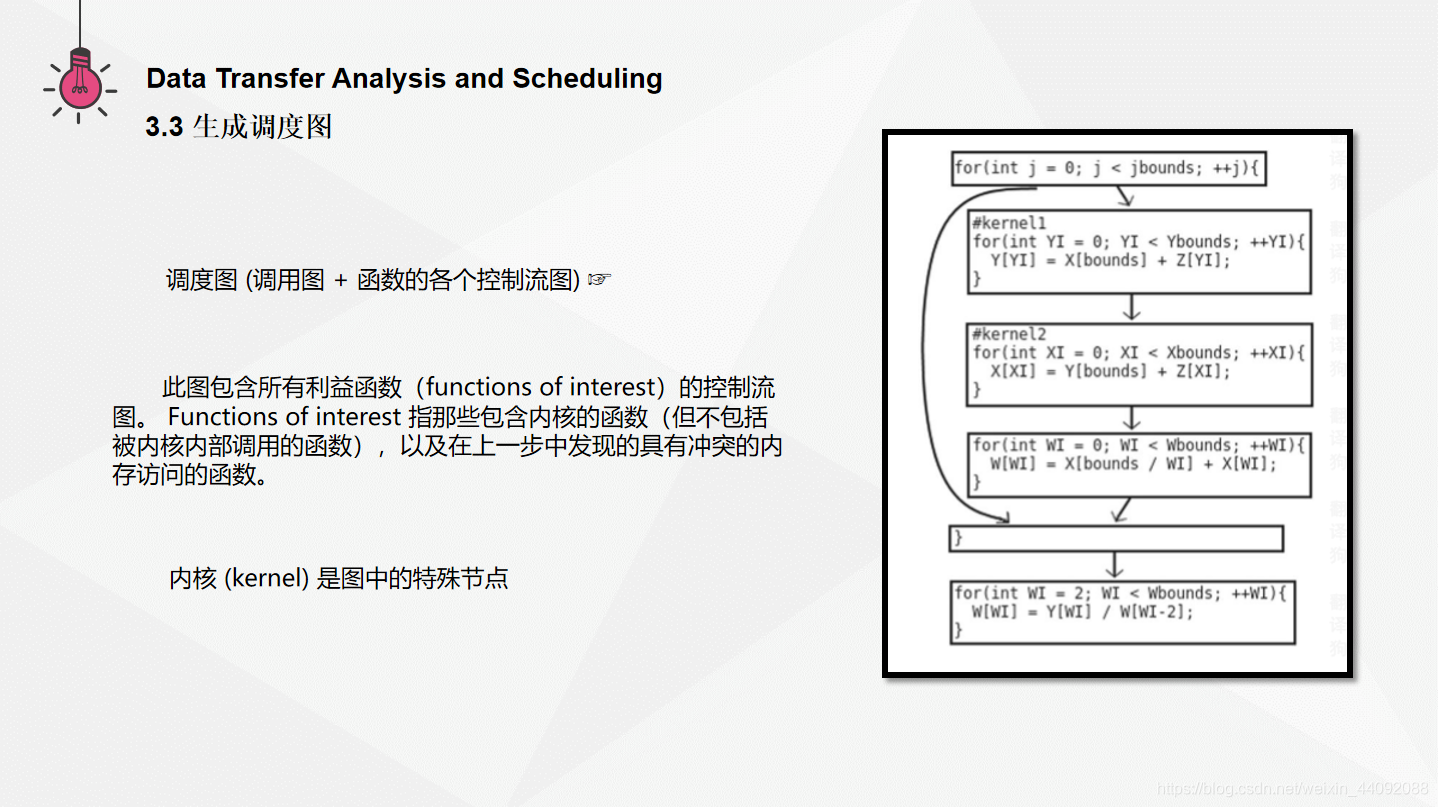
此图包含所有利益函数(functions of interest)的控制流图。 Functions of interest 指那些包含内核的函数(但不包括被内核内部调用的函数),以及在上一步中发现的具有冲突的内存访问的函数。他们还包括所有出于调用图路径上且该路径经过两个利益函数的最近共同祖先节点。
调用指令节点具有指向被调用函数的入口节点的有向边,而返回指令节点具有指向调用站点的有向边。内核是图中的特殊节点,从而处理了从内核内部和外部都调用函数的情况。
3.4 放置数据传输
3.4.1 活跃分析

在这之前假设我们已经知道了内核访问的内存位置、冲突的内存访问,调度图,下面进行数据传输里面的活跃分析。
活跃分析可以显示变量被迫在主机和设备之间移动的位置。活跃分析是一种被很好地定义的数据流分析,用来跟踪哪些变量被使用、处于活跃状态、在程序中的某个给定点。
下面是一些定义。每一个节点的输入 IN 的初始值为该节点中内存被读取的位置 USE (引用),节点的输出 OUT 的初始值为它后继节点(SUCCS)的输入。