前言:基于人大的《数据科学概论》第三章OLAP与结构化数据分析。主要分为三部分,OLAP联机分析处理、高性能OLAP系统的关键技术、结构化数据分析工具。
一、OLAP—Online Analytic Processing联机分析处理
简说:大量的业务系统采用关系数据库来进行数据管理后,随着业务的不断发展,各个企业事业单位和政府部门积攒了大量的业务数据。为了避免数据处理时间过长,对业务顺利运行产生干扰,一般在业务数据库之外建立数据仓库系统。它从业务数据库**抽取、转换、装载**数据,帮助人们在上面执行各种分析任务。
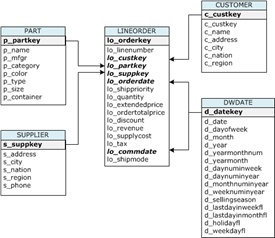
联机分析处理OLAP:也称在线分析处理,是在以星型模型(或者雪花模型)建模的数据仓库上进行多维分析。
多维分析:指的是从各个角度对我们感兴趣的一些数量进行汇总分析,比如我们从地区、客户、时间等维度,对销售明细数据进行汇总分析。
联机事务处理OLTP:比如在银行的存款、取款、查账、转账等业务中,要求的响应时间一般是几秒钟时间。
ETL:从业务数据库抽取、转换和装载(Extract Transform and Load)数据。
数据仓库与星型模型
数据仓库:就是面向主题的、集成的、非易失的、和时变的数据集合,用以支持管理决策。
-
面向主题的:是指每个数据仓库对应于企事业单位决策所包含的所有分析对象(数据)
-
集成的:是指数据仓库按照决策主题选择数据,把分布在各个部门中的多个异构数据源的数据集成起来,并且以新的数据模型来存储。
-
非易失的:指的是数据仓库的数据装载以后,一般不会删除。
-
时变的:是指随着业务的发展,新的业务数据不断地被抽取和装载到数据仓库中,以便进行分析。
操作型数据处理和分析型数据处理的差别:
| 比较项目 | 操作型数据处理 | 分析型数据处理 |
|---|---|---|
| 数据模型 | 实体-关系模型(ER模型) | 星型模型以及雪花模型 |
| 操作的记录数量 | 少量记录 | 大量记录 |
| 数据是否可以更新 | 数据可以更新、删除 | 一般只对数据进行追加、不删除、极少更新 |
| 响应时间要求 | 秒级 | 分钟级、小时级 |
| 目的 | 支持业务运行 | 支持决策需求 |
数据仓库主要采用星型模型进行数据建模。在这个模型中,包含事实表和维表。事实表主要记录了具体的业务交易,比如记录了客户的购物信息。维表记录分类信息,比如时间信息、地理区域信息、产品分类信息等。
- 每个维表代表人们观察数据的一个角度。一般维表具有层次结构(Hierarchy),即人们观察事物的不同细节,比如时间维包括年、季度、月份、日期等不同细节的层次(Level)。维表的具体的一个取值,称为
维的成员(Member)。比如某年某月某日是时间维(时间维的最低的层次是日期)的一个成员。 SSB(Star Schema Benchmark)是麻省州立大学波士顿校区的研究人员定义的、基于实现商业应用的数据仓库测试基准,被学术界和工业界广泛接受,用来测试决策支持类应用中的数据库系统性能。- 测试基准包含
数据模型、工作负载、以及性能指标等三个方面。
联机分析处理OLAP
简说:数据仓库上的分析任务,包括简单的分析和复杂的分析。
简单分析:指的是利用数据生成报表以及进行多维分析。(在这里,简单分析主要指的是联机分析处理,包括固定报表和多维分析,其表现形式是在数据仓库数据上执行查询获得汇总信息)
复杂分析:指的是在数据上运行复杂的统计方法、机器学习和数据挖掘方法,从而发现不是那么显然的规律,发现新的知识。

联机分析处理(OLAP):是数据仓库的主要负载和应用,通过分析操作,为高层管理人员提供决策支持。
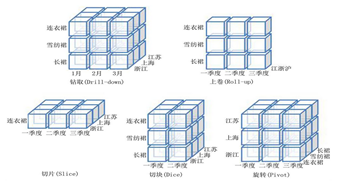
联机分析处理的主要操作:包括下钻(Drill Down)、上卷(Drill Up)、切片(Slice)、切块(Dice)、旋转(Pivot)等。
- 下钻和上卷是改变维的层次,变换分析的粒度。
下钻:是在某个分析维度上,从高层次的汇总数据深入到细节数据进行观察。上卷:是在某个分析维度上,将低层次的细节数据概括到高层次的汇总数据。- 比如当我们把商品销售情况表(SSB数据模型中的LineOrder表)的一部分记录在时间维度上按月度进行分组汇总(比如销售额)以后,上卷操作则把分析的粒度变成年度,即按照年度进行分组汇总,下钻操作则把分析的粒度变成日期(即以天作为汇总的粒度)。
