明天大年三十,去趟迪士尼,今天下班早,睡前写下这篇,结束这一农历年。
其实写这篇的初衷起因于我对那些看见4个窗口就想加到8个窗口的人鄙视,并且这些人几乎都是狂暴之人,我发现那些做业务逻辑的只要懂点TCP都不会好好说话,事实上他们大多数人什么都不懂,只有什么都不懂的人才会自以为是,天天鄙视别人。
对于TCP的优化,我听过无数遍 “丢包就慢点降窗,不丢包就快点增窗呗,这还不简单!” 我只是觉得他们只想炫耀。
就像我很讨厌网吧的网管以及阿里巴巴的运维一样,我也很讨厌那些对TCP夸夸其谈却给不出任何建设性建议的人,懂点网络有啥了不起吗?在我看来,端到端的东西,比如TCP,和网络只是沾边儿!
本文再来聊聊BBR的公平性。
我一直都想知道BBR算法的收敛点,因为我想借此看看它如何保证可以收敛到公平,遗憾的是并没有找到。就连BBR的原始论文以及源码实现,除了一些定性的分析之外,再没有任何更加细致深入的解释,这让我觉得不舒服。
在我看来,拥塞控制算法的公平性比效率更加重要,如果你想提高传输效率,那就别在拥塞控制上做文章了,拥塞控制注定是降低效率的,它提高的是公平性。拥塞控制的目标是保证所有人有路可走,不怕慢就怕停,不患寡而患不均。
而我们知道,包括CUBIC在内的Reno家族CC在这方面做的很好,其背后起作用的就是AIMD。那么BBR的公平性,何去何从?
其实Reno家族的CC和BBR在公平性方面可以是一回事。
再回到BBR论文里的BtlBw/RTprop示意图:
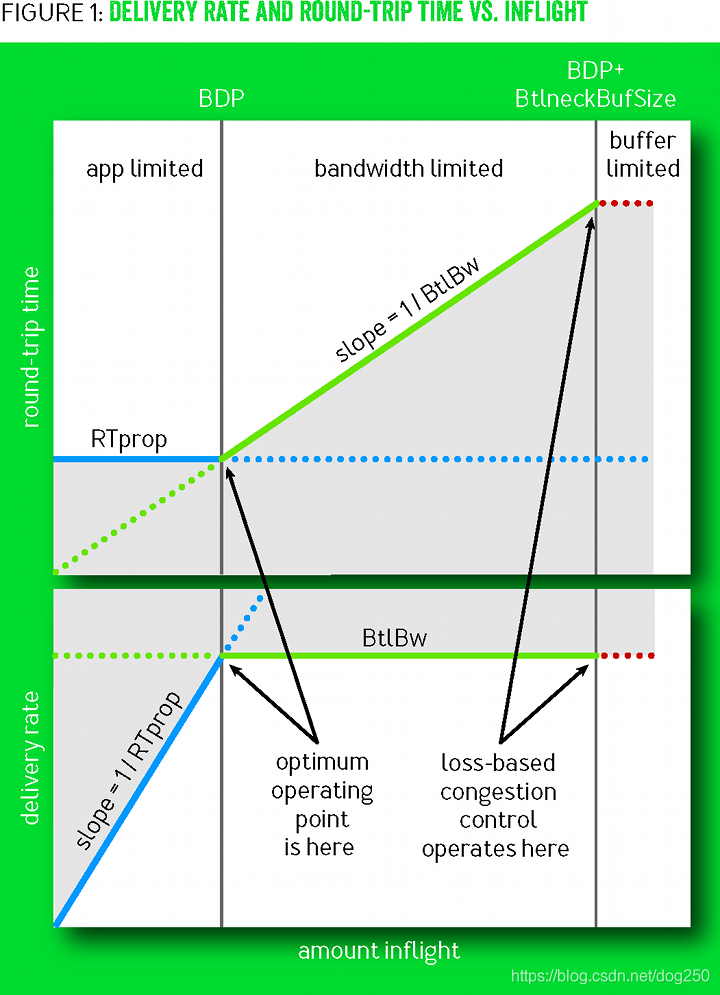
我们来比较一下Reno和BBR的Operating point。先来说什么是Operating point。
所谓的Operating point实际上就是一个 收敛点 。我们知道TCP的CC是一个典型的反馈系统,任何负反馈系统都有一个所谓的 “目标” ,也就是这个系统趋向的位置,然后在这个目标位置附近左右摇摆,最终这实际上是一个平衡点。
对于Reno家族的CC,其收敛点就是 buffer被填满的位置 ,在该位置:
- Reno流的BtlBw最大,RTT最大。
对于BBR而言,其收敛点在 buffer即将被填充但尚未被填充的位置 ,在该位置:
- BBR流的BtlBw最大,RTT最小,等于RTprop。
