什么是PID控制呢?想象热水器和汽车刹车,不会一直一个力度,它会逐渐变小,这个变化的过程需要受到控制,这就是PID控制存在的意义,根据最后的结果以及它的导数,来确定接下来的控制力度,这就是PID控制。但关键是,我们如何制造PID。


最终的控制目的是要保证水缸里的水位永远的维持在1米的高度。假设初始时刻,水缸里的水位是0.2米,那么当前时刻的水位和目标水位之间是存在一个误差的error,且error为0.8
如果单纯的用比例控制算法,就是指加入的水量u和误差error是成正比的。u=kp*error,假设kp取0.5
那么t=1时(表示第1次加水,也就是第一次对系统施加控制),那么u=0.5*0.8=0.4,所以这一次加入的水量会使水位在0.2的基础上上升0.4,达到0.6
接着,t=2时刻(第2次施加控制),当前水位是0.6,所以error是0.4。u=0.5*0.4=0.2,会使水位再次上升0.2,达到0.8,无限接近但不能达到1,但这并不是稳态误差,稳态误差是这个人并不会很精确地往里面投水,即控制精度问题,这个近乎无解。
也就是说,我的目标是1米,但是最后系统达到0.8米的水位就不再变化了,且系统已经达到稳定,因为精度问题已经检测不到了。比如控制汽车运动,摩擦阻力就相当于稳态误差。
于是,在控制中,我们再引入一个分量,该分量和误差的积分是正比关系。
由于这个积分项会将前面若干次的误差进行累计,所以可以很好的消除稳态误差(假设在仅有比例项的情况下,系统卡在稳态误差了,即上例中的0.8,由于加入了积分项的存在,会让输入增大,从而使得水缸的水位可以大于0.8,渐渐到达目标的1.0.)这就是积分项的作用。这也表明稳态误差往往是一种消耗力,最终结果往往小于预期结果。积分就是在最后突然一个猛进,就是这样。积分的控制特征就是如果调整太多微调就给他猛的一下,例如无限接近1,但达不到1,就猛地给他来一下。以越过静态误差。但是这样造成了震荡。
如何解决震荡,就是微分控制,当发现水缸里的水快要接近1的时候,加入微分项,可以防止给水缸里的水加到超过1米的高度,说白了就是减少控制过程中的震荡。是减少震荡的频率和幅度,而不是完全清除震荡。

本来加i就会让系统不稳定,加d就是为了减缓这种不稳定。但一般PI就足够用了。还是放水举例,现在缸里有0.4的水,一共1的水,误差是0.6,误差被输入到PID控制器,得到比例控制0.3,在积分微分修改0.3+x,这个信息就是接下来要放的水量,就是如此了。最后就到达1了。


可能就是调整值对整体情况的灵敏程度,用来进行微调。
差分进化算法基本思想是从初始种群开始,通过变异操作把种群中任意两个个体的向量差加权后按一定的规则与第三个个体求和来产生变异个体,然后将变异个体与当代种群中某个预先决定的个体进行交叉操作生成试验个体,最后通过选择操作在某个预先决定的个体和试验个体之间选择适应值较优的个体,通过不断地迭代计算,保留优良个体,淘汰劣质个体,引导搜索过程向最优解逼近。
 https://wenku.baidu.com/view/9129271f6f1aff00bed51efa.html
https://wenku.baidu.com/view/9129271f6f1aff00bed51efa.html
 https://wenku.baidu.com/view/aea46998172ded630b1cb6d2.html
https://wenku.baidu.com/view/aea46998172ded630b1cb6d2.html
遗传算法有两个重要控制参数——交叉率P.和变异率P。对算法的效率有较大影响
进化算法,也被成为是演化算法(evolutionary algorithms,简称EAs),它不是一个具体的算法,而是一个“算法簇”。遗传算法(Genetic Algorithm,简称GA)是一种最基本的进化算法。
个体的编码方式确定以后,针对上图操作的具体描述如下:
