前言:基于人大的《数据科学概论》第六章的内容。主要提纲为:流数据处理应用、流式处理和批处理的区别、流数据模型、数据流上的查询、流数据处理系统的查询处理、查询处理的基础算法、流数据处理系统。
一、流数据处理应用
有一类数据密集型应用,数据快速到达,转瞬即逝,需要及时进行处理。
应用在:
- 网络监控
- 电信数据管理
- 工业制造
- 传感器网络
- 电子商务
- 量化交易等
二、流式处理和批处理的区别
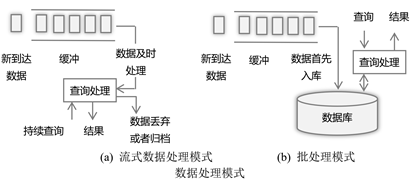
简说:流式处理是针对批处理来讲的,即它们是两种截然不同的数据处理模式,具有不同的特点,适用于不同的场合。不能简单地认为两种截然不同的数据处理模式优于另外一种数据处理模式。
1、批处理
对于批处理来讲,首先数据库不断地采集,保存到数据库中(不一定是关系数据库,可以是HBase或者Hive数据库),然后进行分析处理(包括SQL查询)。批处理适用于对大量数据进行处理的场合。人们需要等到整个分析处理任务完成,才能获得最终结果。
2、流式处理
- 在流式数据处理里,数据持续到达,系统及时处理新到达的数据,并不断产生输出。
- 处理过的数据一般丢弃掉,当然也可以保存起来。
- 流式数据处理模式,强调数据处理的速度。
- 部分原因,是因为数据产生的速度很快,需要及时进行处理。
- 由于流式数据处理的趋势,能够对新到达的数据进行及时处理,所以它能够给决策者提供最新的事物发展变化的趋势,以便对突发事件进行及时响应,调整应对措施。
三、流数据模型
简说:在流数据模型中,将要进行处理的数据,从一个或者多个上游数据源,持续不断地到达,而不是从保存在磁盘或者内存中的数据源,进行随机地存取。
流数据模型和传统的关系模型的区别:
- 数据流的数据元素持续到达
- 流数据处理系统,不能控制数据元素到达的顺序
- 数据流可能是无限的,或者说数据流的大小是无限大
- 数据流的一个数据元素被处理后,可以丢弃或者归档,一般不容易再次提取,除非目前该数据元素还在内存中。能够保存在内存中的数据元素,相对于整个数据流来讲,是极少量的数据。
四、流数据上的查询实例
数据流上的查询和传统数据库上的查询的区别
(1)一次性查询和持续查询
一次性查询,指的是在数据集的某个时刻的快照上执行的查询,对数据进行分析,获得结果后,返回给用户。持续查询,则是在一系列持续到达的数据流的数据元素上执行的查询,它产生一系列结果,这些结果是根据查询不断执行时,不断看到的新数据而产生的。
(2)预定义查询和即席查询对系统的影响
预定义查询:一般是持续查询,当然也可以预先定义一些一次性查询。即席查询:则是在数据流的数据开始流动起来,数据不断到达的时候,才提交给流数据处理系统的。- 即席查询可以是一次性查询,也可以是持续查询,即席查询使得系统的设计和实现复杂化了。
五、流数据处理系统的查询处理
5.1内存需求
- 大部分数据流,是无法预知其最终大小的,或者说数据流的大小(记录数量)可能是无限的。在这种情况下,如果要在数据流上计算一个准确的结果(比如累计数),需要的存储空间将无法预知,有可能超过可用的内存。
- 在某些流数据处理应用中,新数据以极高的速率到达,以至于老数据都还没有来得及处理。我们需要尽量降低处理每个数据元素的时间,每个数据元素要处理得够快,否则流数据的处理,跟不上数据到达的速度。为了达到高速的数据处理,流数据处理系统一般优先采用基于内存的数据处理算法,无需存取磁盘。
5.2近似查询结果
在内存容量有限的情况下,获得一个准确的结果,是不太可能的。正好,在很多应用场合,我们无需一个准确的答案。近似的查询结果,只要足够好,可以作为准确结果替代。
5.3滑动窗口
从数据流上产生近似查询结果的一种技术,是滑动窗口及其之上的查询处理技术。
滑动窗口上的查询处理:指的是在数据流的最近数据元素(记录)上执行查询,而不是在数据流的所有历史记录上执行查询。
- 比如,进行查询处理的时候,仅仅存取数据流上最近一天的数据元素,一天前的数据元素则丢弃掉。
- 为了实现数据流上基于滑动窗口的查询,一般需要在查询语句里,增加滑动窗口的定义方法(一般是对SQL语言进行扩充)。滑动窗口的大小是任意的,当滑动窗口过大时,窗口里的数据元素过多,不能缓存在内存里,需要利用磁盘保存部分数据,这将增加处理的延迟,研究人员在研究利用有限的内存,实现近似计算的算法。
5.4查询数据流的历史数据
- 在标准的流数据处理模式中,当某个元素处理结束后,将无法再访问到。这就意味着,某些数据已经被丢弃以后,用户发起即席查询,将无法获得准确结果。
- 我们可以规定即席查询只能参考它提交以后到达的新数据,之前的历史数据直接忽略掉。
- 我们还可以允许新提交的即席查询参考历史数据。历史数据不是原原本本地保存起来,而是保存一个摘要,是数据的一个梗概或者聚集汇总。这些数据摘要,有助于为未来的即席查询,计算一个近似的结果。这种办法,需要考虑到系统需要支持什么类型的查询,然后利用内存资源,维护一个数据摘要,最大限度地支持这些类型的查询。