由控制论可知在上述的收敛点执行AIMD可以保证公平性,现在的问题是Reno家族和BBR分别怎么知道自己到了收敛点。
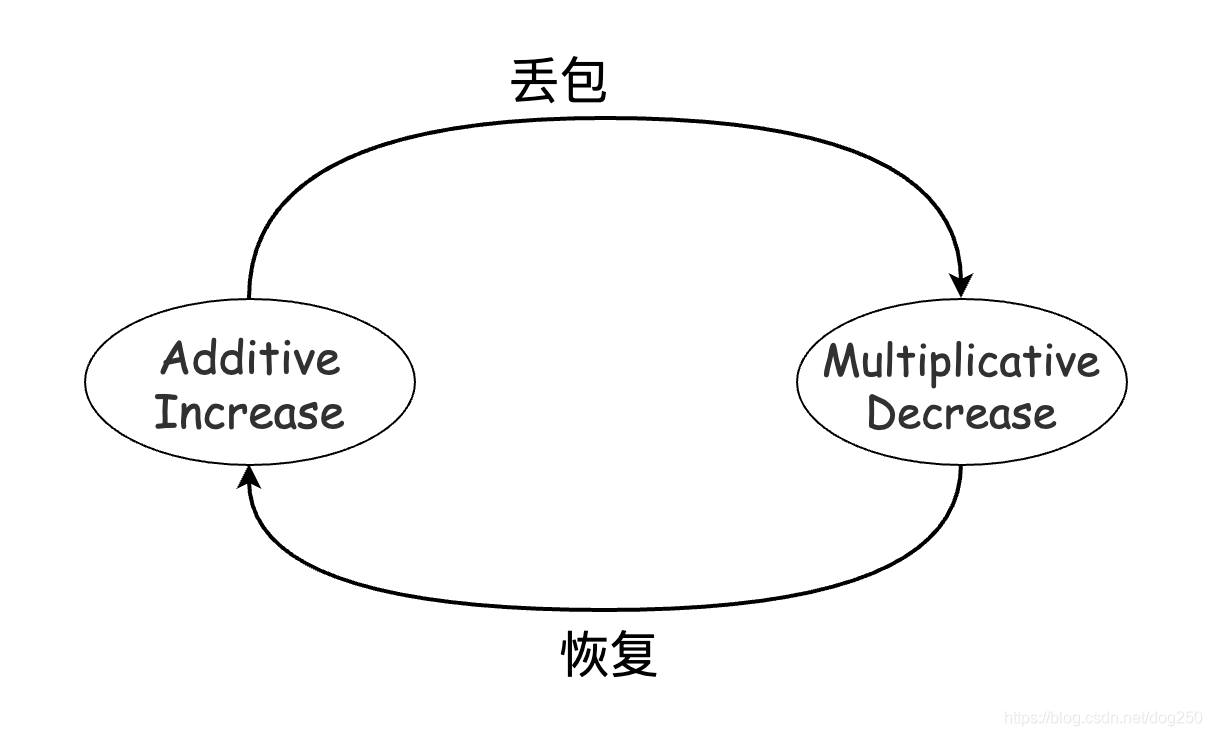
Reno家族简单,路由器交换机的buffer填满后会丢包,基于尾部丢包的假设,丢包将会被所有的Reno TCP流感知,于是它们均会执行MD减窗,然后进行相对缓慢的AI增窗,以此反复我们可以通过数学推导出所有Reno流将收敛到公平。
然而BBR呢?BBR如何感知到自己到达了收敛点呢?似乎很难。没有任何全局信号可以指示收敛点的到来。
根据上图,BBR的BtlBw和RTprop无法同时测量的,测量BtlBw需要塞满buffer,测量RTprop不能使用buffer。
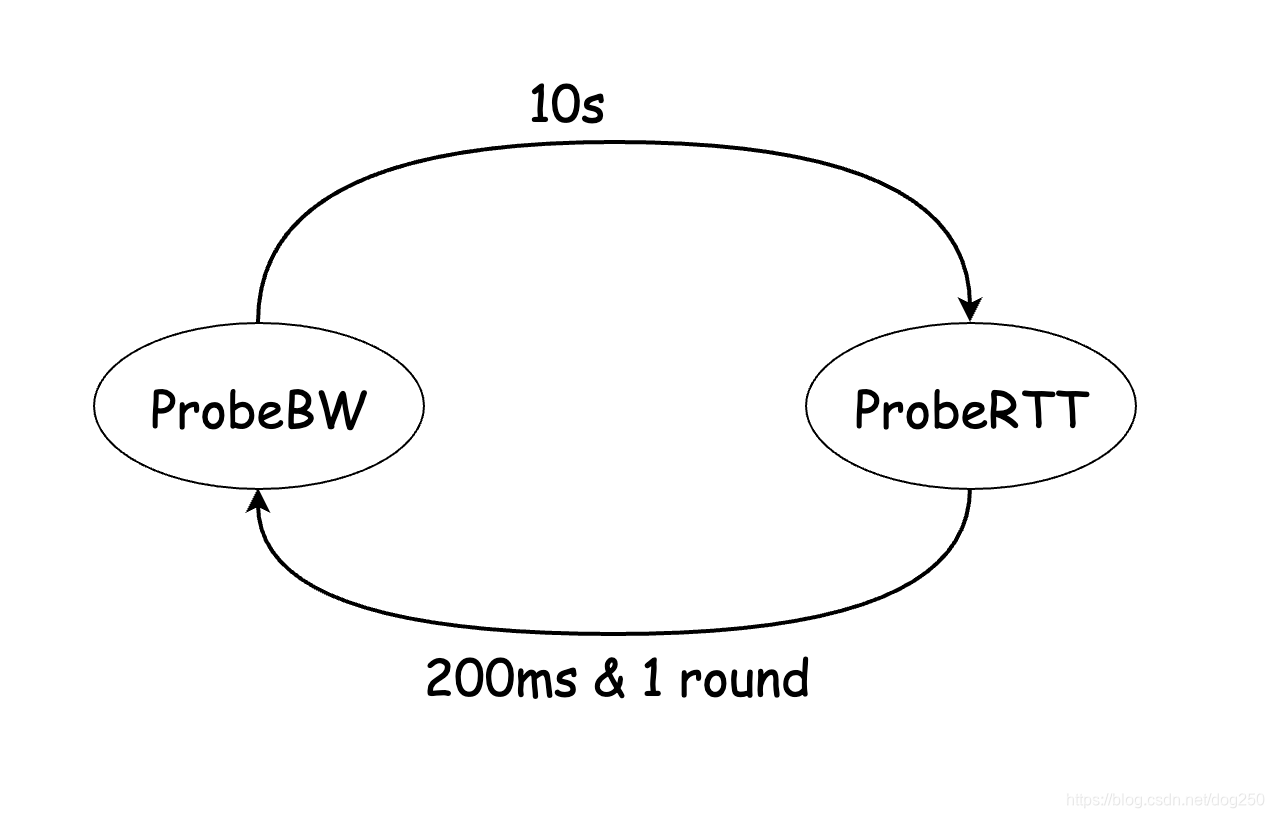
BBR取了个巧:
- ProbeBW状态:BBR通过延续10s的up/down稳态来试图塞满带宽,由此可以测得BtlBw。
不管这10s中是自己还是其它流塞满了带宽,但几乎10s肯定能测量出最大的带宽。 - ProbeRTT状态:BBR在延续10s的up/down之后突然排空所有的buffer,由此可以测得RTprop。
通过将自己cwnd限制为4看起来不能保证整个buffer被排空,但这里有一个自动全局同步,下面说。
注意上面的ProbeRTT状态,很多人会误认为在这个阶段pacing rate会跌零然后重新开始,事实上这是错误的。ProbeRTT状态相比ProbeBW状态而言持续非常短,而BBR计算pacing rate所使用的BtlBw是windowed_max的,因此离开ProbeRTT再次进入ProbeBW状态时,绝大多数情况下,其BtlBw是没有变化的。我们还是看代码的注释吧:
/* Bottleneck Bandwidth and RTT (BBR) congestion control
*
* BBR congestion control computes the sending rate based on the delivery
* rate (throughput) estimated from ACKs. In a nutshell:
*
* On each ACK, update our model of the network path:
* bottleneck_bandwidth = windowed_max(delivered / elapsed, 10 round trips)
* min_rtt = windowed_min(rtt, 10 seconds)
* pacing_rate = pacing_gain * bottleneck_bandwidth
* cwnd = max(cwnd_gain * bottleneck_bandwidth * min_rtt, 4)
...
*/
...
/* The goal of PROBE_RTT mode is to have BBR flows cooperatively and
* periodically drain the bottleneck queue, to converge to measure the true
* min_rtt (unloaded propagation delay). This allows the flows to keep queues
* small (reducing queuing delay and packet loss) and achieve fairness among
* BBR flows.
*
* The min_rtt filter window is 10 seconds. When the min_rtt estimate expires,
* we enter PROBE_RTT mode and cap the cwnd at bbr_cwnd_min_target=4 packets.
* After at least bbr_probe_rtt_mode_ms=200ms and at least one packet-timed
* round trip elapsed with that flight size <= 4, we leave PROBE_RTT mode and
* re-enter the previous mode. BBR uses 200ms to approximately bound the
* performance penalty of PROBE_RTT's cwnd capping to roughly 2% (200ms/10s).
