
注意力机制、动态卷积最近几年被研究得非常透了,不过前述方法大多聚焦于特征图层面,而该文则是从权值角度出发提出了一种非常有意思的机制。该文所提方法仅作用于训练阶段,不会对推理造成任何的计算量消耗、网络结构改变,同时可取得媲美SE的性能提升,更重要的是它可以与SE相互促进。
论文:
http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123750086.pdf
Abstract
该文提出一种新颖的方法用于在训练阶段同时判别卷积神经网络权值的重要性并对重要权值赋予更多的注意力。更确切的讲,作者针对权值从两个方面进行重要性分析:幅值与位置。通过在训练阶段分析权值的上述两种特性,作者提出了两种独立的Weight Excitation(权重激励)机制。作者通过实验证实:在主流ConvNet上,在多个CV应用中,采用WE方法可以取得显著性能提升(比如在ImageNet分类任务上,可以提升ResNet50的精度达1.3%),而且这些改进不会造成额外的计算量或者网络结构调整。此外,只需很少的几行代码即可将其嵌入到卷积模块中。更重要的是,WE可以与其他注意力机制(比如SE)取得互补作用,进一步提升性能。
该文的主要贡献包含以下几点:
- 提出两种关于权值的特性用于刻画每个权值的重要性;
- 提出两种新颖的权值再参数化机制:通过调整反向传播梯度对重要权值赋予更多注意力,作者将这种训练机制称之为权值激励训练;
- 在多个任务(ImageNet、Cifar100分类任务,VOC、Cityscapes语义分割以及手势识别、姿态识别等)、多个ConvNet架构上验证了所提方法的优异性能。
Method
在这部分内容中,我们先来看探索一下权值重要性与幅值、位置的关系;然后再看了解一下作者所提出的权值再参数化方法。注:作者将位置相关的方法称之为LWE(location-based WE),将幅值相关的方法称之为MWE(Magnitude-based WE)。
Investigating the importance of weights
为探索权值的重要性,作者进行了权值影响的系统性分析(通过将权值置零)。作者研究了关于权值的两种特性:幅值和位置。为更好说明两者的重要性,作者采用ImageNet数据集上预训练ResNet50进行相应数据分析。

