脑瓜子嗡嗡的小刘炼丹之路—PointNet论文解析
小刘最近摸鱼的时候,看了一篇关于point (点云,目前在自动驾驶,激光雷达中用的蛮多的)的paper,感觉非常好玩,然后就在这里唠嗑一哈论文!虽然论文是2017年的,但是想一下VGG现在不都还用的蛮好的嘛,经得住时间考验嘛。部门的这边大哥说,PointNet非常的简单,也确实就maxpooling,还有T-net()。emmmmm~~~ 读论文嘛,一千个读者,就有一千个哈姆雷特啦。哈哈哈,因此每个人的理解也是不同的啦!!!芜湖,✈!(我这里可能有点translate那味,有什么不对的,希望各位大佬指正~记得悄咪咪的发§(* ̄▽ ̄*)§)
前言(Preface)
PointNet的由来是Charles R. Qi* & Hao Su* & Kaichun Mo & Leonidas J. Guibas ,在2017年发表的研究3D的paper: 《PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation》 。其中PointNet的基本思想,学习其输入点云(point)的每一个点对应的空间编码,之后再利用所有点的特征,得到一个全局的点云特征,并且基于均匀采样的点云进行训练。
1、未考虑局部特征的处理,只使用了全局特征;
2、在实际的场景中,point的疏密程度不同,因此在实测效果准确率较低;
(这些在PointNet++中有所改善)
摘要(Abstract)
1、通常的做法:将数据转换为规则的三维体素网格(3D voxels)或者图像集合(collections of images)。
2、paper中直接提出一种新型的直接消耗点云的神经网络。
(传统的在数据庞大的情况下,会很鸡肋。在paper中提出的新网络,避免了网格的组合不规则和复杂性,因此更容易学习,并且网络更为简单。)
1、介绍(Introduction)
1、主要介绍了如何使用DL去推理3D几何数据,Traditional CNN需要高度同一的数据格式,以便于优化内核和共享权值。而point是不同的格式,在输入网络结构之前,需要转换为regular 3D voxel grids 或 collections of images (这样数据会complex,并且掩盖数据的不变量)。
2、综上所述,作者就提出了一个PointNet的网络结构,其避免了不规则性和复杂性,因此更加的容易去学习。而因为point是简单的数据结构,并且为点集中的一员,所有在计算的时候,也需要考虑点云的不规则性、无序性和刚性不变性等问题。
3、PointNet直接以点云为输入,输出则为label,在网络架构上,PointNet非常的简单,开始每一个点都是被单独的处理,后网络会学习感兴趣点,并encoding,在最后几层的全连接(FC layers)层,则将这些的信息综合作为全局特征。PointNet在基本设置中,每个点仅由它的三个坐标(x,y,z)表示。其他额外的维度,可以通过计算法线和其他局部或全局的功能补充。
4、PointNet关键只是使用了maxpooling(在实验的时候作者似乎做了sum pooling 和average pooling),以及有效的网络学习的一组优化的功能/标准,最后就是FC层。
PointNet-task如下图:
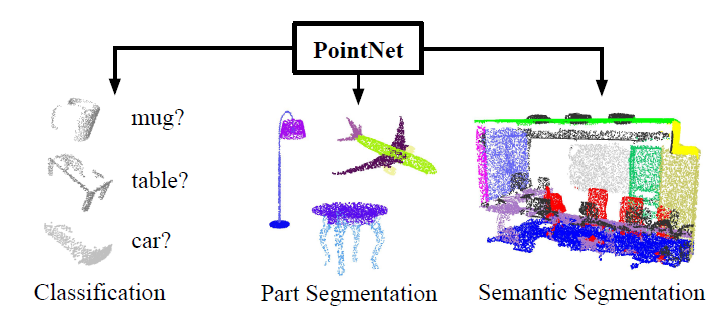
6、主要是讲述其在PointNet论文中作者主要做出的贡献,以及网络的优势。概括如下:
1) 进行了理论和实验的分析,证明了PointNet能够连续的逼近,任何连续行数;
2) 该网络学会采用稀疏关键的来进行分类;
3) 对于小的干扰以及离群点,其都有较好的鲁班性;
4) 在许多的dataset上进行分类、分割、语义效果都较好,并且泛化能力好等特点。
然后后面就是作者完成的贡献,这一部分就不介绍了,哈哈哈哈,反正就是能往好的写就往好的写。写论文通式!(✿◕‿◕✿)
2、相关工作(Related Work)
1、点云特征(Point Cloud Features)
1) 无序性:一团点云数据中有很多个点数据,这些点在点云文件里无论以什么顺序出现,它们指代的信息并不改变,因此,PointNet使用对称函数—maxpooling,来提取点云中的数据特征。
2)不变性:就是在某些编码如刚性变换后,其基本的特征(shape)不会发生改变。paper在进行特征提取之前,先对点云数据进行对齐来保证不变性。通过训练一个小型的网络得到一个旋转矩阵,用这个矩阵与点云数据相乘来实现对齐操作。
2、DL在3D上的运用
paper 中介绍了5中方法:
①、Volumetric CNNs:第一个提出来的,但是数据稀疏计算能力不强导致该种方法的像素精确度并不是很好。
②、FPNN and Vote3D:解决了稀疏性问题,但是还有稀疏性问题,处理起来大的点云依然捉襟见肘。
③、Multiview CNNs:将3D转到2D,再用2D去做卷积,但是在某些特点的task上差人强意。
④、Spectral CNNs:对mesh应用光谱CNN,但是只能用在流形mesh上面比如有机对象,对于一些非等距的物体比如家具就不是很适合。
⑤、Feature-based DNNs:第一次把3D的数据特征格式转化成一个向量,然后用一个全连接层对其分类,但是我们认为这种方法受限于这些特征数据的表达力度。
3、问题陈述(Problem Statement)
PointNet输入为一个没有做处理的point数据,许多点组成了一个集合,每一个用特征向量来表示,其可以描述为(x,y,z)和一个颜色通道等信息。但是文章只使用了(x,y,z)这三个信息。
对于分类任务来说,输入的点云要么从形状中采样,要么就是从场景点云中分割,最后的输出就是k个score。对于语义分割,输入可以是用于部分区域分割的单个对象,也可以是来自三维场景的用于对象区域分割的子集。而这种输入就是为n个点和m个语义,输出得分为n*m。
4、点集在深度学习上(Deep Learning on Point Sets)
先了解的一下这里的 R {R} R 代表什么, R {R} R :实数域。对任意一个正整数n,实数的n元组的全体构成了 R {R} R 上的一个n维向量空间,用 R n {R}^{n} Rn 表示,有时候称为实数坐标。理解为欧氏空间了,单纯的认为是空间坐标系啦,n为维度。详细的,大哥们可以看一下欧几里得空间。
4.1、 R n {R}^{n} Rn 中点集的性质(Properties of Point Sets in R n {R}^{n} Rn )
①点集的无序性
②点之间的相互作用
③刚性不变性