切片和切块:是选定一部分维度值,关心度量数据在剩余维度上的分布情况。如果剩余的维度只有两个,称为切片。如果剩余维度有三个或者以上,称为切块。- 比如在SSB模型中,我们选定某个客户和供应商后,对销售数据在剩余的两个维度即配件维度、时间维度上进行汇总,就是切片操作。如果我们只选定某个顾客,对销售数据在剩余的三个维度,即供应商维度、配件维度、时间维度上进行汇总,就是切块操作。
旋转:是变换维的方向,也就是在汇总表格中(在Excel中称为数据透视表),重新安排维的位置,即对行/列进行互换。
OLAP系统的类型(三种)
简说:按照数据存储格式分类,OLAP系统可以分为多维OLAP(Multi Dimensional OLAP ,MOLAP)、关系OLAP(Relational OLAP,ROLAP)以及混合OLAP(Hybrid OLAP ,HOLAP)三类。
-
MOLAP将OLAP分析所用到的多维数据,物理上存储为多维数组的形式,形成“立方体”(Cube)的结构。星型模型的各个维的属性值,被映射成多维数组的下标值或下标的范围,而聚集数据作为多维数组的值存储在数组的单元中。
- MOLAP的主要优点是性能高,主要缺点是占用大量的空间保存汇总数据。
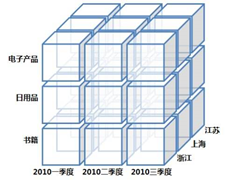
- MOLAP的主要优点是性能高,主要缺点是占用大量的空间保存汇总数据。
-
ROLAP将分析用的多维数据存储在关系数据库中,通过把OLAP操作表达成SQL查询的形式,在关系数据库上执行,获得汇总结果。
- ROLAP的主要优点是,采用关系数据库保存原始明细数据,占用空间有限,但是由于每个OLAP操作都被转换成一个SQL查询重新执行,性能受到影响。
-
HOLAP,它能把MOLAP和ROLAP两种结构的优点结合起立。细节数据保留在关系型数据库的事实表中,但是聚合后的数据保存在“立方体”中的这种方式具有更好的灵活性。HOLAP的查询效率比ROLAP高,但低于MOLAP。
二、高性能OLAP系统的关键技术
列存储技术
-
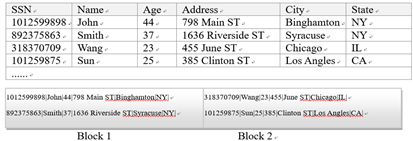
行存储:- 一行一行存放数据
- 适合存取少量数据行
-
列存储:- 一列一列存储数据
- 适合对数据进行分析、存取少量数据列
- 可以使用数据压缩技术,减少磁盘空间占用,和处理这些属性列的时候I/O操作开销,从而加快数据处理过程。
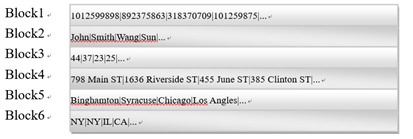
位图索引技术
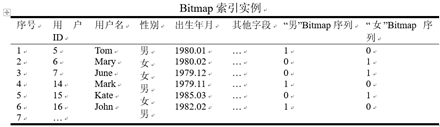
高基数字段的位图索引
- 分容器Bitmap索引
- 也就是需要对数值范围进行分段

内存数据库技术
简说:对于中小规模的数据库来讲,大容量的内存,使得整个数据库的所有数据都可以装载到内存。
(1)存储技术
- 数据的主副本保存在磁盘中,在需要存取的时候装载到缓冲区。在内存数据库中,数据的主副本保存在内存中,暂时不用的数据被保存到磁盘,以便为将要用到的数据腾出空间。围绕内存重新对数据库系统进行设计的策略,称为“anti-caching”策略
- 行存储、列存储、PAX存储
- RCFile是Hadoop平台上的一种PAX存储结构
(2)索引技术
- 当我们从数据库中查询数据,如果有索引的帮助,对数据进行定位,我们就可以避免全表扫描
- Cache敏感的索引、和Cache不敏感的索引、以及特殊索引比如面向非易失性内存的索引。目的是通过数据结构和算法的设计,减少Cache Miss。
(3)查询优化
- 对于内存数据库来讲,查询优化的重点是如何利用多核CPU、以及众核GPU,实现关键的数据操作的快速处理,比如选择、投影、连接、聚集。
(4)并发控制
- 是有多个事务并发执行的情况下,保证数据库状态正确的技术手段。当数据完全驻留内存,我们有多个CPU核心可用的时候,设计合理的并发控制方法,才能有效发挥多核处理的威力。多版本管理、轻量级枷锁等。
(5)恢复技术
- 当发生掉电情况,内存的数据即可消失(除了非易失性内存)。对于内存数据库来讲,恢复模块是保证其可靠性的重要模块。并行日志、查分日志、 Command Logging、非易失性内存的使用等。