- Weight Magnitude。为探索权值幅值的重要性,作者通过如下流程进行了分析(结果见上图):
- 对于每个卷积权值按照绝对值进行升序排序;
- 将不同百分位的权值置零并记录模型性能下降情况。从上图可以看到:更高百分位的权值(即权值幅值更大)置零导致的性能下降更严重,这也就说明了权值的重要性随幅值变大而变大。
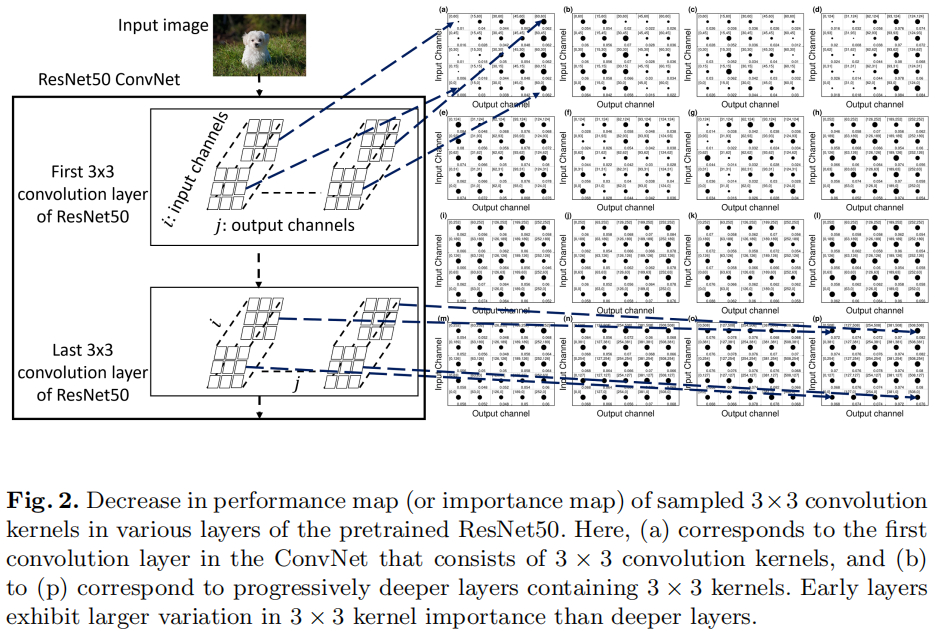
- Weight Location。为探索权值位置的重要性(见上图),作者通过如下方式进行了分析
- 选择预训练ResNet50中L个3x3卷积模块(L=16);
- 对每个所选择的3x3卷积模块( S l , l ∈ { 1 , ⋯ , L } S_l, l\in \{1,\cdots, L\} Sl,l∈{ 1,⋯,L}),选择 N 1 N_1 N1个输出通道( S l , O j , j ∈ { 1 , ⋯ , N 1 } S_{l,O_j}, j \in \{1, \cdots, N_1\} Sl,Oj,j∈{ 1,⋯,N1})
- 对每个所选择的输出通道 S l , O j S_{l,O_j} Sl,Oj,选择 N 2 N_2 N2个输入通道( S l , O j , I i , i ∈ { 1 , ⋯ , N 2 } S_{l, O_j, I_i}, i \in \{1, \cdots, N_2\} Sl,Oj,Ii,i∈{ 1,⋯,N2});
- 将上述所选择的输入通道对应的权值置零并记录模型性能下降情况 D S l , O j , I i D_{S_l, O_j, I_i} DSl,Oj,Ii.
- 注:作者设置的参数为 N 1 = N 2 = 5 N_1=N_2=5 N1=N2=5。结果见上图,也就是说ResNet每一个层将输出一个 5 × 5 5\times 5 5×5的下降情况数据,更高的下降数据意味着更重要的性能影响,也就需要进行保留并赋予高注意力。作者发现:浅层的下降波动更大,深层的下降波动较小,这也就意味着ConvNet不同位置的权值重要性是不同的,且浅层的权值重要性差异更明显。
Location-based weight excitation