Step 1 种群初始化:根据问题特性设计合适的初始化操作(初始化操作应尽量简单,时间复杂度不易过高)对种群中的N个个体进行初始化操作;
Step 2 个体评价:根据优化的目标函数计算种群中个体的适应值(fitness value);
Step 3 迭代设置:设置种群最大迭代次数gmax,并令当前迭代次数g=1;
Step 4 个体选择:设计合适的选择算子来对种群P(g)个体进行选择,被选择的个体将进入交配池中组成父代种群FP(g),用于交叉变换以产生新的个体。选择策略要基于个体适应值来进行,假如要优化的问题为最小化问题,那么具有较小适应值的个体被选择的概率相应应该大一些。常用的选择策略有轮盘赌选择,锦标赛选择等。
Step 5 交叉算子:根据交叉概率pm(预先指定,一般为0.9)来判断父代个体是否需要进行交叉操作。交叉算子要根据被优化问题的特性来设计,它是整个遗传算法的核心,它被设计的好坏将直接决定整个算法性能的优劣。
Step 6 变异算子:根据变异概率pc(预先指定,一般为0.1)来判断父代个体是否需要进行变异操作。变异算子的主要作用是保持种群的多样性,防止种群陷入局部最优,所以其一般被设计为一种随机变换。
通过交叉变异操作以后父代种群FP(g)生成了新的子代种群P(g+1),令种群迭代次数g=g+1,进行下一轮的迭代操作(跳转到Step 4),直至迭代次数达到最大的迭代次数。
如何初始化种群呢?也就是编码,我们知道PID是三个参数控制的,究竟怎么控制就是一个函数,根据之前输出制定一个输入,输入到作用器中,产生我们想要的输出。
所谓的适应度,本质上可以理解为一个代价函数,或者一个规则,通过对初始种群中的个体计算适应度,能够得到对初始种群中的个体是否优劣的一个度量,就是评价函数。
选择操作是根据种群中的个体的适应度函数值所度量的优、劣程度决定它在下一代是被淘汰还是被遗传。选择就是取舍。
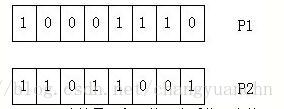
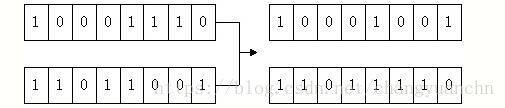
随机产生一个1到7之间的随机数,假设为3,则将p1和 p2的低三位进行互换,这个就是交换,交换后三位,就会产生新的,这叫后代。但这样如何保证收敛性呢?
随机产生一个1到8之间的随机数,假设为3,则将编码的第三位进行变异,将1变为0,这就是变异,但这样如何保证收敛性呢?
Radolph在文献[Radolph G. Convergence Analysis of Canonical Genetic Algorithms. IEEE Transactions on Neural Network, 1994,5(1): 96-101.]中证明了一般的遗传算法不一定收敛,只有每代保存了最优个体时才收敛。很明显,这样的算法每一代总会出现差的,即便收敛到普遍好,仍然会在每代出现几个差的,这是不可避免的。
进化算法包括遗传算法、进化程序设计、进化规划和进化策略等等,进化算法的基本框架还是简单遗传算法所描述的框架,但在进化的方式上有较大的差异,选择、交叉、变异、种群控制等有很多变化,进化算法的大致框图可描述如下图所示:
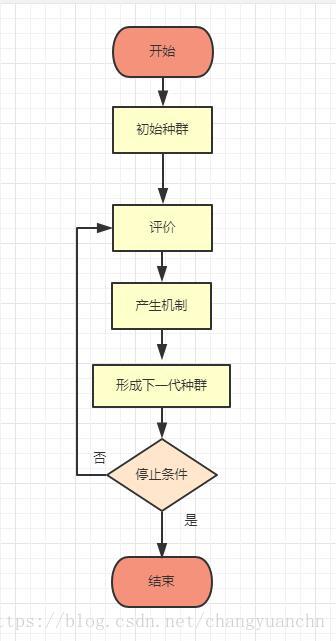
同遗传算法一样,进化算法的收敛性也是在保存最优个体时通用的进化计算是收敛的。但进化算法的很多结果是从遗传算法推过去的。
遗传算法对交叉操作要看重一些,认为变异操作是算法的辅助操作;而进化规划和进化策略认为在一般意义上说交叉并不优于变异,甚至可以不要交叉操作。
如何用进化算法求PID参数呢?
1 如何编码或者生成种群
2 如何变异,或者如何申请新的子代
3 如何计算适应度(重点介绍)
4 流程(流程图+文字说明)
你先看看进化算法该怎么做?其实很明显的,有图就足够了,但是如何进行编码和评价呢?
进行浮点数编码?计算种群个体适应度?
被控对象是一个函数,例如不同的电压对应不同温度,这两个是正相关关系,但不是线性关系,可能是任何其他正相关关系。
一般用ZN法确定范围。
但最开始为什么是一个阶跃信号呢?