*
* Note that flows need only pay 2% if they are busy sending over the last 10
* seconds. Interactive applications (e.g., Web, RPCs, video chunks) often have
* natural silences or low-rate periods within 10 seconds where the rate is low
* enough for long enough to drain its queue in the bottleneck. We pick up
* these min RTT measurements opportunistically with our min_rtt filter. :-)
*/
当我们把BBR简化,去除了非核心的杂项之后,BBR其实就是一个在两个状态之间周期转换的状态机:
是不是和Reno家族的AI状态和MD状态周期转换的状态机很类似:
我们可以在BtlBw/RTprop图示上将两者统一起来:
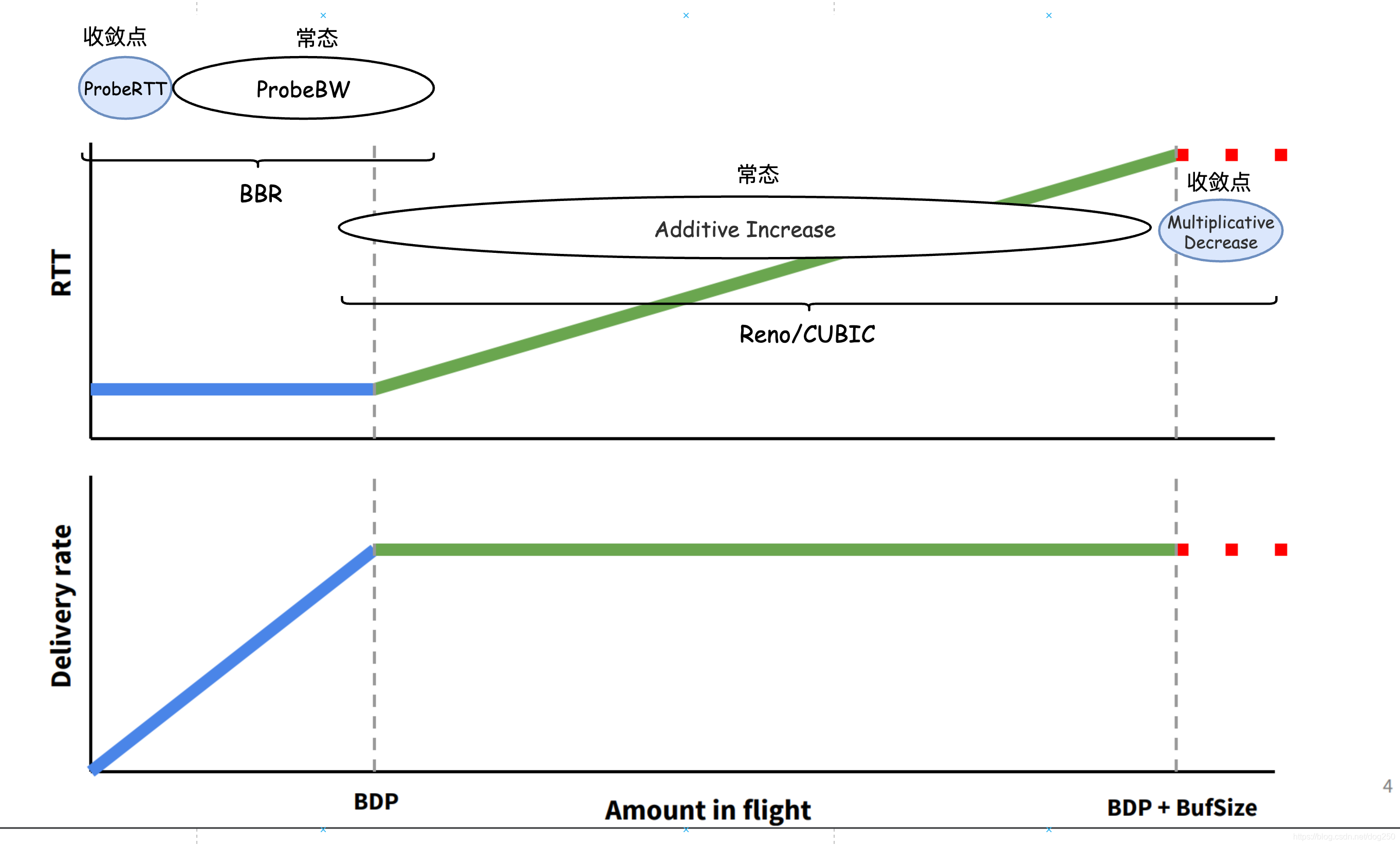
哈哈,Reno确实是 面向buffer的 ,它是bufferbloat的初始。没有buffer的overflow便无法指示Reno的收敛点。
westwood像是一个经过BBR调制的Reno…
附带一个引自BBR论文的描述:
BBR synchronizes flows around the desirable event of an empty bottleneck queue. By contrast, loss-based congestion control synchronizes around the undesirable events of periodic queue growth and overflow, amplifying delay and packet loss.
现在让我们看为什么BBR会收敛到全局同步进入ProbeRTT状态。我觉得还是引用原文的好:
To learn the true RTProp, a flow moves to the left of BDP using ProbeRTT state: when the RTProp estimate has not been updated (i.e., by measuring a lower RTT) for many seconds, BBR enters ProbeRTT, which reduces the inflight to four packets for at least one round trip, then returns to the previous state. Large flows entering ProbeRTT drain many packets from the queue, so several flows see a new RTprop (new minimum RTT). This makes their RTprop estimates expire at the same time, so they enter ProbeRTT together, which makes the total queue dip larger and causes more flows to see a new RTprop, and so on. This distributed coordination is the key to both fairness and stability.
