相关数学基础
1.【m】信息熵
信息量
1>如何描述
多少信息用信息量来衡量,我们接受到的信息量跟具体发生的事件有关
信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如湖南产生的地震了;越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了
2>如何用公式体现
公式性质的要求:
当一个事件发生的概率p(x)为1并且它发生了,那我们等到的信息量是h(x) = 0。
当一个事件发生的概率p(x) 为0 并且它发生了,那我们得到的信息可能是无限大。
H(x)随p(x)单调递减。
独立事件:p(x,y) = p(x)p(y)。
独立事件:h(x,y) = h(x) + h(y)。
信息量h(x) 反比于p(x) 。 7.信息量是非负的。
h(x)一定与p(x)的对数有关(因为只有对数形式的真数相乘之后,能够对应对数的相加形式
信息量公式:
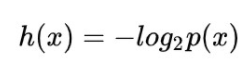
问题:
1.负号
2.2为底数
【m】信息熵
信息量度量的是一个具体事件发生了所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。即:
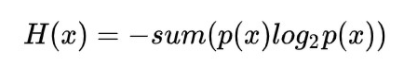
转换一下为:
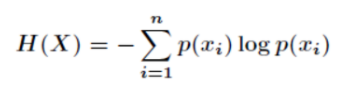
伯努利分布下的信息熵
当随机变量只取两个值,例如 1,0[所有的二分类问题~]:

2.【m】期望
简单理解: 在一场赌博游戏中,给定一个均匀的硬币,记随机变量为每次你的收益,即抛出正面赢一块钱(x=1),抛反面输一块钱(x=-1),如果你抛了足够多的次数,那么你的平均收益为0,即期望在该设定下的物理意义
总结: 期望就是在多次实验之后,整体预期的结果
期望与平均数的关系
平均数是实验后根据实际结果统计得到的样本的平均值,期望是实验前根据概率分布“预测”的样本的平均值
3.联合熵,条件熵与互信息
联合熵
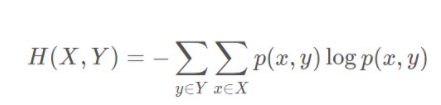
条件熵:

互信息
含义: 一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。
可以度量一个事件的发生对另一个事件贡献的信息量,可以度量一个特征对一个分类标签又多大的贡献度。
互信息的作用:
做特征筛选,将那些与标签相关性不高的特征删除,比如垃圾邮件分类中。
另一个可以度量相关性的工具是皮尔森相关性系数,不过他和互信息站的角度是不同的,互信息是站在熵的角度,两个变量之间之间可以没有线性相关性,而皮尔森相关性系数是必须线性相关的。
为什么要做特征筛选:
1.参数的量过大,样本很少,比如梯度下降中,参数是需要样本支撑的公式来更新的,样本决定了参数更新多少次以及怎么更新,如果样本过少,参数更新次数就会非常低,这样就会造成过拟合的问题。
2.特征比较多,特征多少是靠经验的。
python中计算互信息的模块:
sklearn.metrics.mutual_info_score
互信息的使用:
一般不直接使用,而是结合在算法内部的使用,比如决策树中有一个特征重要性的判断

公式推导:

特性: 概率取负对数表征了当前概率发生所代表的信息量。上式表明,两事件的互信息为各自事件单独发生所代表的信息量之和减去两事件同时发生所代表的信息量之后剩余的信息量,这表明了两事件单独发生给出的信息量之和是有重复的,互信息度量了这种重复的信息量大小。最后再求概率和表示了两事件互信息量的期望。从式中也可以看出,当两事件完全独立时,p(x,y)=p(x)⋅p(y)p(x,y)=p(x)\cdot p(y)p(x,y)=p(x)⋅p(y),互信息计算为 000,这也是与常识判断相吻合的。
互信息、联合熵、条件熵之间的关系


4.【m】交叉熵
对于一个样本集,存在两个概率分布 p(x) 和 q(x),其中 p(x) 为真实分布,q(x) 为非真实分布,在机器学习中就是预测分布。
如果我们用非真实分布 q(x) 来代表样本集的信息量的话,真实熵:
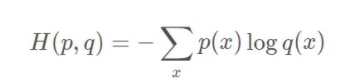
其中表示信息量的项来自于非真实分布 q(x),而对其期望值的计算采用的是真实分布 p(x)
划重点:交叉熵公式要记住,相对熵的公式尽量记住,并知道他和交叉熵单调性是相同的
用途:损失函数的度量
q(x):即模型预测出来的概率分布
p(x):即真实样本标签的概率分布
5.【m】相对熵
也称 KL 散度 公式:
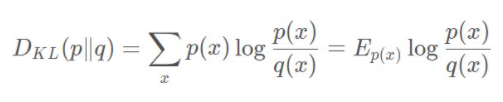
5.相对熵与交叉熵的关系
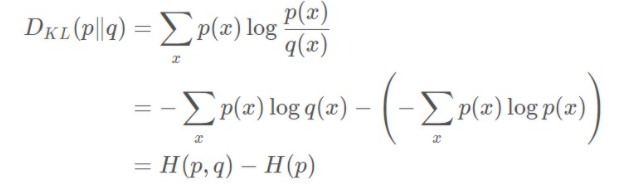
结论:相对熵表示的其实是当我们用一个非真实的分布表示系统时,其得到的信息量期望值相比采用真实分布表示时候多出的部分
因此:相对熵关系可以度量预测系统给出的概率分布与原分布的差异大小,因而可以作为损失函数,其与交叉熵具有一样的单调性。
调包实现决策树:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)
tree_clf.feature_importances_ ##通过基尼系数加权得到的一个值,来评估特征的重要性,帮助我们来筛选特征,背后具体的实现可以查看sklearn文档。
决策树可视化:
# conda install python-graphviz
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file="iris_tree.dot",
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
决策树具体使用可以参考sklearn官方文档,
小tips:
- 决策树深度(max_depth)控制:对于分类树来说,深度不宜过高,否则容易出现过拟合的问题,一般不超过5,回归树的话就可以稍微深点。
- 决策树不是一个精度非常高的分类算法(相对于很多集成模型和深度学习模型),我们需要掌握原理,实际上是很少使用的。
- 对于一个算法,重要的是掌握这个算法的核心参数,以及如果调参的。
- 决策树经常被我们用来做特征筛选(训练时间不长是使用)。
做特征筛选的几个层次: - 皮尔森想关心系数
- 互信息
- 直接用决策树分类器本身
可以通过画图的方式来对决策树进行直观的debug:
conda install python-graphviz
from sklearn.tree import export_graphviz #画图的函数,可以展示一个dot格式的图
export_graphviz(
tree_cif,
out_file="iris_tree.dot",
feature_name=iris.feature_name[2:],
class_name=iris.target_names,
rounded=Tree,
filled=True
)
dot -Tpng iris_tree.dot -o iris_tree.png
通过画图我们可以直观的看到这个模型是否真正的表现出来层级划分,解释性很强。