昨天大年三十下了一整天雨,去了一趟上海迪士尼,非常惊喜,人非常少,全程不用排队,几乎玩遍了所有的项目,估摸着以后是不会再去了。
如果没有人排队,那些占地面积巨大的迂回曲折的综合排队设施就很尴尬地完全成了摆设,但你依然不得不 “迂回曲折” 地经过它们,即便是一路小跑,也要花不少的时间绕过那九曲回廊,如果你是第一次去,还以为穿过这种迷宫式的九曲回廊是项目的一部分呢。
…
都没人排队了,要这些排队设施还有什么用?
本文接着前天那篇接着写:
https://blog.csdn.net/dog250/article/details/113783209
我在想,如果没有任何魔改且实现完美的BBR普及了整个网络,是不是路由器交换机就不再把buffer大小作为重要指标了呢?毕竟buffer没有大用了啊。
这很容易让我联想起我最近比较关注的bufferbloat, 路由器配备越来越多的buffer让数据包在里面尽情排队。 …这解释起来似乎很容易:
- 数据包的到达时间是随机的。
- 路由器转发数据包的时间是固定的。
- …
balabala…感觉又要扯到排队论了…大过年的…
排队论只能解释bufferbloat的低级成因,我们需要一种更加高级层面的解释。这又当如何解释?
最近在看一本书,侯世达的《我是个怪圈》,里面很详细地解释了什么是低级成因,什么是高级成因。
精心设计一套多米诺骨牌组成的装置,使得它可以在你 “输入” 一个素数的时候看到 “某一个特定的分支” 的多米诺骨牌倒下。现在问, “你输入641之后,某块多米诺骨牌为什么倒下? 如果你回答 “因为它前面的那块倒下了。” 那这就是低级成因,如果你回答 “因为你输入的641是一个素数” ,那么这就是高级成因。
那么bufferbloat的高级成因是什么?
如果从路由器的视角看,它似乎只能看到底层的成因,对于某个路由器,它只能看到数据包的到达是符合一定分布,它会将暂时处理不过来的数据包存入buffer…这似乎很合理,也是分内之事。
但是,路由器可以引导并且利用 破窗效应。
- 给你buffer,就是让你用的,buffer给你的越多,你用的就越多。
- 最终所有数据包为越来越多的buffer买单。
从数据包的视角来看,路由器提供的buffer可以带来 踮脚效应。
- 如果我不占buffer,别人就会占更多,我就会更惨。
这么一拉一推,bufferbloat就成了。
踮脚效应,破窗效应事实上是非常损人不利己的相互伤害!
那么到底谁在召唤谁?