BBR的ProbeRTT状态的同步是一种自然的同步。
OK,现在我们确定了BBR的收敛点,即离开ProbeRTT阶段进入ProbeBW的那一刻。在那一刻,BtlBw保持,而RTprop最新测得,为了保证公平性,需要在这个收敛点做点什么,就像Reno家族在buffer overflow做的MD减窗操作那样。
遗憾的是,BBR在这里除了随机选择一个phase进入ProbeBW阶段之外,什么也没有做。我想象不出BBR论文中下图的理由:
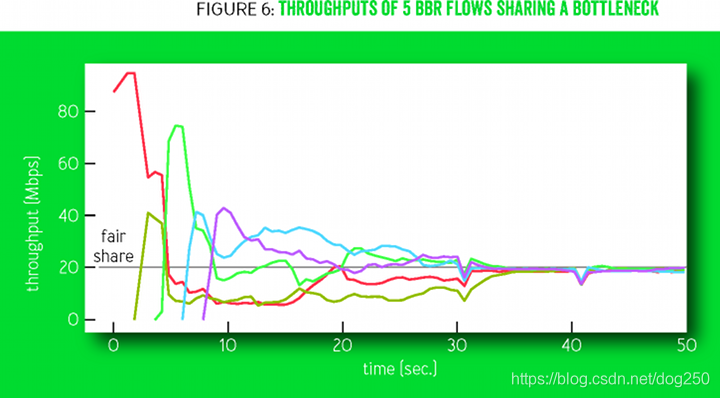
下面这个图倒是像真的:
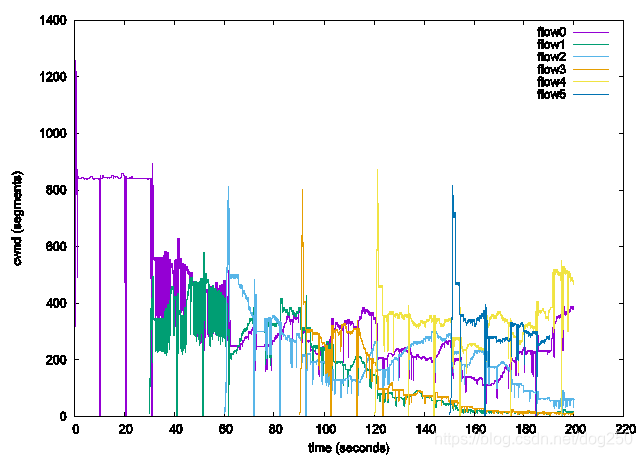
我的测试结果如下:
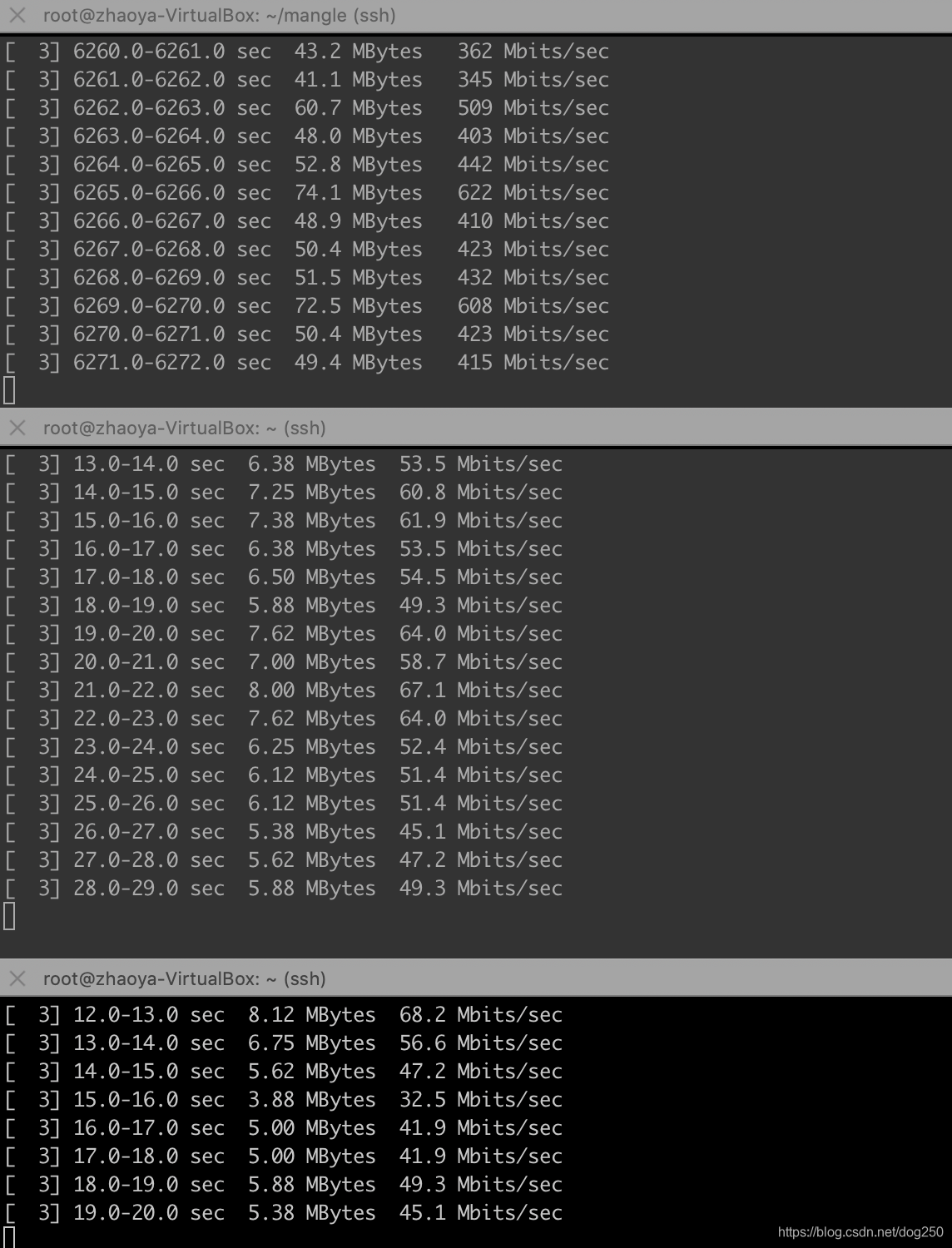
