前言:文章基于人大的《数据科学概论》,主要是总结第一章—数据科学概论 的一些重点内容。里面有些比较细的概念,有心的读者可以自己去查找资料。
文章目录
1.1数据科学的定义
(1)数据科学
数据科学是对数据进行分析,抽取信息和知识的过程,提供指导和支持的基本原则和方法的科学。
数据科学的核心任务是从数据中抽取信息、发现知识。
数据科学包含一组概念、原则、过程、技术/方法、工具为其核心任务服务。
1.2数据科学和统计学、人工智能机器学习、数据挖掘、数据库与数据处理、大数据分析、基于数据的决策 的关系
(1)数据科学跨学科的特点
数据科学是基于计算机科学(数据库、数据挖掘、机器学习等)、统计学、数学等学科的一门新兴的交叉学科。从统计学、人工智能、机器学习、数据挖掘、数据库与数据处理、大数据分析等领域,吸取有效的成分,不断创建起来。
(2)数据科学与数据库、大数据分析的关系
数据库的运行,积累了大量的基础信息,为数据科学提供了重要的“原材料”。
大数据分析是(机器学习与数据挖掘),是数据科学的有效组成部分。
(3)数据科学与基于数据的决策的关系
1、基于数据的决策:人们基于数据分析的结果进行决策,而不仅仅是基于直觉,拍拍脑袋进行决策。
2、数据科学的目的:通过分析理解数据、获得洞察力,它包含一系列的基本原则、过程、技术/方法、和工具。
二者的关系:***故数据科学是为基于决策服务的***即我们从数据中挖掘其隐藏的模式,获得新知,目的是指导我们新的行动
1.3数据科学家
数据科学家需要的技能:拥有一系列的知识和技能,包括一定的数学基础、统计分析、机器学习、数据挖掘、数据可视化、编程能力、对具体应用领域的深入了解、以及良好的沟通能力。
1.4数据科学的基本原则
(1)原则1:数据分析可以划分成一系列明确的阶段
分析数据、获得知识,从而解决具体的业务问题,是数据科学的核心任务。这个任务可以划分为 理解业务数据、收集数据、对数据进行集成、对数据进行分析挖掘、对结果进行可视化、把结果表达给目标听众等阶段。
(2)原则2:描述性分析与预测性分析
描述性分析:面向过去,发现隐藏在数据表面之下的历史规律或模式。
预测性分析:面向未来,对现有的数据进行深度分析,构建分类/回归模型,对未来趋势进行预测。
总结:简单了来说,原则2就是对数据分析的结果进行评估,需要结合所处的应用程序上下文环境进行仔细考察。
(3)原则3:实体的相似度
从大量的基础数据中,我们可能分析出变量之间的相关性。
(4)原则4:模型的泛化能力
在一些属性上相似的实体,在其他属性上(可能是未知的一些属性)一般也是相似的。
计算相似度是数据科学的基本方法。
(5)原则5:分析结果的评估与特定的应用场景有关
在现有的数据上适配很好的模型(分析结果),可能不能很好地泛化,即不能适配到新数据上。----------过度拟合
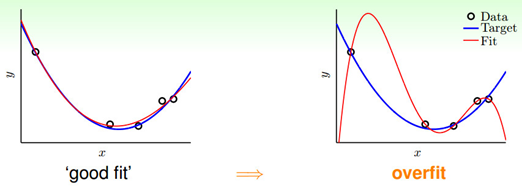
(6)原则6:相关性不同于因果关系
相关性:数据多了,a发生时b发生的概率足够明显,那么a和b就是相关的。
因果性:是逻辑上的概念,前者的出现必然导致后者,a发生导致b发生。
总结:当我们从数据分析结果中,试图得出一些因果关系的结论的时候,我们必须考虑到一些额外的因子。(有可能先前没有考虑进来)
(7)通过并行处理提高数据处理(分析)速度
程序=数据结构+算法
数据科学=数据+数据上的计算
1、任务并行:多个进程对数据进行处理
2、数据并行:依赖于数据的划分
即把整个数据集(大规模),划分成一系列小的数据集,然后利用多个进程对这些小的数据进行并行操作,以达到提高数据处理速度的目的。
1.5数据处理流程:一种横向视角
(1)数据的生命周期
包括数据的产生、数据的表示和保存、数据的销毁等各个阶段。
(2)冷数据和热数据
经常用到的数据叫热数据,暂时不用的历史数据是冷数据
(3)数据处理的流程
- 数据采集
- 数据表示和存储
- 数据清洗–剔除错误
- 数据集成
- 数据分析
- 数据可视化
- 基于数据的决策
1.6数据处理系统的架构
(1)一种纵向视角:
数据处理系统包括:硬件平台、存储、检索和分析、应用
(2)三种处理模式
- 批处理:数据先保存起来,然后分析(全量数据);响应时间较久,为分钟/小时计。
- 流式处理:数据及时处理,处理过后一般不保存;响应时间以秒计时。
- 交互式处理:数据先保存起立,然后查询(部分数据);响应时间毫秒计时。
(3)Lambda架构
这三种不同的处理模式整合起来就是Lambda架构。
分为三个层次:
- 批处理层(Batch Layer)
- 实时处理层(Speed Layer)
- 服务层(Serving Layer)

1.7数据的多样性:一种空间视角
我们可以采集到很多的数据,类型丰富多样,我们把这些数据分成三类
(1)三类数据
1、结构化数据:主要指的是符合关系数据模型的二维表数据。
2、半结构化数据:包括各种包含结构标记(Tag)的HTML网页、XML文档、RDF数据等。
3、非结构化数据:包括文本数据、图数据以及各种多媒体数据。
(2)不同数据在计算机里面的表示
1、实体及其关系:轨迹数据、时序数据可以用关系模型描述
2、文本:布尔模型、TF、IDF、Embedding…
3、社交网络:邻接矩阵、边列表、邻接关系列表…
1.8数据价值的挖掘:一种价值提升视角
数据价值的提升:
- 原始数据,一般数据量大,数据的价值低,有可能包含噪声(错误数据)
- 经过
数据清洗,获得高质量的数据,来自不同数据源的数据需要集成 - 对数据的分析方法,从
简单到复杂,包括简单统计和报表、复杂分析包括统计分析、数据挖掘、机器学习方法。 - 经过适当地分析,可以挖掘到数据中隐藏的模式、相关性
- 在普适的一些模式的基础上,我们继续抽象出知识。
知识是比模式、相关性等更加具有普遍性的规律。