这些在前面都介绍过了,①③在这里就不重复介绍了。②:这些点来自具有距离度量的空间,因此每个点都不是孤立的,每个相邻的点构成了子集,在计算的过程中需要考虑局部结果的相互作用。
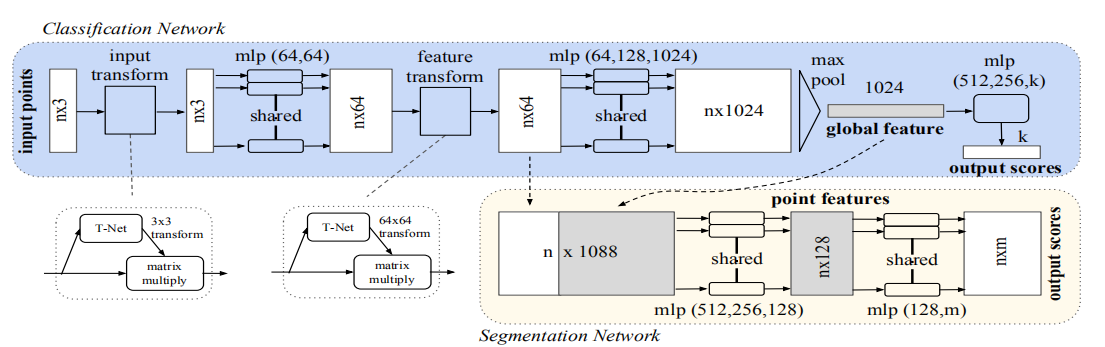
4.2、PointNet网络结构(PointNet Architecture)
1、其输入为一帧的全部点云数据,表示为n*3的二维tensor,n代表着 点云的数量,3为(X,Y,Z)空间坐标;
2、输入数据先通过和一个T-Net学习到的转换矩阵矩阵对齐(这个我看别人的博客说他的作用不大),这样保证了模型对特定空间的不变性;
3、通过多次MLP对点云进行特征提取,再用一个T-net来对其对齐。(T-Net是Input Transformer network & feature transform的部分,它的任务是产生一个仿射变换矩阵,然后利用这个矩阵进行矩阵变化);
4、将得到的各个维度上特征输入maxpooling层,得到最终的全局特征(global feature);
5、对分类(Classification)任务、将全局特征通过MLP来预测最后的分类分数;
6、对分割任务,将全局特征和之前学习到的各点云的局部特征进行串联,在通过MLP(多层感知网络)得到每个数据的分类结果。
pointnet网络架构,如下图:
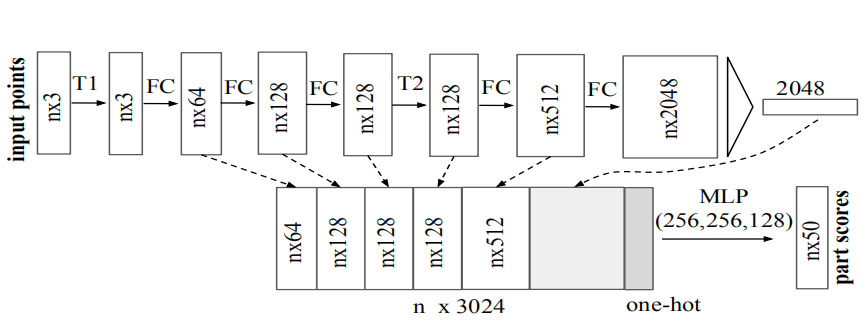
4.2.1、如何处理无序性(Symmetry Function for Unordered Input)
paper主要提出了3点:
1、将输入排序规范,但是会存在w.r.t扰动(这里的w.r.t我也不知道是什么,失策!);
2、将输入作为序列,先对数据进行增强(将所有的刚性考虑到),再输入RNN中;
3、设计一个对称函数(maxpooling),将所有的点通过这个平衡函数聚合起来,其输入为n个点输出为一个与输入顺序相同的新向量(不变性)。
作者表示虽然RNN在较小序列的输入排序下,具有较强的鲁棒性,但是千条以上的数据,会影响性能,因此作者采用了第三种方式,通过MLP(多层感知机:multi-layer perceptron network)学习得到h,再用单变量函数(single variable function) 和maxpooling来得到g,通过不同的h,可以学习得到表征不同属性的多个f。
PointNet采用的是maxpooling。
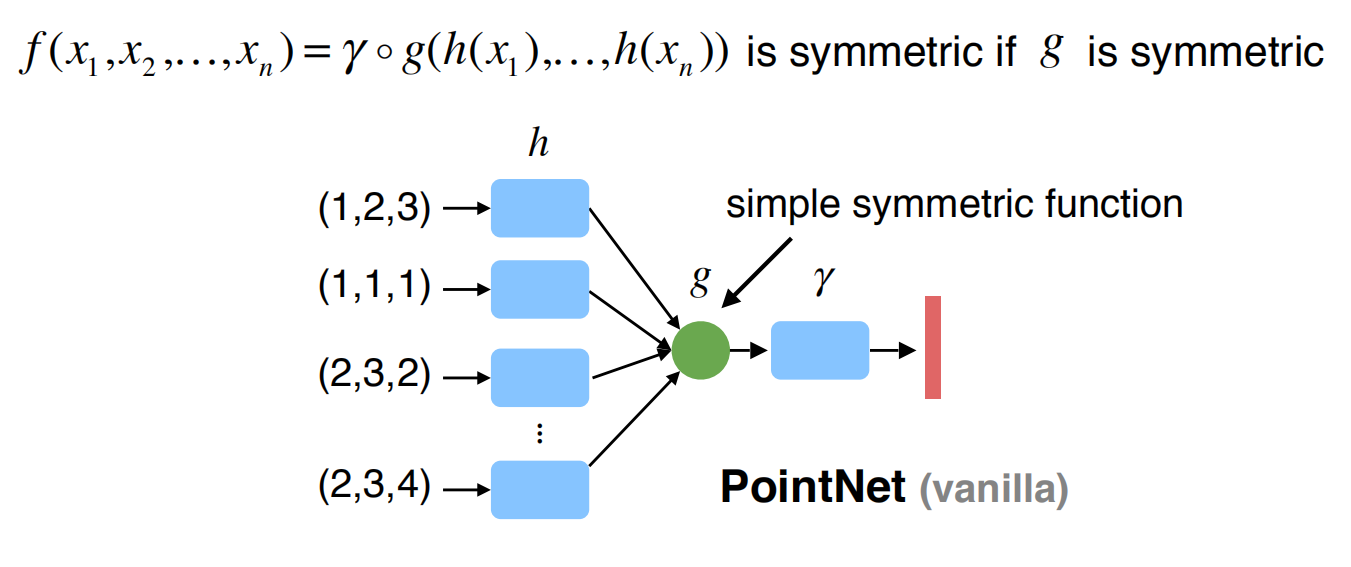
X:point中的某个点,h:特征提取层,g:对称方法,γ:更高维度特征提取
4.2.2、聚合局部与全局信息(Local and Global Information Aggregation)
作者在paper中写道,对上述的输出向量 [f1,...,fK],可以直接采用svm和MLP来对全局特征进行分类,但是对于point分割问题,就需要结合局部和全局特征的组合来。paper中的做法是,将全部级联在每个点的局部特征后面。在此基础上再学习得到新的点局部特征,这每个点特征知道局部和全局信息了。
4.2.3、联合对齐网络(Joint Alignment Network)
不论point如何变换下,作者希望point set学得到的东西还保留着语义label信息,是不变的。paper中提出了两种方法:
1)、特征提取前,将所有输入几何整合到标准空间中,以空间变换的思想,通过采样和插值对准2D图像,再在GPU上的特定层学习。
2)、采样较小的网络T-net来预测point的仿射变换矩阵,并且将其并将其直接应用到原始点云坐标系。因此,作者在这里引入了T-net,来做transform。
同样的思想也可以用于特征空间,即用于整合不同点云得到的特征。然而,由于特征空间下的变换矩阵维度要远远高于原始空间,为了降低最优化的难度,作者在softmax训练损失的基础上,添加了一个正则项:
L r e g = ∣ ∣ I − A A T ∣ ∣ F 2 L_{reg}=\left || I-AA^T \right ||^2_F Lreg=∣∣∣I−AAT∣∣∣F2 A:为微型网络预测的特征对齐矩阵,该正则项要求学习得到的矩阵是正交矩阵(正交变换不会丢失输入的信息)。
4.3、理论分析(Theoretical Analysis)
先了解下Hausdorff distance(豪斯多夫距离):量度度量空间中真子集之间的距离,另一种可以应用在边缘匹配算法的距离,它能够解决SED方法不能解决遮挡的问题。
假设: f : x → R \begin{aligned}f:x→{R}\end{aligned} f:x→R
在Hausdorff距离 d H ( ⋅ , ⋅ ) \begin{aligned}d_H(·,·)\end{aligned} dH(⋅,⋅)为连续函数。 ∀ ∈ > 0 , ∃ \begin{aligned}∀_∈>0, ∃\end{aligned} ∀∈>0,∃一个连续函数h和一个对称函数 g ( x 1 , . . . , x n ) = γ ο M A X \begin{aligned}g(x_1,...,x_n)=γοMAX\end{aligned} g(x1,...,xn)=γοMAX,对于任何 s ∈ x \begin{aligned}s ∈ x\end{aligned} s∈x。
∣ f ( s ) − γ ( M A X x i ∈ S { h ( x i ) } ) ∣ < ∈ |f(s)-γ(MAX_{x_i∈S}\lbrace h(x_i)\rbrace)|< ∈ ∣f(s)−γ(MAXxi∈S{
h(xi)})∣<∈ 其中 x 1 , . . . x n x_1,...x_n x1,...xn是S中任意元素的完整列表,γ是连续函数, M A X MAX MAX是以n个向量为输入,并返回元素最大值的新向量。
定理1:
证明了神经网络对连续集函数的普遍逼近能力,并且PointNet网络能够拟合任意的连续集合函数,同时如果maxpooling中存在足够的神经元,K个,那么模型的表达能力就越强,可以近似任意的f。
作者从理论和实验上发现,PointNet受限于maxpooling中的维度,即K的影响。并且定义了 U = M A X x i ∈ S { H ( x i ) } U=MAX_{x_i∈S}\lbrace H(x_i)\rbrace U=MAXxi∈S{
H(xi)},为f的子网络,其将在 [ 0 , 1 ] m [0,1]^m [0,1]m的点映射到K维向量上,因此得出了定理2;