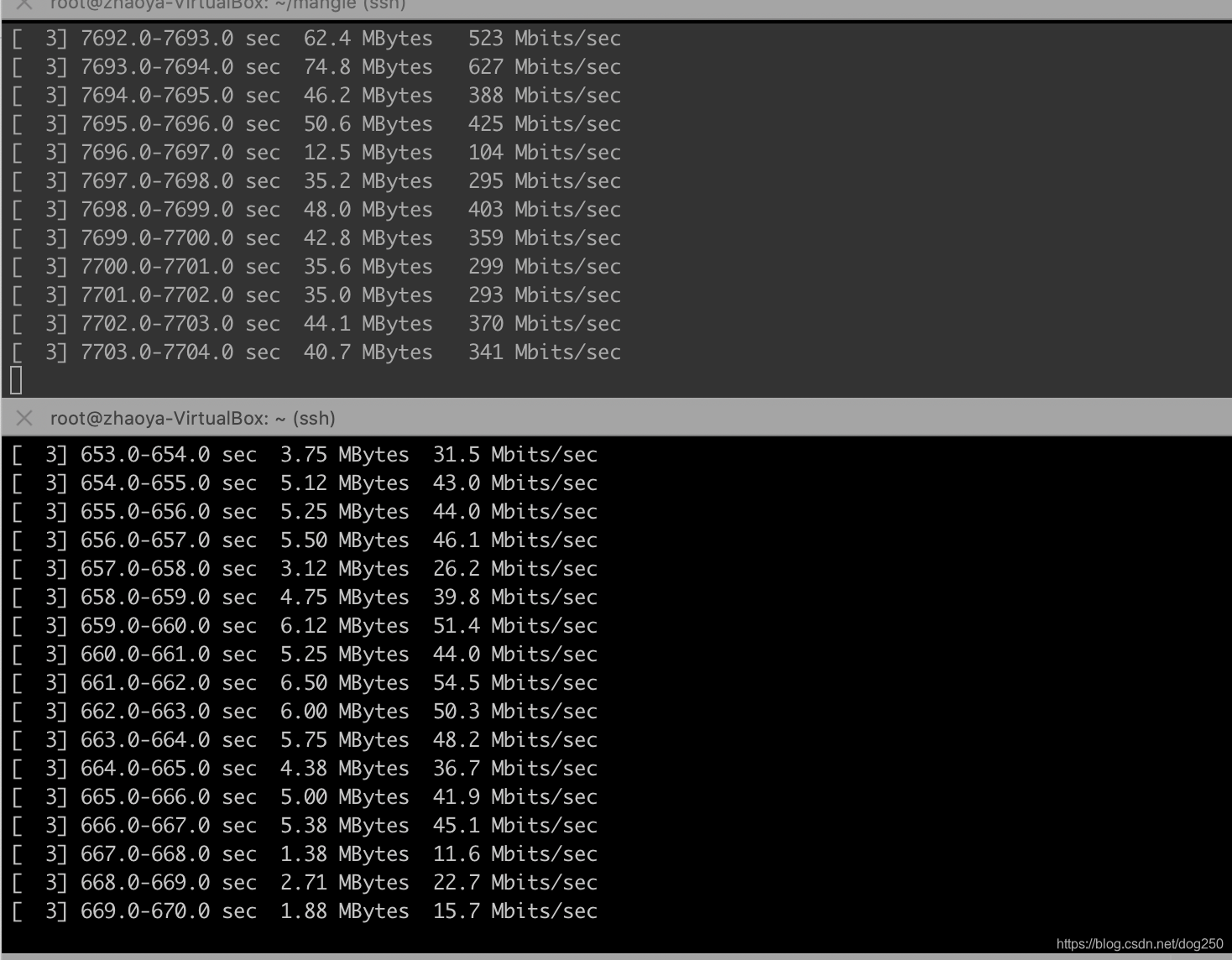
我想象不出除了靠运气,还有什么潜在的动力学可以保证这些流最终收敛到公平。
假设塞满整个pipe时两条流的BtlBw之比是 m n \dfrac{m}{n} nm,离开ProbeRTT状态进入ProbeBW状态时,除非二者分别一个up phase一个down phase,否则它们的BtlBw还将保持这个比例。
5 4 \dfrac{5}{4} 45和 3 4 \dfrac{3}{4} 43的均值是1,相当于什么也没有做。除非真的有空余带宽被加进来(有流退出或者路由重新收敛到更大带宽的路径)才会避免 3 4 \dfrac{3}{4} 43 down。
那么如何解决BBR的这个公平性问题?