接着将该节点输出中没有在该节点内部定义的变量添加到它的输入(IN)中,这样向前遍历,直到到达定义了该变量的节点。同时注意,这里我们只关注那些相互矛盾的指令。
(下图是完整算法)

算法执行完毕之后,我们得到了 IN, OUT, ACCIN, ACCOUT。这些数据将会被用来调度数据传输。另外,了解哪些内核节点被每一个加速器输出、输出直接影响到也是很重要的。就因为这个原因,ACCIN和ACCOUT被用来跟踪哪些内核节点被每一个变量影响到。
下面用人话开始讲解例子。
(line 1 ~ 12)算法前面第1至12行用来初始化信息。这里TIN(n),TOUT(n)是之前确定好的传输给加速器的数据初值,那么就不再详细解释。worklist 里面存储的是待处理的节点,当它非空时进行下面的操作:
弹出栈顶节点元素 n,对节点 n 进行分析,主要分为两部分:普通活跃分析(在主机上运行),和加速器活跃分析(在加速器内核上运行)。并且这两部分顺序执行。

(line 14 ~ 21)对于普通的活跃分析而言:节点 n 的输出 OUT(n) 是其所有后继节点 s 的输入 IN(s) 的并集。记录下原来的 节点 n 的输入IN(n),当其改变的时候,意味着从后向前传播成功了,还有可能向前进一步传播,所以把节点 n 的前驱加入 worklist 中等待以后的再次处理。(下图)
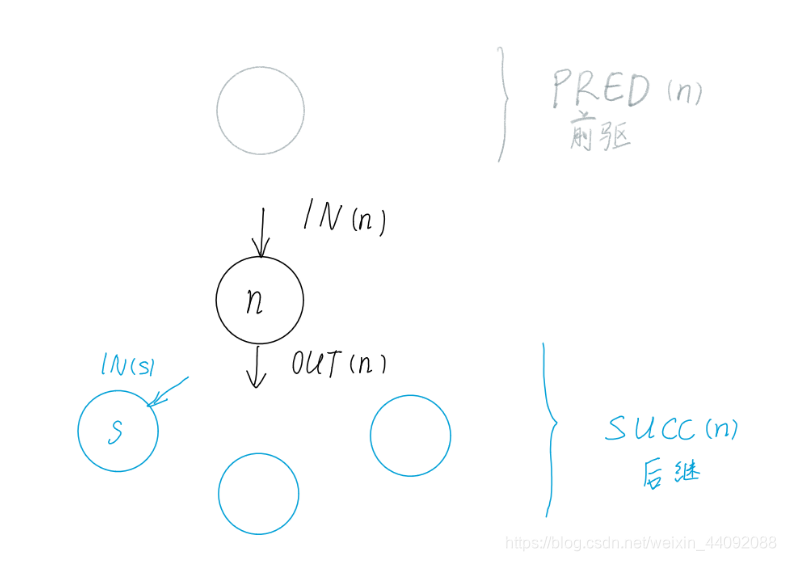

(line 23 ~ 32)来到对于加速器活跃分析第一部分 ACCIN :先保存节点 n 的加速器输入 ACCIN (n),声明集合 accsuccin ,是节点 n 所有后继节点 s 的加速器输入 ACCIN(s) 的交集,这里就和前面提到的知识联系上了,加速器喜欢做重复的事情,所以把这些集合的交集一起送给加速器来做会得到比较好的效率。对于集合 accsuccin(n) 里面的每一个变量 v 来说,如果它没有在节点 n 里面被定义,那么就被合并到节点 n 的加速器输入 ACCIN(n) 里面去。这里可以简单想一想变量 v 是从哪里来的,它是节点 n 所有后继节点 s 的加速器输入 ACCIN(s) 的交集中一个变量,既然出现在了后面,那么一定是要从前面传过来的,也就是在 ACCIN(n) 里面。