假设: u : X → R K u:X→{R}^K u:X→RK,如 U = M A X x i ∈ S { H ( x i ) } U=MAX_{x_i∈S}\lbrace H(x_i)\rbrace U=MAXxi∈S{
H(xi)} 和 f = γ ο u f=γοu f=γοu,得:
(a) ∀ S , ∃ C S , N S ⊆ X , f ( T ) = f ( S ) i f C S ⊆ T ⊆ N S ; ∀S,∃C_S,N_S\subseteq X,f(T)=f(S) ifC_S\subseteq T\subseteq N_S; ∀S,∃CS,NS⊆X,f(T)=f(S)ifCS⊆T⊆NS;
(b) ∣ C S ∣ ≤ K |C_S|≤K ∣CS∣≤K
定理2:
(a) 表示如果 C S C_S CS中的所有点都被保留,则 f ( S ) f(S) f(S)直到输入损坏是不变的;它还随着直到 N S N_S NS的额外噪声点而不变。
(b) 表示 C S C_S CS仅包含有界数,由K确定。换言之, f ( S ) f(S) f(S)实际上完全由有限或不等于K元素的有限子集 C S C_S CS决定。
因此,我们称 C S C_S CS为S的临界点集,称K为 f f f的瓶颈维数。PointNet通过总结这些物体的关键点来判断物体的类别,这样体现了PointNet对数据缺失和噪声的鲁棒性。作者列出了几个sample得关键点,如下图所示:

5、实验(Experiment)
这一部分作者主要分为了四个子任务来进行实验论证:
1)展示了PointNet可以用于多个3D任务
a、分类( Classification)
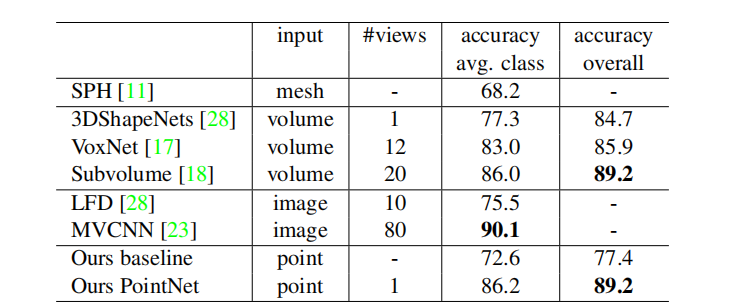
在ModelNet40的分类基准上评估该模型,采用二八分的思想(广泛接受的数据集划分思想),来对模型进行测试(testing)和训练(training),并训练的过程中进行数据增强,引入高斯噪声。作者采用直接处理point:在网格面上均匀采样1024个点,并且归一化在球面上。PointNet虽然推理速度快,但是相比于MVCNN还是存在着差距,在表[1]中可以看出。
b、分割(Segmentation)
在ShapeNet的分割基准上评估模型,采用的是mIoU的评价指标,计算groundtruth和prediction之间的关系,为empty计为1。然后计算C类各个类型的平均值,得到各个类型的IoU。(emmmmm,这个我也不是很了解!>﹏<)
分类的结果如表[2]所示。
c、语义(Semantic Segmentation)
从Stanford 3D semantic parsing data进行模型的评估,(PointNet的语义分割是在其分割的基础上转变而来的,部门的大哥说这个做的不是很好,在PointNet++上似乎解决的这个问题。) 作者为了准备训练数据,我们首先按房间分割点,然后将房间分成1m×1m的小块。每个点由XYZ、RGB和房间归一化位置由9-dim的向量表示(从0到1)。training:随机在在每个区块上抽样4096 points。testing:对所有的点进行预测。PointNet使用MLP作为分类器。结果如表[3],可以得出PointNet方法显著优于基线法。并且PointNet能够输出平滑的预测,并且对缺失点和遮挡具有鲁棒性.