按照控制论的观点, 效率和公平是不可兼得的。 为了增强公平性,就不得不损失点效率。
我们知道,离开ProbeRTT状态进入ProbeBW状态时,所有BBR流的BtlBw之和等于网络pipe的瓶颈带宽,没有任何空余的带宽空间可以用来执行公平性的工作,这个时候如果有流主动出让带宽,会被认为是 降低了带宽利用率 ,而BBR的广告词就是提高带宽利用率,主动降低带宽实则打脸。我们可以从BBR论文里的一段话里看出,它涉及到一个小优化(但我并没有在代码里看到它的实现):
Furthermore, to improve mixing and fairness, and to reduce queues when multiple BBR flows share a bottleneck, BBR randomizes the phases of ProbeBW gain cycling by randomly picking an initial phase—from among all but the 3/4 phase—when entering ProbeBW. Why not start cycling with 3/4? The main advantage of the 3/4 pacing_gain is to drain any queue that can be created by running a 5/4 pacing_gain when the pipe is already full. When exiting Drain or ProbeRTT and entering ProbeBW, there is no queue to drain, so the 3/4 gain does not provide that advantage. Using 3/4 in those contexts only has a cost: a link utilization for that round of 3/4 instead of 1. Since starting with 3/4 would have a cost but no benefit, and since entering ProbeBW happens at the start of any connection long enough to have a Drain, BBR uses this small optimization.
但是,若想保证公平,必须有流出让带宽,这样才能实现重分配。
问题是如何出让,出让多少呢?在我看来,在ProbeRTT状态和ProbeBW状态中间加一个Converge状态即可:
