广播变量允许开发人员将 一个只读的变量缓存在每台机器上而不用在任务之间传递变量。广播变量可被用于有效地给每个节点一个大输入数据集的副本。
一个Executor只需要在第一个Task启动时获得一份Broadcast数据,之后的Task都直接从本节点的BlockManager中获取相关数据。
默认情况下task执行算子中使用了外部的变量时,每个task都会获取一份变量的副本,有什么缺点呢?在什么情况下,会出现性能上的恶劣的影响呢?

对于map这种数据结构,其存放数据的一个单位是Entry,还有可能会用链表的格式的来存放Entry链条,所以map是比较消耗内存的。如果任务资源给的到位,并行度调节的绝对到位且当前一共执行着1000个task,这些task里面都用到了占用1M内存的map数据,默认情况下map数据会拷贝1000份副本,然后通过网络传输到各个task中去。那么整体算总计有1G的数据会通过网络传输。
如上图所示,上面这种情况下网络传输的开销是比较大的,也许会占用spark作业运行的总时间的一小部分。另外,map数据副本传输到了各个task上之后是要占用内存的。1个map数据只有1M,确实不大,但是1000个map分布在你的集群中,一下子就耗费掉1G的内存。对性能会有什么影响呢?
不必要的内存的消耗和占用,就导致了在进行RDD持久化到内存时可能就无法完全在内存中放下,就只能写入磁盘,最后导致后续的操作在磁盘IO上消耗性能。
自定义的task在创建对象的时候,也许会出现堆内存放不下所有对象导致垃圾回收器频繁的回收。GC的时候,一定会导致工作线程停止,也就是导致Spark暂停工作一点时间。频繁GC的话,对Spark作业的运行的速度会有相当可观的影响。
上面举例的这种外部变量map还是小的,如果是从某个表里面读取了一些维度数据,比如大概100M左右的所有商品品类的信息,对应到1000个task上一共涉及到100G的数据网络传输。集群瞬间因为这个原因消耗掉100G的内存。
我们现在举例来说明外部大变量做成广播变量。
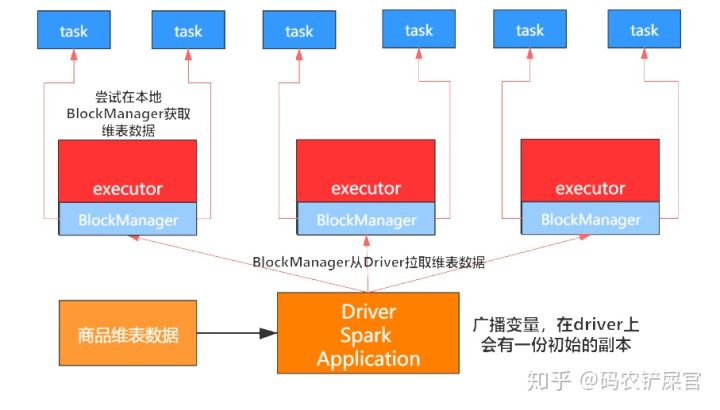
广播大变量
如上图所示, 广播变量初始的时候就在Drvier上有一份副本。
task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中尝试获取变量副本;如果本地没有,那么就从Driver远程拉取变量副本并保存在本地的BlockManager中;此后这个executor上的task都会直接使用本地的BlockManager中的副本。
executor的BlockManager除了从driver上拉取,也可能从其他节点的BlockManager上拉取变量副本,距离越近越好。
我们现在举例来说明外部大变量做成广播变量之后的优势:
假设当前我们一共有100个executor,2000个task。一个外部大变量map,大小为20M。
默认情况下,2000个task共计创建2000份副本。一共需要40G数据的网络传输,耗费40G的内存资源。
使用了广播变量情况下,100个execurtor共计创建100个副本。一共需要2G数据的网络传输,且这些网络传输不一定都是从Driver传输到每个节点,还可能是就近从最近的节点的executor的blockmanager上拉取到的,网络传输速度大大增加;对集群的内存耗费量也仅仅为2G。
在使用广播变量后,网络传输量以及集群内存占用量大大的降低了。其中网络传输性能消耗的降低了20倍以上;集群内存消耗减少了20倍。对性能的提升和影响,还是很客观的。
虽然说上述这种优化手段不一定会对性能产生决定性的作用。比如运行30分钟的spark作业,可能做了广播变量以后,速度快了2分钟,或者5分钟。但是一点一滴的调优,积少成多,最后还是会起到效果的。

3种Flink State Backend | 你该用哪个?