MPP并行数据库
MPP是Massive Parallel Processing的缩写,MPP并行数据库利用专用的数据库集群(dedicated cluster)的多个节点的并行处理能力,提高数据库的查询处理性能。
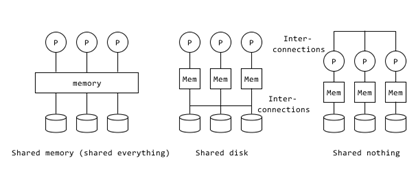
(1)架构
- 共享内存架构(Shared memory)
- 共享磁盘架构(Shared disk)
- 无共享架构(Shared nothing)
(2)数据划分方法
- 数据的划分称为分片,分片的主要方法有Range、hash等方法。
- Range方法把数据库表的记录按照某个字段的值所属的范围进行分片
- 比如当按照日期进行数据分片时,我们可以把不同年度不同月份的数据划分到不同分片。
- hash方法,则对于数据库表中的记录,根据其某一个或者某几个属性列的取值,计算一个Hash值,对应到具体的分区,完成数据分片。
(3)查询处理
- 单表查询及其处理(子查询与结果合并)
- 单表查询指的是对一个数据库表进行选择、分组和聚集的查询。从销售表中,选择产品101的销售记录,按照年度进行分组,计算销售额的汇总。
- 多表连接查询及其处理(Hash连接)
- 从销售表和客户表中,进行连接查询,选择2015和2016年的销售记录,按照客户和年度进行分组,汇总销售额。
三、结构化数据分析工具
分为两大类:
- 传统的MPP数据库以及列存储数据库
- 基于Hadoop的结构化数据分析工具,即SQL on Hadoop系统

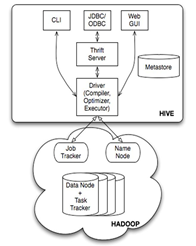
(1)MPP(Shared Nothing)数据库、基于列存储的关系数据库
1、Teradata
Teradata数据库,是面向大型数据仓库应用的基于Shared Nothing架构体系的并行数据库系统。Teradata系统由三部分组成,分别是处理节点(Node)、实现节点间通讯的高速互联网络(Interconnection)、数据存储介质(一般是磁盘阵列)。
- OS与PDE。Teradata并行数据库扩展(PDE,Parallel Database Extensions),操作系统软件(OS)。PDE是直接架构在操作系统之上的一个接口层,主要功能是,管理和运行虚拟处理器、进行Teradata并行任务调度、进行操作系统内核和Teradata数据库的运行时故障处理等。
- AMP。存取模块处理器(AMP,Access Module Processor),是Teradata数据库的关键进程,用于处理所有与数据有关的文件系统的操作任务。
- PE。解析引擎(Parsing Engine,PE),用于实现客户端(通常是使用Teradata数据库的应用程序的SQL请求)和存取模块处理器(AMP)之间的通信和交互。主要功能包括会话控制(Session Control),SQL语句解析、优化,查询步骤的生成和分发、并行查询处理、和返回查询结果。
- BYNET。用于节点之间的双向广播、多路广播(multicast)和点对点通信(point-to-point communication)。
2、SAP HANA(面向OLAP)
SAP HANA是支持OLTP和OLAP混合负载的内存数据库系统。通过采用内存计算技术,HANA能够获得极快的事务响应时间和极高的事务吞吐能力。
- 通过利用大内存、以及利用列存储和数据压缩技术,HANA把整个数据保存在内存中,实现了实时的查询处理。利用HANA的快速查询处理能力,人们可以获得秒级的响应时间(小于10秒),性能评测结果显示,在相同的硬件缓急和数据量情况下,HANA往往能够获得超过Oracle(磁盘数据库)一个数量级左右的查询性能提升。
HANA:HANA数据库产品是一个完备的工具套件,包括内存数据库服务器、建模工具以及客户端工具。
3、MonetDB/Vectorwise/VectorH
- MonetDB是基于列存储的面向分析型应用的内存数据库系统。
- Vectorwise是MonetDB的商业化版本
- VectorH是基于Vectorwise的SQL on Hadoop系统