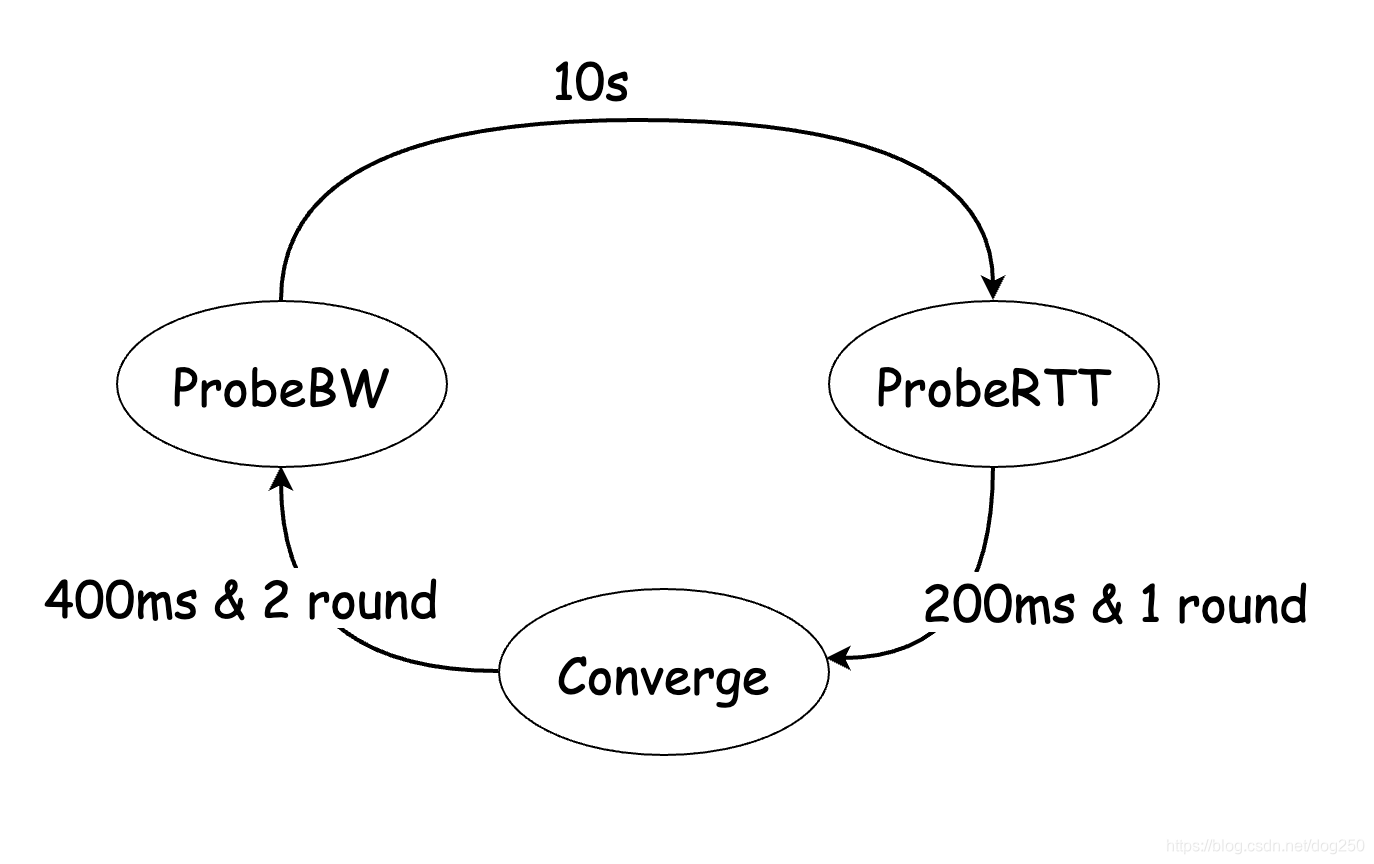
和ProbeRTT一样的思路,用一个比较短但又足够长的时间来range这个Converge状态的持续时间,比方说400ms(虽不优雅,但再来个800ms又何妨),在这个Converge状态,对pacing执行AIMD替代ProbeBW状态的 5 4 \dfrac{5}{4} 45, 3 4 \dfrac{3}{4} 43固定增益的up,down操作:
ai_up()
{
if (sub_state != up)
return;
pacing_rate += 10/RTprop;
if (is_full_length &&
(rs->losses || /* perhaps pacing_gain*BDP won't fit */
inflight >= bbr_inflight(sk, bw, bbr->pacing_gain))) {
sub_state = down;
bbr->pacing_gain = BBR_UNIT * 3/4;
}
}
md_down()
{
if (sub_state != down)
return;
bbr->pacing_gain = BBR_UNIT;
if (is_full_length ||
inflight <= bbr_inflight(sk, bw, BBR_UNIT)
sub_state = up;
}
到头来,其实Reno家族和BBR是一样的:
- Reno家族通过丢包被动发现收敛点。
- BBR通过ProbeRTT主动发现收敛点。
都一样,到达收敛点之后执行AIMD即可。
很多人所谓的魔改BBR都是扯淡,根本就不理解内在的机制,乱改一通而已。
当有人看到ProbeRTT状态只有4个窗口的时候,他们总觉得太少,总是手痒痒想加点儿,加到10?60?干脆75%吧…当他们看到200ms,10s,10轮的时候,忽而觉得时间太短,要么觉得时间太长,总之就是手痒。
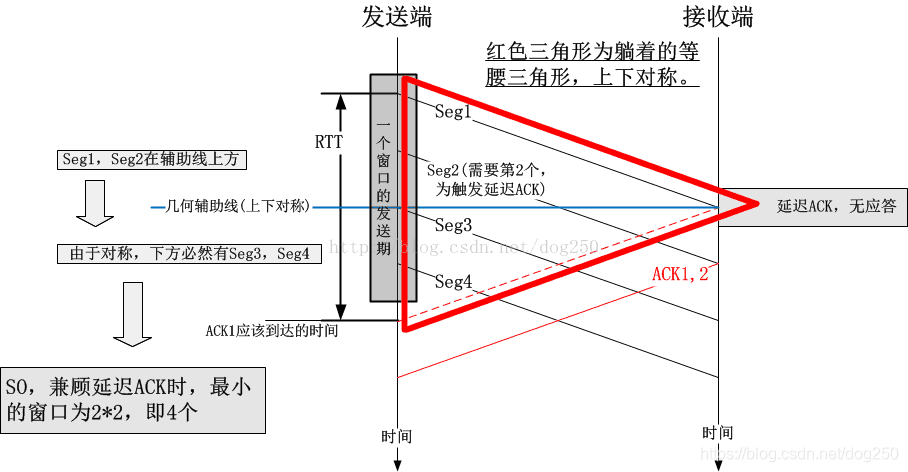
为什么是4?为什么不是2?为什么不是INIT_CWND?什么叫 Try to keep at least 4 packets in flight, if things go smoothly.
请参见:https://blog.csdn.net/dog250/article/details/72042516
经理正好走到办公室门口,滑了一下,滑跌了,可能是皮鞋底子不是牛筋底吧,但由于领带没有和西装固定在一起,所以领带保持在原来的高度,给人的感觉就是领带好像飞起来了一样,可是皮鞋的方向也变化了。
浙江温州皮鞋湿,下雨进水不会胖。