正如前面所介绍的,卷积权值的重要性会随位置而发生变化,因此对于维度为 O u t × I n × h × w Out\times In\times h\times w Out×In×h×w的权值( h = 3 , w = 3 h=3,w=3 h=3,w=3),每个 h × w h \times w h×w权值核的重要性是可变的。为对不同卷积核赋予不同的注意力,作者设计了一个 O u t × I n Out \times In Out×In大小的注意力图 m ∈ R : m ∈ [ 0 , 1 ] m \in R: m\in[0,1] m∈R:m∈[0,1]用于调整卷积核的赋值。这就会导致更重要的权值具有更大的反向传播梯度。那么如何设计这样一个注意力图呢,一种最简单的方式就是将其参数化到卷积中,但这种方式将ConvNet的参数量变大(对于ResNet50而言,约提升60%参数量)。
作者提出采用一个简单的子网络,它以 I n × h × w In\times h\times w In×h×w权值作为输入并生成In个重要性注意力值,相同的子网络同时处理多路权值进而得到前述注意力图m。尽管该子网络可以具有多种不同的结构,作者选择了SE模块,定义如下:
m j = A 2 ( F C 2 ( A 1 ( F C 1 ( A v g ( W j ) ) ) ) ) m_j = A_2(FC_2(A_1(FC_1(Avg(W_j))))) mj=A2(FC2(A1(FC1(Avg(Wj)))))
与之对应的LWE结构如下图a所示,有没有觉得挺简单的呀,嘿嘿。
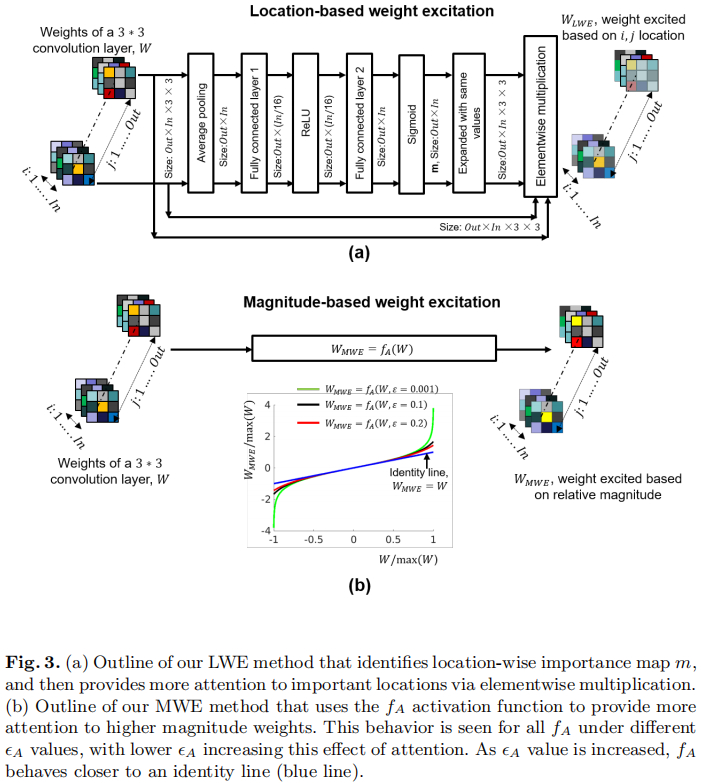
Magnitude-based weight excitation
前面已经介绍了LWE的原理,接下来就要介绍了MWE了。作者所提的MWE是一种新颖的激活函数 f A ( w ) f_A(w) fA(w),它以权值w作为输入,并赋予其不同的重要性注意力,定义如下:
w M W E = f A ( W ) = M A × 0.5 × l n 1 + w / M A 1 − w / M A w_{MWE} = f_A(W) = M_A \times 0.5 \times ln \frac{1+w/M_A}{1-w/M_A} wMWE=fA(W)=MA×0.5×ln1−w/MA1+w/MA