如果节点 n 的加速器输入 ACCIN(n) 被更新了,那么就把节点 n 的前驱结点 PRED(n) 加入进 worklist 里面等待之后的处理,意味着加速器活跃分析从后往前传播成功了。(下图)
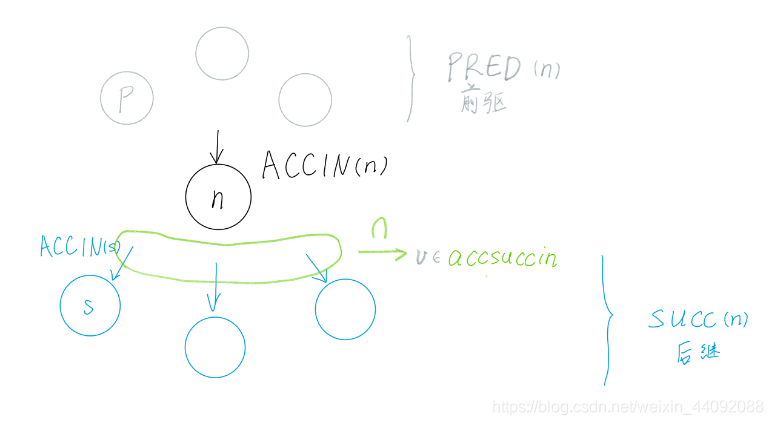

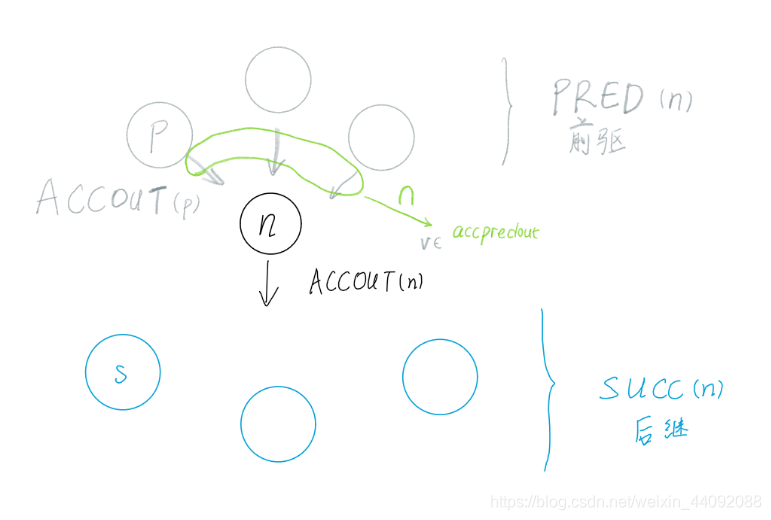
(line 33 ~ 42)加速器活跃分析第二部分 ACCOUT :保存原来的节点 n 的加速器输出 ACCOUT(n),声明变量 accpredout ,为节点 n 的所有前驱结点 p 的加速器输出 ACCOUT§ 的交集,和上一次一样,还是取交集。对其中的每一个变量 v 来说,如果它在节点 n 中既没有被定义也没有被引用,那么就被合并至节点 n 的加速器输出 ACCOUT(n) 中 // 原因 ,可以简单解释一下,现在这个变量 v 既没有被引用也没有被定义,所以在节点 n 处是没有加速器什么事情的,所以可以直接跳过节点 n ,送给节点 n 的加速器输出 ACCOUT(n),交给后面来处理就好。如果节点 n 的加速器输出 oldaccout 被更新了的话,就将节点 n 的每一个后继节点压入 worklist 中,此时数据流向后传播。(下图)