向量化的查询处理模式:是每个属性列的每100-1000个值构成以一个向量,执行查询的时候,这一系列的向量以流水线的方式流过,对该属性列进行操作的一系列操作符,以致最后完成查询。这种查询处理模式,可以充分利用现代CPU的SIMD指令,通过并行操作,快速完成数据的处理。
数据库查询执行模式
-
(1)一次处理一个元组(Tuple-at-a-time Progressing)
- 也称Volcano风格的查询处理模式。该模式是在DBMS系统中使用最广泛的查询处理模式。该模式是在DBMS系统中使用最广泛的查询处理模式,包括MySQL、SQList、PostgreSQL、Oracle等。、
- 查询执行引擎拿到一个查询执行计划,该计划由查询优化器从SQL语句翻译而来,是由物理操作符构成的一颗语法树。
- 每个操作符有三个接口,分别是Open()、next()、close()。Open方法初始化资源,包括初始化内存数据结构或者打开文件,close方法则释放资源。
- 整个执行计划的执行是由树根节点的next方法拉动的,父节点的next方法,从子节点提取一个元组。
-
(2)一次处理一块
- Block-oriented processing查询处理模式是对Tuple-at-a-time(一次处理一个元组)查询处理模式的扩展。对next函数的调用,将返回一组元组(100-1000个),而不是一个元组。
- 减少了函数调用的开销,获得比Tuple-at-a-time处理模式更高的CPU数据Cache和指令Cache命中率。
- 但是存取 每行记录不必要的字段,虽然导致频繁的CPU数据Cache Miss
-
(3)一次处理一列(Column-at-a-time Progress)
- 一次处理一列查询模式,是最初实现的查询计划列式执行模式。
- 该查询模式使用列存储格式,每个数据列单独进行存放(紧密排列的数组,dense-packed arrays)和后续处理,每个操作符的next方法,处理整张表格的某一列,并且把中间结果保存起来。
- 为了支持这种处理模式,需要定义和实现若干操作原语,这些操作原语在一个紧凑的循环中,对数组的各个元素值进行处理。一般来讲,对这些循环处理进行翻译后的指令,更容易装入CPU的L1指令Cache,提高指令Cache的命中率。
- 但是Column-at-a-time Progress查询处理模式也有其局限性,因为它对一个表格的整个数据列进行操作,于是中间结果集可能很大,需要物化到内存、或者磁盘中,于是导致CPU的数据CAche Miss以及I/O代价。
-
向量化查询处理模式(Vectorized Query Processing)
-
向量化查询处理模式,是最先进的列式执行模式,它解决了一次处理一列查询处理模式的缺点。
-
这种处理模式建立在一次处理一列的查询模式之上,只不过在每个next函数调用中,操作符处理的是某列数据的一部分,称为一个向量,而不是整个表的某一列。
-
Y this Y this Y this
-
(2)SQL on Hadoop系统
SQL on Hadoop系统是基于结构化数据分析的工具
Hive on MapReduce 和 Hive on Tez 是Hadoop平台上的结构化大数据分析工具,SparkSQL则是Spark平台上的结构化大数据分析工具。
- SQL on Hadoop系统依赖于HDFS(Hadoop Distributed File System)作为数据存储层。
HDFS具有高度的扩展性和容错性(通过数据的多副本存放),于是SQL on Hadoop系统在存储层面支持超大规模数据的处理。 - MPP并行数据库需要运行在特定的硬件平台上,各个厂家的软件也不是免费的,而SQL on Hadoop系统则可以运行在廉价服务器构成的集群上,软件几乎是免费的。
1、Impala
Impala是Cloudera公司开发的大数据实时查询系统。它提供SQL查询接口,能够查询存储在Hadoop的HDES和HBase中的PB级大数据。
- Impala的实现,借鉴了Google 的
Dremet(交互式数据分析系统)系统。 Dremet的主要技术特色包括:- (1)实现了嵌套的列存储数据结构
- (2)使用多层查询数,使得任务可以在上千节点上并行执行,不断对结果进行聚集。