如果路由器真的在使唤破窗效应,比如配置了稍微昂贵但还算优惠的大buffer,真的会被用尽吗?
反过来,数据包的踮脚效应会让路由器配备越来越大同时越来越昂贵的buffer吗?
这就要看各个TCP CC算法的收敛点在哪里了,即大家在瓜分什么,是在瓜分带宽呢,还是在瓜分buffer:
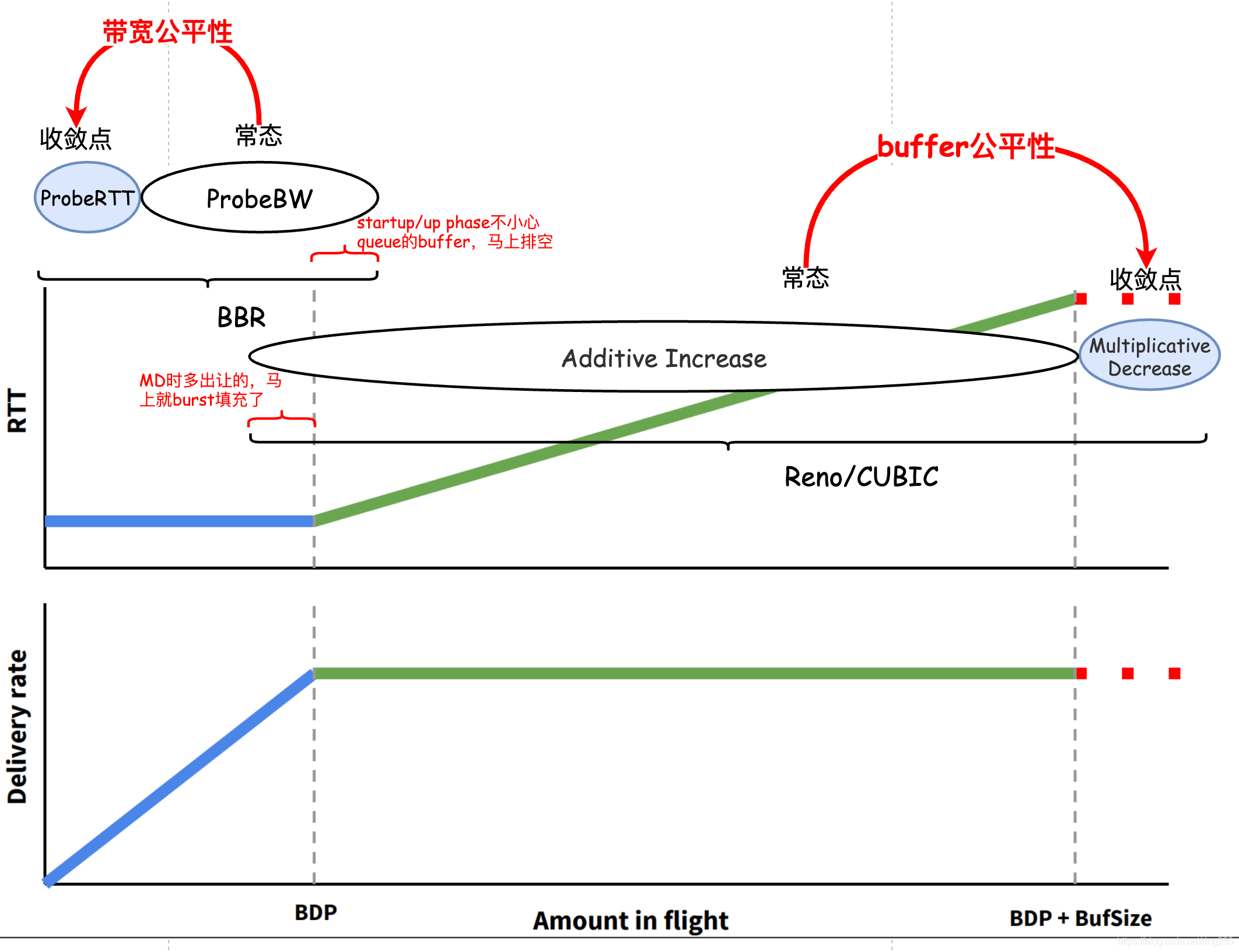
只要网络有一个Reno流,都会趋使所有流的收敛点向右边偏移,最终让路由器厂商得逞,提供越来越大的buffer,利用破窗效应让所有的数据流为这些buffer买单。
但是现在我们假设网络上已经没有Reno流了,全部是BBR流,那会怎样?
很多稍微懂点儿的人这个时候又该瞎逼逼了,告诉我国内的网络环境多么多么特殊,告诉我不可知的运营商如何如何,BBR还是会占buffer的,总会有新建连接的吧,我说数据包不排队,这不是瞎JB扯淡吗?你可能会拿一组实实在在的数据甩在我脸上,来告诉我BBR在现实中是多么不靠谱…
这些都不是核心,核心是什么?核心就是那个 ProbeRTT的自动同步。 为什么会自动同步?很简单:
- 占据buffer最多的那个流总会在10s后进入ProbeRTT,它将会排空它自己所占的buffer,此时所有因排队造成RTT增加的其它流均会同时采集到一个新的更小的RTT,即便此时仍然有排队,这些流的该RTT也会在从当刻起10s后同时过期,进而同时进入ProbeRTT,网络buffer被同时排空。
即便你再次用短连接撑不了10s,网络抖动等因素来怼,也无法改变这个核心。这是一个长期的趋势,一个稳定的状态,这个状态在上图中是将收敛点往左边拉的,换句话说,BBR有一种将buffer排空的 欲望 。
BBR对任何buffer的占据都是暂时的迫不得已。路由器配置大buffer将无法成为亮点。
一直以来传统的观点就是路由器交换机上一定要有大buffer,这其实是一种误区。我一向的观点是将数据的始发/终点和数据的通路分开,也就是把整个处理过程分为计算,传输和存储,其实传输就是网络,而存储则是数据的落盘,网络只是一条需要快速经过的路,而磁盘才是家,所以在网络上搞那么大buffer干什么? 不要把快速路当成停车场。
buffer是要有,但绝不是越来越大,buffer是应对突发和暂时拥塞的,但拥塞绝不是趋势。Reno家族事实上它最大的成果就是AIMD的公平,但对于拥塞控制的策略,它本质上是用拥塞治拥塞:
- 只有我观察到了拥塞,我才知道发生了拥塞!