5.5多查询优化与查询计划的适应性
在流数据处理系统中,大多数的查询是长时间运行的持续查询。系统同时运行大量的查询,可以通过多查询优化技术,提高查询处理的性能。由于系统不断有新的即席查询提交上来,为一组查询寻找最佳的执行计划,需要在线进行优化决策。
5.6堵塞操作
堵塞操作是这样的操作,它需要看到所有的输入数据以后,才能开始产生输出结果。
5.7数据流里的时间戳
滑动窗口,是基于数据流元素的时间戳或者顺序号属性进行定义的。
对于来自一个数据流的数据来讲时间戳一般不存在歧义。但是在一些场合,我们要对时间戳给予关注。原因是:
- 如果滑动窗口是在从多个数据流上产生的组合元组上定义的,如果来自两个数据流的元素的时间戳数值不一样,那么两个元组连接产生的组合元组应该赋予什么时间戳,是一个问题。
- 当若干分布式的数据流,构成一个逻辑数据流的时候,以及在分布式的传感器网络上,比较不同数据流的数据元素的时间戳,具有实际业务意义。
5.8批处理、采样、梗概
(1)批量处理
update操作足够快,但是computeAnswer操作很慢
新来的数据元素先缓存起来,在资源允许的情况下,定期计算查询的结果。查询结果不是根据最新的数据进行计算的(最新数据缓存起来,有待下一次进行成批的处理),而是有一定时间的延迟。
这种计算方法,获得的查询结果是准确的,只不过它是最近的准确的结果,而不是当前的准确结果。也就是,因为使用批量处理,牺牲了结果的及时性,但是跟上了数据流新数据达到的速率。
(2)采样
computeAnswer操作足够快,但是update操作很慢,不足以及时处理新到达的数据。
由于数据到达是在太快,没有必要利用所有的数据来计算查询结果。我们可以忽略一部分元组,在数据流上进行采样,在采样上而不是整个数据流上,计算查询的结果。
(3)梗概
既支持快速的update操作,也支持快速的computeAnswer操作,能够及时处理数据流新到达的数据。
梗概是一个比较小的数据结构,它能够把每个元素的处理代价保持到最低水平,从而使得流数据处理系统,能够赶上数据到达的速度。
六、查询处理的基础算法
6.1随机采样
- 数据上的随机采样,可以看作是一种摘要式的数据结构,它包含了整个数据集的基本特征。
分层采样:首先按照对观察指标影响较大额的某种特征,将总体分为若干个类别,再从每一类别内随机抽取一定数量的样本,合起来组成一个样本。蓄水池采样:只需要对数据进行一遍扫描,特别适合于数据流的采样。- 蓄水池采样的基本原理是,首先建立一个数组,将数据流里的前K个数,保存在数组中,即所谓的"蓄水池"。对于第n个数据元素(元组)An,以k/n的概率取An并以1/k的概率随机替换“蓄水池”中的某个元素,如果没有发生替换,则“蓄水池”数组元素不变,依此类推处理新到达的其它各个元素。该算法可以保证取到数据的随机性。
6.2梗概技术
梗概技术,是在数据流上,使用少量的内存,建立一个摘要结构。这个摘要结构,可以用于特定查询的近似结果的估计。
6.3直方图
直方图是一种摘要数据结构,人们使用直方图,来捕捉数据集里的一个字段或者一组字段的取值的分布情况。
6.5布隆过滤器
布隆过滤器是一种简单、高效的数据结构,用来判断一个元素是否属于一个集合。对其操作包括初始化、元素插入和元素查询过程。
Bloom Filter由一个长度为m的bit数组和k个Hash函数构成。M和k两个参数,可以根据我们可以接受的假阳性(False Positive)比率来进行调整。

6.6计数最小梗概
–计数最小梗概(Count-Min Sketch),使用一个次线性空间(Sub-Linear Space),来计算频率。它包含d行w列的一个矩阵,w和d的选择,体现了准确性和时间/空间开销的折中(Trade Off)。每一行有一个Hash函数,当一个元素到达,它被针对每行进行Hash操作,即使用每行对应的Hash函数,对元素数据进行映射,得到每行的一个下标,于是对应这些下标的列的元素保存的计数器(Counter),增加1,如图所示。可以看出,Count-Min Sketch和Bloom Filter有一些相似度之处。

七、流数据处理系统
7.1Storm
Storm是一个分布式的、高度容错的实时数据(流数据)处理的开源系统。
7.2其他流数据处理系统
tch和Bloom Filter有一些相似度之处。
[外链图片转存中…(img-25DzRhgf-1609506706456)]
七、流数据处理系统
7.1Storm
Storm是一个分布式的、高度容错的实时数据(流数据)处理的开源系统。
7.2其他流数据处理系统
除了经典的Storm系统,其它的流数据处理系统,还有Apex、Flink、Onyx等。