- Impala包含 Query Planner、Query Coordinator 和 Query Exec Engine三个模块。Query Planner接收来自客户端的SQL查询请求,然后将其查询转化为许多子查询,Query Coordinator将这些子查询分发到各个节点上,由各个节点上的Query Exec Engine负责子查询的执行,最后返回子查询的结果。这些中间结果经过聚集之后,最终返回给用户。
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xBVBray6-1608644955863)(OLAP与结构化数据分析.assets/image-20201222211129816.png)]](https://img-blog.csdnimg.cn/20201222215431317.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80ODkzMTg3NQ==,size_16,color_FFFFFF,t_70)
2、Presto
Presto是由Facebook贡献出来的开源SQL on Hadoop 项目(2012年开发,2013年开源),它的目标和Impala是类似的,就是要提供在Hadoop平台上对结构化数据的交互式查询能力。
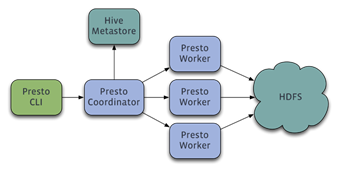
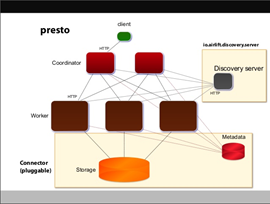
- Presto 采用 Master-Slave 的架构,它由一个Coordinator 节点,多个Worker节点组成。Coordinator节点中通常内嵌一个Discovery Server。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Serve服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。
-
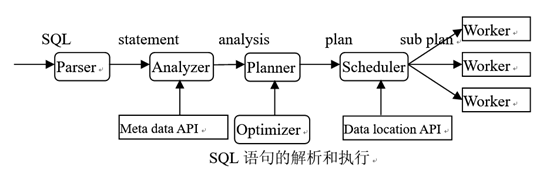
SQL语句的解析过程,Presto服务器对其接收到的SQL查询,大致经过如下步骤对其进行解析和执行。首先Parser对SQL语句进行语法和词法解析,生成statement 结构。然后Analyzer利用元信息,对语法树进行检查,生成analysis结构。Planner利用Optimizer的帮助,生成逻辑计划plan,并进行优化。Scheduler根据数据的位置信息,把逻辑计划划分成物理计划片段sub plan,分发给若干Worker节点,由其执行。
-
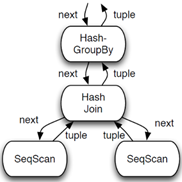
该SQL查询语句生成的逻辑执行计划如图所示。逻辑执行计划图中的虚线,是Presto对逻辑执行计划的切分点。这些切分点把逻辑计划划分成四个字计划Sub Plan,每个Sub Plan交给一个或者多个Worker节点运行。先导和后续Sub Plan之间需要进行数据交换,如图所示:

-
(1)Coordinator通过HTTP协议调用Worker节点的任务(Task)接口,将执行计划分配给Worker节点(图中蓝色箭头)。
-
(2)执行SubPlan1的每个Worker节点,读取一个Split的数据,并过滤后将数据分发给每个SubPlan0节点,进行Join操作和Partial Aggregation操作。
-
(3)执行SubPlan0的每个Worker节点,计算完成后,按Group By Key 的Hash值,将数据分发到不同的SubPlan2节点。
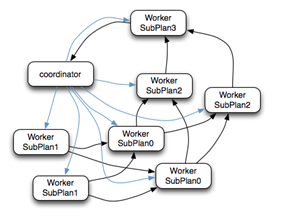
-
(4)执行SubPlan2的每个Worker节点,进行全局聚集,进行计算完成后,后将数据分发到执行SubPlan3的Worker节点,执行Limit操作。
lit的数据,并过滤后将数据分发给每个SubPlan0节点,进行Join操作和Partial Aggregation操作。 -
(5)执行SubPlan3的Worker节点计算完成后,通知Coordinator 结束查询,并将数据发送给Coordinator,由其返回客户端程序。
-