[2]、Segmentation results on ShapeNet part dataset.(state-of-the-art in mIoU)
 [3]、Results on 3D object detection in scenes.(Iou=0.5)
[3]、Results on 3D object detection in scenes.(Iou=0.5)
a、为什么使用MLP
由下图可得,在ModelNet同一数据集评估下,使用Maxpooling其accuracy较高。
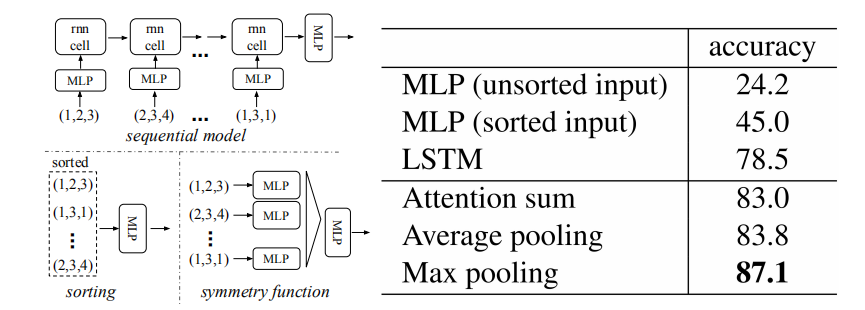
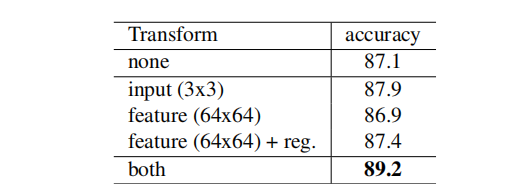
在其他结构合理化的情况下,添加T-net,在同一测试数据上,提升了0.8%的准确度,若在添加正则化,其结果会更好。
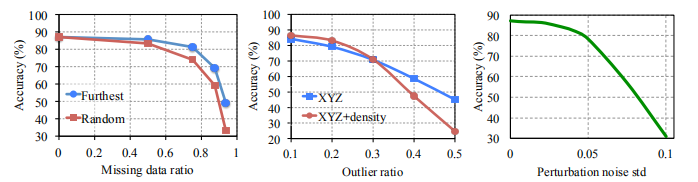
作者将一些损失点云信息做测试,当损失50%的点,准确度仅仅下降了2.4%-3.8%;而对增加一些随机点的情况,鲁棒性依然很好。作者做了两个实验,一个是特征设成3维坐标形式,另一个是三维坐标形式外加一个点密度。事实证明,即使有20%的外部点参与,准确度依然可以达到80%以上。
可视化网络在前面的定理二介绍了,这里就不说了,码字太累了。详细的可以看前面,实在不行阔以,去读一下paper原文!