活跃分析完成之后,为了减少内存——加速器内核的传输次数以及寻找到变量的最佳传输位置,我们需要针对程序生成支配树和后置支配树(将原调配图的前驱节点和后继节点身份互换)。
为此,使用 Tarjan 算法(一种在流程图中查找支配者的快速算法。大家在大二上的离散课里学过)求出某个节点的立即支配者和后置立即支配者。
在调度传输时,我们使用支配树和后置支配树来确保插入的任何传输过程均正确支配或后置支配于使用它们的内核。
3.4.2 调度数据传输
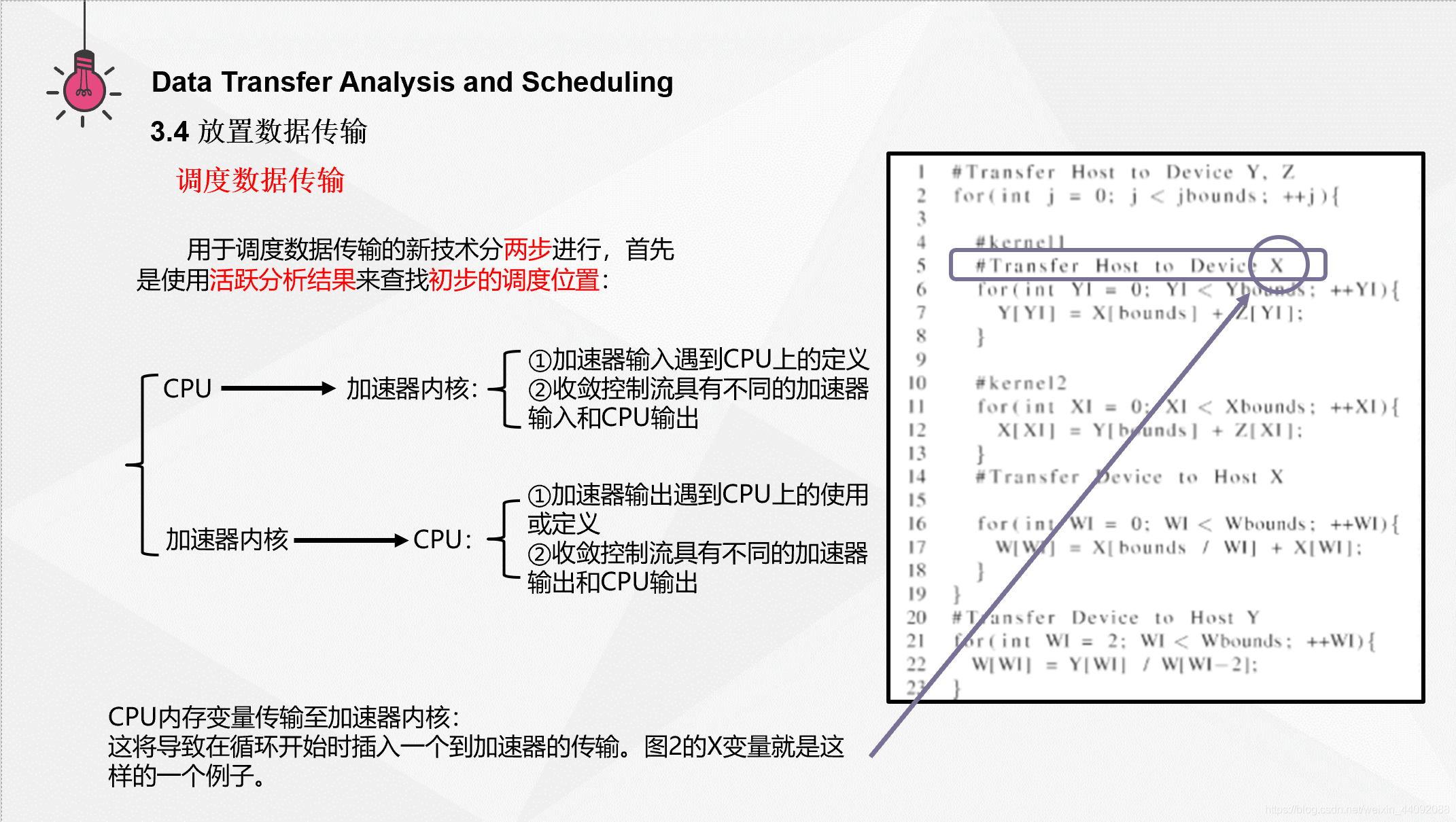
CPU 内存变量传输至加速器内核中收敛的输入通常发生在包含内核的循环和访问相同内存位置的嵌套循环中。此情况可能会导致分支上的加速器输入进入循环,而在循环的后沿产生 CPU 输出。这将导致在循环开始时插入一个到加速器的传输。图2的 X 变量就是这样的一个例子。
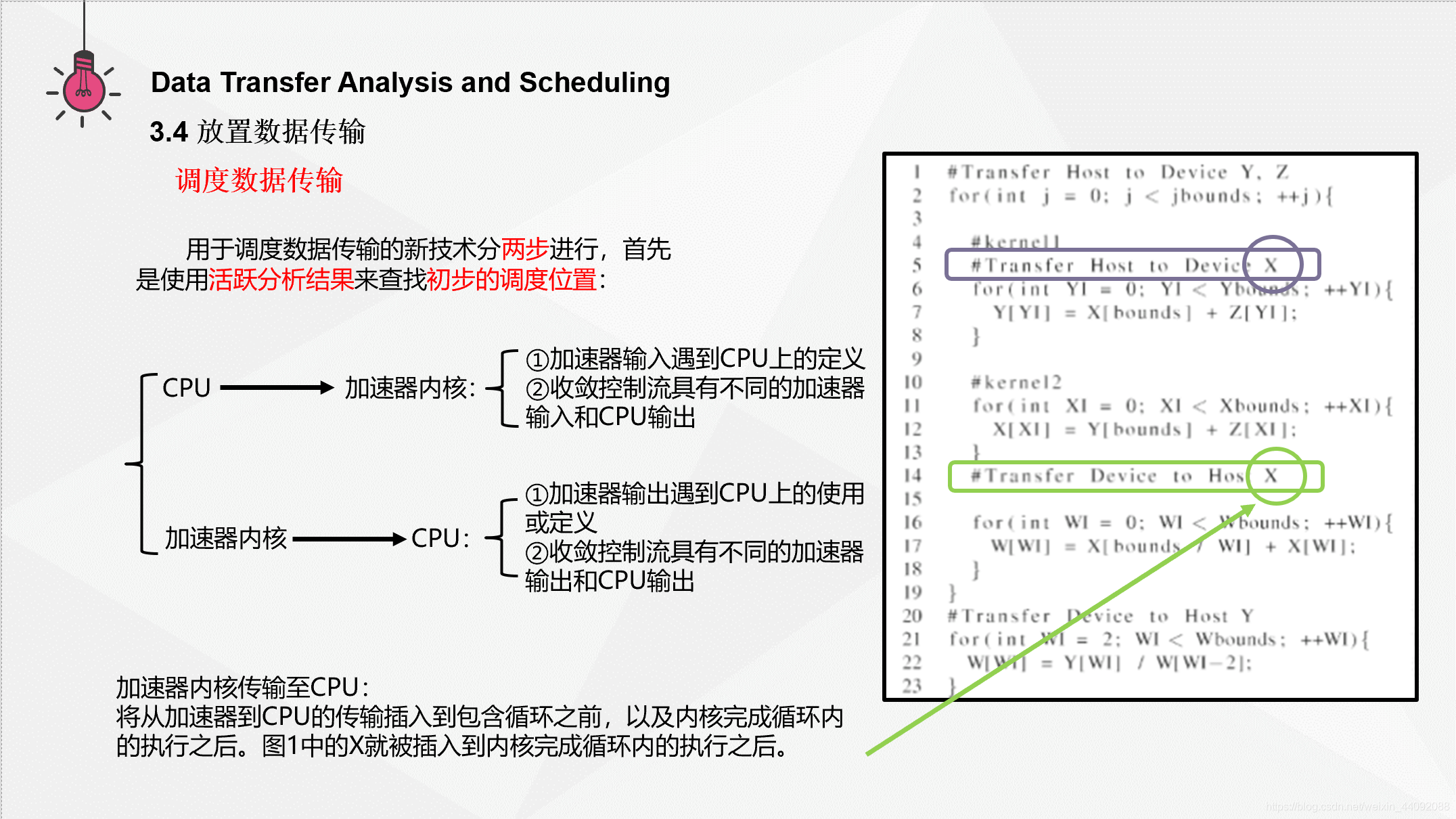