有点意思吧。
更有意思的是,后面出现了Westwood,但是却没有把BBR从中剥离出来,看起来Westwood中已经蕴含了BBR了啊,少了什么呢?
嗯,Westwood少了那个ProbeRTT的收敛点,不过这是后话了。
我想喷一会儿,针对某些人或者不针对某些人。
对TCP算法的魔改有收益,那完全是对自私的一种苍白辩解。
早在大约10几年前,中国本土或者一些香蕉人社区开始出现一批希望通过多发些数据包企图绕过TCP固有拥塞控制的人,这是一种朴素的 “TCP加速” 的思想,在今天看来,这是一种倒行逆施(即使在今天这批人也不承认他们在开历史倒车,依然以元老泰斗的身份招摇撞骗),但在那个时候,这些人彷佛开辟了新世界。
他们根本不知道维护公平性的意义! 回到1986年之前,每个人都在做TCP加速!!!
诚然,人各为己,但那是建立在契约之上的,损人利己,就会被唾弃。他们行为的结果并非什么技术上的突破,而是几乎所有的公司甚至个人都开始了自己的 TCP加速!
最开始是APPEX,然后是网宿,依托这种伎俩构建了足够高的门槛,洋洋自得,但这个行当迟早还是被互联网公司,特别被大型互联网公司盯上了。于是这批 自称 第一代,第二代,第三代,第xx代的各种 掌门人 开始跃跃欲试于大型互联网公司之各家(通俗点说他们也是在主动找工作,而不是工作在找他们),几乎用同一种非常朴素的方式让这个行当(远远不能称之为行业)在整个互联网行业里成了带点乌烟瘴气的 “黑科技” ,这种乌七八黑里摸索出来的rubbish反过来又吸引了各类本应该在其它领域里创造辉煌的精英或者那些仅仅想蹭点技术热度的媒体人的注意,这就是现状。
这些 “掌门人” , “长老” 们,除了可以抑扬顿挫地鄙视一下晚辈们,还能做些什么呢?本着一种态度上的较真儿,这些人真的比谷歌的Neal Cardwell更牛逼吗? 为啥Neal看起来更善良呢?这帮掌门人长老泰斗们,如果你问他们一些形而上的问题,他们可以给你扯上8个小时17分钟29秒,如果你问一些具体的问题,比如CUBIC的细节是什么,比如Reordering是怎么计算的,他们的回答只有 “这么简单的问题还不会?” 或者 “自己看代码去。” 其实我很清楚,他们自己根本就不懂这些。
核心的中转设备之间很多都不是用裸TCP封装IP头之后传输的,要么换头,要么再封装,SCTP,GRE,UDP这种用的也很多,至少在网络设备看来,能看到TCP的就很少,把TCP当成整个网络,就以为网络就像大学课本上讲TCP/IP原理时那么朴素,也太简单了点。
具体情节,请在各大论坛,知乎,微信群,QQ群会会他们就知道,但唯独在maillist和github上找不到他们,哈哈。是不是觉得是时候像干马保国一样干他们一波了啊哈,然后看他们 “鼻青脸肿” 的样子去PR,最后再编出各种段子?
那么我是谁?我也是什么都不懂的,我甚至不会写JAVA,想 “打” 他们的,那绝对不是我,我 “打” 不过,哈哈,我甚至连他们都不如。
大年初一早上了,回想昨日,玩遍了整个迪士尼几乎所有项目,排除加倍的溢价,如果平时去迪士尼,一天只能玩三四个大型项目,甚至都不如,那么排队的成本(抵消掉了我玩新项目的时间)谁来买单呢?当然是我啊!
所以,用Reno/CUBIC的,你还觉得路由器仅仅转发了你的数据包吗?记住,本来你只能发1k数据,结果你把10k数据全部burst出去了,你以为这就完事了吗?结果呢:
- 最后一个ACK的到达时间没有丝毫改变(可能还更迟)。
- 你要花更多的钱买buffer更大的路由器(即便中间设备你不直接买,最终也是摊钱了的)。
经理滑倒了的瞬间,可是领带却还保持在原来的高度,皮鞋本来就在地面上,也没有降低高度,降低了的只有经理的衬衫,西裤,皮带,以及经理本人。
浙江温州皮鞋湿,下雨进水不会胖。