4)分析了时间和空间的复杂度
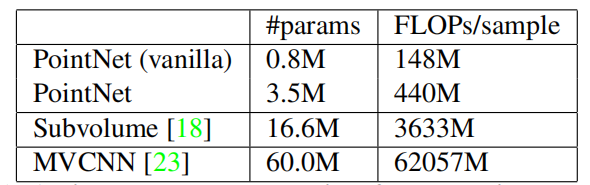
将PointNet与MVCNN和Subvolumn进行了对比,三者在ModelNet40上的accuracy都非常的高,但PointNet的时间复杂度和空间复杂度都是O(N),是线性增长的,而MVCNN和Subvolumn在卷积占计算时间的主导地位,而时间复杂度直接取决于输入图像的分辨率,因此是呈现立方增长。
时间复杂度上面,PointNet可以每秒处理超过100万个点的图像分类,大概是1千个物体的检测,或者也可以在全景分割上每秒处理2间屋子,分别领先上述两种算法141倍,8倍。空间复杂度上面,PointNet只用了350万参数,领先两种算法17倍,4倍。 从经验上讲,PointNet能够在TensorFlow上使用1080XGPU每秒处理100多万个点,用于点云分类(大约1K个对象/秒)或语义分割(约2个房间/秒),显示出巨大的实时应用潜力。其中PointNet (vanilla) 是表示去掉T-net后的PointNet网络,更为轻便。(这一步复现,我正在做!!!哈哈哈,应该快了。)
6、总结(Conclusion) !!!
本文中作者提出了一种新的深度神经网络PointNet,它直接消耗point。其网络为许多3D recognition tasks提供了一种统一的方法,包括对象分类、分割和语义分割,同时在标准基准上获得了比艺术状态更好的或更好的结果,并且还为理解PointNet提供了理论分析和可视化。
paper中使用softmax来做分类器的。
总体流程可以如下所示:
T-net在整个网络空间中做出了两次对齐操作,简单的来说,就是做了数据的规范。
maxpooling则是抽取数据中的主要特征,简单的来说,就是去除做了MLP中的不必要的特征。
softmax则是在多分类问题中常用的,可以理解为做概率的,其总和为1。
作者后面还添加了一系列的补充,如:PointNets与VoxNet比较、网络架构细节、PintNet分割网络细节、管道细节。想要了解的可以去看一下原文,挺有意思的一篇paper了!ヾ(•ω•`)o
如果我有什么说的不对的地方,请阅读的大哥们一定要指出来,谢谢大哥们了!!!(写到这,恍然大悟,那个w.r.t可能是空间编码???)
脑瓜子嗡嗡的小刘的其他想法
不同的应用场景,使用不同方式,从目标检测的角度来说,在图像上目标检测已经非常实用了,如开源的YOLO系列,SSD系列,RCNN系列等,都是一些优秀的网络架构了,基本上可以满足大多数的常规识别任务了。但是这些二维检测任务的性能虽然已经非常的实用化,那如果是从自动驾驶的角度来看,相比于基于图像的目标检测,基于三维点云的目标检测更接近实用.
而点云的采集方式基本上为为激光雷达采集(3D建模),简单来说点云(point)是用各种设备仪器采集得到的数据集合。point其在40年代雷达检测就出现了,而随着传感器和光学的发展,这一块的研究也随之更多了,如测绘,自动驾驶,医疗和VR等等。\( ̄︶ ̄*\))
 |
 |
参考文献(references):
[1].PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
[2].Frustum PointNets for 3D Object Detection from RGB-D Data
[3]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
[4].stanford pointnet
[5].cvpr17_pointnet_slides
[6].维基百科—欧几里得空间
[7].维基百科—郝斯多夫距离
[8].美团无人配送-PointNet系列论文解读
[9].phosphenesvision
代码链接(Code link):
Tensorflow :
https://github.com/charlesq34/pointnet
https://github.com/charlesq34/pointnet2
pytorch:
https://github.com/yanx27/Pointnet_Pointnet2_pytorch
https://github.com/erikwijmans/Pointnet2_PyTorch
脑瓜子嗡嗡的小刘,是某造车新势力的一名自动驾驶图像算法实习生。同时小刘也是一枚热衷于人工智能技术与嵌入式技术的萌新小白。小刘在校期间也参加过许许多多的国内比赛(主要是嵌入式与物联网相关的),要是大哥们有什么问题,可以随时Call me,希望能和大哥们共同进步!!!同时也希望大哥们看文章的时候也能抽空点个赞!谢谢大哥们了!!!(づ ̄ 3 ̄)づ