阶跃信号就是突加给定,有一个跳变。对绝大多数系统来说,阶跃信号是一种比较严格的工作条件。因而,在经典控制的范畴,一般用阶跃响应来量化系统的性能指标。比如,上升时间与调节时间衡量快速性,超调量表达过渡过程的平稳性等等。那你还用不用阶跃信号?很明显初始的东西是自己设定的,其实设定的不是阶跃函数,而是一个差值,最后就会达到阶跃函数的最终值。误差变为极小。输入值是期望值,输出值是实际值,改变了世界了的。
因此必须有控制器,有负反馈,不然工作元件就会无脑做,这不行,最简单的控制器就是P控制器,进阶就是PID控制器。那么神经网络,或者进化算法如何施加到PID控制器上的?PID控制器控制工作元件,让元件正常工作,神经网络控制器控制PID控制器,使得元件工作更优秀,能自学习适应环境,这是神经网络存在的关键。
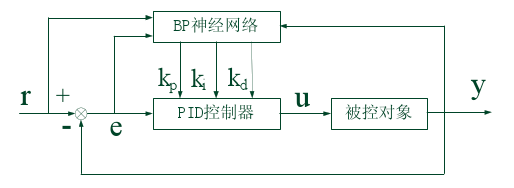
那么神经网络的损失函数是什么?首先我们知道输出是三个参数,而这个神经网络是实时加在生产环境的,期望输出是什么?r,实际输出是什么?y,用差值进行学习,就能学习出三个参数?你要知道,PID每次只接受差值作为接受的,那么它可能内部还会记忆过去的误差以实现积分与求导的效果,对,必然要积累这些误差。按理说神经网络应该跟标准PID参数进行求差从而反向传播。它是如何反向求导的呢?是求出y后与标准r的误差经过被控对象公式,导到PID控制器,然后上传到神经网络,这样就实现了修正参数。
拉普拉斯变换是工程数学中常用的一种积分变换,又名拉氏变换。 [1] 拉氏变换是一个线性变换,可将一个有参数实数t(t≥ 0)的函数转换为一个参数为复数s的函数。

好,那么继续考虑进化算法,编码的基因就是x=[xp,xi,xd],然后m个就可以了。
种群由M个染色体构成,为X(M,3)矩阵.
初始染色体中的基因在[0,1]范围内随机产生.
(3)基因交又率与变异率计算.
在X(M,3)矩阵中逐列选中基因,按式(1)计算对应平均欧氏距离,再按式(2)求出对应的交叉率和变异率。
(4)进化操作.先复制种群.在复制的种群中,按各列基因对应的交叉率和变异率逐列进行基因的交叉(采用算术交叉)和变异(在[0,1]区间随机地产生一个数来取代原有值),形成M个子代染色体.
然后,进行同一世代染色体的评价与选择.将染色体逆映射于PID参数空间获得对应的PID参数,然后将PID参数代人仿真程序计算阶跃响应及评价函数J.选出其中J值最小的M个染色体构成新种群,并显示本世代的最佳染色体的评价值.
(5)过程结束判定.如果gen<MAXGEN,回到步骤(3)重复进行;如果gen≥MAXGEN,则存贮最佳染色体.绘制最佳染色体的输出响应曲线,结束求解过程.
再看看进化算法的普遍实现过程,适应度是什么呢?交叉率和变异率是怎么回事呢?
| 比如种群长度为6,20个种群,交叉概率为0.7对此种群的意义是什么? 变异概率又是什么意思啊? |
| 20个染色体中,每两个染色体从第一位到第六位的代码都有0.7的概率交换交叉点前后的染色体代码! |
emmm,说实话并不会代码的编写。。。
弄懂进化算法,能写出代码
求出所有适应度,找出最佳适应度(就是这个),那么适应度函数是什么呢?很明显,就是用这个参数得出的最终结果与预期结果的p1范数或者p2范数,就是如此了。
变异,交叉,选择,有没有改变种群规模?预计没有,但是问题不大。
那么整体看来,进化算法是用在运行环境,实时修改,还是之前弄好的?它是有一个收敛过程的,BP神经网络也是有收敛过程啊?但进化算法收敛过程是中心,应该不是,应该就是求出一个稳定的PID,它是前馈的。
实现matlab代码,画出图像
写报告
算了,不搞了,两天了,真学不会。。。没办法,意义也不大。
看看论文模板。