加速器内核传输至 CPU 内存变量中,当在循环之前和循环内在内核中访问相同的内存位置,并在同意循环内的 CPU 上访问同一内存位置时,通常会发生这种收敛的控制流。这些实例要求在包围循环之前,以及内核完成循环内的执行之后。图1中的 X 就被插入到内核完成循环内的执行之后。
下面介绍调度传输算法:

这里的变量介绍,b 是边界节点,c 是被一个边界节点使用到的内存位置。DOM(n) 为支配集,可以理解为必经结点集,DESC(n) 为节点 n 的后代集合。K(b)© 是被在边界节点 b 中 内存位置 c 影响到的内核。
对 K(b)© 中的每一个加速器内核 k 来说,先把它当作新的传输内核 NewTransfer,如果边界节点 b 是内核 k 的支配节点,那么就把边界节点 b 作为新的传输节点 NewTransfer ,否则进行以下判断:
对内核 k 的支配集中每一个节点 d ,如果它既是边界节点 b 的后代,同时满足不是边界节点 b 的支配节点,那么就把 NewTransfer 更新为 d。否则跳出循环,来到后面对 C(n)© 的分析。
如果 对节点 n 而言的受边界节点获取的内存位置 c 的调度传输 C(n)© 为空时,把 NewTransfer 放进去;如果非空,那么记录下当前的C(n)© 数据传输 CurrentTransfer ,如果它不属于上一部分得到的 NewTransfer 的支配集,则将它 NewTransfer 设置为新的 CunrrentTransfer。
(下图是完整算法)


如果图形的输入节点具有加速器输入值,则表明这些值未在CPU上初始化。 这意味着不需要将数据从CPU传输到加速器,并且可以删除传输。如果图形的出口节点具有加速器输出值,则意味着内核之后不再在CPU上再次使用该数据, 因此可以删除从加速器到CPU的数据传输。

Experimental Methodology

Experimental Results and Conclusion
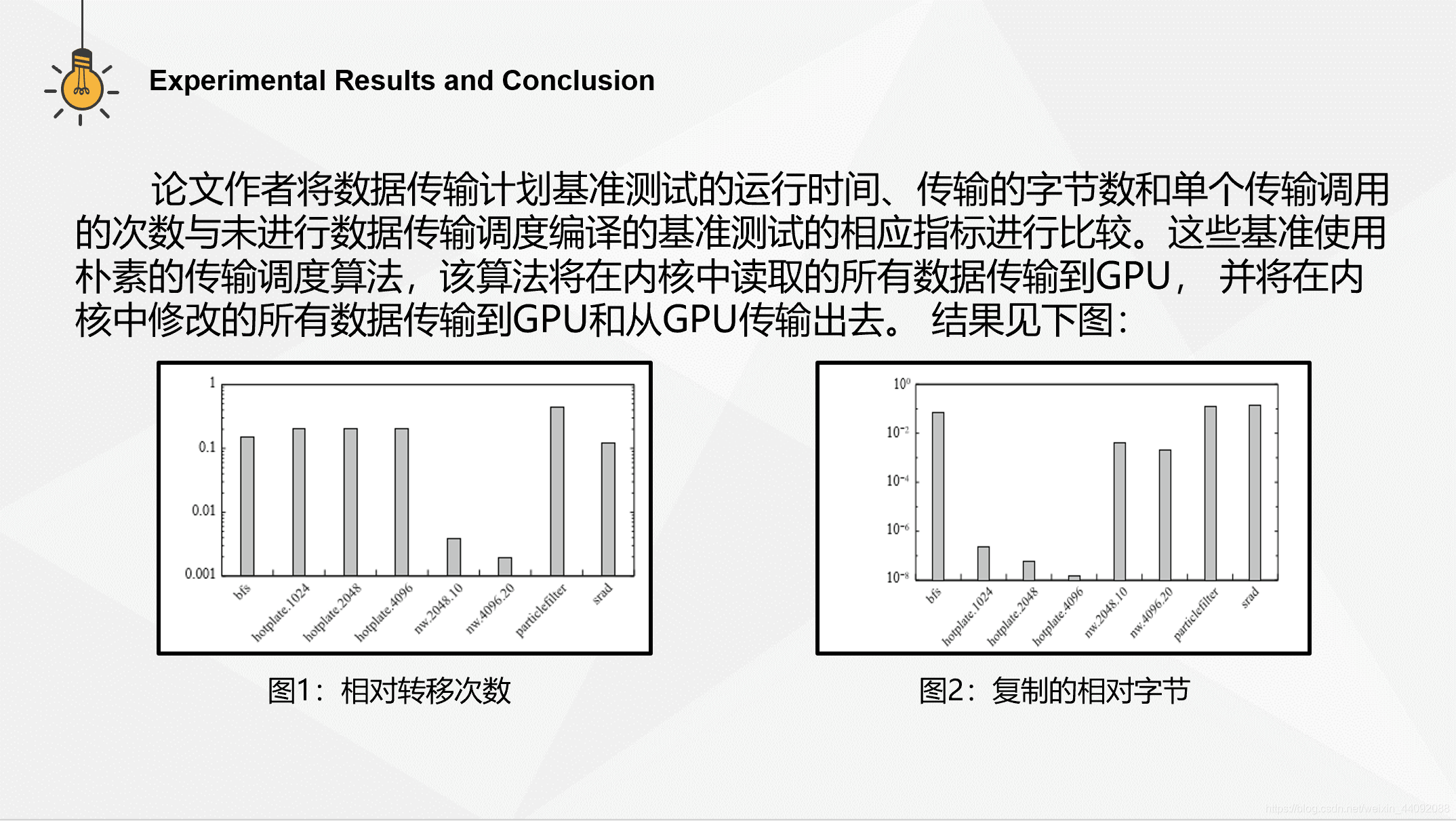
我们将数据传输计划基准测试的运行时间,传输的字节数和单个传输调用的 次数与未进行数据传输调度编译的基准测试的相应指标进行比较。这些基准 基准使用朴素的传输调度算法,该算法将在内核中读取的所有数据传输到GPU, 并将在内核中修改的所有数据传输到GPU和从GPU传输出去。