其中 M A = ( 1 + ϵ A ) × M M_A = (1+\epsilon_A)\times M MA=(1+ϵA)×M,而M表示权值的最大幅值, 0 < ϵ A < 0.2 0< \epsilon_A < 0.2 0<ϵA<0.2表示超参数。此时权值的梯度就变成了:
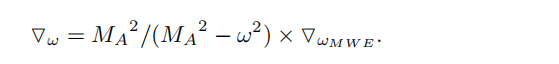
此外需要注意的是:对于LWE或MWE的输入权值,作者先进行了归一化,而这一操作可以导致ConvNet性能的轻微提升。注:WE仅作用于训练阶段,而不会造成推理阶段的额外计算量或网络架构调整。
Experiments
为说明所提方法的有效性,作者在ImageNet分类、VOC语义分割以及Mini-Kinetics姿态识别等任务上进行了验证。
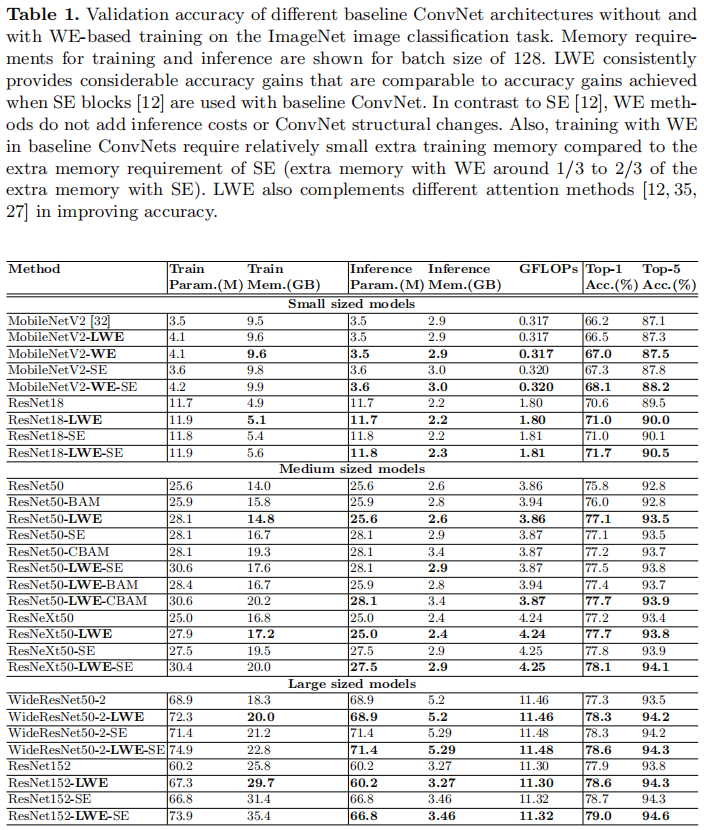
直接上结果了,ImageNet任务上的性能对比见下图。可以看到:在主流ConvNet上(如MobileNetV2、ResNet50、ResNeXt50、ResNet152-SE,Wide ResNet50)均可得到一致性的性能提升,且MWE的性能增益要比LWE增益低。作者同时发现:LWE对于深度分离卷积的增强并不好,这也是该方法的一个局限所在。与此同时,作者还将所提方法与其他注意力机制进行了对比,见下图b。相比SE,LWE的一个优势在于:提供同等性能增益同时具有更少的训练消耗、无需额外的推理消耗。
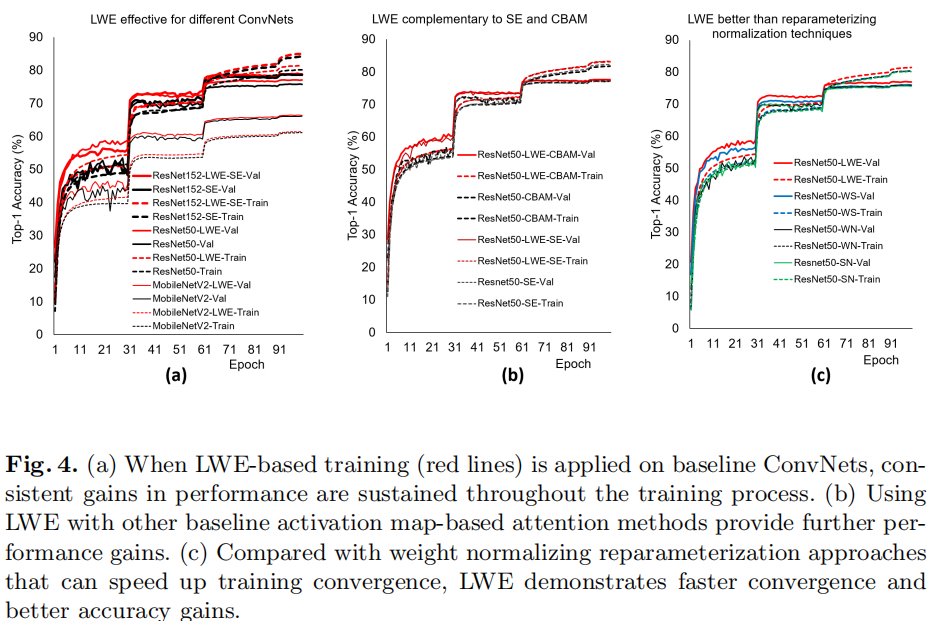
与此同时,作者还对比了所提方与其他规范化(如BatchNorm、GroupNorm)技术的性能差异。

最后,我们再来看一下所提方法在不同任务、不同架构上的性能增益对比,见下表。很明显,采用WE机制训练的模型均可得到一定程度的性能提升。

全文到此结束,更多实验结果与分析详见原文,建议各位同学去查阅一下原文。
原文链接:https://bbs.cvmart.net/articles/3250
专注计算机视觉前沿资讯和技术干货
关注极市平台公众号(ID:extrememart),获取计算机视觉前沿资讯/技术干货/招聘面经等
